 使用RAPID cuDF處理時間序列數據的常見步驟
使用RAPID cuDF處理時間序列數據的常見步驟
這篇文章是 加速數據分析系列文章的一部分:
加速數據分析:使用 RAPID cuDF 加速數據探索討論了 pandas 庫如何在 Python 中提供高效、富有表現力的函數。
本文將帶您了解使用 RAPID cuDF 處理時間序列數據的常見步驟
由于標準探索性數據分析( EDA )工作流程通常局限于單個核心,因此它得益于 RAPIDS cuDF 的加速計算,這是一個具有 pandas 類接口的加速數據分析庫。眾所周知,時間序列數據需要額外的數據處理,這會增加工作流程的時間和復雜性,使其成為利用 RAPIDS 的另一個很好的用例。
使用 RAPIDS cuDF ,您可以加快對不太大也不太小的“金發姑娘”數據集的時間序列處理。這些數據集在 pandas 上很繁重,但不需要像 Apache Spark 或 Dask 這樣的完全分布式計算工具。
什么是時間序列數據?
本節介紹了依賴時間序列數據的 機器學習( ML )用例,以及何時考慮加速數據處理。
時間序列數據無處不在。時間戳在許多類型的數據源中都是一個變量,從天氣測量和資產定價到產品購買信息等等。
時間戳具有所有級別的粒度,例如毫秒讀數或月讀數。當時間戳數據最終被用于復雜建模時,它就變成了時間序列數據,對其他變量進行索引,使模式變得可觀察。
以下流行的 ML 用例在很大程度上依賴于時間序列數據,還有更多的依賴:
金融服務業欺詐異常檢測
零售業的預測分析
用于天氣預報的傳感器讀數
內容建議推薦系統
復雜的建模用例通常需要處理具有高分辨率歷史數據的大型數據集,這些數據可能跨越數年至數十年,還需要處理實時流數據。時間序列數據需要經過轉換,例如向上和向下重新采樣數據,以使數據集之間的時間段一致,并被平滑到滾動窗口中,以消除模式噪聲。
pandas 提供了簡單、富有表現力的功能來管理這些操作,但您可能在自己的工作中觀察到,單線程設計很快就會被所需的處理量所淹沒。這尤其適用于需要快速數據處理周轉的大型數據集或用例,而時間序列分析用例通常會這樣做。 pandas 處理數據的后續等待時間可能會令人沮喪,并可能導致見解延遲。
因此,這些場景使 cuDF 非常適合時間序列數據分析。使用類似 pandas 的 API ,您可以以高達 40 倍的速度處理數十 GB 的數據,從而節省任何數據項目中最有價值的資產:您的時間。
RAPIDS cuDF 的時間序列
為了展示 RAPIDS cuDF 加速探索數據的好處,以及它是如何被輕易采用的,本文介紹了 Time Series Data Analysis 中的一個子集時間序列處理操作。這是一個強大的筆記本分析,對 RAPIDS GitHub 存儲庫中公開的真實天氣讀數數據集進行了分析。
在完整的分析中, RAPIDS cuDF 以 13 倍的加速執行(有關確切數字,請參閱本文后面的基準測試部分)。加速通常會隨著整個工作流程變得更加復雜而增加。
從現實世界中推斷,這種收益具有真正的影響。當一個小時的工作量可以在 5 分鐘內完成時,你就可以有意義地為一天增加時間。
數據集
Meteonet 是一個現實的天氣數據集,它匯集了 2016-2018 年巴黎各地氣象站的讀數,包括缺失和無效的數據。它的大小約為 12.5 GB 。
分析方法
對于這篇文章,假設你是一名數據科學家,第一次收到這些匯總數據,必須為氣象用例做好準備。具體的用例是開放式的:它可以是氣候模型中的預測、報告或輸入。
當你回顧這篇文章時,大多數功能應該都很熟悉,因為它們的設計類似于 pandas 中的操作。此分析旨在執行以下任務:
格式化數據幀。
重新對時間序列進行采樣。
運行滾動窗口分析。
這篇文章忽略了筆記本 Time Series Data Analysis Using cuDF . 中演示的端到端工作流程中解決的幾個數據不一致
步驟 1. 格式化數據幀
首先,使用以下命令導入此分析中使用的包:
# Import the necessary packages import cudf import cupy as cp import pandas as pd
接下來,讀取 CSV 數據。
## Read in data gdf = cudf.read_csv('./SE_data.csv')
首先關注感興趣的氣象參數:風速、溫度和濕度。
gdf = gdf.drop(columns=['dd','precip','td','psl'])
隔離感興趣的參數后,執行一系列快速檢查。通過將日期列轉換為日期時間數據類型來啟動第一次轉換。然后,打印出前五行,以可視化您正在處理的內容,并評估表格數據集的大小。
# Change the date column to the datetime data type. Look at the DataFrame info gdf['date'] = cudf.to_datetime(gdf['date']) gdf.head() Gdf.shape
| number_sta | lat | lon | height_sta | date | ff | hu | t | |
| 0 | 1027003 | 45.83 | 5.11 | 196.0 | 2016-01-01 | 98.0 | 279.05 | |
| 1 | 1033002 | 46.09 | 5.81 | 350.0 | 2016-01-01 | 0.0 | 99.0 | 278.35 |
| 2 | 1034004 | 45.77 | 5.69 | 330.0 | 2016-01-01 | 0.0 | 100.0 | 279.15 |
| 3 | 1072001 | 46.20 | 5.29 | 260.0 | 2016-01-01 | 276.55 | ||
| 4 | 1089001 | 45.98 | 5.33 | 252.0 | 2016-01-01 | 0.0 | 95.0 | 279.55 |
表 1 。顯示數據集前五行的輸出結果
輸出
DataFrame 形狀( 127515796 , 8 )顯示 12751579 六行乘八列。現在已經知道了數據集的大小和形狀,您可以開始更深入地研究數據采樣的頻率。
## Investigate the sampling frequency with the diff() function to calculate the time diff ## dt.seconds, which is used to find the seconds value in the datetime frame. Then apply the ## max() function to calculate the maximum date value of the series. delta_mins = gdf['date'].diff().dt.seconds.max()/60 print(f"The dataset collection covers from {gdf['date'].min()} to {gdf['date'].max()} with {delta_mins} minute sampling interval")
數據集涵蓋了從2016-01-01T00:00:00.000000000到2018-12-31T23:54:00.000000000的傳感器讀數,采樣間隔為 6 分鐘。確認數據集中表示了預期的日期和時間。
在完成對數據集的基本審查后,開始使用特定于時間序列的格式。首先將時間增量分隔成單獨的列。
gdf['year'] = gdf['date'].dt.year gdf['month'] = gdf['date'].dt.month gdf['day'] = gdf['date'].dt.day gdf['hour'] = gdf['date'].dt.hour gdf['mins'] = gdf['date'].dt.minute gdf.tail
現在,數據在年末被分為年、月和日的列。這使得以不同的增量對數據進行切片要簡單得多。
| number_sta | lat | lon | height_sta | date | ff | hu | t | year | month | day | hour | mins | |
| 127515791 | 84086001 | 43.811 | 5.146 | 672.0 | 2018-12-31 23:54:00 | 3.7 | 85.0 | 276.95 | 2018 | 12 | 31 | 23 | 54 |
| 127515792 | 84087001 | 44.145 | 4.861 | 55.0 | 2018-12-31 23:54:00 | 11.4 | 80.0 | 281.05 | 2018 | 12 | 31 | 23 | 54 |
| 127515793 | 84094001 | 44.289 | 5.131 | 392.0 | 2018-12-31 23:54:00 | 3.6 | 68.0 | 280.05 | 2018 | 12 | 31 | 23 | 54 |
| 127515794 | 84107002 | 44.041 | 5.493 | 836.0 | 2018-12-31 23:54:00 | 0.6 | 91.0 | 270.85 | 2018 | 12 | 31 | 23 | 54 |
| 127515795 | 84150001 | 44.337 | 4.905 | 141.0 | 2018-12-31 23:54:00 | 6.7 | 84.0 | 280.45 | 2018 | 12 | 31 | 23 | 54 |
表 2 。以時間增量分隔為列的輸出結果
通過選擇要分析的特定時間范圍和電臺,對更新后的 DataFrame 進行實驗。
# Use the cupy.logical_and(...) function to select the data from a specific time range. import pandas as pd start_time = pd.Timestamp('2017-02-01T00') end_time = pd.Timestamp('2018-11-01T00') station_id = 84086001 gdf_period = gdf.loc[cp.logical_and(cp.logical_and(gdf['date']>start_time,gdf['date']
DataFrame 已成功準備,包含 13 個變量和 146039 行。
步驟 2. 對時間序列重新采樣
現在已經設置了 DataFrame ,運行一個簡單的重新采樣操作。盡管數據每 6 分鐘更新一次,但在這種情況下,必須對數據進行整形,使其進入日常節奏。
首先將日期設置為索引,以便其余變量隨時間調整。每 6 分鐘對樣本中的數據進行一次下采樣,每天一個記錄,每天為每個變量生成一個記錄。保留每天每個變量的最大值作為當天的記錄。
## Set "date" as the index. See what that does?
gdf_period.set_index("date", inplace=True)
## Now, resample by daylong intervals and check the max data during the resampled period.
## Use .reset_index() to reset the index instead of date.
gdf_day_max = gdf_period.resample('D').max().bfill().reset_index()
gdf_day_max.head()
數據現在以每日增量提供。請參閱該表以檢查操作是否產生了所需的結果。
| date | number_sta | lat | lon | height_sta | ff | hu | t | year | month | day | hour | mins | |
| 0 | 2017-02-01 | 84086001 | 43.81 | 5.15 | 672.0 | 8.1 | 98.0 | 283.05 | 2017 | 2 | 1 | 23 | 54 |
| 1 | 2017-02-02 | 84086001 | 43.81 | 5.15 | 672.0 | 14.1 | 98.0 | 283.85 | 2017 | 2 | 2 | 23 | 54 |
| 2 | 2017-02-03 | 84086001 | 43.81 | 5.15 | 672.0 | 10.1 | 99.0 | 281.45 | 2017 | 2 | 3 | 23 | 54 |
| 3 | 2017-02-04 | 84086001 | 43.81 | 5.15 | 672.0 | 12.5 | 99.0 | 284.35 | 2017 | 2 | 4 | 23 | 54 |
| 4 | 2017-02-05 | 84086001 | 43.81 | 5.15 | 672.0 | 7.3 | 99.0 | 280.75 | 2017 | 2 | 5 | 23 | 54 |
表 3 。下采樣數據集的前五行的輸出
步驟 3. 運行滾動窗口分析
在上一個重新采樣示例中,點是基于時間進行采樣的。但是,也可以使用滾動窗口根據頻率平滑數據。
在下面的示例中,在數據上取一個長度為三的滾動窗口。再次,保留每個變量的最大值。
# Specify the rolling window.
gdf_3d_max = gdf_day_max.rolling('3d',min_periods=1).max()
gdf_3d_max.reset_index(inplace=True)
gdf_3d_max.head()
滾動窗口可用于對數據進行去噪,并評估數據隨時間的穩定性。
| date | number_sta | lat | lon | height_sta | ff | hu | t | year | month | day | hour | mins | |
| 0 | 2017-02-01 | 84086001 | 43.81 | 5.15 | 672.0 | 8.1 | 98.0 | 283.05 | 2017 | 2 | 1 | 23 | 54 |
| 1 | 2017-02-02 | 84086001 | 43.81 | 5.15 | 672.0 | 14.1 | 98.0 | 283.85 | 2017 | 2 | 2 | 23 | 54 |
| 2 | 2017-02-03 | 84086001 | 43.81 | 5.15 | 672.0 | 14.1 | 99.0 | 283.85 | 2017 | 2 | 3 | 23 | 54 |
| 3 | 2017-02-04 | 84086001 | 43.81 | 5.15 | 672.0 | 14.1 | 99.0 | 283.35 | 2017 | 2 | 4 | 23 | 54 |
| 4 | 2017-02-05 | 84086001 | 43.81 | 5.15 | 672.0 | 12.5 | 99.0 | 283.35 | 2017 | 2 | 5 | 23 | 54 |
[體積x117]
這篇文章向您介紹了時間序列數據處理的常見步驟。雖然以天氣數據集為例,但這些步驟適用于所有形式的時間序列數據。該過程與您現在的時間序列分析代碼類似。
性能加速
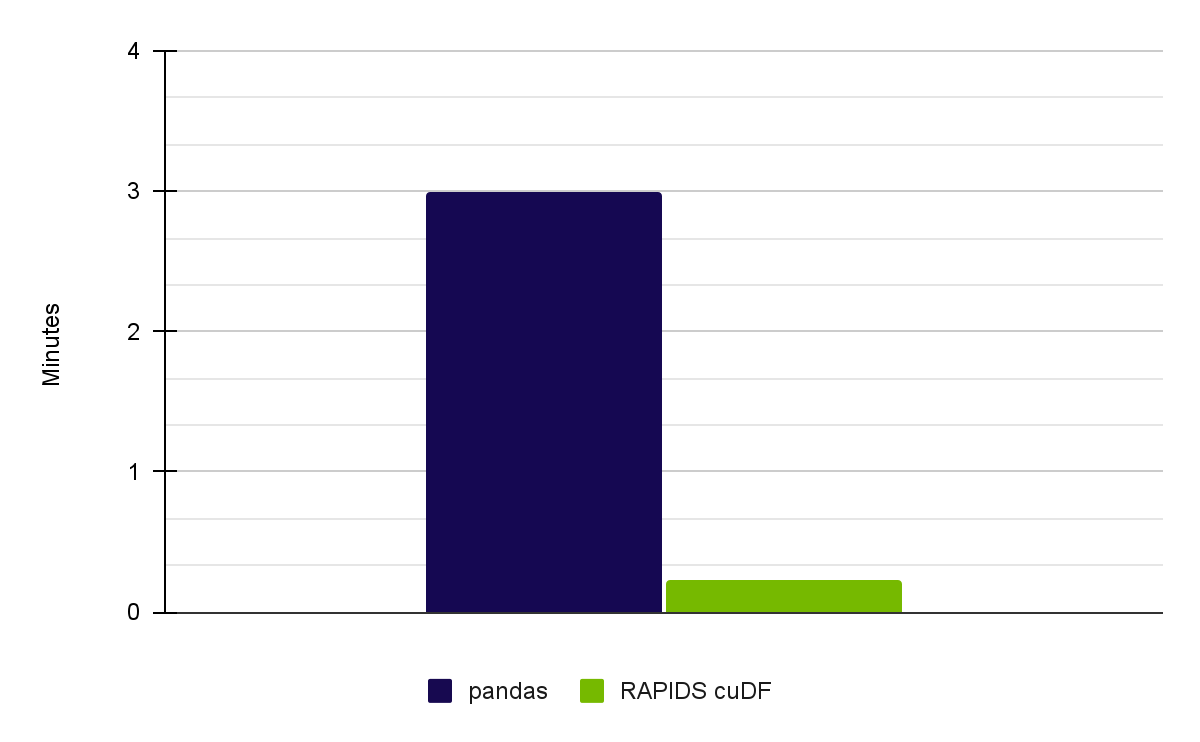
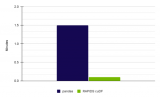
當使用 Meteonet 天氣數據集運行完整的筆記本電腦時,我們使用 RAPIDS 23.02 在 NVIDIA RTX A6000 GPU 上實現了 13 倍的加速(圖 1 )。
 [體積x118]
[體積x118]
| Pandas on CPU (Intel Core i7-7800X CPU) |
User: 2 min 32 sec Sys: 27.3 sec Total: 3 min |
| RAPIDS cuDF on NVIDIA A6000 GPUs |
User: 5.33 sec Sys: 8.67 sec Total: 14 sec |
表 5 。性能比較顯示完整筆記本電腦的 12.8 倍加速效果
主要收獲
時間序列分析是分析的核心部分,與其他變量相比,它需要額外的處理。使用 RAPIDS cuDF ,您可以更快地管理處理步驟,并使用您習慣的 pandas 功能縮短洞察時間。
-
NVIDIA
+關注
關注
14文章
5076瀏覽量
103718 -
AI
+關注
關注
87文章
31513瀏覽量
270328 -
數據分析
+關注
關注
2文章
1461瀏覽量
34164
發布評論請先 登錄
相關推薦
【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
【《時間序列與機器學習》閱讀體驗】+ 了解時間序列
【《時間序列與機器學習》閱讀體驗】+ 時間序列的信息提取
科學數據時間序列的預測方法
時間序列小波分析的操作步驟及實例分析

小波回聲狀態網絡的時間序列預測





 工商網監
工商網監
評論