") 基于SAM實(shí)現(xiàn)自動分割遙感圖像實(shí)例
基于SAM實(shí)現(xiàn)自動分割遙感圖像實(shí)例
1. 背景
借助大量的訓(xùn)練數(shù)據(jù)(SA-1B),Meta AI Research 提出的基礎(chǔ) "Segment Anything Model"(SAM)表現(xiàn)出了顯著的泛化和零樣本能力。盡管如此,SAM 表現(xiàn)為一種類別無關(guān)的實(shí)例分割方法,嚴(yán)重依賴于先驗(yàn)的手動指導(dǎo),包括點(diǎn)、框和粗略掩模。此外,SAM 在遙感圖像分割任務(wù)上的性能尚未得到充分探索和證明。
本文考慮基于 SAM 基礎(chǔ)模型設(shè)計(jì)一種自動化實(shí)例分割方法,該方法將語義類別信息納入其中,用于遙感圖像。受prompt learning啟發(fā),本文通過學(xué)習(xí)生成合適的Prompt來作為 SAM 的輸入。這使得 SAM 能夠?yàn)檫b感圖像生成語義可辨別的分割結(jié)果,該方法稱之為 RSPrompter。
本文還根據(jù) SAM 社區(qū)的最新發(fā)展提出了幾個基于SAM的實(shí)例分割衍生方法,并將它們的性能與 RSPrompter 進(jìn)行了比較。在 WHU Building、NWPU VHR-10 和 SSDD 數(shù)據(jù)集上進(jìn)行的廣泛實(shí)驗(yàn)結(jié)果驗(yàn)證了所提出的方法的有效性。
由于在超過十億個掩模上進(jìn)行訓(xùn)練,SAM 可以在不需要額外訓(xùn)練的情況下分割任何圖像中的任何對象,展示了其在處理各種圖像和對象時顯著的泛化能力。這為智能圖像分析和理解創(chuàng)建了新的可能性和途徑。然而,由于其交互式框架,SAM 需要提供先驗(yàn)的Prompt,例如點(diǎn)、框或掩模來表現(xiàn)為一種類別無關(guān)分割方法, 如下圖(a)所示。顯然,這些限制使 SAM 不適用于遙感圖像的全自動解譯。
(a)顯示了基于點(diǎn)、基于框、SAM 的“全圖”模式(對圖像中的所有對象進(jìn)行分割)以及 RSPrompter 的實(shí)例分割結(jié)果。SAM 執(zhí)行類別無關(guān)的實(shí)例分割,依賴于手動提供的先驗(yàn)prompt。(b)展示了來自不同位置的點(diǎn)prompt、基于兩個點(diǎn)的prompt和基于框的prompt的分割結(jié)果。prompt的類型、位置和數(shù)量嚴(yán)重影響 SAM 的結(jié)果。
此外,我們觀察到遙感圖像場景中的復(fù)雜背景干擾和缺乏明確定義的物體邊緣對 SAM 的分割能力構(gòu)成重大挑戰(zhàn)。SAM 很難實(shí)現(xiàn)對遙感圖像目標(biāo)的完整分割,其結(jié)果嚴(yán)重依賴于prompt類型、位置和數(shù)量。在大多數(shù)情況下,精細(xì)的手動prompt對于實(shí)現(xiàn)所需效果至關(guān)重要,如上圖(b)所示。這表明 SAM 在應(yīng)用于遙感圖像的實(shí)例分割時存在相當(dāng)大的限制。
為了增強(qiáng)基礎(chǔ)模型的遙感圖像實(shí)例分割能力,本文提出了RSPrompter,用于學(xué)習(xí)如何生成可以增強(qiáng) SAM 框架能力的prompt。本文的動機(jī)在于 SAM 框架,其中每個prompt組可以通過掩碼解碼器獲取實(shí)例化掩碼。想象一下,如果我們能夠自動生成多個與類別相關(guān)的prompt,SAM 的解碼器就能夠產(chǎn)生帶有類別標(biāo)簽的多個實(shí)例級掩碼。
然而,這個過程存在兩個主要挑戰(zhàn):(i)類別相關(guān)的prompt從哪里來?(ii)應(yīng)選擇哪種類型的prompt作為掩膜解碼器的輸入? 由于 SAM 是一種類別無關(guān)的分割模型,其編碼器的深度特征圖無法包含豐富的語義類別信息。為了克服這一障礙,我們提取編碼器的中間層特征以形成Prompter的輸入,該輸入生成包含語義類別信息的prompt。其次,SAM 的prompt包括點(diǎn)(前景/背景點(diǎn))、框或掩膜。考慮到生成點(diǎn)坐標(biāo)需要在原始 SAM prompt的流形中搜索,這嚴(yán)重限制了prompt器的優(yōu)化空間,我們進(jìn)一步放寬了prompt的表示,并直接生成prompt嵌入,可以理解為點(diǎn)或框的嵌入,而不是原始坐標(biāo)。
這種設(shè)計(jì)還避免了從高維到低維再返回到高維特征的梯度流的障礙,即從高維圖像特征到點(diǎn)坐標(biāo),然后再到位置編碼。 本文還對 SAM 模型社區(qū)中當(dāng)前進(jìn)展和衍生方法進(jìn)行了全面的調(diào)查和總結(jié)。這些主要包括基于 SAM 骨干網(wǎng)絡(luò)的方法、將 SAM 與分類器集成的方法和將 SAM 與檢測器結(jié)合的技術(shù)。
2. 方法
2.1 SAM模型
SAM 是一個交互式分割框架,它根據(jù)給定的prompt(如前景/背景點(diǎn)、邊界框或掩碼)生成分割結(jié)果。它包含三個主要組件:圖像編碼器、prompt編碼器和掩膜解碼器。SAM 使用基于 Vision Transformer (ViT)的預(yù)訓(xùn)練掩碼自編碼器將圖像處理成中間特征,并將先前的prompt編碼為嵌入Tokens。隨后,掩膜解碼器中的交叉注意力機(jī)制促進(jìn)了圖像特征和prompt嵌入之間的交互,最終產(chǎn)生掩膜輸出。該過程可以表達(dá)為: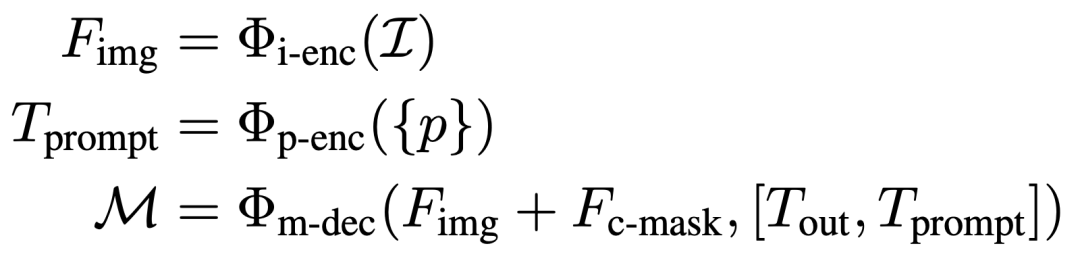
2.2 SAM 的實(shí)例分割擴(kuò)展
除了本文中提出的 RSPrompter 之外,還介紹了其他三種基于 SAM 的實(shí)例分割方法進(jìn)行比較,如下圖(a)、(b) 和 (c) 所示。本文評估了它們在遙感圖像實(shí)例分割任務(wù)中的有效性并啟發(fā)未來的研究。
這些方法包括:外部實(shí)例分割頭、分類掩碼類別和使用外部檢測器,分別稱為SAM-seg、SAM-cls 和 SAM-det。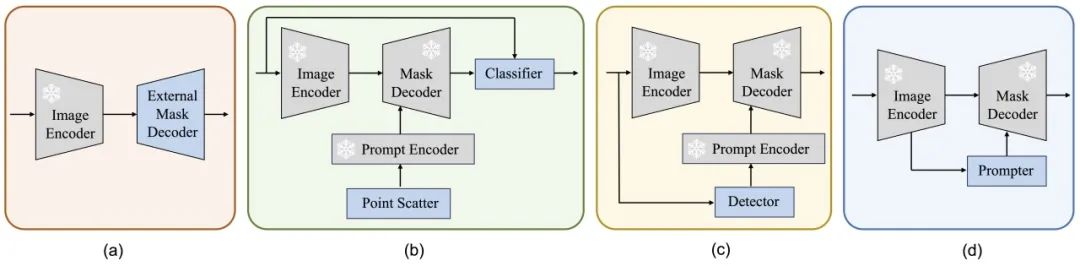
2.2.1 SAM-seg
SAM-seg利用了 SAM 圖像編碼器存在的知識,同時保持編碼器不變。它從編碼器中提取中間層特征,使用卷積塊進(jìn)行特征融合,然后使用現(xiàn)有的實(shí)例分割(Mask R-CNN和 Mask2Former)執(zhí)行實(shí)例分割任務(wù)。這個過程可以表示為:
2.2.2 SAM-cls
在 SAM-cls 中,首先利用 SAM 的“全圖像”模式來分割圖像中的所有潛在實(shí)例目標(biāo)。其實(shí)現(xiàn)方法是在整個圖像中均勻分布點(diǎn)并將每個點(diǎn)視為實(shí)例的prompt輸入。在獲得圖像中所有實(shí)例掩碼后,可以使用分類器為每個掩碼分配標(biāo)簽。這個過程可以描述如下: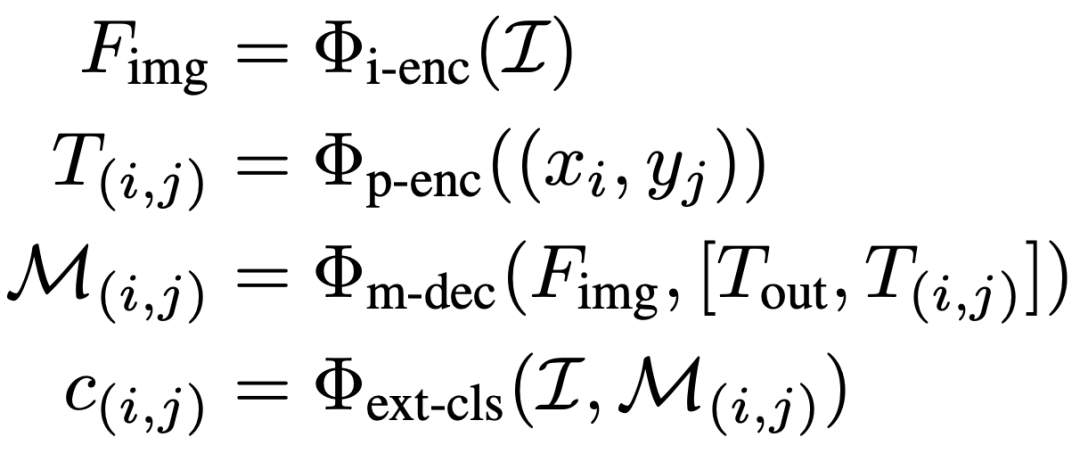
為了便捷,本文直接使用輕量級的 ResNet18 來標(biāo)記掩碼。其次,可以利用預(yù)訓(xùn)練的 CLIP 模型,使 SAM-cls 能夠在不進(jìn)行額外訓(xùn)練的情況下運(yùn)行以達(dá)到零樣本的效果
2.2.3 SAM-det
SAM-det 方法更加簡單直接,已經(jīng)被社區(qū)廣泛采用。首先訓(xùn)練一個目標(biāo)檢測器來識別圖像中所需的目標(biāo),然后將檢測到的邊界框作為prompt輸入到 SAM 中。整個過程可以描述為: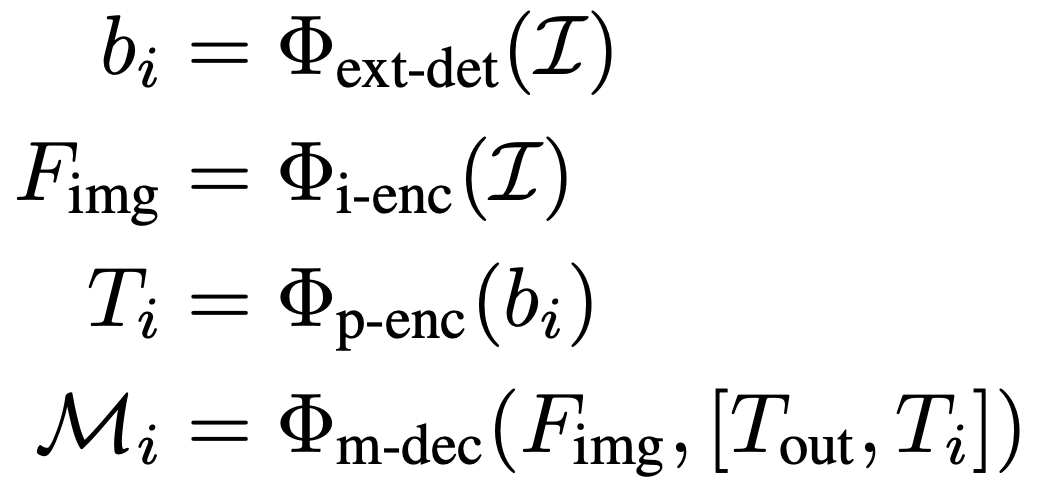
2.3 RSPrompter
2.3.1 概述
上圖(d)展示了所提出的RSPrompter的結(jié)構(gòu),我們的目標(biāo)是訓(xùn)練一個面向SAM的prompter,可以處理測試集中的任何圖像,同時定位對象,推斷它們的語義類別和實(shí)例掩碼,可以表示為以下公式: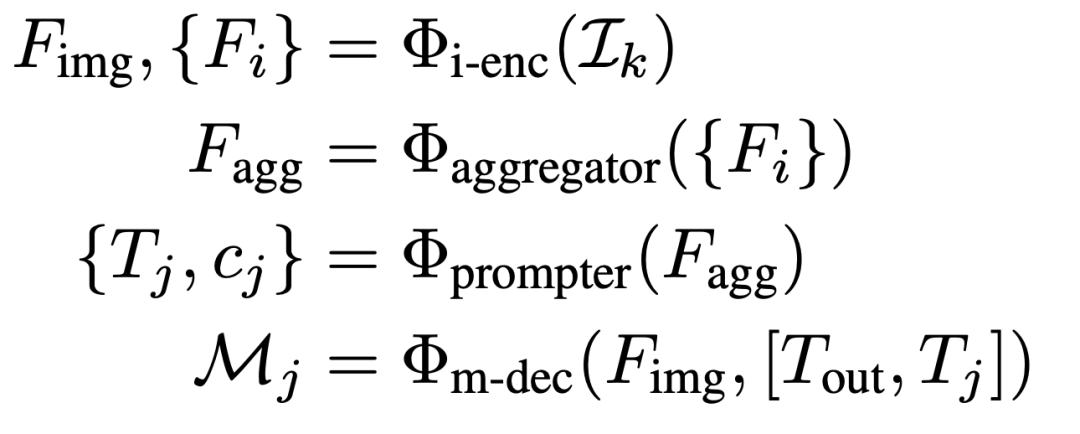
圖像通過凍結(jié)的SAM圖像編碼器處理,生成Fimg和多個中間特征圖Fi。Fimg用于SAM解碼器獲得prompt-guided掩碼,而Fi則被一個高效的特征聚合和prompt生成器逐步處理,以獲取多組prompt和相應(yīng)的語義類別。為設(shè)計(jì)prompt生成器,本文采用兩種不同的結(jié)構(gòu),即錨點(diǎn)式和查詢式。
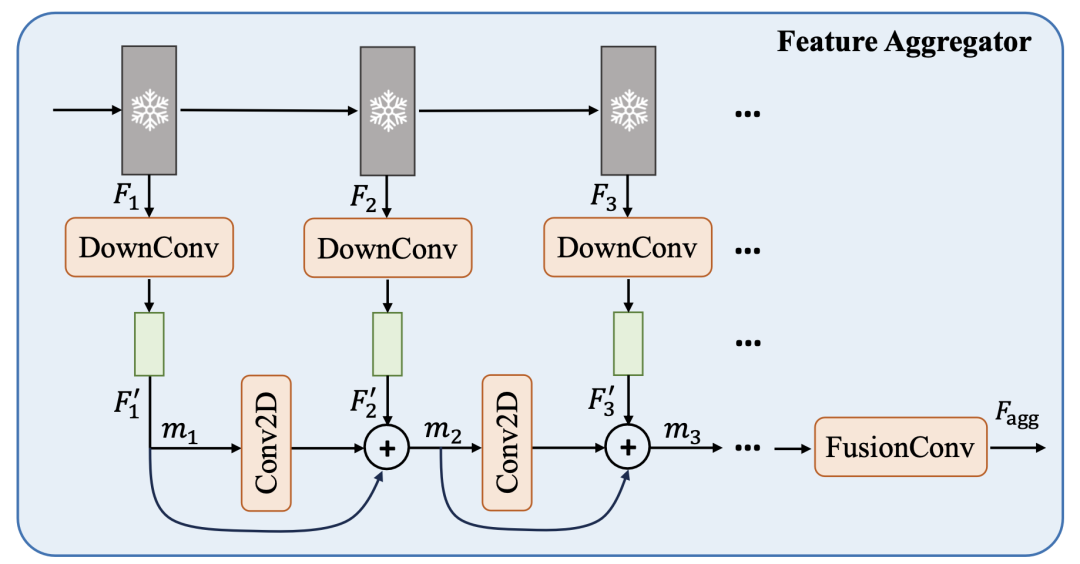
2.3.2特征聚合器
SAM是基于prompt的類別無關(guān)的分割模型,為了在不增加prompter計(jì)算復(fù)雜度的情況下獲得語義相關(guān)且具有區(qū)分性的特征,本文引入了一個輕量級的特征聚合模塊。如下圖所示,該模塊學(xué)習(xí)從SAM ViT骨干網(wǎng)絡(luò)的各種中間特征層中表示語義特征,可以遞歸地描述為: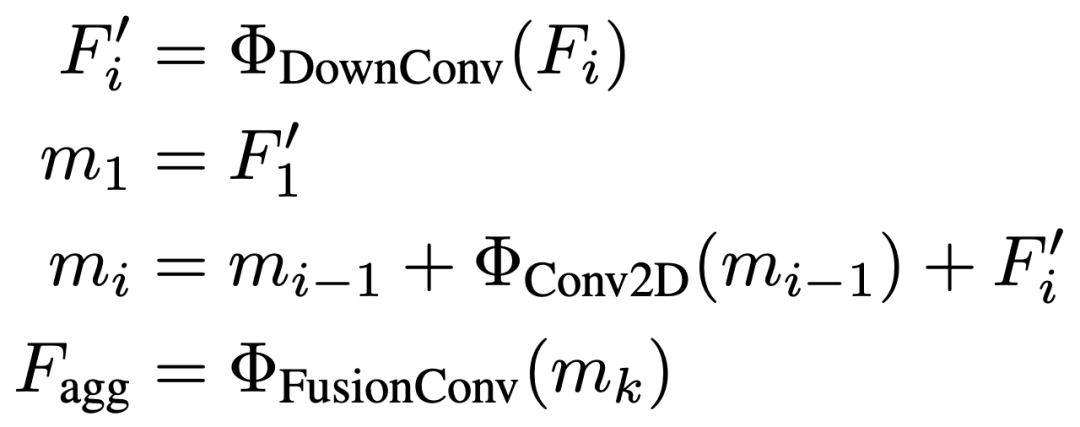
2.3.3 錨點(diǎn)式Prompter 架構(gòu):
首先使用基于錨點(diǎn)的區(qū)域提議網(wǎng)絡(luò)(RPN)生成候選目標(biāo)框。接下來,通過RoI池化獲取來自位置編碼過的特征圖的單個對象的視覺特征表示。從視覺特征中派生出三個感知頭:語義頭、定位頭和prompt頭。語義頭確定特定目標(biāo)類別,而定位頭在生成的prompt表示和目標(biāo)實(shí)例掩碼之間建立匹配準(zhǔn)則,即基于定位的貪心匹配。prompt頭生成SAM掩碼解碼器所需的prompt嵌入。整個過程如下圖所示,可以用以下公式表示: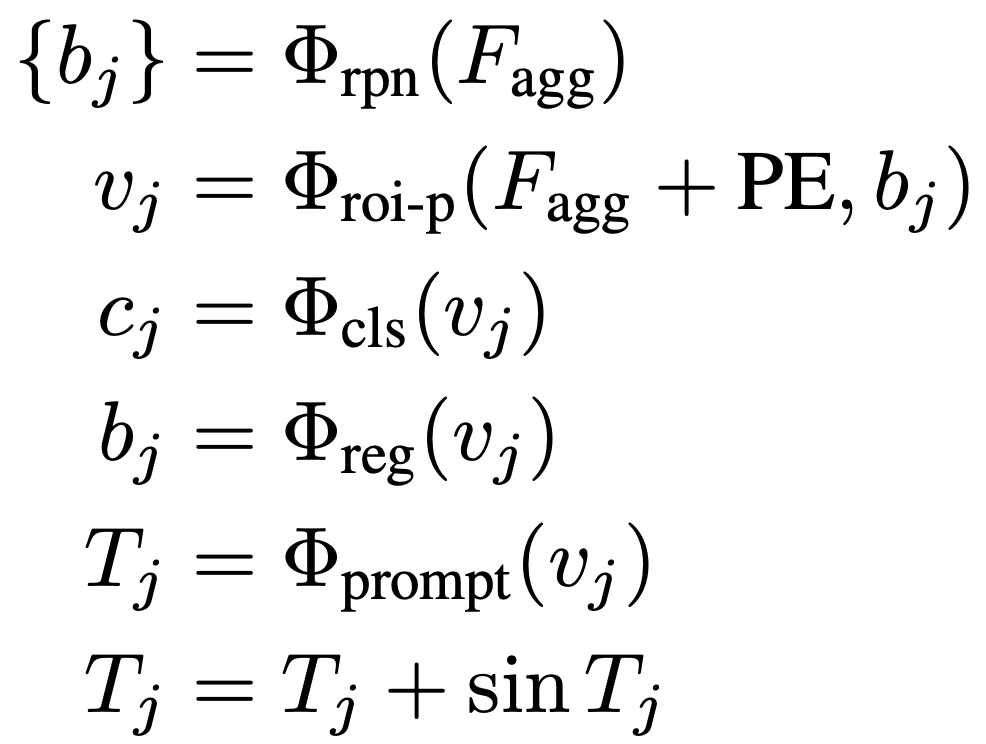
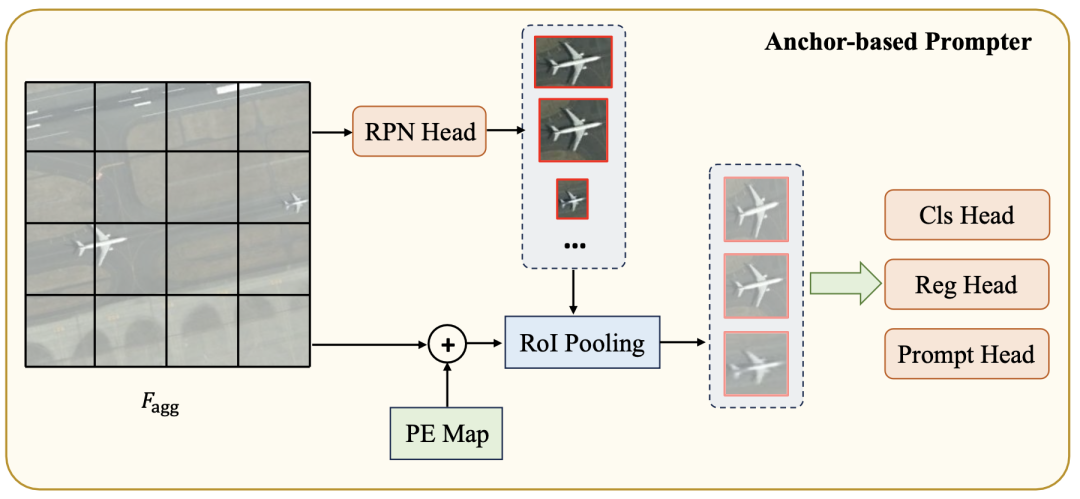
損失:該模型的損失包括RPN網(wǎng)絡(luò)的二元分類損失和定位損失,語義頭的分類損失,定位頭的回歸損失以及凍結(jié)的SAM掩碼解碼器的分割損失。總損失可以表示為: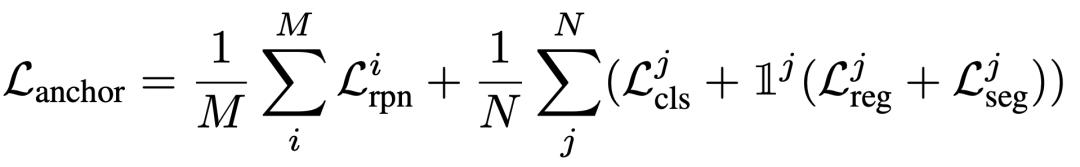
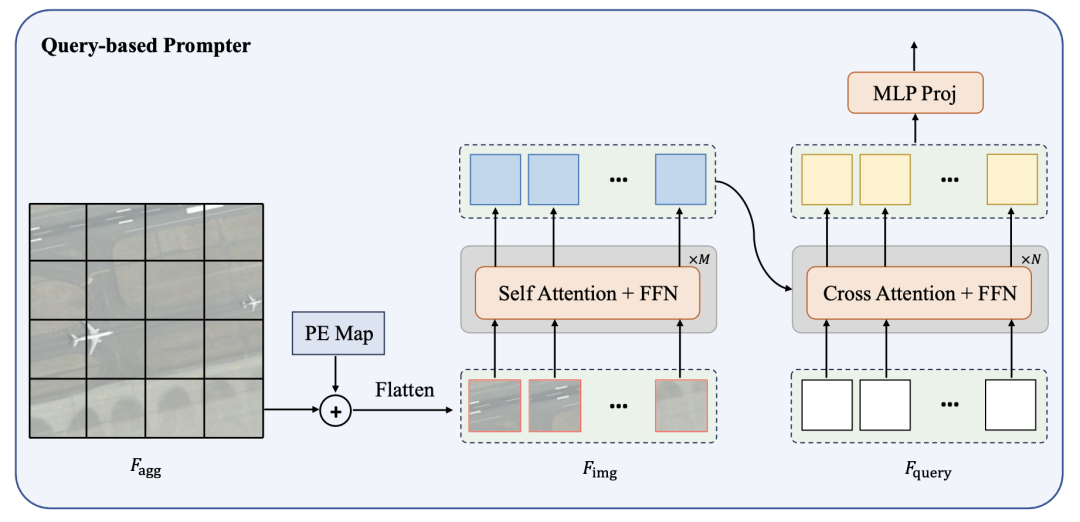
2.3.4查詢式Prompter 架構(gòu):
錨點(diǎn)式Prompter相對復(fù)雜,涉及到利用邊界框信息進(jìn)行掩碼匹配和監(jiān)督訓(xùn)練。為了簡化這個過程,提出了一個基于查詢的Prompter,它以最優(yōu)傳輸為基礎(chǔ)。查詢式Prompter主要由輕型Transformer編碼器和解碼器組成。編碼器用于從圖像中提取高級語義特征,而解碼器則通過與圖像特征進(jìn)行attention交互,將預(yù)設(shè)的可學(xué)習(xí)查詢轉(zhuǎn)換為SAM所需的prompt嵌入。整個過程如下圖所示,可以表示為: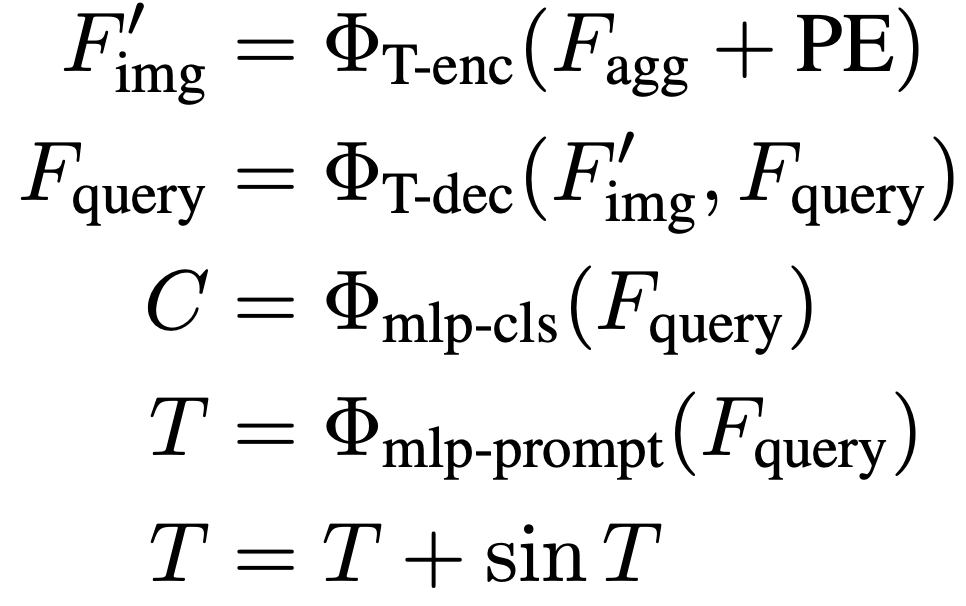
損失:查詢式Prompter的訓(xùn)練過程主要涉及兩個關(guān)鍵步驟:(i)將由SAM掩碼解碼器解碼的掩碼與真實(shí)實(shí)例掩碼進(jìn)行匹配;(ii)隨后使用匹配標(biāo)簽進(jìn)行監(jiān)督訓(xùn)練。在執(zhí)行最優(yōu)傳輸匹配時,我們定義考慮預(yù)測的類別和掩碼的匹配成本,如下所示: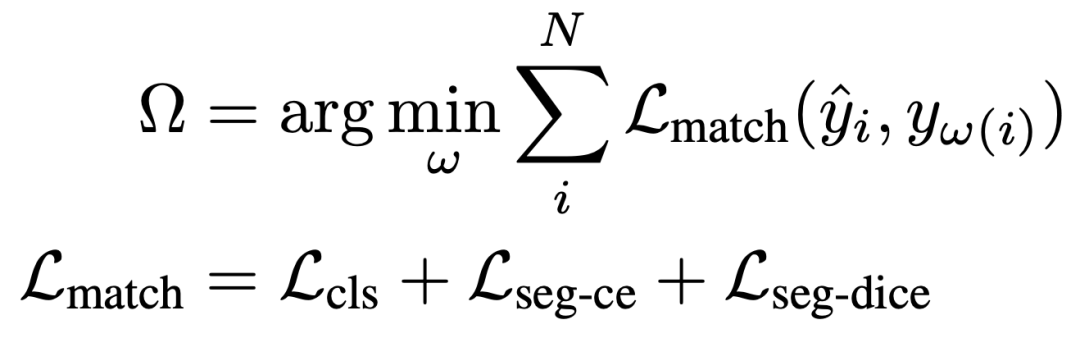
一旦每個預(yù)測實(shí)例與其相應(yīng)的真實(shí)值配對,就可以應(yīng)用監(jiān)督項(xiàng)。這主要包括多類分類和二進(jìn)制掩碼分類,如下所述: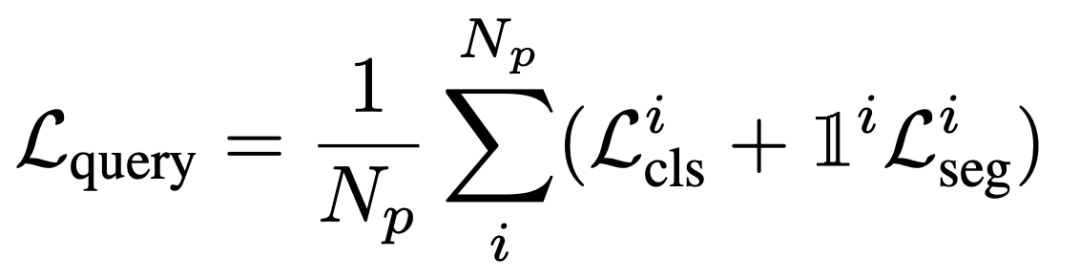
3. 實(shí)驗(yàn)
在本文中使用了三個公共的遙感實(shí)例分割數(shù)據(jù)集:WHU建筑提取數(shù)據(jù)集,NWPU VHR-10數(shù)據(jù)集和SSDD數(shù)據(jù)集。WHU數(shù)據(jù)集是單類建筑物目標(biāo)提取分割,NWPU VHR-10是多類目標(biāo)檢測分割,SSDD是SAR船只目標(biāo)檢測分割。使用 mAP 進(jìn)行模型性能評價(jià)。
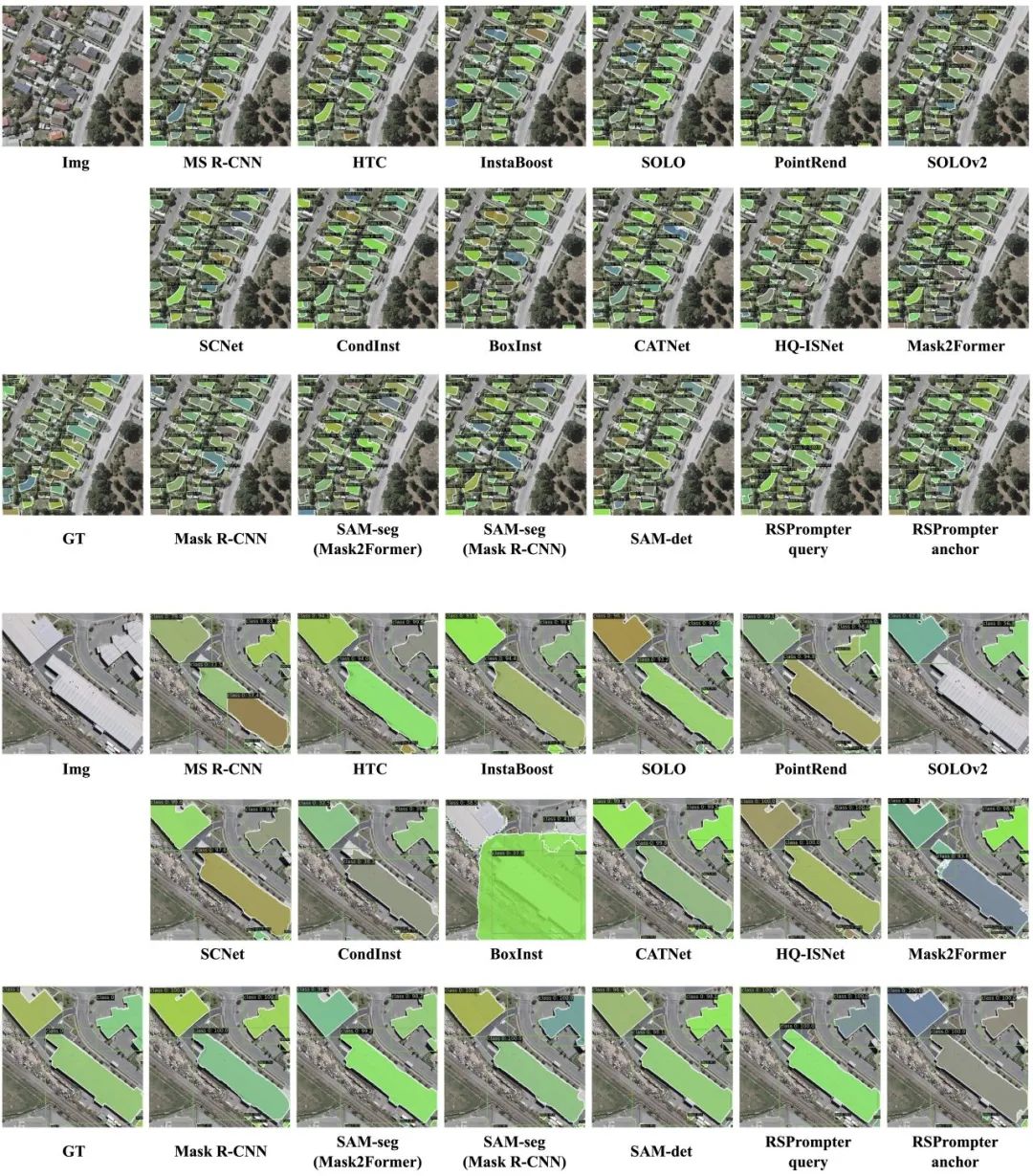
3.1 在WHU上的結(jié)果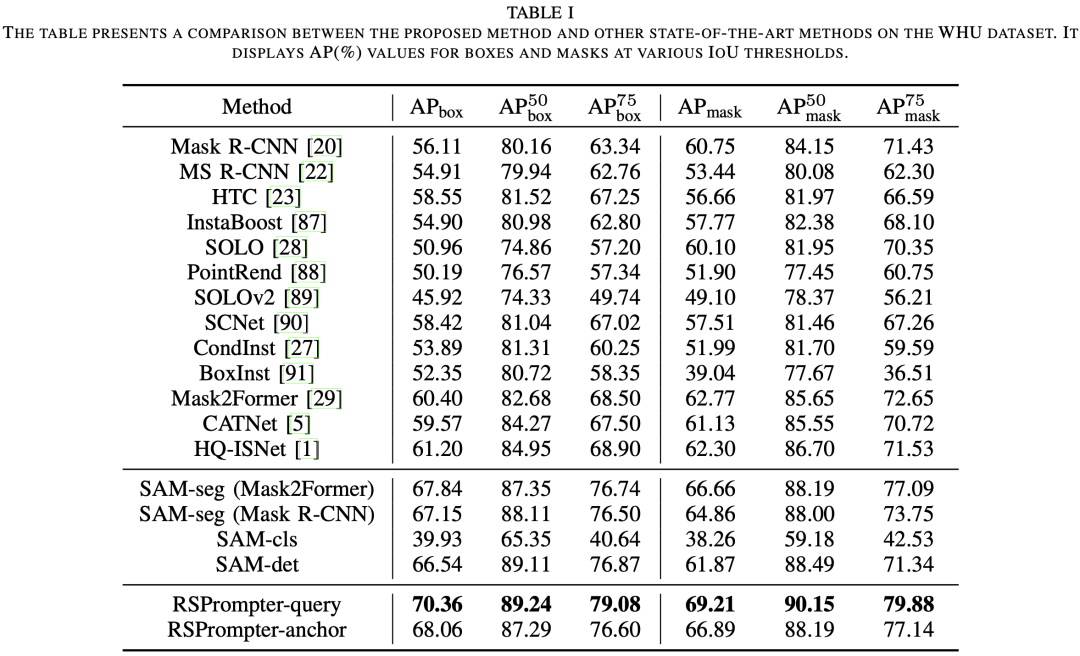
3.2 在NWPU上的結(jié)果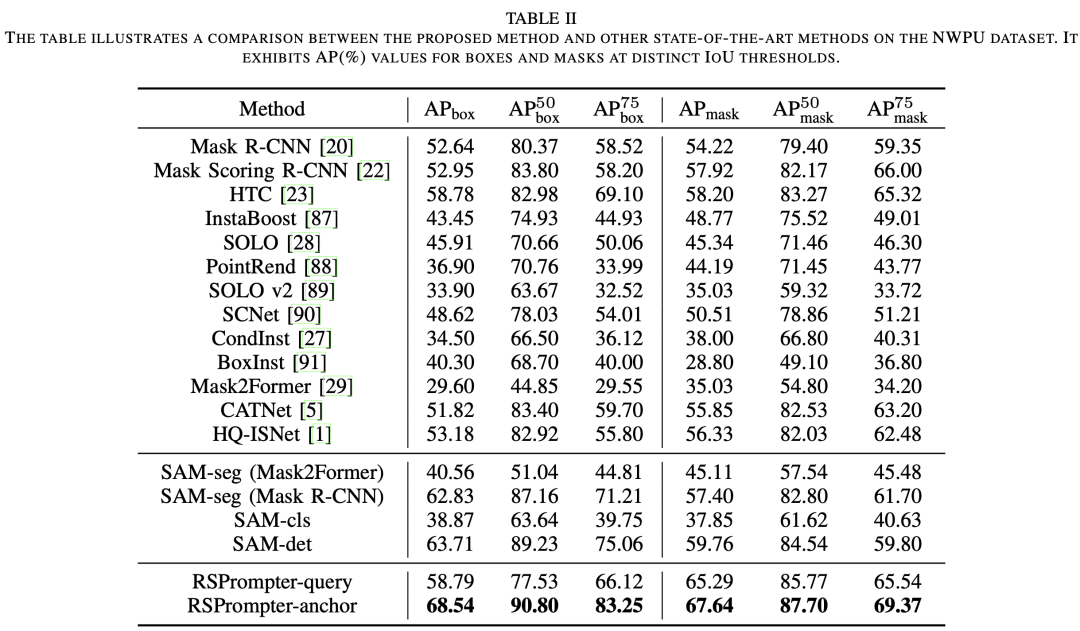

3.3 在SSDD上的結(jié)果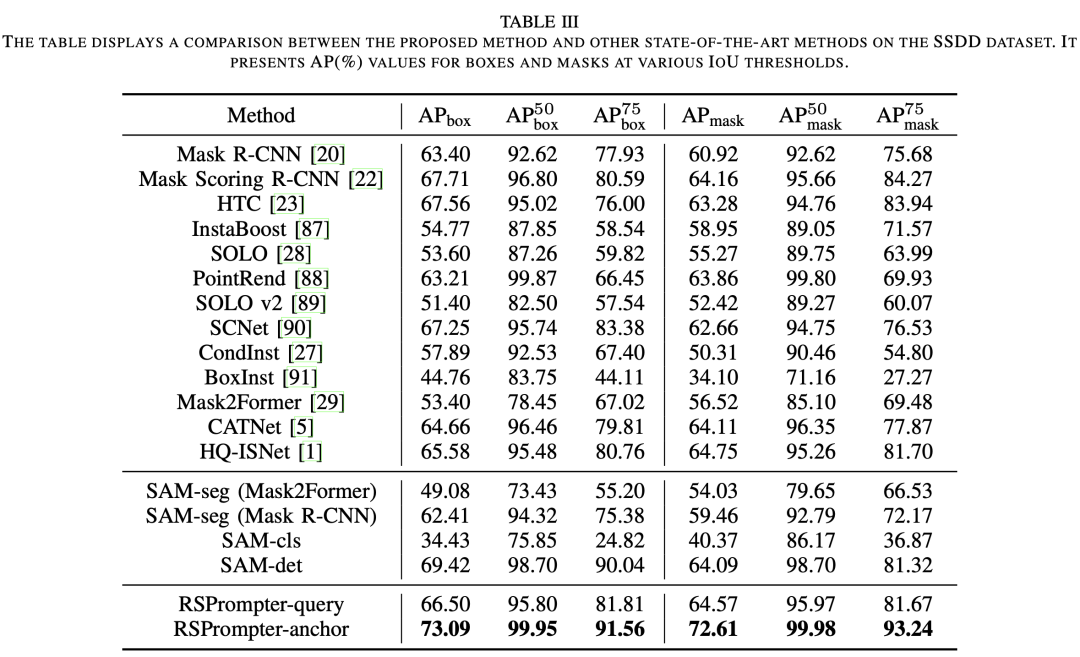

4. 總結(jié)
在本文中,我們介紹了RSPrompter,這是一種用于遙感圖像實(shí)例分割的prompt learning方法,利用了SAM基礎(chǔ)模型。RSPrompter的目標(biāo)是學(xué)習(xí)如何為SAM生成prompt輸入,使其能夠自動獲取語義實(shí)例級掩碼。相比之下,原始的SAM需要額外手動制作prompt,并且是一種類別無關(guān)的分割方法。RSPrompter的設(shè)計(jì)理念不局限于SAM模型,也可以應(yīng)用于其他基礎(chǔ)模型。
基于這一理念,我們設(shè)計(jì)了兩種具體的實(shí)現(xiàn)方案:基于預(yù)設(shè)錨點(diǎn)的RSPrompter-anchor和基于查詢和最優(yōu)傳輸匹配的RSPrompter-query。此外,我們還調(diào)查并提出了SAM社區(qū)中針對此任務(wù)的各種方法和變體,并將它們與我們的prompt learning方法進(jìn)行了比較。通過消融實(shí)驗(yàn)驗(yàn)證了RSPrompter中每個組件的有效性。同時,三個公共遙感數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果表明,我們的方法優(yōu)于其他最先進(jìn)的實(shí)例分割技術(shù),以及一些基于SAM的方法。
審核編輯:劉清
-
解碼器
+關(guān)注
關(guān)注
9文章
1147瀏覽量
40932 -
編碼器
+關(guān)注
關(guān)注
45文章
3667瀏覽量
135243 -
SAM
+關(guān)注
關(guān)注
0文章
113瀏覽量
33576 -
圖像編碼
+關(guān)注
關(guān)注
0文章
26瀏覽量
8353
原文標(biāo)題:RSPrompter:遙感圖像實(shí)例分割利器,基于SAM實(shí)現(xiàn)自動分割
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
手把手教你使用LabVIEW實(shí)現(xiàn)Mask R-CNN圖像實(shí)例分割(含源碼)
如何利用VBE標(biāo)準(zhǔn)實(shí)現(xiàn)遙感圖像實(shí)時滾動顯示?

圖像分割基礎(chǔ)算法及實(shí)現(xiàn)實(shí)例

基于U-net分割的遙感圖像配準(zhǔn)方法
什么是圖像實(shí)例分割?常見的圖像實(shí)例分割有哪幾種?

AI算法說-圖像分割

近期分割大模型發(fā)展情況

自動駕駛場景圖像分割(Unet)

SAM 到底是什么

YOLOv8最新版本支持SAM分割一切

基于SAM設(shè)計(jì)的自動化遙感圖像實(shí)例分割方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論