 基于醫學知識增強的基礎模型預訓練方法
基于醫學知識增強的基礎模型預訓練方法
近年來,基于大數據預訓練的多模態基礎模型 (Foundation Model) 在自然語言理解和視覺感知方面展現出了前所未有的進展,在各領域中受到了廣泛關注。在醫療領域中,由于其任務對領域專業知識的高度依賴和其本身細粒度的特征,通用基礎模型在醫療領域的應用十分有限。因此,如何將醫療知識注入模型,提高基礎模型在具體診療任務上的準確度與可靠性,是當前醫學人工智能研究領域的熱點。 在此背景之下,上海交通大學與上海人工智能實驗室聯合團隊探索了基于醫學知識增強的基礎模型預訓練方法,發布了首個胸部 X-ray 的基礎模型,即 KAD(Knowledge-enhanced Auto Diagnosis Model)。該模型通過在大規模醫學影像與放射報告數據進行預訓練,通過文本編碼器對高質量醫療知識圖譜進行隱空間嵌入,利用視覺 - 語言模型聯合訓練實現了知識增強的表征學習。在不需要任何額外標注情況下,KAD 模型即可直接應用于任意胸片相關疾病的診斷,為開發人工智能輔助診斷的基礎模型提供了一條切實可行的技術路線。
KAD 具有零樣本(zero-shot)診斷能力,無需下游任務微調,展現出與專業醫生相當的精度;
KAD 具有開放疾病診斷(open-set diagosis)能力,可應用于胸片相關的任意疾病診斷;
KAD 具有疾病定位能力,為模型預測提供可解釋性。
研究論文《Knowledge-enhanced Visual-Language Pre-training on Chest Radiology Images》已被知名國際期刊《自然 - 通訊》(Nature Communications)接收。論文作者為張小嫚、吳超逸、張婭教授,謝偉迪教授(通訊),王延峰教授(通訊)。
論文鏈接:https://arxiv.org/pdf/2302.14042.pdf
代碼模型鏈接:https://github.com/xiaoman-zhang/KAD
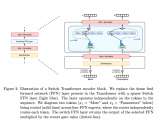
模型介紹 KAD 模型的核心是利用醫學先驗知識引導基礎模型預訓練,第一階段,該研究利用醫學知識圖譜訓練一個文本知識編碼器,對醫學知識庫在隱空間進行建模;第二階段,該研究提出放射報告中提取醫學實體和實體間關系,借助已訓練的知識編碼器來指導圖像與文本對的視覺表征學習,最終實現了知識增強的模型預訓練。具體流程如圖 1 所示。
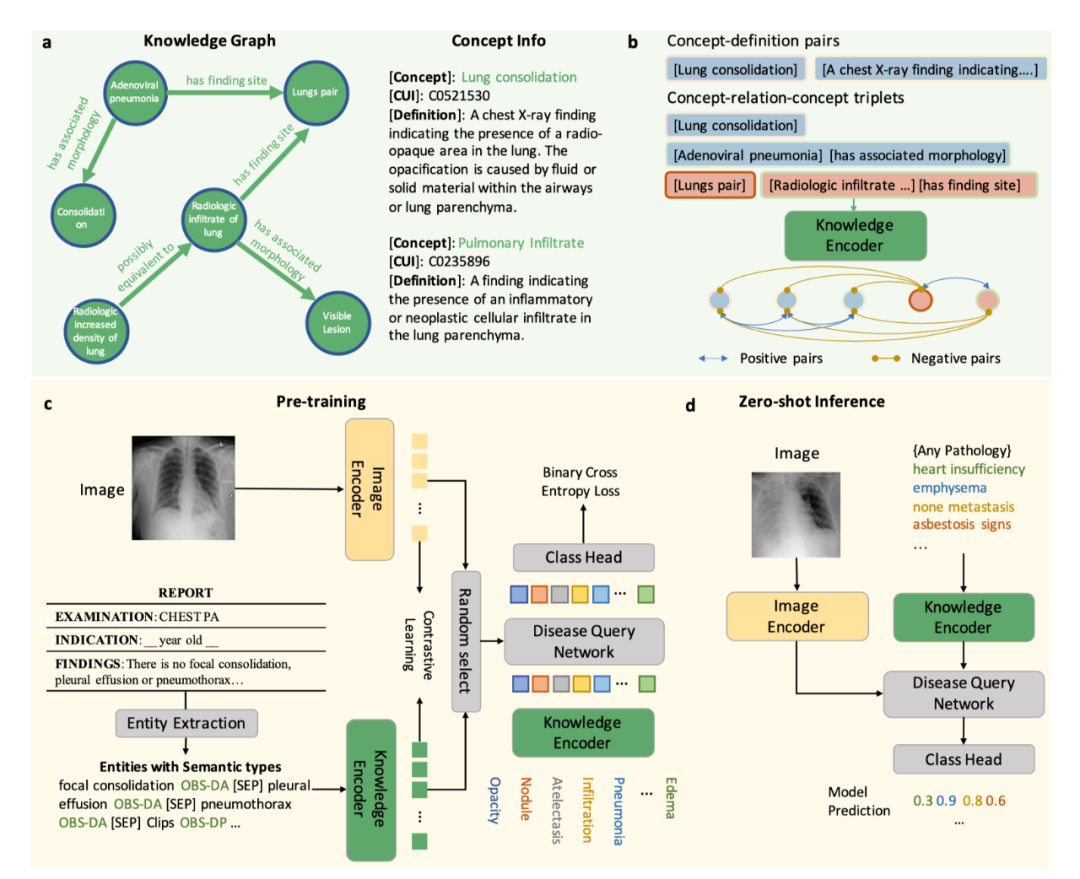
圖 1:KAD 的模型架構 知識編碼器 知識編碼器的核心是在特征空間隱式地建立醫學實體之間的關系。具體來說,該研究將統一醫學語言系統 (Unified Medical Language System,UMLS) 作為醫學知識庫,如圖 1a 所示;通過對比學習訓練文本編碼器,將醫學知識注入模型,如圖 1b 所示。 知識引導的視覺表征學習 知識編碼器訓練完成后,模型在文本特征空間已經建立了醫學實體之間的關系,即可用于引導視覺表征學習。具體來說,如圖 1c 所示,基于胸片 - 報告對的數據,首先進行實體提取,得到常見疾病的集合及其標簽,該研究嘗試了三種方法:基于 UMLS 啟發式規則的實體提取、基于報告結構化工具 RadGraph 的實體提取以及基于 ChatGPT 的實體提取;在模型層面,該研究提出了基于 Transformer 架構的疾病查詢網絡(Disease Query Networks),以疾病名稱作為查詢 (query) 輸入,關注 (attend) 視覺特征以獲得模型預測結果;在模型訓練過程中,該研究聯合優化圖像 - 文本對比學習和疾病查詢網絡預測的多標簽分類損失。 經過上述兩階段的訓練,在模型使用階段,如圖 1d 所示,給定一張圖像以及查詢的疾病名稱,分別輸入圖像編碼器和知識編碼器,經過疾病查詢網絡,即可得到查詢疾病的預測。同時可以通過疾病查詢網絡得到注意力圖對病灶進行定位,增強模型的可解釋性。 實驗結果 研究團隊將僅在 MIMIC-CXR [1] 上使用圖像和報告預訓練的 KAD 模型,在多個具有不同數據分布的公開數據集上進行了系統性評測,包括 CheXpert [2], PadChest [3], NIH ChestX-ray [4] 和 CheXDet10 [5]。MIMIC-CXR 數據收集于貝斯以色列女執事醫療中心(Beth Israel Deaconess Medical Center,BIDMC)是,CheXpert 數據收集于美國斯坦福醫院(Stanford Hospital),PadChest 數據收集于西班牙圣胡醫院(San Juan Hospital),NIH ChestX-ray 和 CheXDet10 數據來自于美國國立衛生研究院(National Institutes of Health)臨床 PACS 數據庫。 (1) KAD 零樣本診斷能力與專業放射科醫生精度相當 如圖 2 所示,該研究將預訓練的 KAD 模型在 CheXpert 數據上進行評測,在其中的五類疾病診斷任務與放射科醫生進行了比較,圖中 Radiologists 表示三名放射科醫生的平均結果。KAD 在五類疾病診斷任務上的平均 MCC 超過了 Radiologists,且在其中三類疾病的診斷結果顯著優于放射科醫生,肺不張 atelectasis (KAD 0.613 (95% CI 0.567, 0.659) vs. Radiologists 0.548);肺水腫 edema (KAD 0.666 (95% CI 0.608, 0.724) vs. Radiologists 0.507);胸腔積液 pleural effusion (KAD 0.702 (95% CI 0.653, 0.751) vs. Radiologists 0.548)。該結果證實了基于知識增強的模型預訓練的有效性。
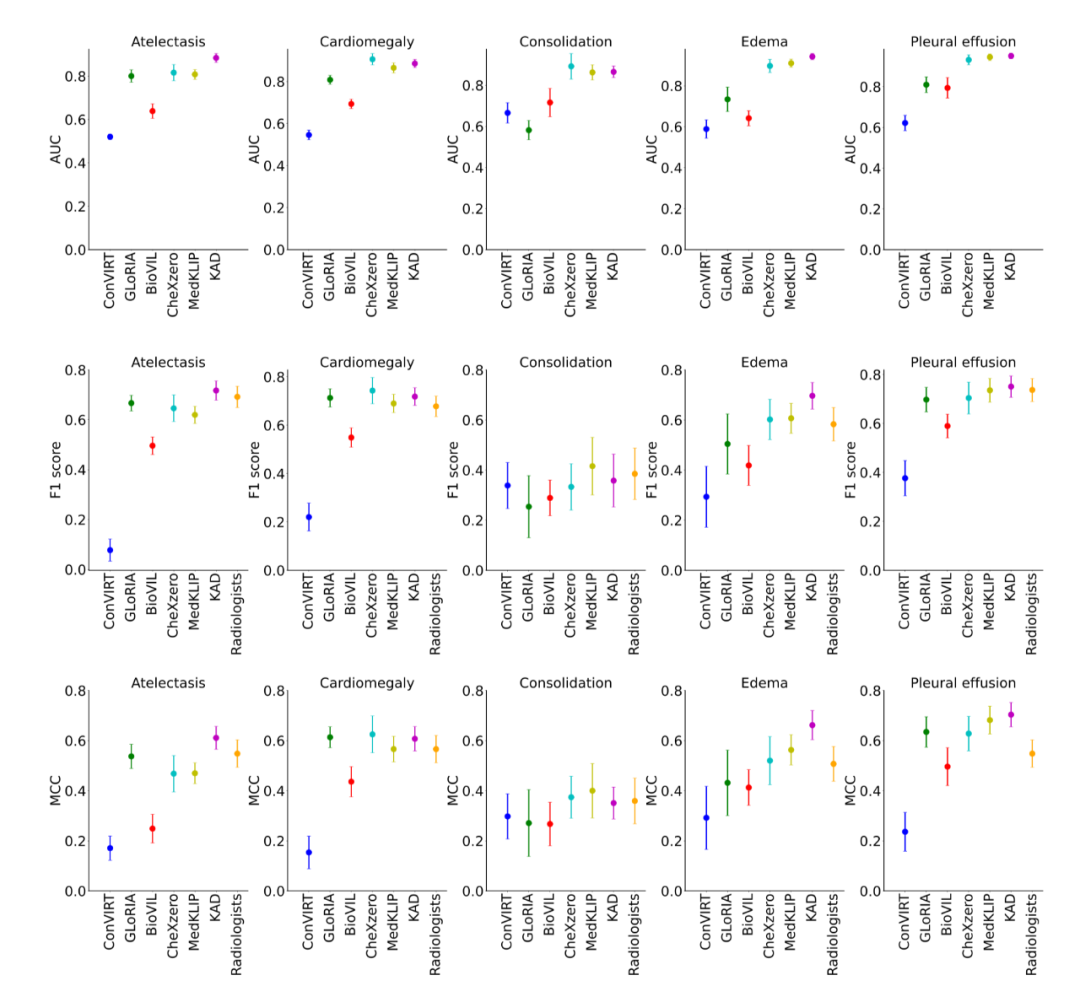
圖 2:KAD 在 CheXpert 數據集上與基線模型以及放射科醫生的比較 (2) KAD 零樣本診斷能力與全監督模型相當,支持開放集疾病診斷 如圖 3a 所示,在 PadChest 上的零樣本診斷性能大幅度超越此前所有多模態預訓練模型(例如 Microsoft 發布的 BioVIL [6],Stanford 發布的 CheXzero [7]),與全監督模型 (CheXNet [8]) 相當。此外,全監督的模型的應用范圍受限于封閉的訓練類別集合,而 KAD 可以支持任意的疾病輸入,在 PadChest 的 177 個未見類別的測試中,有 31 類 AUC 達到 0.900 以上,111 類 AUC 達到 0.700 以上,如圖 3b 所示。
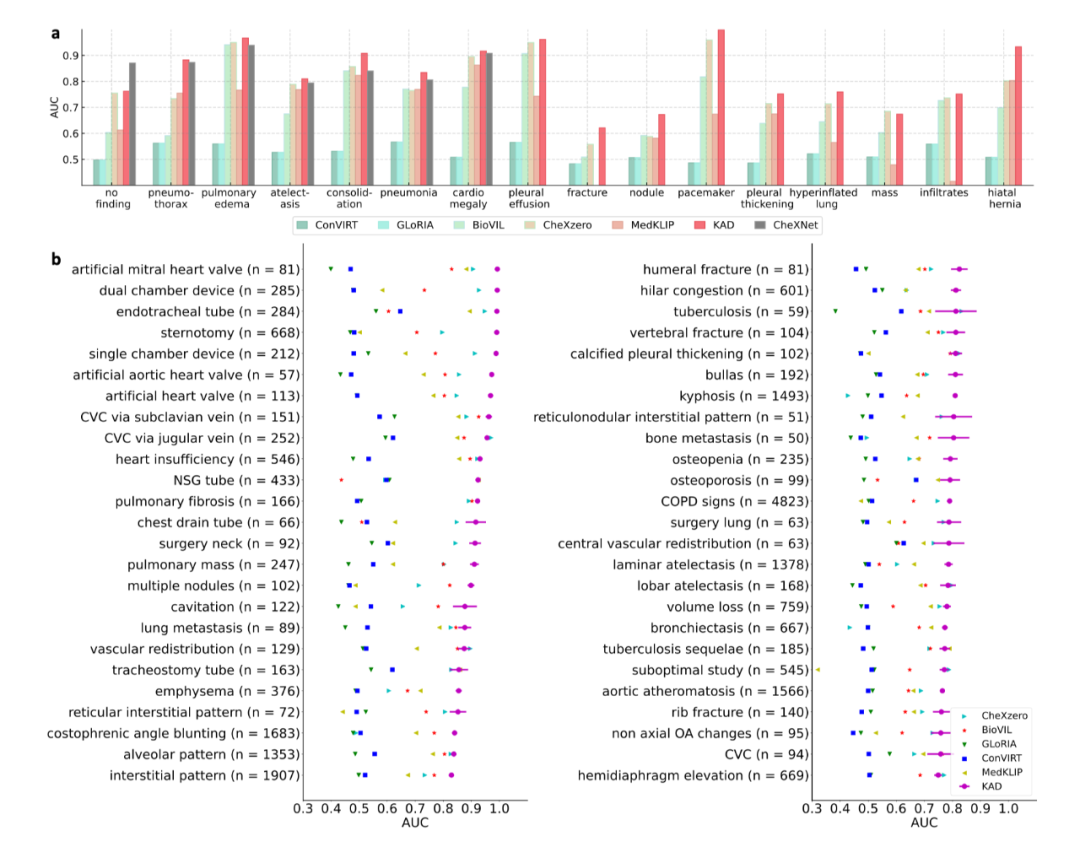
圖 3:KAD 在 PadChest 數據集上與基線模型的比較 (3) KAD 具有疾病定位能力,為模型預測提供可解釋性 除了自動診斷能力,可解釋性在人工智能輔助醫療的作用同樣關鍵,能夠有效幫助臨床醫生理解人工智能算法的判斷依據。在 ChestXDet10 數據集上對 KAD 的定位能力進行了定量分析與定性分析。如圖 4 所示,KAD 的定位能力顯著優于基線模型。圖 5 中,紅色方框為放射科醫生提供的標注,高亮區域為模型的熱力圖,從中可以看出模型所關注的區域往往能與醫生標注區域對應上,隨著輸入圖像的分辨率增加,模型的定位能力也顯著增強。 需要強調 這是模型設計的優勢,是在無需人工病灶區域標注情況下獲得的副產品。
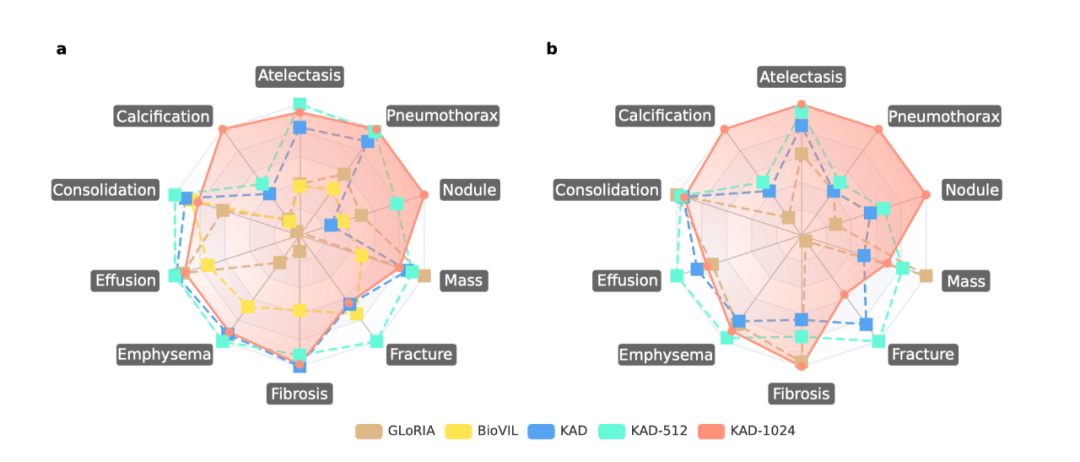
圖 4: KAD 在 ChestXDet10 數據集上與基線模型的比較
圖 5:KAD 的定位結果可視化 總結 醫療領域的專業性,導致通用基礎模型在真實臨床診療場景下的應用十分受限。KAD 模型的提出為基于知識增強的基礎模型預訓練提供了切實可行的解決方案。KAD 的訓練框架只需要影像 - 報告數據,不依賴于人工注釋,在下游胸部 X-ray 診斷任務上,無需任何監督微調,即達到與專業放射科醫生相當的精度;支持開放集疾病診斷任務,同時以注意力圖形式提供對病灶的位置定位,增強模型的可解釋性。值得注意的是,該研究提出的基于知識增強的表征學習方法不局限于胸部 X-ray,期待其能夠進一步遷移到醫療中不同的器官、模態上,促進醫療基礎模型在臨床的應用和落地。
-
編碼器
+關注
關注
45文章
3667瀏覽量
135243 -
模型
+關注
關注
1文章
3305瀏覽量
49221 -
大數據
+關注
關注
64文章
8908瀏覽量
137791
原文標題:Nature子刊!上海交大&上海AI Lab提出胸部X-ray疾病診斷基礎模型
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文詳解知識增強的語言預訓練模型
【大語言模型:原理與工程實踐】大語言模型的預訓練
微軟在ICML 2019上提出了一個全新的通用預訓練方法MASS

新的預訓練方法——MASS!MASS預訓練幾大優勢!

檢索增強型語言表征模型預訓練
一種側重于學習情感特征的預訓練方法


利用視覺語言模型對檢測器進行預訓練
介紹幾篇EMNLP'22的語言模型訓練方法優化工作
基礎模型自監督預訓練的數據之謎:大量數據究竟是福還是禍?

基于生成模型的預訓練方法

混合專家模型 (MoE)核心組件和訓練方法介紹





 工商網監
工商網監
評論