") Poly在深度學(xué)習(xí)領(lǐng)域中發(fā)揮的作用
Poly在深度學(xué)習(xí)領(lǐng)域中發(fā)揮的作用
從對上層應(yīng)用的約束角度來看,作為一種通用程序設(shè)計(jì)語言的編譯優(yōu)化模型,Poly本身對應(yīng)用是敏感的,只能處理滿足一定約束條件的、規(guī)則的應(yīng)用。Poly要求被分析的應(yīng)用中,循環(huán)邊界、數(shù)組下標(biāo)都是仿射表達(dá)式,而且控制流必須是靜態(tài)可判定的,我們暫且把這種對應(yīng)用的要求稱為靜態(tài)仿射約束。實(shí)際上,對于通用語言而言,靜態(tài)仿射約束的限制對程序的要求不算低,但是深度學(xué)習(xí)領(lǐng)域的大部分核心計(jì)算卻恰好滿足這種靜態(tài)仿射約束,所以許多深度學(xué)習(xí)編譯軟件棧利用Poly來實(shí)現(xiàn)循環(huán)優(yōu)化。
而從充分發(fā)揮底層AI芯片架構(gòu)的能力角度來講,Poly也非常適合,這得益于Poly能夠自動判定和實(shí)現(xiàn)上層應(yīng)用中循環(huán)的tiling/blocking(分塊)變換并自動將軟件循環(huán)映射到并行硬件上。本系列文章第一篇中圖12和圖13就是Poly在GPU上自動實(shí)現(xiàn)分塊并將分塊后對應(yīng)的循環(huán)維度映射到GPU的線程塊和線程兩級并行硬件抽象上的實(shí)例。
為什么Poly需要自動實(shí)現(xiàn)分塊?這是由底層AI芯片的架構(gòu)導(dǎo)致的。以GPU為例,圖14[15]所示是GPU的架構(gòu)示意圖。每個GPU上擁有自己的全局緩存(Global/Device Memory),然后每個線程塊也有自己的局部緩存(Shared/Local Memory)。緩存越靠近計(jì)算單元,訪存的速度越快,但是緩存空間越小。因此,當(dāng)計(jì)算數(shù)據(jù)量大于緩存空間的時候,就需要通過將原來的數(shù)據(jù)進(jìn)行分塊的方式存儲到緩存上,以此來適應(yīng)目標(biāo)架構(gòu)的硬件特征。
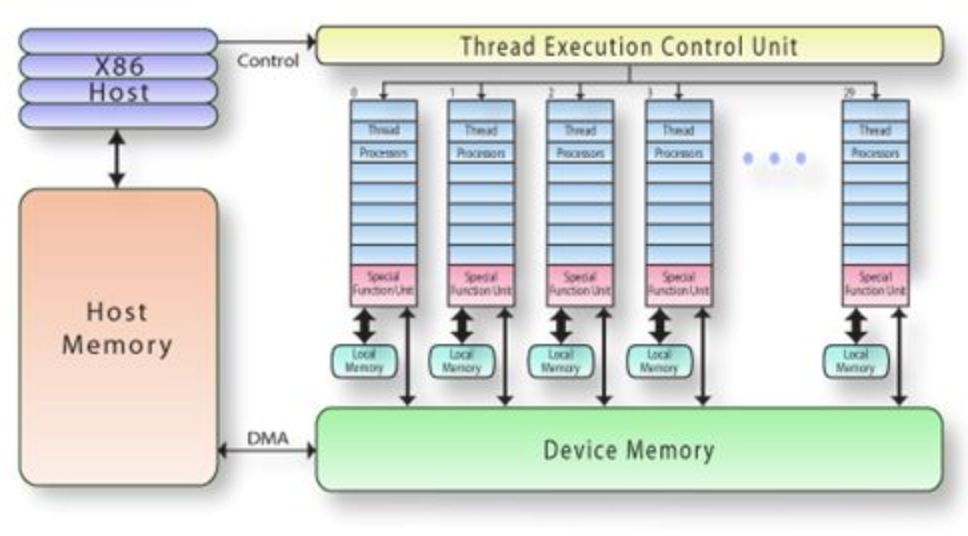
圖14 GPU架構(gòu)示意圖
而專用AI芯片的架構(gòu)可能更復(fù)雜,如圖15[16]所示是TPU v2和TPU v3的架構(gòu)示意圖,每個TPU有多種不同類型的計(jì)算單元,包括標(biāo)量、向量以及矩陣計(jì)算單元,這些不同的計(jì)算單元對應(yīng)地可能會有各自不同的緩存空間,這就給分塊提出了更高的要求。只有通過對應(yīng)用的正確分塊才能充分利用好芯片上的架構(gòu)特征。
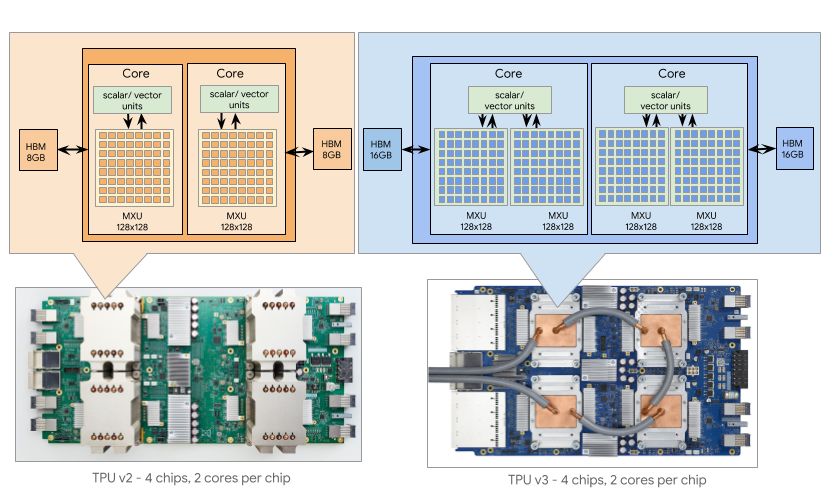
圖15 TPU架構(gòu)示意圖
當(dāng)前一部分深度學(xué)習(xí)編譯軟件棧采用了手工調(diào)度和映射的方式來將上層應(yīng)用部署到底層芯片上。以TVM為例,圖16[17]中給出了一個TVM的調(diào)度示例。其中,調(diào)度過程首先將計(jì)算s進(jìn)行分塊(對應(yīng)圖16中的split操作),然后將分塊后的維度映射到GPU的線程塊和線程上(對應(yīng)圖16中的bind操作)。

圖16 TVM調(diào)度示例
這部分工作需要由熟悉底層芯片架構(gòu)的人員來編寫,并且要人工分析分塊的合法性,映射也需要手工完成。而Poly的作用就是將上述手工調(diào)度的過程自動實(shí)現(xiàn)。為了實(shí)現(xiàn)自動調(diào)度,許多深度學(xué)習(xí)編譯軟件棧開始采用Poly來實(shí)現(xiàn)上述功能。那么,Poly在深度學(xué)習(xí)軟件棧上發(fā)揮的作用如何呢?
首先,Poly能夠計(jì)算精確的數(shù)據(jù)流信息。Poly通過將傳統(tǒng)的編譯器中語句之間的依賴關(guān)系細(xì)化到語句實(shí)例的粒度,分析的結(jié)果比傳統(tǒng)的方法更精確。計(jì)算精確的數(shù)據(jù)流信息有以下三點(diǎn)好處。
1.計(jì)算精確的緩存搬移數(shù)據(jù)量。Poly不僅能自動計(jì)算出從管理核心(如CPU)到加速芯片(如GPU)之間傳輸?shù)臄?shù)據(jù)總量,還負(fù)責(zé)計(jì)算加速芯片上多級緩存之間的數(shù)據(jù)搬移總量,例如從GPU的global memory到shared memory上的數(shù)據(jù)搬移。“存儲墻”問題給我們揭示了一個道理:數(shù)據(jù)搬移是程序性能提升的關(guān)鍵,尤其是現(xiàn)在市場上越來越復(fù)雜的多級緩存架構(gòu)上,數(shù)據(jù)總量計(jì)算是否精確對程序性能的影響更加明顯。
2.降低內(nèi)存空間使用。通過計(jì)算精確的數(shù)據(jù)流信息,Poly可以計(jì)算出臨時tensor變量,這些臨時變量的聲明可在對應(yīng)的緩存級別上實(shí)現(xiàn),從而降低加速芯片上數(shù)據(jù)的訪存開銷。例如,圖9所示的代碼段中,tensor b就可以看作是一個臨時tensor變量。
3.自動實(shí)現(xiàn)緩存上的數(shù)據(jù)部署。以華為剛公布的昇騰AI處理器芯片為例,如圖17[18]是該芯片的AI Core架構(gòu)示意圖。其中,UnifiedBuffer(輸出緩沖區(qū))和L1 Buffer(輸入緩沖區(qū))是低級緩存,離計(jì)算單元較遠(yuǎn);BufferA L0/B L0/C L0是高級緩存,靠近計(jì)算單元。在低級緩存上,Poly可以借助標(biāo)記節(jié)點(diǎn),將不同計(jì)算單元所需的數(shù)據(jù)分別流向UnifiedBuffer和L1 Buffer;同時,當(dāng)數(shù)據(jù)到達(dá)高級緩存時,Poly仍然可以借助標(biāo)記節(jié)點(diǎn)將數(shù)據(jù)自動部署到BufferA L0/B L0/C L0。(注:這里描述的是如何通過Poly來實(shí)現(xiàn)這樣的數(shù)據(jù)分流,只是為了說明Poly能夠?qū)崿F(xiàn)這樣的自動數(shù)據(jù)部署功能,與具體實(shí)現(xiàn)無關(guān)。至于昇騰AI處理器芯片的編譯團(tuán)隊(duì)是否使用了Poly,或者是否使用了這種方法來實(shí)現(xiàn)數(shù)據(jù)的自動部署還請以官方公布為準(zhǔn)。)
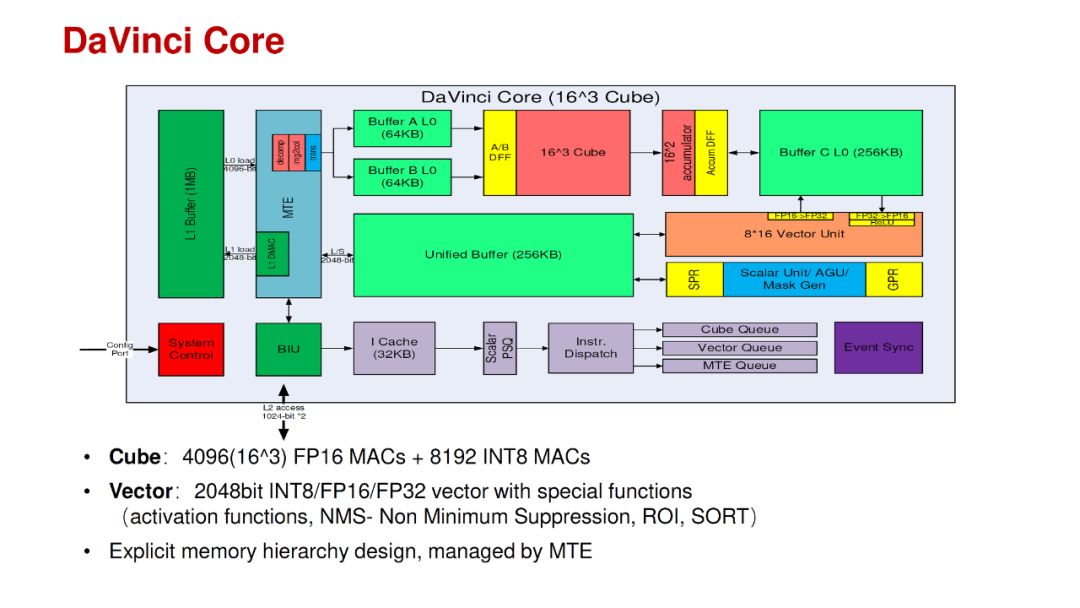
圖17 昇騰AI處理器的DaVinci Core架構(gòu)示意圖
其次,Poly能夠?qū)崿F(xiàn)幾乎全部的循環(huán)變換。Poly通過仿射函數(shù)來實(shí)現(xiàn)幾乎所有循環(huán)變換及其組合,這種仿射函數(shù)的計(jì)算過程不僅要考慮應(yīng)用程序的并行性和局部性,還要考慮底層加速芯片的硬件特征。從循環(huán)變換角度來講,Poly對編譯軟件棧的貢獻(xiàn)包括以下幾個方面。
1.Poly中的調(diào)度算法[19-22]能夠根據(jù)依賴關(guān)系分析的結(jié)果自動計(jì)算出變換后循環(huán)的并行性、循環(huán)維度是否可以實(shí)施分塊等特征,這些特征為后面硬件上的計(jì)算任務(wù)分配、緩存上的循環(huán)變換提供了理論依據(jù)。(這些信息保存在band節(jié)點(diǎn)(下面會介紹)的屬性中)而部分循環(huán)變換如skewing/shifting(傾斜/偏移)、interchange(交換)等都可以在調(diào)度階段自動完成。我們?nèi)匀灰詧D9中所示的例子來說明。對于圖10生成的代碼,Poly計(jì)算出來的調(diào)度用其中間表示(schedule tree)[23]后得到的結(jié)果如圖18所示,而圖11生成的代碼對應(yīng)的調(diào)度如圖19所示。(注:為方便說明,這里的schedule tree可能和實(shí)際在Poly中使用的有所不同,我們只是為了更直觀地表示schedule tree的表示方式。)其中,domain節(jié)點(diǎn)包含所有的語句實(shí)例集合,sequence節(jié)點(diǎn)表示其子節(jié)點(diǎn)按序執(zhí)行,而“[]”包含的節(jié)點(diǎn)稱為band節(jié)點(diǎn),可以想象成循環(huán)。
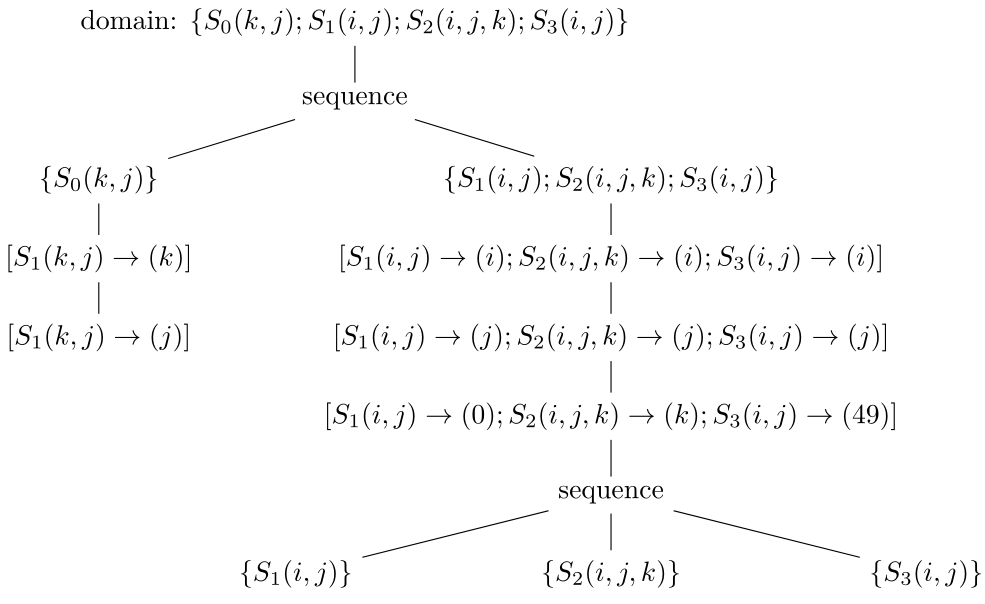
圖18 圖10對應(yīng)的schedule tree表示
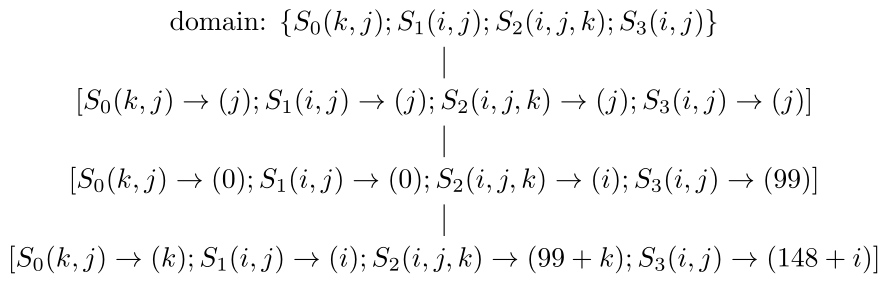
圖19 圖11對應(yīng)的schedule tree表示
2.自動實(shí)現(xiàn)深度學(xué)習(xí)應(yīng)用中最關(guān)鍵的tiling/blocking(分塊)和fusion(合并)變換。分塊的目的是為了充分利用加速芯片上的緩存,而合并的目的是為了生成更多的臨時緩存變量,降低訪存開銷。而且,Poly通過數(shù)學(xué)變換,能夠自動實(shí)現(xiàn)更復(fù)雜的、手工難以實(shí)現(xiàn)的分塊形狀[6, 24-26]。其中,合并可根據(jù)調(diào)度選項(xiàng)在調(diào)度變換過程實(shí)現(xiàn),分塊則是在調(diào)度變換之后根據(jù)循環(huán)維度是否可分塊等特征來實(shí)現(xiàn)。如圖18和19就是根據(jù)不同的編譯選項(xiàng)實(shí)現(xiàn)的合并策略對應(yīng)的schedule tree,其中合并已經(jīng)通過sequence節(jié)點(diǎn)實(shí)現(xiàn),而分塊的實(shí)現(xiàn)在Poly上很簡單,只需要將band節(jié)點(diǎn)中的仿射函數(shù)進(jìn)行修改就可以得到分塊對應(yīng)的schedule tree。如圖20是圖18經(jīng)過分塊之后的調(diào)度樹,圖19的分塊也可以同樣的方式得到,我們就不再贅述了。
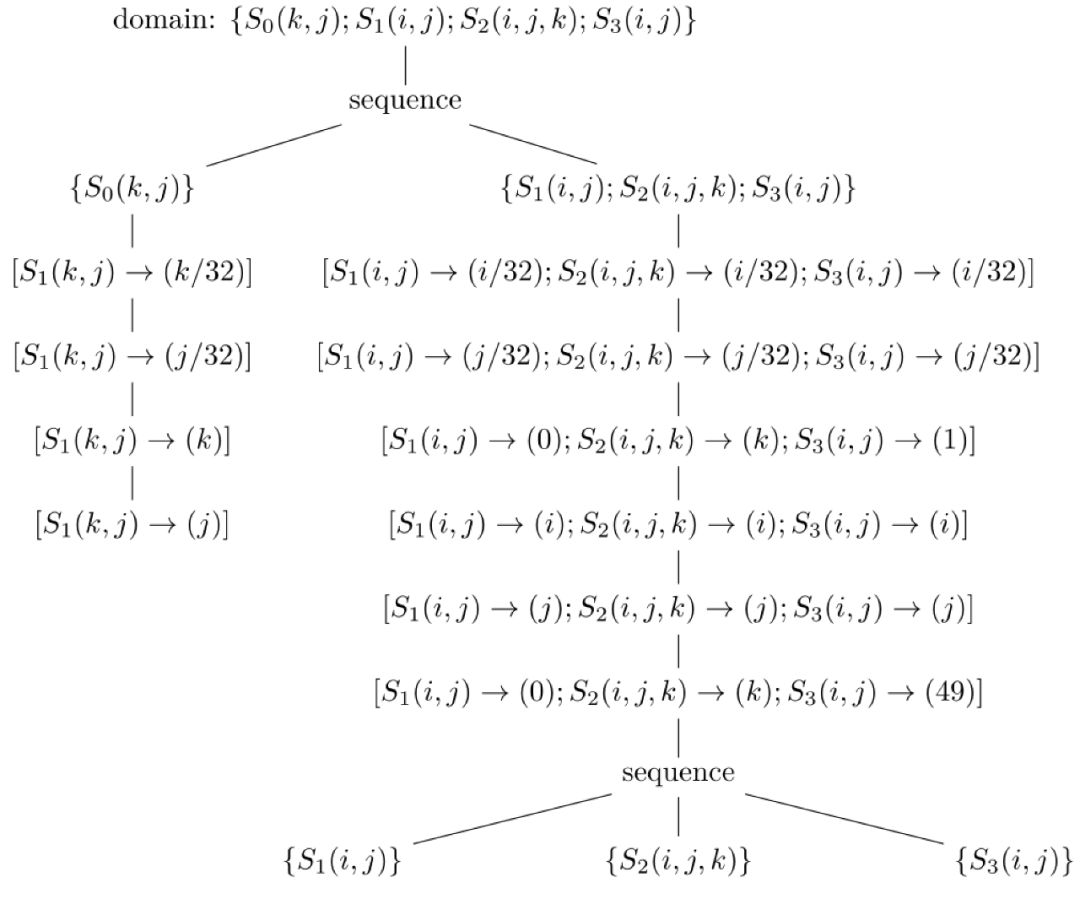
圖20 圖18分塊之后的schedule tree
3.通過代碼生成方式自動實(shí)現(xiàn)不改變語句順序、但只改變循環(huán)結(jié)構(gòu)的變換。這類循環(huán)變換包括peeling(剝離)、unrolling(展開)等。因?yàn)檫@些循環(huán)變換不改變語句的執(zhí)行順序,而只是對循環(huán)的結(jié)構(gòu)進(jìn)行修改來實(shí)現(xiàn)。這些循環(huán)變換對特殊加速芯片上的代碼生成有十分重要的作用,例如一些架構(gòu)可能并不喜歡循環(huán)上下界中有min/max這樣的操作,此時就需要實(shí)現(xiàn)這類循環(huán)變換。這類循環(huán)變換可以通過在schedule tree中的band節(jié)點(diǎn)上添加特殊的options屬性來實(shí)現(xiàn)。(注:我們的圖中沒有標(biāo)出options,但實(shí)際使用的schedule tree中有options,而options中的內(nèi)容是一個集合或者映射表達(dá)式,計(jì)算起來也很方便。)
第三,Poly能夠自動實(shí)現(xiàn)存儲系統(tǒng)的管理。在越來越復(fù)雜的加速芯片架構(gòu)上,復(fù)雜的存儲系統(tǒng)是實(shí)現(xiàn)芯片上計(jì)算部署的難點(diǎn),即便是硬件開發(fā)人員來手工實(shí)現(xiàn)程序在存儲結(jié)構(gòu)上的管理,也是一個十分耗時且易出錯的任務(wù)。而Poly借助中間表示自動實(shí)現(xiàn)了在多級緩存結(jié)構(gòu)上的存儲管理[27],使得底層優(yōu)化和硬件開發(fā)人員從這些瑣碎的工作中脫離出來。這種自動管理存儲系統(tǒng)的實(shí)現(xiàn)包括以下兩個方面。
1.自動計(jì)算緩存之間傳遞數(shù)據(jù)需要插入的位置。由于數(shù)據(jù)傳輸指令在原程序中是不存在的,所以Poly要能夠?qū)崿F(xiàn)這種從無到有的指令生成過程,并且正確計(jì)算出相應(yīng)的位置。Poly借助schedule tree上的特殊節(jié)點(diǎn)和仿射函數(shù),實(shí)現(xiàn)了數(shù)據(jù)傳輸指令位置的準(zhǔn)確計(jì)算和自動插入。
2.自動生成數(shù)據(jù)傳輸指令的循環(huán)信息。確定數(shù)據(jù)傳輸指令的位置后,Poly可以根據(jù)數(shù)學(xué)關(guān)系計(jì)算出當(dāng)前指令所在循環(huán)的層次和維度信息,并自動為數(shù)據(jù)傳輸指令計(jì)算對應(yīng)的調(diào)度關(guān)系,然后交給后端代碼生成器生成代碼。
如圖21所示,是圖20的schedule tree經(jīng)過插入特殊的extension節(jié)點(diǎn)之后,得到的帶有數(shù)據(jù)傳輸指令的中間表示。其中,kernel0和kernel1分別對應(yīng)圖20中最上面sequence節(jié)點(diǎn)下的兩棵子樹,而to_device_B和to_device_a表示從CPU的內(nèi)存上拷貝tensor B和a到GPU的global memory,這兩個語句在計(jì)算之前。from_device_c表示將GPU上的tensor c從global memory傳輸回CPU內(nèi)存上,這個語句在計(jì)算之后。Poly并沒有傳輸tensor b,而是在GPU的global memory上創(chuàng)建和使用了tensor b。(注:to_device_B和to_device_a也可以顛倒順序執(zhí)行,為了便于說明我們在這里假設(shè)按序執(zhí)行。)
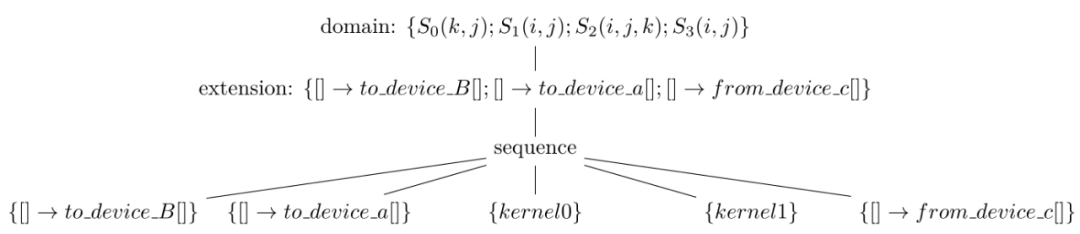
圖21 圖20的schedule tree插入數(shù)據(jù)傳輸指令之后的中間表示
最后,Poly還能夠自動計(jì)算出變換之后循環(huán)到硬件上的映射。在提供多級并行硬件抽象和按計(jì)算的類型提供不同計(jì)算單元的加速芯片上,軟件循環(huán)要實(shí)現(xiàn)到硬件上的映射,而這種映射關(guān)系也可以借助Poly的仿射函數(shù)和schedule tree上的標(biāo)記來自動實(shí)現(xiàn)。這可以通過在kernel0和kernel1的子樹內(nèi)的band節(jié)點(diǎn)上添加特殊標(biāo)記來實(shí)現(xiàn)。(注:圖中未標(biāo)出。)
-
存儲器
+關(guān)注
關(guān)注
38文章
7528瀏覽量
164349 -
緩存器
+關(guān)注
關(guān)注
0文章
63瀏覽量
11692 -
TPU
+關(guān)注
關(guān)注
0文章
144瀏覽量
20784 -
TVM
+關(guān)注
關(guān)注
0文章
19瀏覽量
3689 -
AI處理器
+關(guān)注
關(guān)注
0文章
92瀏覽量
9547
發(fā)布評論請先 登錄
相關(guān)推薦
一文看盡智能連接將會在哪些關(guān)鍵領(lǐng)域中發(fā)揮重要作用?
如何在交通領(lǐng)域構(gòu)建基于圖的深度學(xué)習(xí)架構(gòu)
深度學(xué)習(xí)介紹
對2017年NLP領(lǐng)域中深度學(xué)習(xí)技術(shù)應(yīng)用的總結(jié)
如何深度強(qiáng)化學(xué)習(xí) 人工智能和深度學(xué)習(xí)的進(jìn)階
排序算法如何在機(jī)器學(xué)習(xí)技術(shù)中發(fā)揮重要作用
RFID技術(shù)將在未來的智能工廠中發(fā)揮很大的作用
深度學(xué)習(xí)在各個領(lǐng)域有什么樣的作用深度學(xué)習(xí)網(wǎng)絡(luò)的使用示例分析
VR娛樂中心在VR推廣中發(fā)揮著關(guān)鍵性的作用
傳感器在醫(yī)療領(lǐng)域發(fā)揮的重要作用
薄膜電容器在應(yīng)用領(lǐng)域中發(fā)揮著什么樣的作用
薄膜電容在眾多領(lǐng)域中發(fā)揮的作用是什么
機(jī)器學(xué)習(xí)在物聯(lián)網(wǎng)中發(fā)揮關(guān)鍵作用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論