 APE:對CLIP進行特征提純能夠提升Few-shot性能
APE:對CLIP進行特征提純能夠提升Few-shot性能
本文介紹我們在ICCV 2023上接收的論文《Not All Features Matter: Enhancing Few-shot CLIP with Adaptive Prior Refinement》。這篇文章基于CLIP提出了一種特征提純的方法為下游任務選擇合適的特征,以此來提高下游任務的性能并同時提高計算效率。

論文: https://arxiv.org/pdf/2304.01195
代碼: https://github.com/yangyangyang127/APE
相比于其他方法,我們能夠在性能和計算量上實現較好的均衡,如下圖所示。
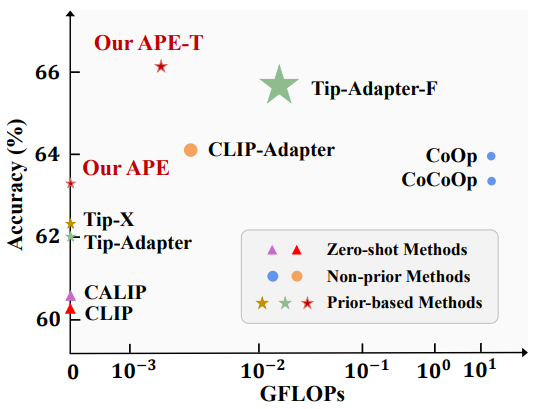
1. 概述
問題:大規模預訓練的視覺-文本模型,如CLIP,BLIP等,能夠在多種數據分布下表現出良好的性能,并已經有很多的工作通過few-shot的方式將它們應用于下游任務。但這些方法或者性能提升有限(如CoOp, CLIP-Adapter等),或者需要訓練大量的參數(如Tip-Adapter等)。因此我們會問,能否同時實現高few-shot性能且少參數量呢?
出發點和思路:CLIP是一個通用的模型,考慮到下游數據分布的差異,對某個下游任務來說,CLIP提取的特征并不全是有用的,可能包含一部分冗余或噪聲。因此,在這篇文章中,我們首先提出一種特征提純的方法,為每個數據集提純個性化的特征通道,從而減少了參數量,且提升了計算效率;然后設計了一種參數高效的few-shot框架,提升了CLIP在不同數據集上的few-shot性能,下圖是論文的整體流程圖。
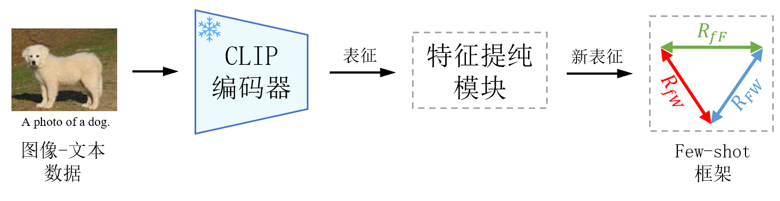
2. 方法
這一部分中,我們分別介紹特征提純模塊和新提出的few-shot框架。
2.1 特征提純
CLIP是一個通用的模型,在下游任務上,考慮到數據分布,CLIP提取的特征可能并不全是有用的,因此我們試圖為每個下游數據集提純個性化的特征。我們通過最大化類間差異,或者說最小化類間相似度,來選擇合適的特征。對于一個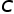 類的下游任務,我們計算所有類的所有樣本表征之間平均相似度
類的下游任務,我們計算所有類的所有樣本表征之間平均相似度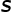 ,
,
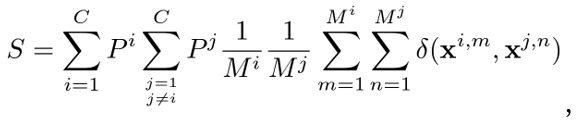
其中,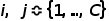 代表類的序號,
代表類的序號,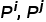 代表兩個類的先驗概率,
代表兩個類的先驗概率,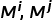 代表兩個類中的樣本數量,
代表兩個類中的樣本數量,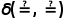 是相似度函數,
是相似度函數, 代表表征。假設
代表表征。假設 代表特征通道是否被選中,
代表特征通道是否被選中, 代表特征維度,
代表特征維度,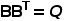 代表預先限制
代表預先限制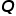 個特征被選中,則通過求解
個特征被選中,則通過求解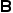 使得最小我們可以得到需要的特征,即求解以下優化問題:
使得最小我們可以得到需要的特征,即求解以下優化問題:
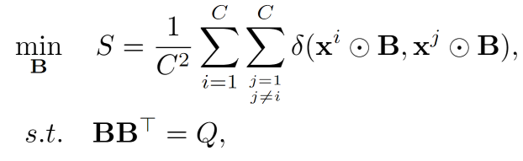
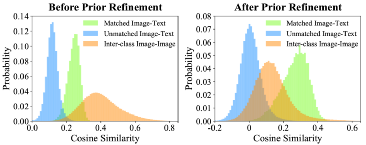
其中 代表逐元素相乘。最后,經過特征提純,我們在ImageNet上統計了圖像和文本相似度的變化,如下圖所示。相比于沒有特征提純,我們選定的特征減小了類間相似度,同時增大了圖像和文本的匹配程度。且我們提純出的特征能夠獲得更好的similarity map。
代表逐元素相乘。最后,經過特征提純,我們在ImageNet上統計了圖像和文本相似度的變化,如下圖所示。相比于沒有特征提純,我們選定的特征減小了類間相似度,同時增大了圖像和文本的匹配程度。且我們提純出的特征能夠獲得更好的similarity map。

2.2 三邊關系的few-shot框架
CLIP等視覺文本模型一般基于測試圖像和文本表征的相似度或距離來完成分類任。但除此之外,我們還可以使用測試圖像和訓練圖像的相似度來校正,并使用訓練圖像和文本的相似度來為困難樣本提供額外的信息。基于這種考慮,我們探究了測試圖像、文本描述和訓練圖像之間的三邊嵌入關系。
假設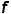 代表測試圖像特征,
代表測試圖像特征,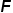 和
和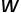 分別代表訓練圖像和文本描述的特征,
分別代表訓練圖像和文本描述的特征,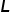 代表訓練圖像的label,則我們可以建立三邊關系,
代表訓練圖像的label,則我們可以建立三邊關系,
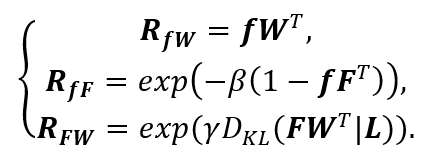
其中,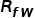 代表一般的CLIP基于視覺文本相似度的預測,
代表一般的CLIP基于視覺文本相似度的預測,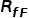 代表模態間的相似度,即測試圖像和訓練圖像之間的相似度,
代表模態間的相似度,即測試圖像和訓練圖像之間的相似度,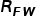 反映了訓練圖像對測試圖像的貢獻。基于以上三種關系,可以得到最終的預測為
反映了訓練圖像對測試圖像的貢獻。基于以上三種關系,可以得到最終的預測為
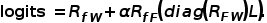
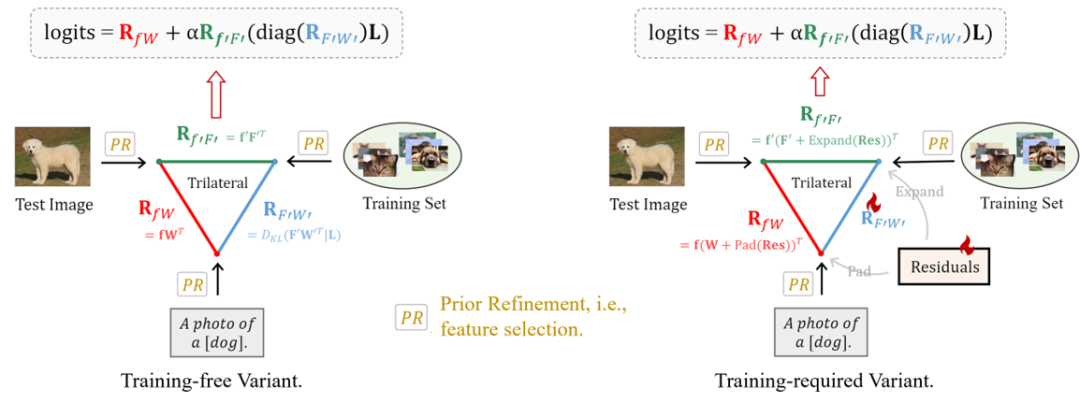
我們可以將特征提純與三邊關系結合起來,直接在選擇出來的特征上進行三種關系的few-shot學習,這樣可以減少參數和計算效率。我們提出了training-free和training-required兩種框架,如下圖,后者相比于前者增加了少量可訓練的殘差。
3. 結果
我們在11個分類數據集上研究了方法的性能,并提出了training-free和training-required兩個版本,下圖是11個數據集上的平均性能以及和其他方法的比較。
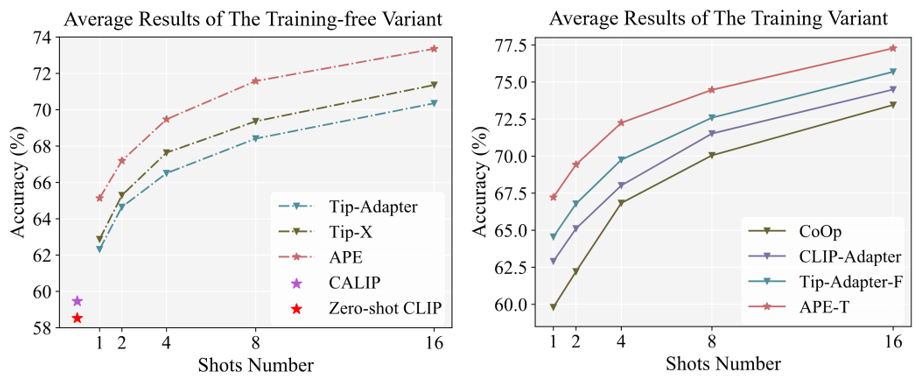
與其他方法相比,我們的計算效率和參數量都有所優化。
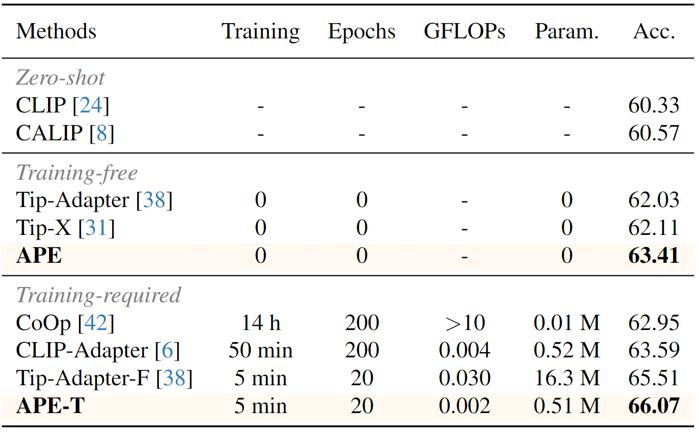
提純的特征通道的數量對結果也有所影響:
感謝您的閱讀,更多的實現細節和比較請看我們的文章,我們的代碼已開源。感謝您提出寶貴意見。
-
模型
+關注
關注
1文章
3305瀏覽量
49220 -
數據集
+關注
關注
4文章
1209瀏覽量
24832 -
Clip
+關注
關注
0文章
31瀏覽量
6711
原文標題:?ICCV 2023 | APE:對CLIP進行特征提純能夠提升Few-shot性能
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于將 CLIP 用于下游few-shot圖像分類的方案
NLP事件抽取綜述之挑戰與展望
樣本量極少可以訓練機器學習模型嗎?
介紹兩個few-shot NER中的challenge
Few-shot NER的三階段
介紹一個基于CLIP的zero-shot實例分割方法
使用MobileNet Single Shot Detector進行對象檢測

語言模型性能評估必備下游數據集:ZeroCLUE/FewCLUE與Chinese_WPLC數據集
基于GLM-6B對話模型的實體屬性抽取項目實現解析
邁向多模態AGI之開放世界目標檢測
基于多任務預訓練模塊化提示
為什么叫shot?為什么shot比掩膜版尺寸小很多?

基于顯式證據推理的few-shot關系抽取CoT
更強!Alpha-CLIP:讓CLIP關注你想要的任何地方!






 工商網監
工商網監
評論