") Wayve:從源頭講起,如何實(shí)現(xiàn)以對(duì)象為中心的自監(jiān)督感知方法?
Wayve:從源頭講起,如何實(shí)現(xiàn)以對(duì)象為中心的自監(jiān)督感知方法?
Wayve:從源頭講起,如何實(shí)現(xiàn)以對(duì)象為中心的自監(jiān)督感知方法?
1. 摘要
以對(duì)象中心的表示使自主駕駛算法能夠推理大量獨(dú)立智能體和場(chǎng)景特征之間的交互。傳統(tǒng)上,這些表示是通過(guò)監(jiān)督學(xué)習(xí)獲得的,但會(huì)使感知與下游駕駛?cè)蝿?wù)分離,可能會(huì)降低模型的泛化能力。在這項(xiàng)工作中,我們?cè)O(shè)計(jì)了一個(gè)以對(duì)象為中心的自監(jiān)督視覺(jué)模型,僅使用RGB視頻和車輛姿態(tài)作為輸入來(lái)實(shí)現(xiàn)進(jìn)行對(duì)象分割。我們?cè)赪aymo公開(kāi)感知數(shù)據(jù)集上證明了我們的方法取得了令人滿意的結(jié)果。我們發(fā)現(xiàn)我們的模型能夠?qū)W習(xí)一種隨時(shí)間推移融合多個(gè)相機(jī)姿勢(shì)的表示,并在數(shù)據(jù)集中成功跟蹤大量車輛和行人。我們介紹了該方法的起源和具體實(shí)現(xiàn)方法,并指明了未來(lái)的發(fā)展方向,為了幫助大家更好地復(fù)現(xiàn)代碼,我們將詳細(xì)地參數(shù)列入附表。
論文地址:https://arxiv.org/abs/2307.07147
模型代碼:https://github.com/wayveai/SOCS。
2. 方法起源
人類和機(jī)器人有一種傾向,即認(rèn)為對(duì)象的行為是單一連貫的,這是一種與生俱來(lái)的感知法則。對(duì)象在人類視覺(jué)中發(fā)揮著核心作用。我們根據(jù)特征將對(duì)象分組,用它們來(lái)描述我們周圍的環(huán)境,同時(shí),為我們不熟悉的對(duì)象尋找語(yǔ)義標(biāo)簽。當(dāng)使用視覺(jué)表示進(jìn)行下游任務(wù)時(shí),如機(jī)器人技術(shù)等,對(duì)象中心模型是令人滿意的:因?yàn)樗鼈儽榷说蕉四P透菀妆蝗祟惱斫狻@對(duì)驗(yàn)證安全性和贏得人類對(duì)視覺(jué)系統(tǒng)的信任非常重要。除此之外,以對(duì)象為中心的表示還提供了一套多樣而強(qiáng)大的推理真實(shí)世界的工具,如物理理解模型、多智能體預(yù)測(cè)和規(guī)劃模型以及因果推理模型。支持這類模型的表示可能對(duì)自動(dòng)駕駛至關(guān)重要,因?yàn)樵谧詣?dòng)駕駛中,使用這些表示對(duì)大量相互作用的智能體和物理因素進(jìn)行推理,可以獲得車輛的最佳運(yùn)動(dòng)軌跡。
傳統(tǒng)上,以對(duì)象中心的表示是通過(guò)訓(xùn)練監(jiān)督對(duì)象檢測(cè)模型,并從中提取對(duì)象屬性(如位置和速度)來(lái)實(shí)現(xiàn)的。這種方法有兩大缺點(diǎn)。首先,它需要與檢測(cè)對(duì)象相匹配的帶標(biāo)簽數(shù)據(jù)集,而大規(guī)模獲取帶標(biāo)簽數(shù)據(jù)集的成本很高,而且可能會(huì)引入不必要的偏差。另外,為了使系統(tǒng)能夠處理新的對(duì)象或新的環(huán)境,必須收集新的帶標(biāo)簽的數(shù)據(jù)。沒(méi)有足夠正確標(biāo)注的數(shù)據(jù)會(huì)影響這類方法的泛化能力,但這正是以對(duì)象為中心的自監(jiān)督模型的關(guān)鍵優(yōu)勢(shì)之一。
其次,根據(jù)有監(jiān)督的視覺(jué)模型預(yù)測(cè)創(chuàng)建的對(duì)象表示,會(huì)使感知和決策組件之間脫節(jié)。例如,騎自行車的人應(yīng)該被視為一個(gè)對(duì)象還是兩個(gè)對(duì)象??jī)扇顺穗p人自行車又如何?他們?cè)谙蛉诵械郎系男腥藫]手重要嗎?如果他們正在打轉(zhuǎn)向手勢(shì)呢?這些問(wèn)題的正確答案取決于如何使用信息做出決策。理想情況下,感知行為的結(jié)果應(yīng)該反饋并改善感知本身,利用端到端學(xué)習(xí),可以找到比手工設(shè)計(jì)更好的以對(duì)象為中心的表示。
這些考慮激發(fā)了以對(duì)象為中心的自監(jiān)督感知模型的設(shè)計(jì),這種模型將圖像編碼到一個(gè)將相關(guān)信息劃分為多個(gè)“槽”的潛在空間中,然后這些槽中的信息被解碼為自監(jiān)督目標(biāo),如例如重建原始RGB輸入,以及用于下游任務(wù)。已經(jīng)有不少論文提出了各種方法,來(lái)鼓勵(lì)模型在單個(gè)槽中編碼關(guān)于不同對(duì)象的信息,例如通過(guò)使用使槽在像素上競(jìng)爭(zhēng)注意力的編碼器,或者通過(guò)不同的自動(dòng)編碼器損失來(lái)鼓勵(lì)槽解碼。然而,這些方法在復(fù)雜的現(xiàn)實(shí)世界數(shù)據(jù)中難以獲得良好的結(jié)果。最近,SAVi++算法在Waymo真實(shí)世界駕駛視頻公開(kāi)數(shù)據(jù)集上顯示了其分割能力。然而,這些結(jié)果需要額外的深度監(jiān)督,而且需要初始對(duì)象與周圍環(huán)境邊界的槽,才能夠獲得最佳性能。
基于上述考慮,我們提出了一種僅使用RGB視頻和相機(jī)運(yùn)動(dòng)信息進(jìn)行自監(jiān)督分割的模型,并在真實(shí)駕駛視頻上獲得了良好的的結(jié)果。相機(jī)運(yùn)動(dòng)信息在自動(dòng)駕駛車輛中容易獲得(例如來(lái)自同時(shí)定位與建圖(SLAM)或輪組測(cè)距),而且不需要專用激光雷達(dá)等傳感器,因此是一種特別經(jīng)濟(jì)的方法。
3. 方法實(shí)現(xiàn)
我們的模型架構(gòu)建立在SIMONe的視圖監(jiān)督變體上。該模型的目標(biāo)是將場(chǎng)景分割為一組K個(gè)對(duì)象槽,對(duì)場(chǎng)景中每個(gè)對(duì)象的信息進(jìn)行編碼。通過(guò)以下步驟可以獲得這些槽。首先,輸入X(F幀圖像序列,可選擇從多相機(jī)視點(diǎn))由標(biāo)準(zhǔn)卷積神經(jīng)網(wǎng)絡(luò)(CNN)并行處理,得到一組特征補(bǔ)丁。補(bǔ)丁與位置嵌入連接,位置嵌入在每個(gè)補(bǔ)丁源圖像內(nèi)的位置,以及與源圖像相關(guān)的時(shí)間和視點(diǎn)變換矩陣進(jìn)行編碼。然后,它們作為僅解碼transformer的輸入信號(hào)。輸出標(biāo)記在整個(gè)圖像維度上的平均值。在原始SIMONe模型中,這個(gè)維度對(duì)應(yīng)于單個(gè)相機(jī)在幾個(gè)時(shí)間點(diǎn)上拍攝的圖像;但在這項(xiàng)工作中,我們使用了三個(gè)不同的姿勢(shì)的相機(jī),在時(shí)間和視點(diǎn)上進(jìn)行取平均值。最后,通過(guò)MLP將每個(gè)信號(hào)解碼為m維向量和,這兩個(gè)向量分別包含單個(gè)槽中潛預(yù)測(cè)平均值和方差。如果輸入信號(hào)的數(shù)量與所需的槽的數(shù)量不同,則在transformer層的中途可選地進(jìn)行跨信號(hào)特征的空間池化操作。具體模型如下圖所示。
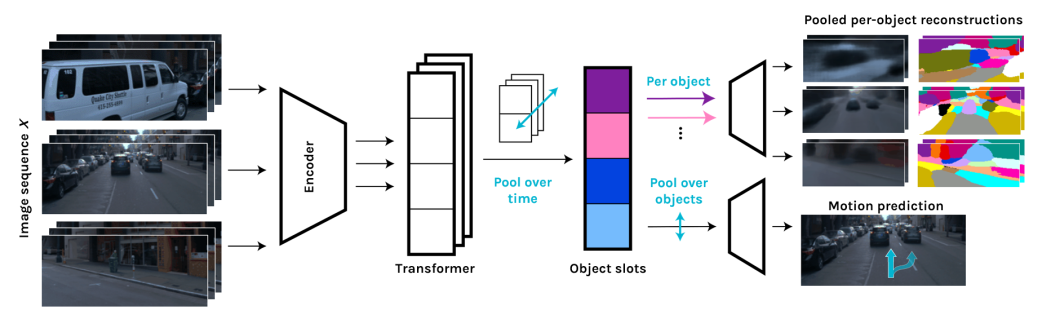
3.1. 訓(xùn)練和損失
為了鼓勵(lì)模型在不同的槽中存儲(chǔ)不同對(duì)象的信息,在訓(xùn)練期間我們應(yīng)用三個(gè)互補(bǔ)的損失。第一項(xiàng)是每個(gè)槽潛在向量與單位正態(tài)分布之間的KL散度之和,對(duì)所有槽求和:
其中是輸入幀,是槽 的m維正態(tài)分布,均值和方差由模型預(yù)測(cè),先驗(yàn)分布是一個(gè)單位球面正態(tài)分布。直觀地,這個(gè)損失鼓勵(lì)模型避免使用多個(gè)槽表示同一對(duì)象,因?yàn)榕c使用單個(gè)槽表示對(duì)象并讓其他槽保持接近單位正態(tài)分布相比,這樣做會(huì)導(dǎo)致更大的懲罰。這個(gè)損失還鼓勵(lì)潛在向量的每個(gè)維度之間解耦。
第二個(gè)損失基于模型執(zhí)行對(duì)象級(jí)重建任務(wù)的能力。首先,根據(jù)每個(gè)槽 的潛在分布獲取對(duì)象的潛在向量。然后,每個(gè)被獨(dú)立解碼到空間廣播解碼器進(jìn)行逐像素預(yù)測(cè)。為了滿足模型計(jì)算要求和內(nèi)存需求,在訓(xùn)練期間每個(gè)輸入序列中僅對(duì)N個(gè)隨機(jī)像素進(jìn)行解碼。每個(gè)槽 對(duì)每個(gè)像素的預(yù)測(cè)結(jié)果用RGB分布表示。和邏輯單元 (經(jīng)過(guò)槽歸一化)表示槽 表示像素的可能性。為了獲得每個(gè)像素的最終預(yù)測(cè),我們?nèi)∶總€(gè)槽預(yù)測(cè)的加權(quán)混合:
其中針對(duì)像素的每槽分布經(jīng)softmax后的值加權(quán):
的分布在第3.3節(jié)中進(jìn)行了更詳細(xì)的討論。
最后,重建損失是每個(gè)像素在混合分布下的真實(shí)RGB值的對(duì)數(shù)概率:
由于每個(gè)槽的對(duì)象潛變量被獨(dú)立解碼,模型被迫在預(yù)測(cè)每個(gè)像素的RGB值時(shí)一次只使用單個(gè)槽中編碼的信息。因此,直觀地,這個(gè)損失鼓勵(lì)模型將預(yù)測(cè)像素的顏色所需的所有信息存儲(chǔ)在單個(gè)槽中。
另外,學(xué)習(xí)到的槽表示還可以用于各種輔助任務(wù)。在本文中,受到對(duì)象與自動(dòng)駕駛環(huán)境中相關(guān)的表示與用于預(yù)測(cè)良好駕駛動(dòng)作的表示之間的密切聯(lián)系的啟發(fā),我們實(shí)驗(yàn)使用預(yù)測(cè)車輛自身的未來(lái)路徑作為輔助任務(wù)。在圖像池化步驟之后,槽信息經(jīng)過(guò)兩個(gè)Transformer 解碼器層,求平均值,并通過(guò)單層MLP解碼成一系列預(yù)測(cè)偏移量,在自我參考幀的xy平面上。然后我們應(yīng)用以下任務(wù)損失:
其中匯總是對(duì)每個(gè)未來(lái)時(shí)間點(diǎn)。我們使用以10Hz頻率開(kāi)始于最后圖像幀之后0.1秒的自我參考幀中的16個(gè)未來(lái)路徑。
最終訓(xùn)練損失與負(fù)ELBO損失類似,增加了輔助任務(wù)損失:
其中和超參數(shù)平衡不同的損失項(xiàng)。
3.2. 附加的模型輸出
除了參數(shù)化加權(quán)混合像素分布,權(quán)重還作為每一個(gè)槽 的α 掩碼,使我們可以非常直觀地看到每個(gè)槽關(guān)注場(chǎng)景的哪些像素。為每個(gè)槽取最大值可以得到場(chǎng)景的預(yù)測(cè)分割。這種分割可以幫助模型調(diào)試和解釋。例如,如果無(wú)法用掩碼跟蹤特定車輛,表明模型沒(méi)有從場(chǎng)景的其他特征中區(qū)分出該對(duì)象的特征,因此沒(méi)有獨(dú)立表示其運(yùn)動(dòng)狀態(tài)。
對(duì)象的槽或潛在向量也可以解碼為圖像重建或軌跡預(yù)測(cè)以外的其他輸出。其他潛在下游任務(wù)可能包括視頻預(yù)測(cè)、生產(chǎn)系統(tǒng)模型或有運(yùn)動(dòng)條件世界模型。在端到端機(jī)器學(xué)習(xí)中,哪些輔助任務(wù)可以協(xié)同提升性能,是一個(gè)激動(dòng)人心的開(kāi)放問(wèn)題。
3.3. 對(duì)象槽解碼分布
原始SIMONe模型采用正態(tài)分布預(yù)測(cè)的像素RGB值。(注意,在本節(jié)中,我們將RGB元組稱為正態(tài),但在現(xiàn)實(shí)中,R、G和B通道是獨(dú)立對(duì)待的。)我們發(fā)現(xiàn),在進(jìn)行場(chǎng)景中分割時(shí),這個(gè)分布會(huì)導(dǎo)致模型過(guò)度依賴顏色差異。這會(huì)導(dǎo)致一些失敗的案例,如無(wú)法分割車身和擋風(fēng)玻璃、無(wú)法識(shí)別出與背景顏色相似的對(duì)象等。我們猜測(cè)這是因?yàn)樵趦蓚€(gè)不同顏色的區(qū)域邊界附近,模型不確定為給定像素分配什么顏色。為了用正態(tài)分布表示這種不確定性,模型被迫將不同顏色的區(qū)域分配給不同的槽,并使用每個(gè)槽的權(quán)重給出每種顏色的可能性 。
對(duì)于我們的體系結(jié)構(gòu),我們使用多頭正態(tài)分布替換SIMONe中的正態(tài)分布,來(lái)減輕這個(gè)問(wèn)題。定性的說(shuō),我們發(fā)現(xiàn)這能夠更好地反映對(duì)象運(yùn)動(dòng)的分割。對(duì)于每個(gè)像素和每個(gè)槽 k,解碼器輸出H個(gè)模式,其中預(yù)測(cè)平均RGB元組和邏輯單元 決定每個(gè)模式的權(quán)重。(注意,此外還有一個(gè)單獨(dú)的“全局” 回歸,它控制第k個(gè)槽對(duì)總混合分布的貢獻(xiàn),如方程2所示。) 因此,每個(gè)槽的分布是:
其中正常分布的方差是一個(gè)超參數(shù)。當(dāng)時(shí),這簡(jiǎn)化為SIMONe中的解碼分布:
在我們的實(shí)驗(yàn)中,我們使用和。
最后,模型的分割結(jié)果和軌跡預(yù)測(cè)如下圖所示:


4. 結(jié)論
最近,以對(duì)象為中心的自我監(jiān)督表示學(xué)習(xí)方法,在具有明確定義對(duì)象的人工數(shù)據(jù)集上表現(xiàn)出了很強(qiáng)的性能,但在具有復(fù)雜紋理和模糊對(duì)象的復(fù)雜真實(shí)世界數(shù)據(jù)上仍然舉步維艱。在本文中,我們已展示的結(jié)果表明,通過(guò)使用相機(jī)姿態(tài)作為附加輸入,有可能在RGB駕駛視頻中獲得合理的動(dòng)態(tài)、以對(duì)象中心的表示。與3D深度傳感器不同,姿態(tài)估計(jì)是自動(dòng)駕駛汽車的一個(gè)普遍特征,因此我們認(rèn)為我們的方法是在自動(dòng)駕駛領(lǐng)域?qū)崿F(xiàn)可擴(kuò)展的、實(shí)用的,以對(duì)象中心的表示學(xué)習(xí)的一個(gè)很有前途的途徑。此外,我們的研究結(jié)果表明,預(yù)測(cè)車輛自身的未來(lái)姿態(tài)是一項(xiàng)協(xié)同任務(wù),它不會(huì)阻礙學(xué)習(xí)表達(dá)的質(zhì)量。這對(duì)端到端駕駛模型來(lái)說(shuō)尤其令人興奮,因?yàn)樗蜷_(kāi)了駕駛性能和表示學(xué)習(xí)共同建立良性循環(huán)的可能性,同時(shí)保留了以對(duì)象為中心的表示的關(guān)鍵優(yōu)勢(shì),如可解釋性。
我們認(rèn)為仍有可能進(jìn)一步提高對(duì)象分割質(zhì)量,例如,通過(guò)擴(kuò)大模型規(guī)模和采取數(shù)據(jù)增強(qiáng)策略(這兩點(diǎn)對(duì)SAVi++的性能非常重要)。我們還注意到,Waymo 公開(kāi)感知數(shù)據(jù)集包含三個(gè)前向攝像頭的480,000幀圖像,對(duì)于理想的表示學(xué)習(xí)而言相比,該數(shù)據(jù)集的規(guī)模與其復(fù)雜性可能不夠大。相比之下,最近的對(duì)象場(chǎng)景表示transformer模型是在1000萬(wàn)幀合成數(shù)據(jù)集上訓(xùn)練的。
最后,我們注意到,我們模型中的KL-發(fā)散損失鼓勵(lì)學(xué)習(xí)理順的對(duì)象潛在特征。更詳細(xì)地研究這些特征是未來(lái)工作的一個(gè)令人興奮的方向。
5. 論文中的超參數(shù)
| 參數(shù) | 值 |
|---|---|
| 權(quán)重, β (帶路徑預(yù)報(bào)任務(wù)) | 5e-7 |
| β (無(wú)路徑預(yù)報(bào)任務(wù)) | 4.5e-7 |
| 權(quán)重, | 1e-4 |
| 對(duì)象槽的方差, | 0.08 |
| 對(duì)象槽數(shù)量 | 21 |
| 對(duì)象潛在維度 | 32 |
| Transformer 層數(shù) | 6 |
| Transformer 頭數(shù) | 4 |
| Transformer 特征維度 | 512 |
| Transformer 前饋維度 | 1024 |
| 重建 MLP 層數(shù) | 3 |
| 重構(gòu)MLP的隱藏維度 | 1536 |
| 圖像序列長(zhǎng)度 | 8 |
| 圖像尺寸(高、寬) | (96, 224) |
| 每個(gè)訓(xùn)練序列解碼的像素?cái)?shù)量,N | 2016 |
| 批大小 | 8 |
| 學(xué)習(xí)率 | 1e-4 |
-
編碼器
+關(guān)注
關(guān)注
45文章
3669瀏覽量
135251 -
算法
+關(guān)注
關(guān)注
23文章
4630瀏覽量
93359 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24835
原文標(biāo)題:Wayve:從源頭講起,如何實(shí)現(xiàn)以對(duì)象為中心的自監(jiān)督感知方法?(附代碼)
文章出處:【微信號(hào):GiantPandaCV,微信公眾號(hào):GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
實(shí)現(xiàn)以太網(wǎng)通信硬件電路方法
基于transformer和自監(jiān)督學(xué)習(xí)的路面異常檢測(cè)方法分享

有誰(shuí)是做認(rèn)知無(wú)線電頻譜感知方向的嗎
智能感知方案怎么幫助實(shí)現(xiàn)安全的自動(dòng)駕駛?
認(rèn)知無(wú)線電中基于循環(huán)平穩(wěn)特征的頻譜感知方法

一種基于智能終端的環(huán)境與接近度感知方法
基于信道歷史狀態(tài)信息的頻譜感知方法
一種自監(jiān)督同變注意力機(jī)制,利用自監(jiān)督方法來(lái)彌補(bǔ)監(jiān)督信號(hào)差異
新的工業(yè)應(yīng)用智能感知方案
基于人工智能的自監(jiān)督學(xué)習(xí)詳解
極目智能產(chǎn)品方案亮相上海車展 攜手地平線、楚航科技發(fā)力智能駕駛感知方案

基于純視覺(jué)的感知方法
4分鐘了解吸頂燈具智能感知方案測(cè)試方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論