") riscv的fpga實現(xiàn)案例 基于RISC-V加速器實現(xiàn)現(xiàn)場可編程門陣列 CNN異構(gòu)的控制方案
riscv的fpga實現(xiàn)案例 基于RISC-V加速器實現(xiàn)現(xiàn)場可編程門陣列 CNN異構(gòu)的控制方案
作者:吳海龍, 李金東, 陳翔,電子與信息工程學(xué)院,中山大學(xué),中國 (在此特別鳴謝!)
摘要:現(xiàn)場可編程門陣列(FPGA)具有低功耗、高性能和靈活性的特點。FPGA神經(jīng)網(wǎng)絡(luò)加速的研究正在興起,但大多數(shù)研究都基于國外的FPGA器件。為了改善國內(nèi)FPGA的現(xiàn)狀,提出了一種新型的卷積神經(jīng)網(wǎng)絡(luò)加速器,用于配備輕量級RISC-V軟核的國產(chǎn)FPGA(紫光同創(chuàng)PG2L100H)。所提出的加速器的峰值性能達(dá)到153.6 GOP/s,僅占用14K LUT(查找表)、32個DRM(專用RAM模塊)和208個APM(算術(shù)處理模塊)。所提出的加速器對于大多數(shù)邊緣AI應(yīng)用和嵌入式系統(tǒng)具有足夠的計算能力,為國內(nèi)FPGA提供了可能的AI推理加速方案。
背景
卷積神經(jīng)網(wǎng)絡(luò)在機(jī)器視覺任務(wù)中越來越流行,包括圖像分類和目標(biāo)檢測。如何在有限的條件下充分發(fā)揮FPGA的最大性能是各研究者的主要方向。如今,大多數(shù)CCN使用外國FPGA器件。由于國內(nèi)FPGA起步較晚,其相關(guān)開發(fā)工具和設(shè)備落后于其他外國制造商。因此,在國內(nèi)FPGA上構(gòu)建高性能CNN并替換現(xiàn)有成熟的異構(gòu)方案是一項具有挑戰(zhàn)性的任務(wù)。 Zhang[1]于2015年首次對卷積網(wǎng)絡(luò)推理中的數(shù)據(jù)共享和并行性進(jìn)行了深入分析和探索。Guo[2]提出的加速器在214MHz下達(dá)到了84.3 GOP/s的峰值性能。2016年,Qiu[3]更深入地探索了使用行緩沖器的加速器。
本文提出了一種更高效、更通用的卷積加速器。提出的加速器峰值性能達(dá)到153.6GOP/s,僅占用14K LUT、32個DRM和208個APM。本文的章節(jié)安排如下,第2節(jié)介紹了我們提出的加速器的詳細(xì)設(shè)計以及基于RISC-V的加速器實現(xiàn)的控制調(diào)度方案。第3節(jié)給出了實驗結(jié)果。
系統(tǒng)設(shè)計
整個RISC-V片上系統(tǒng)設(shè)計如圖1所示。該系統(tǒng)主要由RISC-V軟核CPU、指令/數(shù)據(jù)存儲器、總線橋、外圍設(shè)備、DMA(直接存儲器訪問)和卷積加速器組成。
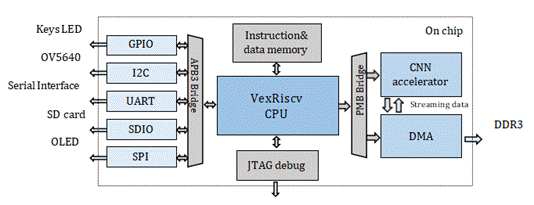
Fig. 1. 片上RISC-V系統(tǒng)設(shè)計圖
我們的工作主要在三個方面。首先,我們使用軟核CPU作為片上系統(tǒng)的主控,控制外設(shè),DMA,CNN加速器來實現(xiàn)數(shù)據(jù)調(diào)度和操作。其次,1D(一維)加速器被設(shè)計用于改變緩沖機(jī)制。第三,為紫光同創(chuàng)的FPGA設(shè)備設(shè)計了一個DMA IP,用于卷積加速的應(yīng)用。
A、RISC-V 軟核CPU 架構(gòu)
軟核。使用RISC-V軟核VexRiscv代替Ibex[4]構(gòu)建RISC-V的片上系統(tǒng)和面向軟件的方法可以使VexRiscv具有高度的靈活性和可擴(kuò)展性。
接口。I2C和SPI等外圍設(shè)備通過APB3總線連接到RISC-V軟核。DMA和加速器通過PMB總線連接到RISC-V軟核。
指令與數(shù)據(jù)存儲。程序被交叉編譯以獲得一個特定的文件,該文件由JTAG燒錄到片上指令/數(shù)據(jù)存儲器中。
B、CNN 加速器結(jié)構(gòu)
輸入緩存。使用乒乓緩存來實現(xiàn)緩沖區(qū),可以有效地提高吞吐量。
輸出緩存。權(quán)重緩存模塊由一系列分布式RAM和串行到并行單元組成。
卷積。圖2中的1D卷積模塊分為四組,其中包含四個1D卷曲單元。每個單元負(fù)責(zé)1D卷積的一個信道。
合并。積分模塊有四組加法器樹。每組加法器樹將每組卷積運(yùn)算單元的結(jié)果相加,得到單向輸出結(jié)果。
累加。累加模塊中有四組FIFO和四個加法器。加速器一次只能接收四個通道的輸入特征圖數(shù)據(jù)。
量化。該量化模塊由乘法單元和移位單元組成。它通過比例變換將24位累加結(jié)果重新轉(zhuǎn)換為8位[5]。
激活。激活功能通過查找由一系列分布式RAM組成的表來實現(xiàn)。它存儲ReLu、Leaky ReLu和sigmoid函數(shù)的INT8函數(shù)表。
池化。確定當(dāng)前卷積層是否與池化層級聯(lián),然后決定是否使用池化模塊來完成池化操作。
輸出緩存。輸出緩沖器由FIFO而不是乒乓緩存實現(xiàn)。輸出高速緩存FIFO將結(jié)果存儲回片外存儲器,作為下一卷積層的輸入。
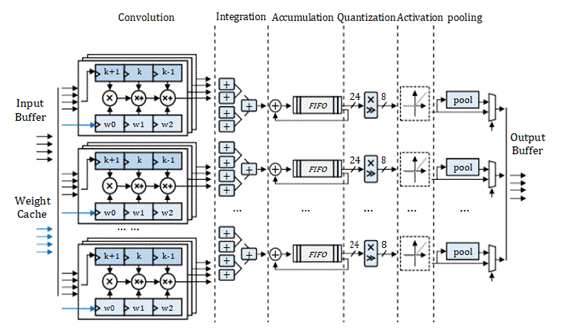
Fig. 2.CNN 加速器實現(xiàn)
C、DMA 結(jié)構(gòu)
神經(jīng)網(wǎng)絡(luò)不僅對計算能力有很高的要求,而且對內(nèi)存也有很大的需求。中低端FPGA通常需要DDR SRAM(雙數(shù)據(jù)速率同步動態(tài)隨機(jī)存取存儲器)來承載整個神經(jīng)網(wǎng)絡(luò)和所有中間運(yùn)算結(jié)果的權(quán)重。紫光同創(chuàng)的FPGA的DDR3內(nèi)存驅(qū)動器IP為用戶提供了簡化AXI4總線的內(nèi)存訪問接口。 由于Simpled AXI和AXI之間的標(biāo)準(zhǔn)差異,需要新的DMA設(shè)計。DMA設(shè)計如下。讀和寫地址通道由RISC-V軟核直接控制。讀寫數(shù)據(jù)通道的FIFO用作卷積加速器和DDR3驅(qū)動器IP的緩沖器,以完成端口轉(zhuǎn)換。
D、實現(xiàn)細(xì)節(jié)
1、一維卷積單元陣列設(shè)計 神經(jīng)網(wǎng)絡(luò)不僅對計算能力有很高的要求,而且對內(nèi)存也有很大的需求。中低端FPGA通常需要DDR SRAM(雙數(shù)據(jù)速率同步動態(tài)隨機(jī)存取存儲器)來承載整個神經(jīng)網(wǎng)絡(luò)和所有中間運(yùn)算結(jié)果的權(quán)重。紫光同創(chuàng)的FPGA的DDR3內(nèi)存驅(qū)動器IP為用戶提供了簡化AXI4總線的內(nèi)存訪問接口。 由于Simpled AXI和AXI之間的標(biāo)準(zhǔn)差異,需要新的DMA設(shè)計。DMA設(shè)計如下。讀和寫地址通道由RISC-V軟核直接控制。讀寫數(shù)據(jù)通道的FIFO用作卷積加速器和DDR3驅(qū)動器IP的緩沖器,以完成端口轉(zhuǎn)換。
2、卷積加速器控制
本文提出了一種基于指令隊列的設(shè)計,以減少RISC-V軟核中DMA和加速器的響應(yīng)延遲。RISC-V CPU可以連續(xù)發(fā)送多個存儲器讀寫請求指令和多個操作調(diào)度控制指令,而不用等待DMA和加速器的反饋。DMA和加速器從隊列中獲取指令,任務(wù)完成后直接從隊列中取出下一條指令,無需等待相應(yīng)的CPU,從而實現(xiàn)低延遲調(diào)度。
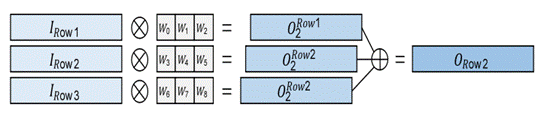
Fig. 3. 1X3 一維卷積原理圖
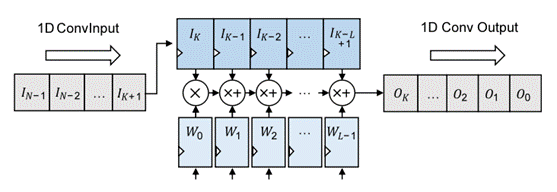
Fig. 4. 一維卷積單元硬件實現(xiàn)
實現(xiàn)結(jié)果和備注
通過在PG2L100H和X7Z020上實現(xiàn)相同配置的CNN加速器,完成了CNN加速器的性能測試,驗證了國產(chǎn)FPGA CNN加速方案的可行性。加速器的資源消耗和性能如表I和表II所示。
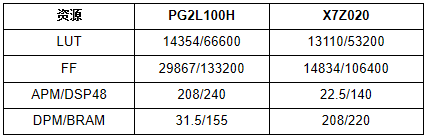
TABLE I 資源利用 PG2L100H和X7Z020的資源消耗相似。PG2L100H需要額外的邏輯資源來構(gòu)建VexRiscv CPU,而X7Z020為AXI DMA IP使用更多的邏輯資源。就加速器性能而言,可從表II中看出。由于FPGA器件架構(gòu)的差異,與X7Z020相比,加速器的卷積運(yùn)算在PG2L100H上只能在200MHz下實現(xiàn)更好的收斂。RISC-V軟核只能在100MHz下實現(xiàn)定時收斂。
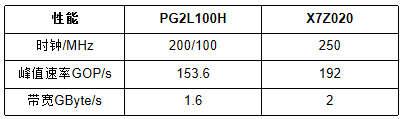
TABLE II 性能對比 我們提出了一種基于RISC-V的一維卷積運(yùn)算的新設(shè)計。該加速器在國內(nèi)FPGA上的實現(xiàn)和部署已經(jīng)完成,其性能與具有相同規(guī)模硬件資源的國外FPGA相當(dāng)。
本文論證了基于國產(chǎn)FPGA的CNN異構(gòu)方案的可行性,該研究是國產(chǎn)FPGA應(yīng)用生態(tài)中CNN加速領(lǐng)域的一次罕見嘗試。
作者:吳海龍, 李金東, 陳翔,電子與信息工程學(xué)院,中山大學(xué),中國 (在此特別鳴謝!)
REFERENCES:
[1]Zhang. C, et al. "Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks. " the 2015 ACM/SIGDA International Symposium ACM, 2015.
[2]K. Guo et al., "Angel-Eye: A Complete Design Flow for Mapping CNN Onto Embedded FPGA," in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 37, no. 1, pp. 35-47, Jan. 2018.
[3]Qiu.J, et al. "Going Deeper with Embedded FPGA Platform for Convolutional Neural Network." the 2016 ACM/SIGDA International Symposium ACM, 2016.
[4]E. Gholizadehazari, T. Ayhan and B. Ors, "An FPGA Implementation of a RISC-V Based SoC System for Image Processing Applications," 2021 29th Signal Processing and Communications Applications Conference (SIU), 2021, pp. 1-4.
[5]B. Jacob et al., "Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference," 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 2704-2713.
[6]B. Bosi, G. Bois and Y. Savaria, "Reconfigurable pipelined 2-D convolvers for fast digital signal processing," in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 7, no. 3, pp. 299-308, Sept. 1999.
-
FPGA
+關(guān)注
關(guān)注
1630文章
21797瀏覽量
606016 -
加速器
+關(guān)注
關(guān)注
2文章
807瀏覽量
38088 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101172 -
cnn
+關(guān)注
關(guān)注
3文章
353瀏覽量
22335 -
RISC-V
+關(guān)注
關(guān)注
45文章
2323瀏覽量
46595
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論