 談談大數據時代中數據架構的變遷
談談大數據時代中數據架構的變遷
一、前大數據時代
人人都知道羅馬不是一天建成的,但沒人告訴過你羅馬是怎樣一天天建成的。你看見羅馬時,它就已經是羅馬了。當我進阿里時,正是這樣的感覺。
我沒有經歷過阿里數據架構(包括平臺工具)從0到1的過程。我相信很多阿里老員工也沒有未見得全經歷過。因為從行業視角來看,這是一個長達二三十年的過程,阿里作為先行者本身也是摸著石頭過河。很多年輕一些的阿里員工看到當前的架構設計,他們的感受大概就是:“不就該是這樣嗎?不然還能怎樣?”?
魯迅就有話說了:“從來如此,便對么?”
好在我前些年輾轉了多家公司,有幸在一線接觸到了國內外各種不同業務不同類型的數據團隊及架構,再加上自己翻閱資料,才基本梳理清楚了數據架構的發展脈絡。
BI系統
現在人們身處大數據時代的洪流之中,數據產品日新月異,令人應接不暇。阿里還出過一本書——《大數據之路》,里面詳細介紹了大數據從采集到消費等各個環節的方法論和案例。那么,在大數據時代之前,人們也進行數據分析嗎?那時的人們又使用的是怎樣的工具和方法論呢? 這就要介紹一位熟悉又陌生的老朋友——BI系統。說它熟悉,是因為數據側的同學幾乎天天都會和BI系統打交道,比如阿里的FBI。說它陌生,是因為現在的BI系統與上世紀九十年代的初代BI系統并不完全是一回事。
BI(Business Intelligence,商業智能)的概念很早就有了(正如AI這一概念一樣)。早期它的內涵相對模糊,按照百度百科的解釋:“商業智能描述了一系列的概念和方法,通過應用基于事實的支持系統來輔助商業決策的制定。“隨著人們實踐不斷深入,BI系統的樣貌也逐漸清晰。
到了上世紀九十年代,BI系統迎來了它的第一個輝煌時期,Gartner將各種類型的類BI系統全部統稱為BI,BI產品也基本確定為了是一套集數據清洗、數據分析、數據挖掘、報表展示等功能于一體的完整解決方案,數據倉庫也基于此建立。從此BI系統一統江湖,江湖上再也沒了DSS(Decision Support System, 決策支持系統)、EIS(Executive Information System, 主管信息系統)的名字。如果大家翻閱出版于上世紀八九十年代的數據倉庫領域的書籍,就會發現里面頻繁出現DSS、EIS、DW/BI等概念,例如William H.Inmon所著的《數據倉庫(Building the Data Warehouse)》、Ralph Kimball所著的《數據倉庫生命周期工具箱(The Data Warehouse Lifecycle Toolkit)》等,即便它們經歷了多次翻譯和再版,但其中的概念還是得以保留,大家一定要注意辨析其中很多概念實際上早已過時。
事實上,與中國許多工業領域的發展一樣,正由于我們起步晚,因此反而沒有歷史包袱,我國絕大多數企業都沒有經歷過初代BI的時代,因此除非對技術歷史感興趣也實在沒有必要去了解這些概念。? 那時雖然沒有大數據的概念,但數據分析、商業分析顯然是人們長久以來都有的需求,也積累了相當多的方法論。
當數據量不是主要矛盾時,BI系統能夠支持的分析方法、UI等層面就成為了核心競爭力。BI系統的核心是Cube,它是一個業務模型抽象,在Cube上可以上鉆、下鉆、切片,為了更方便多維分析,還配套了MDX查詢語言。當然,大多數BI系統都構建在關系型數據庫之上,或者說很多BI系統本就是商業關系型數據庫的配套產品,因此也都是支持SQL語言的。在計算和存儲上可能類似于開源框架Apache Kylin。??
初代BI系統沒落的原因主要是:
1.底層構建在傳統關系型數據庫之上,因為存在數據一致性約束等問題,支持不了大數據。(這也暗合了網傳了很多年的阿里技術規范中提到的一條——不要設置外鍵,要通過其他技術手段保證數據一致性。)
2.不支持非結構化數據。?
說它沒落,但是它也并未消亡,在歐洲、澳大利亞、東南亞等不少地區還有不少傳統企業仍然在使用這項技術。因此人們常說這些地方技術落后國內互聯網大廠二十年,這就是一典型案例。而中國伴隨著經濟的快速發展、互聯網技術的迅速普及、開源大數據技術的引進和國務院《促進大數據發展行動綱要》的印發,除了阿里等少數企業,幾乎是一步到位直接進入了大數據時代。?
下面就談談大數據時代中數據架構的變遷。
二、大數據架構的演變
傳統大數據架構
為了解決上述問題,一些公司開始研發分布式的計算引擎和分布式的存儲平臺。其中最成功、最知名的便是Google研發的分布式文件系統與MapReduce計算引擎,后來這套技術被開源重寫為了Hadoop體系的多個項目,其生態圈也不斷擴大。?
下圖是一個典型的傳統大數據架構:
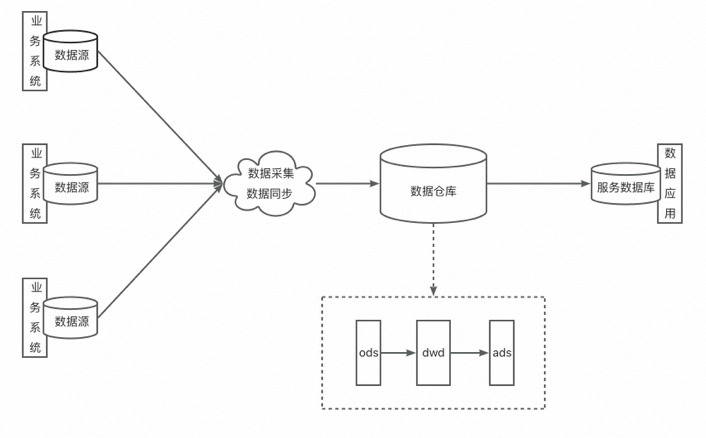 ?
?
雖然我在上文提到了Hadoop體系,但我還是需要做一點澄清——本文提到的架構與具體的技術選型沒有必然聯系。比如上圖的傳統大數據架構,它的業務系統數據源可能是關系型數據庫MySQL,也可能是平面文件,也可能是任意未知的源;數據采集和數據同步工具也是視具體的業務和上下游技術選型而定;接下來數據會進入數據倉庫,大致上會依次經過ODS層、DWD層和ADS層,最終提供給消費方使用。
在Miravia的技術選型中,通常業務數據通過binlog同步到TT,或者流量日志直接上報到日志服務器,再同步到TT。TT定期將一個時間區間內的數據同步到ODPS,ODPS再通過每日調度的任務對這些數據進行處理,最終落到ADS層的表。結果表的數據再同步到Holo或Lindorm等介質中,供消費方使用。因此單看這整個流程,實際上就是典型的傳統大數據架構的一種實現。但需要注意的是,該架構并沒有對輸入數據有結構化的要求,也沒有規定ETL過程使用的工具和編程語言。
在這種架構下,業務系統和分析系統的隔離性做得更好了,而且無論輸入數據是什么,最終提供給消費方的都是標準的結構化數據。它的缺點是整個過程不再有完整的解決方案,需要做大量的定制化工作。
流式架構
正應了湯師爺那句話:“步子大了,容易……”
流式架構就是典型代表。
流式架構的思路相當激進。雖然傳統大數據架構在技術選型上與BI系統比已經算是脫胎換骨,但其精神還是一脈相承。流式架構干脆扔掉一整套離線的數據采集、數據同步和ETL工作,直接讓流式計算引擎消費業務數據庫產生的增量數據,并直接輸出給消費方,以此提供實時的計算結果。?
而早期的技術儲備明顯不足以同時高質量保證實時性和結果的準確性,因此只被用在了極少數對結果實時性十分敏感卻對準確性要求不高的場景中。隨著技術的進步和業務復雜度的提高,這種架構也基本銷聲匿跡了。?
下圖是流式架構的典型代表:?
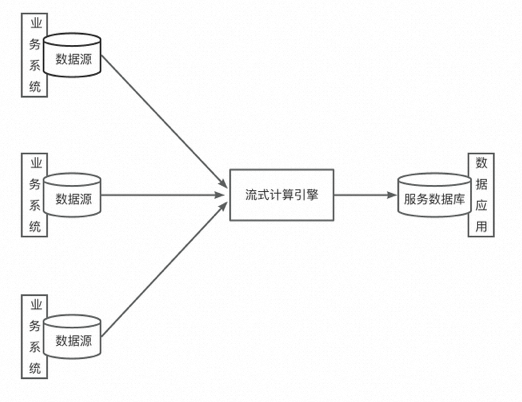
Lambda架構
在早期技術無法同時支持結果的實時性和準確性的情況下,有沒有辦法可以通過架構的設計,同時滿足兩者呢?有一位叫做Nathan Marz的大佬提出了Lambda架構。
先看Lambda架構的示意圖:
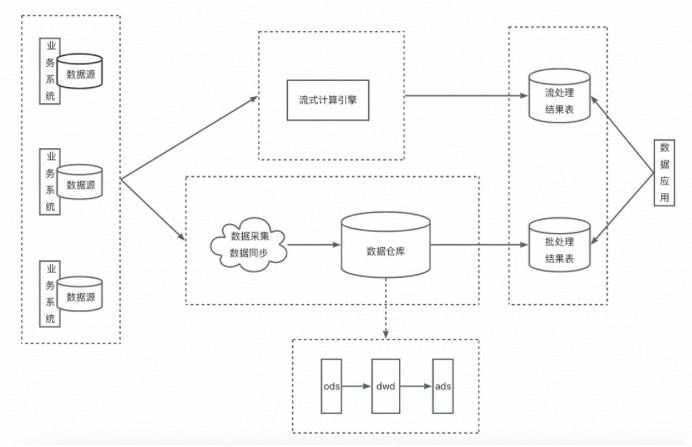
Lambda架構的邏輯是,流任務與批任務讀取相同的數據源,實時計算結果由流任務產出;批任務通常按天執行,計算T-1的數據,并寫入到結果表中。最終數據應用根據自己的需要對兩個結果表的結果進行合并。其核心思路是:用流任務保證結果的實時性,同時用批任務保證結果的最終一致性。
據我觀察,凡是對結果有實時性要求的業務團隊,在數據側基本都采用的是這種架構。但Lambda架構有幾個顯而易見的缺點:
1.需要開發、維護兩套系統,成本太大。
2.兩套系統難以保證計算口徑的一致。甚至不同計算引擎提供的計算語義完全不同。
總之,Lambda架構在滿足了部分業務需求的同時,給開發和運維同學也帶來了“深重的災難”。懂的都懂。
因此,我每每看到Lambda架構這種硬把批和流雜糅在一起的架構,都不免想起周星馳《少林足球》中的臺詞:
“少林功夫+唱歌跳舞,你說有沒有搞頭啊。”
”沒搞頭。“
”不試試你怎么知道沒搞頭。“
說完還邊唱邊跳:“少林功夫好耶,真是好。”?
如果說流式架構好比是人用一條腿走路,存在先天性的不足,那么Lambda架構就是走路時一條腿長一條腿短。
Kappa架構
雖然Lambda架構存在這么多缺點,但有行業大佬背書,并且在現有技術限制下,也很難提出更好的解決方案,故天下數(據)開(發),不敢言而敢怒,只等某一天“戍卒叫,函谷舉”。終于等到了另一位大佬Jay Kreps提出了一種新的架構方案——Kappa架構。?
在流處理技術不成熟的時期,主要問題之一就是吞吐量上不去。隨著Kafka等大數據消息隊列的出現,吞吐量不再是瓶頸。Kappa架構的主要貢獻之一就是引入了分布式消息隊列。如下圖所示:
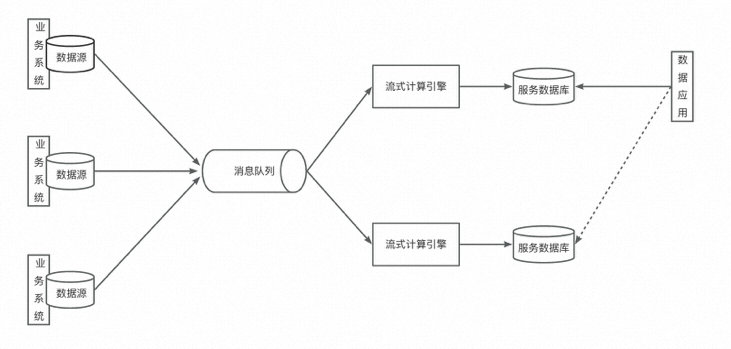
?與Lambda架構不通,Kappa架構只保留了流處理層,完全舍棄了批處理層。讓其中一個流處理層正常運行,數據應用讀取它的輸出;當數據出現錯誤,或是業務邏輯發生變更時,啟動另一個流處理層,利用消息隊列的重播機制,重新消費先前的數據并輸出到另一個結果表中,當確定可以替換線上表時,完成替換。?
當然,在實際生產中這個過程會復雜得多。而且受限于消息隊列數據生命周期的限制,這種架構在生產中被應用得較少。
不過,Kappa架構的另一貢獻是啟發了人們用單一系統去實現曾經需要兩套系統才能實現的需求。人們開始思考:為什么流式計算引擎不能提供結果的準確性?是哪些環節出了問題?如果流處理能夠保證結果準確性,是否意味著重啟流任務的需要大大降低,是否意味著Kappa架構能夠徹底取代Lambda架構?流處理引擎是否可以實現批處理引擎等價的語義?
后續文章將會通過對Flink底層技術細節的介紹來回答上述問題。在此之前,讓我們先脫離具體技術選型,來看看流批一體與上述架構的關系。
三、流批一體與數據架構的關系
流批一體聽起來很簡單,但內涵卻十分復雜。它包含了計算語義、編程模型、API、調度、執行、shuffle等各個方面的統一,不過對于我們數據開發的同學來說,我認為流批一體最終想要達到的效果可以這樣描述:給定確定的數據源(可以是物理的也可以是邏輯上的),編寫一套代碼(Java代碼或SQL),執行引擎能夠根據需要(例如根據用戶配置“STREAMING/BATCH”或自動識別)將代碼轉換為流任務(增量地讀取、流式地處理)或批任務(全量地讀取、批式地處理),并輸出相同的結果。
可以認為這是計算引擎發展到一定階段后固有的一個能力,用戶可以使用也可以不使用,可以通過配置將其當作單純的流式/批式計算引擎也是一種選擇。
現在我們討論的,是在同一個應用中,同時使用兩種模式(手動配置或自動識別/切換)。而具體如何使用流批一體,要根據應用類型而定,這既決定了流批一體與數據架構的關系,也體現了流批一體在不同場景下的價值。
數據分析型應用
數據側的同學開發的絕大多數應用都屬于數據分析型應用。上一節的所有數據架構也基本是為這種應用設計的。在這種應用中,流批一體與Lambda架構結合得最為自然。如下圖所示:?
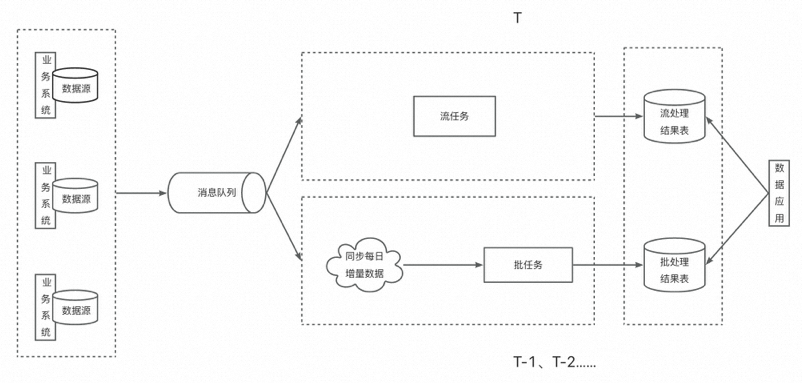
這里引入了消息隊列,算是Jay Kreps在提出Kappa架構時給我們提供的改進思路。由于流任務和批任務用的是同一套代碼,我們默認計算引擎內部已經實現了語義的統一,因此核心問題在于如何上輸入統一。輸出結果可以是不同的表,也可以是相同的表,根據需要而定,這并沒有太大影響。?
因為流任務和批任務對輸入的要求是不一樣的,前者一般讀取的都是類似Kafka這樣的消息流,后者則讀取的是數據庫在某一刻的全量快照,所以我們暫且認為兩個任務需要用不同的連接器讀取不同的數據源。為了保證輸入統一,我們可以讓流任務直接讀取消息隊列中的數據,這樣它就在一刻不停地讀取業務上的增量數據;在離線側,我們周期性地將消息隊列中的數據落盤,然后每日單獨處理當天的增量數據,由此批任務也達成了周期性處理增量數據的效果。理想情況下,當批任務把T-1的數據輸出時,結果應與流任務先前輸出的T-1的結果相同。
這就是流批一體在數據分析型應用中的典型案例,它是Lambda架構的一種高級實現,解決了原Lambda架構中需要開發兩套代碼、維護兩套系統、計算邏輯口徑不一致的問題。Dataphin提供給大家的解決方案就是針對這種應用而來的。
不過要特別注意的是,計算邏輯口徑一致不是因為你使用了相同的代碼,而是基于相同的代碼,計算引擎內部將其翻譯成批任務和流任務時在語義、編程模型等方面達到了統一。如果計算引擎內部沒有做到這一點,即便寫了相同的代碼也是無濟于事的。
數據管道型應用
除了數據分析型應用,還有一類應用,比如數據同步,這部分工作其實也可以通過計算引擎來實現,流批一體在這其中還能發揮大作用。這類應用可以叫做數據管道型應用。?
比如需求是將一個線上數據庫中的數據遷移到另一個數據庫中,在同步的過程中線上數據庫仍然會繼續發生增刪改查等業務操作。以往的方式往往是先通過一個離線同步工具同步全量數據,再通過另一個增量同步工具不斷地同步新增數據。在這個過程中選擇從哪一時刻開始增量同步是一大難點。如果在同步的過程中需要對數據做一些清洗或轉換,則難度又大了一截。
而通過計算引擎的流批一體能力和對應的connector,則可以解決上述問題。我們可以直接通過寫SQL的方式聲明數據轉換的邏輯,配合connector的能力,計算引擎會先批量讀取數據,然后在某一時刻自動切換成流任務增量讀取后續數據,而計算引擎內部流批一體的能力保證了語義的相同。
例如Flink CDC項目就是在做這樣的事。不過在此場景中Flink runtime是否有流和批的區別,這一點我并沒有核實。?
不管怎么說,這也可以算是廣義的流批一體的應用。并且,利用此技術,還可以實現實時數倉的建設,這在后續文章中或許會提到,大家也可以直接參考其他文章。
四、總結
數據架構經歷了如下演變:
早期BI系統 --> 傳統大數據架構(解決數據量的問題,但業務延遲高)
傳統大數據架構 --> 流式架構(解決業務延遲問題,但數據準確性低)
流式架構 --> Lambda架構(解決數據準確性低的問題,用實時層保證低延遲,用離線層保證數據最終一致性,但架構復雜、計算邏輯口徑難以一致)
Lambda架構 --> Kappa架構(解決架構冗余問題和計算邏輯口徑不一致的問題,但消息隊列數據生命周期短)
最終,在Lambda架構的基礎上采用了流批一體實現方案,使得系統復雜度降低,計算邏輯口徑達成一致。
流批一體當然也能用在其他架構中,以Flink為例,利用Flink CDC技術還能有更多玩法,但Lambda架構這一案例在我看來是能夠最直觀展示流批一體這一技術在數據架構中的位置和作用的。?
審核編輯:劉清
-
SQL
+關注
關注
1文章
775瀏覽量
44254 -
ADS仿真
+關注
關注
1文章
71瀏覽量
10506 -
流處理器
+關注
關注
1文章
45瀏覽量
9421 -
MYSQL數據庫
+關注
關注
0文章
96瀏覽量
9453 -
odps
+關注
關注
0文章
3瀏覽量
2573
原文標題:深入淺出流批一體理論篇——數據架構的演進
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
緩存對大數據處理的影響分析
raid 在大數據分析中的應用
emc技術在大數據分析中的角色
SD NAND在大數據時代的應用場景

智慧城市與大數據的關系
云計算在大數據分析中的應用
基于Kepware的Hadoop大數據應用構建-提升數據價值利用效能
【「大模型時代的基礎架構」閱讀體驗】+ 未知領域的感受
使用CYW20829的BLE進行最大數據發送應用,BLE丟失數據如何解決?
大數據在部隊管理中的運用有哪些
分布式存儲與計算:大數據時代的解決方案
CYBT-343026傳輸大數據時會丟數據的原因?
簡析大數據技術下智能充電樁在網絡系統中的應用
淺析大數據時代下的數據中心運維管理






 工商網監
工商網監
評論