") 使用 DLA 在 NVIDIA Jetson Orin 上最大限度地提高深度學(xué)習(xí)性能
使用 DLA 在 NVIDIA Jetson Orin 上最大限度地提高深度學(xué)習(xí)性能

NVIDIA Jetson Orin 是同類(lèi)嵌入式人工智能平臺(tái)中的翹楚。Jetson Orin SoC 模塊以 NVIDIA Ampere 架構(gòu) GPU 為核心,但 SoC 上還有更多的計(jì)算功能:
-
深度學(xué)習(xí)加速器(DLA)中用于深度學(xué)習(xí)工作負(fù)載的專(zhuān)用深度學(xué)習(xí)推理引擎
-
用于圖像處理和計(jì)算機(jī)視覺(jué)算法的可編程視覺(jué)加速器(PVA)引擎
NVIDIA Orin SoC 的功能非常強(qiáng)大,擁有 275 個(gè)峰值 AI TOPs,是最佳的嵌入式和汽車(chē) AI 平臺(tái)。您知道嗎,這些 AI TOPs 中近 40% 來(lái)自 NVIDIA Orin 上的兩個(gè) DLA?NVIDIA Ampere GPU 擁有同類(lèi)產(chǎn)品中最佳的吞吐量,而第二代 DLA 則擁有同類(lèi)產(chǎn)品中最佳的能效。近年來(lái),隨著 AI 應(yīng)用的快速增長(zhǎng),對(duì)更高效計(jì)算的需求也在不斷增長(zhǎng)。在能效始終是關(guān)鍵 KPI 的嵌入式方面尤其如此。
這就是 DLA 的用武之地。DLA 專(zhuān)門(mén)為深度學(xué)習(xí)推理而設(shè)計(jì),可以比 CPU 更有效地執(zhí)行卷積等計(jì)算密集型深度學(xué)習(xí)操作。
當(dāng)集成到 SoC(如Jetson AGX Orin 或 NVIDIA DRIVE Orin)中時(shí), GPU 和 DLA 的組合可以為您的嵌入式 AI 應(yīng)用程序提供一個(gè)完整的解決方案。我們將在這篇文章中討論深度學(xué)習(xí)加速器,讓您不再錯(cuò)過(guò)。我們將介紹涵蓋汽車(chē)和機(jī)器人領(lǐng)域的幾個(gè)案例研究,以展示 DLA 如何幫助 AI 開(kāi)發(fā)者為其應(yīng)用程序添加更多功能和性能。最后,我們將介紹視覺(jué) AI 開(kāi)發(fā)者如何使用 DeepStream SDK 構(gòu)建應(yīng)用工作流,使用 DLA 和整個(gè) Jetson SoC 實(shí)現(xiàn)最佳性能。
以下是 DLA 會(huì)產(chǎn)生重大影響的一些關(guān)鍵性能指標(biāo)。
關(guān)鍵性能指標(biāo)
在設(shè)計(jì)應(yīng)用程序時(shí),您需要滿(mǎn)足一些關(guān)鍵性能指標(biāo)或 KPI。例如最大性能和能效之間的設(shè)計(jì)權(quán)衡,這需要開(kāi)發(fā)團(tuán)隊(duì)仔細(xì)分析和設(shè)計(jì)應(yīng)用程序,以便在 SoC 上使用不同的 IP。
如果應(yīng)用程序的關(guān)鍵 KPI 是延遲,則必須在一定的延遲預(yù)算下在應(yīng)用程序中安排任務(wù)。您可以將 DLA 作為加速器,用于與運(yùn)行在 GPU 上的計(jì)算密集型任務(wù)并行的任務(wù)。DLA 峰值性能對(duì) NVIDIA Orin 整體深度學(xué)習(xí)(DL)性能的貢獻(xiàn)率在 38% 至 74% 之間,具體取決于電源模式。
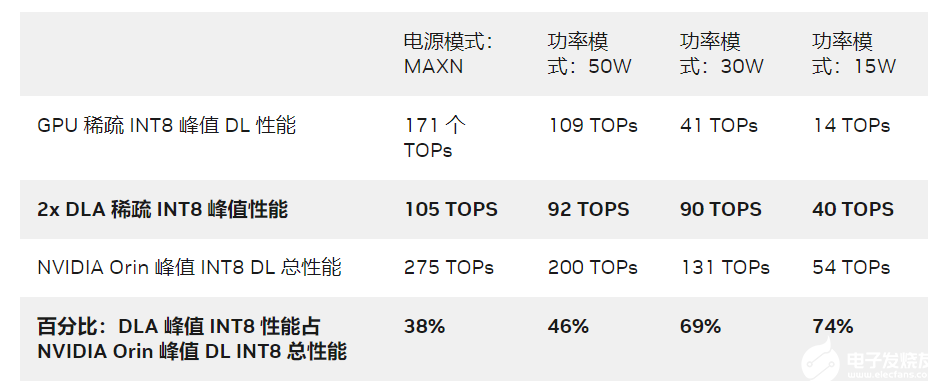
表 1. DLA 吞吐量
Jetson AGX Orin 64GB 上 30W 和 50W 功率模式的 DLA TOPs 與 NVIDIA DRIVE Orin 汽車(chē)平臺(tái)上的最大時(shí)鐘相當(dāng)。
如果功耗是您的關(guān)鍵 KPI 之一,那么就應(yīng)該考慮使用 DLA 來(lái)利用其功耗效率方面的優(yōu)勢(shì)。與 GPU 相比,每瓦 DLA 的性能平均高出 3–5 倍,這具體取決于電源模式和工作負(fù)載。以下圖表顯示了代表常見(jiàn)用例的三個(gè)模型的每瓦性能。
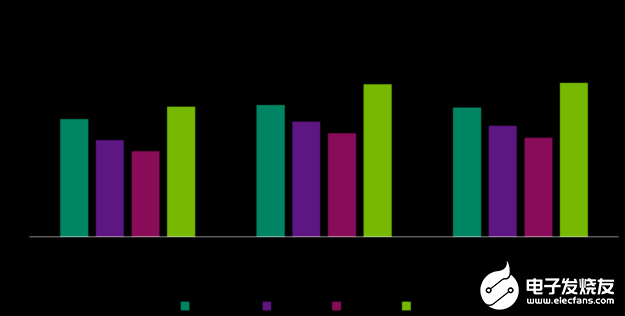
圖 1. DLA 能效
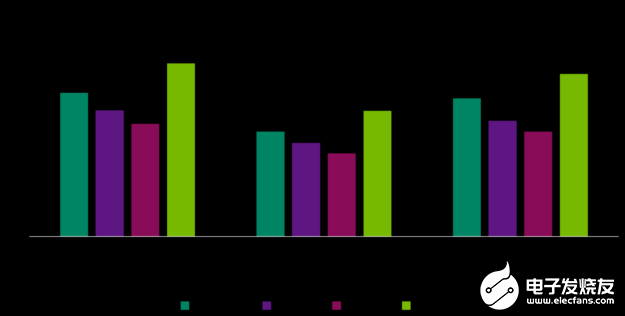
圖 2. 結(jié)構(gòu)化稀疏性和每瓦性能優(yōu)勢(shì)
換句話(huà)說(shuō),如果沒(méi)有 DLA 的能效,就不可能在給定的平臺(tái)功率預(yù)算下在 NVIDIA Orin 上實(shí)現(xiàn)高達(dá) 275 個(gè)峰值的 DL TOPs。想要了解更多信息和更多型號(hào)的測(cè)量結(jié)果,請(qǐng)參閱 DLA-SW GitHub 庫(kù)。
以下是 NVIDIA 內(nèi)部如何在汽車(chē)和機(jī)器人領(lǐng)域使用 DLA 提供的 AI 計(jì)算的一些案例研究。
案例研究:汽車(chē)
NVIDIA DRIVE AV是端到端的自動(dòng)駕駛解決方案堆棧,可幫助汽車(chē)原始設(shè)備制造商在其汽車(chē)產(chǎn)品組合中添加自動(dòng)駕駛和映射功能。它包括感知層、映射層和規(guī)劃層,以及基于高質(zhì)量真實(shí)駕駛數(shù)據(jù)訓(xùn)練的各種 DNN。
NVIDIA DRIVE AV 團(tuán)隊(duì)的工程師致力于設(shè)計(jì)和優(yōu)化感知、映射,并通過(guò)利用整個(gè) NVIDIA Orin SoC 平臺(tái)規(guī)劃工作流。考慮到自動(dòng)駕駛堆棧中需要處理大量的神經(jīng)網(wǎng)絡(luò)和其他非 DNN 任務(wù),它們會(huì)依靠 DLA 作為 NVIDIA Orin SoC 上的專(zhuān)用推理引擎來(lái)運(yùn)行 DNN 任務(wù)。這一點(diǎn)至關(guān)重要,因?yàn)?GPU 計(jì)算能力是為處理非 DNN 任務(wù)而保留的。如果沒(méi)有 DLA 計(jì)算,團(tuán)隊(duì)將無(wú)法達(dá)到 KPI。
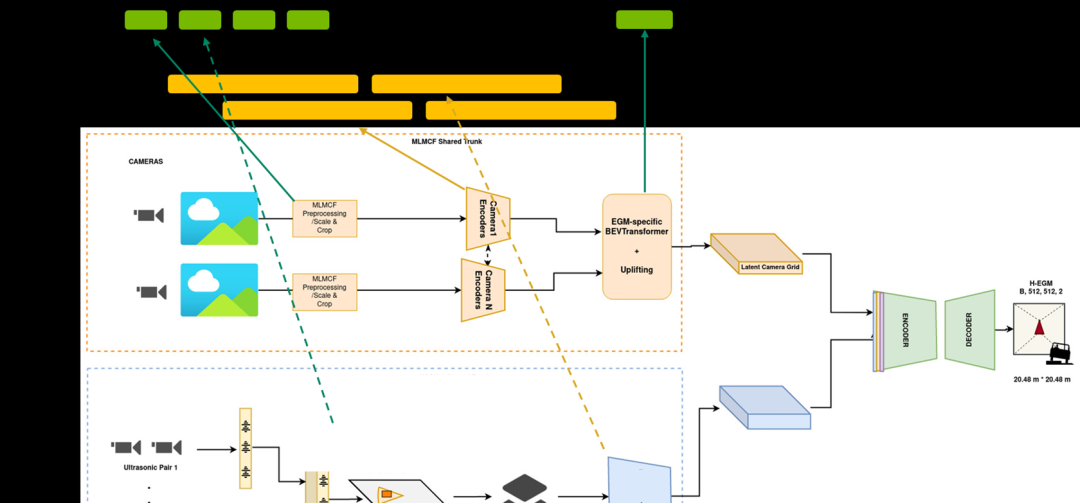
圖3.感知管線(xiàn)的一部分
想要了解更多信息,請(qǐng)?jiān)L問(wèn)Near-Range Obstacle Perception with Early Grid Fusion:https://developer.nvidia.cn/zh-cn/blog/near-range-obstacle-perception-with-early-grid-fusion/
例如,在感知工作流中,它們有來(lái)自八個(gè)不同相機(jī)傳感器的輸入,整個(gè)工作流的延遲必須低于某個(gè)閾值。感知堆棧是 DNN 的重頭戲,占所有計(jì)算的 60% 以上。
為了達(dá)到這些 KPI,并行工作流任務(wù)被映射到 GPU 和 DLA,其中幾乎所有的 DNN 都在 DLA 上運(yùn)行,而非 DNN 任務(wù)則在 GPU 上運(yùn)行,以實(shí)現(xiàn)總體工作流的延遲目標(biāo)。然后,其他 DNN 在映射和規(guī)劃等其他工作流中按順序或并行消耗輸出。您可以將工作流視為一個(gè)巨大的圖形,其中的任務(wù)在 GPU 和 DLA 上并行運(yùn)行。通過(guò)使用 DLA,該團(tuán)隊(duì)將延遲降低了 2.5 倍。

圖 4. 作為感知堆棧一部分的對(duì)象檢測(cè)
NVIDIA 自動(dòng)駕駛團(tuán)隊(duì)工程經(jīng)理 Abhishek Bajarger 表示:“利用整個(gè) SoC,特別是 DLA 中專(zhuān)用的深度學(xué)習(xí)推理引擎,使我們能夠在滿(mǎn)足延遲要求和 KPI 目標(biāo)的同時(shí),為軟件堆棧添加重要功能。只有 DLA 才能做到這一點(diǎn)。”
案例研究:機(jī)器人
NVIDIA Isaac 是一個(gè)功能強(qiáng)大的端到端平臺(tái),用于開(kāi)發(fā)、仿真和部署機(jī)器人開(kāi)發(fā)者使用的 AI 機(jī)器人。特別是對(duì)于移動(dòng)機(jī)器人來(lái)說(shuō),可用的 DL 計(jì)算、確定性延遲和電池續(xù)航能力是非常重要的因素。這就是為什么將 DL 推理映射到 DLA 非常重要的原因。
NVIDIA Isaac 團(tuán)隊(duì)的一組工程師開(kāi)發(fā)了一個(gè)使用 DNN 進(jìn)行臨近分割的庫(kù)。鄰近分割可用于確定障礙物是否在鄰近場(chǎng)內(nèi),并避免在導(dǎo)航過(guò)程中與障礙物發(fā)生碰撞。他們?cè)?DLA 上實(shí)現(xiàn)了 BI3D 網(wǎng)絡(luò),該網(wǎng)絡(luò)可通過(guò)立體攝像頭執(zhí)行二進(jìn)制深度分類(lèi)。
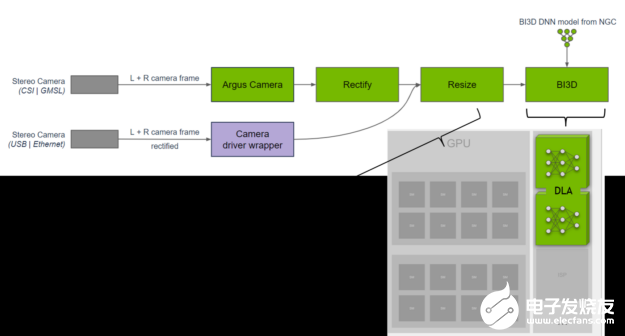
圖 5. 近距離分割流水線(xiàn)
一個(gè)關(guān)鍵的 KPI 是確保從立體攝像頭輸入進(jìn)行 30 幀/秒的實(shí)時(shí)檢測(cè)。NVIDIA Isaac 團(tuán)隊(duì)將這些任務(wù)分配到 SoC 上,并將 DLA 用于 DNN,同時(shí)為在 GPU 上運(yùn)行的硬件和軟件提供功能安全多樣性。想要了解更多信息,請(qǐng)?jiān)L問(wèn)NVIDIA Isaac ROS 鄰近分割:https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_proximity_segmentation

圖 6. 使用 BI3D 對(duì)立體輸入進(jìn)行鄰近分割
將 NVIDIA DeepStream 用于 DLA
探索 DLA 最快捷的方式是通過(guò) NVIDIA DeepStream SDK,一個(gè)完整的流分析工具包。
如果你是一名視覺(jué) AI 開(kāi)發(fā)者,正在構(gòu)建 AI 驅(qū)動(dòng)的應(yīng)用程序來(lái)分析視頻和傳感器數(shù)據(jù),那么 DeepStream SDK 可以幫助您構(gòu)建最佳的端到端工作流。對(duì)于零售分析、停車(chē)管理、物流管理、光學(xué)檢測(cè)、機(jī)器人技術(shù)和體育分析等云端或邊緣用例,DeepStream 可讓您不費(fèi)吹灰之力就能使用整個(gè) SoC,特別是 DLA。
例如,您可以使用下表中突出顯示的 Model Zoo 中的預(yù)訓(xùn)練模型在 DLA 上運(yùn)行。在 DLA 上運(yùn)行這些網(wǎng)絡(luò)就像設(shè)置一個(gè)標(biāo)志一樣簡(jiǎn)單。想要了解更多信息,請(qǐng)?jiān)L問(wèn)如何使用 DLA 進(jìn)行推理:https://docs.nvidia.com/metropolis/deepstream/dev-guide/text/DS_Quickstart.html#using-dla-for-inference
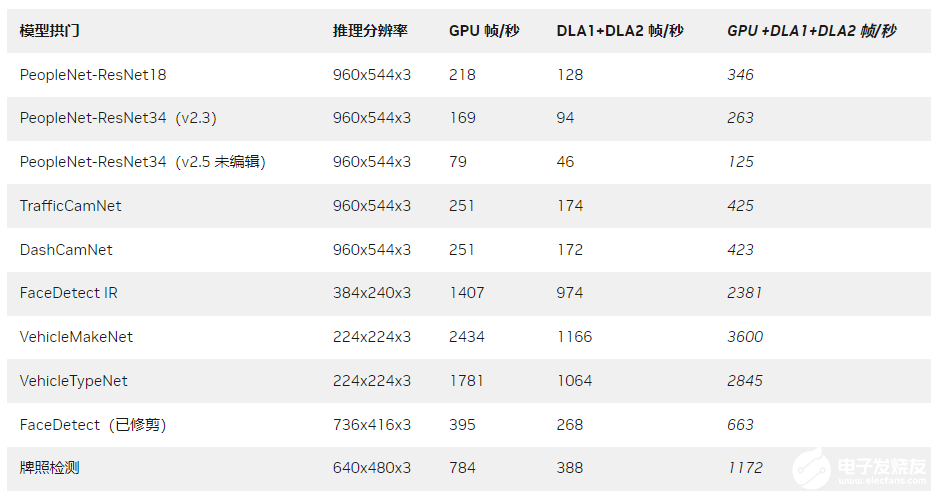
表 2. Model Zoo 網(wǎng)絡(luò)樣本
及其在 DLA 上的吞吐量
開(kāi)始使用深度學(xué)習(xí)加速器
準(zhǔn)備好深入了解了嗎?有關(guān)詳細(xì)信息,請(qǐng)參閱以下資源:
-
Jetson DLA 教程演示了基本的 DLA 工作流,幫助您開(kāi)始將 DNN 部署到 DLA:https://github.com/NVIDIA-AI-IOT/jetson_dla_tutorial
-
DLA-SW GitHub存儲(chǔ)庫(kù)中有一系列參考網(wǎng)絡(luò),您可以使用它們來(lái)探索在 Jetson Orin DLA 上運(yùn)行 DNN:https://github.com/NVIDIA/Deep-Learning-Accelerator-SW/tree/main/scripts/prepare_models
-
示例頁(yè)面提供了關(guān)于如何使用 DLA 充分利用 Jetson SoC 的其他示例和資源:https://github.com/NVIDIA/Deep-Learning-Accelerator-SW/
-
DLA 論壇有其他用戶(hù)的想法和反饋:https://forums.developer.nvidia.com/tag/dla
SIGGRAPH 2023
NVIDIA 精彩發(fā)布
SIGGRAPH 2023 | NVIDIA 主題演講重磅發(fā)布精彩回顧,探索 AI 無(wú)限未來(lái)!
敬請(qǐng)持續(xù)關(guān)注...
SIGGRAPH 2023 NVIDIA 主題演講中文字幕版已上線(xiàn) !掃描下方海報(bào)二維碼,或點(diǎn)擊“閱讀原文”即可觀看,與 NVIDIA 創(chuàng)始人兼首席執(zhí)行官黃仁勛一起探索 AI 的未來(lái)!
原文標(biāo)題:使用 DLA 在 NVIDIA Jetson Orin 上最大限度地提高深度學(xué)習(xí)性能
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3847瀏覽量
91970
原文標(biāo)題:使用 DLA 在 NVIDIA Jetson Orin 上最大限度地提高深度學(xué)習(xí)性能
文章出處:【微信號(hào):NVIDIA_China,微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
智能電機(jī)控制裝置如何最大限度地提高恢復(fù)能力和正常運(yùn)行時(shí)間
NVIDIA發(fā)布小巧高性?xún)r(jià)比的Jetson Orin Nano Super開(kāi)發(fā)者套件
初創(chuàng)公司借助NVIDIA Metropolis和Jetson提高生產(chǎn)線(xiàn)效率
TAS5630如何才能最大限度地減少電壓失調(diào),或者調(diào)節(jié)為0?
Orin芯片在汽車(chē)行業(yè)的應(yīng)用
Orin芯片功耗分析
Orin芯片與其他芯片對(duì)比
最大限度地提高MSP430? FRAM的寫(xiě)入速度

最大限度地減少TPS53355和TPS53353系列器件的開(kāi)關(guān)振鈴
最大限度地提高GSPS ADC中的SFDR性能:雜散源和Mitigat方法
利用智能eFuses最大限度地縮短系統(tǒng)停機(jī)時(shí)間
最大限度地減少UCC287XX系列的待機(jī)消耗
如何在C2000設(shè)備中最大限度地利用GPIO
通過(guò)優(yōu)化補(bǔ)償最大限度地減少導(dǎo)通時(shí)間抖動(dòng)和紋波
NVIDIA Jetson Orin系列邊緣計(jì)算主機(jī)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論