") 大語言模型“書生·浦語”多項(xiàng)專業(yè)評(píng)測(cè)拔頭籌
大語言模型“書生·浦語”多項(xiàng)專業(yè)評(píng)測(cè)拔頭籌
最近,AI大模型測(cè)評(píng)火熱,尤其在大語言模型領(lǐng)域,“聰明”的上限被不斷刷新。
“SuperCLUE是由創(chuàng)立于2019年的CLUE學(xué)術(shù)社區(qū)最新發(fā)布的中文通用大模型綜合性評(píng)測(cè)基準(zhǔn),包含SuperCLUE-Opt客觀題測(cè)試、SuperCLUE-Open主觀題測(cè)試、SuperCLUE-LYB瑯琊榜用戶投票的匿名對(duì)戰(zhàn)測(cè)試三大基準(zhǔn)組成。為更好地反映國內(nèi)大模型與國際領(lǐng)先大模型間的差距和優(yōu)勢(shì),SuperCLUE選取了多個(gè)國內(nèi)外有代表性的可用模型進(jìn)行評(píng)測(cè),同時(shí)由于其數(shù)據(jù)集保密性高,對(duì)大模型來說是‘閉卷考試’,減少了模型訓(xùn)練數(shù)據(jù)混入評(píng)測(cè)數(shù)據(jù)的可能性。此外,SuperCLUE還通過自動(dòng)化評(píng)測(cè)方式測(cè)試不同模型效果,可一鍵對(duì)大模型進(jìn)行評(píng)測(cè),相對(duì)更客觀。” “書生·浦語”:不僅善于考試,還是開源大模型中的佼佼者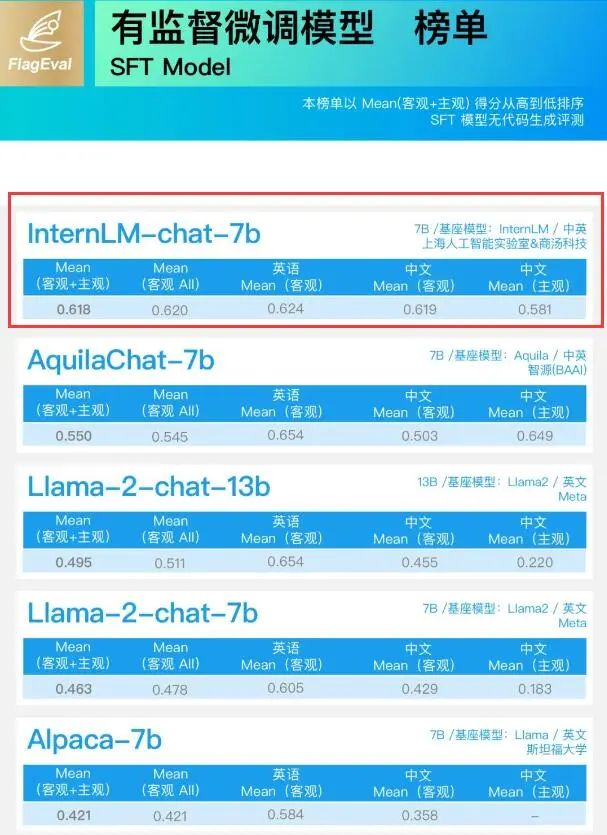
 ?
? ?作為SuperCLUE綜合性三大基準(zhǔn)之一,SuperCLUE-Opt評(píng)測(cè)基準(zhǔn)每期有3700+道客觀題(選擇題),由基礎(chǔ)能力(10個(gè)子任務(wù))、中文特性能力(10個(gè)子任務(wù))、學(xué)術(shù)專業(yè)能力(50+子任務(wù))組成,采用封閉域測(cè)試方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在學(xué)術(shù)專業(yè)方面取得較大領(lǐng)先,同時(shí)全面領(lǐng)先于第三名Baichuan-13B-Chat。
?作為SuperCLUE綜合性三大基準(zhǔn)之一,SuperCLUE-Opt評(píng)測(cè)基準(zhǔn)每期有3700+道客觀題(選擇題),由基礎(chǔ)能力(10個(gè)子任務(wù))、中文特性能力(10個(gè)子任務(wù))、學(xué)術(shù)專業(yè)能力(50+子任務(wù))組成,采用封閉域測(cè)試方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在學(xué)術(shù)專業(yè)方面取得較大領(lǐng)先,同時(shí)全面領(lǐng)先于第三名Baichuan-13B-Chat。
商湯與上海AI實(shí)驗(yàn)室等聯(lián)合打造的大語言模型“書生·浦語”(InternLM)也表現(xiàn)出色,分別在智源FlagEval大語言模型評(píng)測(cè)8月排行榜和中文通用大模型綜合性評(píng)測(cè)基準(zhǔn)SuperCLUE 7月評(píng)測(cè)榜兩項(xiàng)業(yè)內(nèi)權(quán)威大模型評(píng)測(cè)榜單中獲得優(yōu)異成績。 “FlagEval是知名人工智能新型研發(fā)機(jī)構(gòu)北京智源人工智能研究院推出的大模型評(píng)測(cè)體系及開放平臺(tái)。FlagEval大模型評(píng)測(cè)體系構(gòu)建了“能力-任務(wù)-指標(biāo)”三維評(píng)測(cè)框架,可視化呈現(xiàn)評(píng)測(cè)結(jié)果,總計(jì)600+評(píng)測(cè)維度,包括22個(gè)主觀、客觀評(píng)測(cè)數(shù)據(jù)集,84433道評(píng)測(cè)題目。除知名的公開數(shù)據(jù)集 HellaSwag、MMLU、C-Eval外,F(xiàn)lagEval還集成了包括智源自建的主觀評(píng)測(cè)數(shù)據(jù)集Chinese Linguistics & Cognition Challenge (CLCC),北京大學(xué)等單位共建的詞匯級(jí)別語義關(guān)系判斷、句子級(jí)別語義關(guān)系判斷、多義詞理解、修辭手法判斷評(píng)測(cè)數(shù)據(jù)集。”
“SuperCLUE是由創(chuàng)立于2019年的CLUE學(xué)術(shù)社區(qū)最新發(fā)布的中文通用大模型綜合性評(píng)測(cè)基準(zhǔn),包含SuperCLUE-Opt客觀題測(cè)試、SuperCLUE-Open主觀題測(cè)試、SuperCLUE-LYB瑯琊榜用戶投票的匿名對(duì)戰(zhàn)測(cè)試三大基準(zhǔn)組成。為更好地反映國內(nèi)大模型與國際領(lǐng)先大模型間的差距和優(yōu)勢(shì),SuperCLUE選取了多個(gè)國內(nèi)外有代表性的可用模型進(jìn)行評(píng)測(cè),同時(shí)由于其數(shù)據(jù)集保密性高,對(duì)大模型來說是‘閉卷考試’,減少了模型訓(xùn)練數(shù)據(jù)混入評(píng)測(cè)數(shù)據(jù)的可能性。此外,SuperCLUE還通過自動(dòng)化評(píng)測(cè)方式測(cè)試不同模型效果,可一鍵對(duì)大模型進(jìn)行評(píng)測(cè),相對(duì)更客觀。” “書生·浦語”:不僅善于考試,還是開源大模型中的佼佼者
“書生·浦語”,是商湯科技、上海AI實(shí)驗(yàn)室聯(lián)合香港中文大學(xué)、復(fù)旦大學(xué)及上海交通大學(xué)打造的大語言模型,具有千億參數(shù),在包含1.8萬億token的高質(zhì)量語料上訓(xùn)練而成。
今年6月,“書生·浦語”聯(lián)合團(tuán)隊(duì)曾選取20余項(xiàng)評(píng)測(cè)進(jìn)行檢驗(yàn),包括全球最具影響力的四個(gè)綜合性考試評(píng)測(cè)。結(jié)果顯示,“書生·浦語”在綜合性考試中表現(xiàn)突出,在多項(xiàng)中文考試中超越ChatGPT。(詳情可參考「AI考生今日抵達(dá),商湯與上海AI實(shí)驗(yàn)室等發(fā)布“書生·浦語”大模型」報(bào)道) 7月,“書生·浦語”正式開源70億參數(shù)的輕量級(jí)版本InternLM-7B。(https://github.com/InternLM/InternLM)
后續(xù)又推出升級(jí)版對(duì)話模型InternLM-Chat-7Bv1.1,成為首個(gè)具有代碼解釋能力的開源對(duì)話模型,能根據(jù)需要靈活調(diào)用Python解釋器等外部工具,解決復(fù)雜數(shù)學(xué)計(jì)算等任務(wù)的能力顯著提升。
此外,該模型還可通過搜索引擎獲取實(shí)時(shí)信息,提供具有時(shí)效性的回答。
在北京智源人工智能研究院FlagEval大語言模型評(píng)測(cè)體系8月最新排行榜中, “InternLM-chat-7B”和“InternLM-7B”分別在監(jiān)督微調(diào)模型(SFT Model)榜單、基座模型(Base Model)榜單中取得第一和第二名。
“InternLM-chat-7B”還刷新中英客觀評(píng)測(cè)記錄。 「什么是“基座模型”、“有監(jiān)督微調(diào)模型”?」 基座模型(Base Model)是經(jīng)過海量數(shù)據(jù)預(yù)訓(xùn)練(Pre-train)得到的,它具備一定的通用能力,比如:GPT-3。 有監(jiān)督微調(diào)模型(SFT Model)則是經(jīng)過指令微調(diào)數(shù)據(jù)(包含了各種與人類行為及情感相關(guān)的指令和任務(wù)的數(shù)據(jù)集)訓(xùn)練后得到的,具備了與人類流暢對(duì)話的能力,如:ChatGPT。 普遍的觀點(diǎn)認(rèn)為,基座模型在很大程度上決定了微調(diào)模型的能力。 因此,F(xiàn)lagEval大語言模型評(píng)測(cè)體系針對(duì)基座模型的評(píng)測(cè)主要從“提示學(xué)習(xí)評(píng)測(cè)”和“適配評(píng)測(cè)”兩方面進(jìn)行;針對(duì)有監(jiān)督微調(diào)模型的評(píng)測(cè)則從“復(fù)用針對(duì)基座模型的客觀評(píng)測(cè)” 進(jìn)一步增加“引入主觀評(píng)測(cè)”。 此次兩個(gè)榜單中,“InternLM-chat-7B”和“InternLM-7B”均表現(xiàn)出優(yōu)異的綜合性能,超越備受關(guān)注的Llama2-chat-13B/7B和Llama2-13B/7B。 特別在SFT Model測(cè)試中,InternLM-chat-7B中文能力大幅領(lǐng)先同時(shí),英文能力也與對(duì)手保持在相近水平,展現(xiàn)出更強(qiáng)的實(shí)用性能。
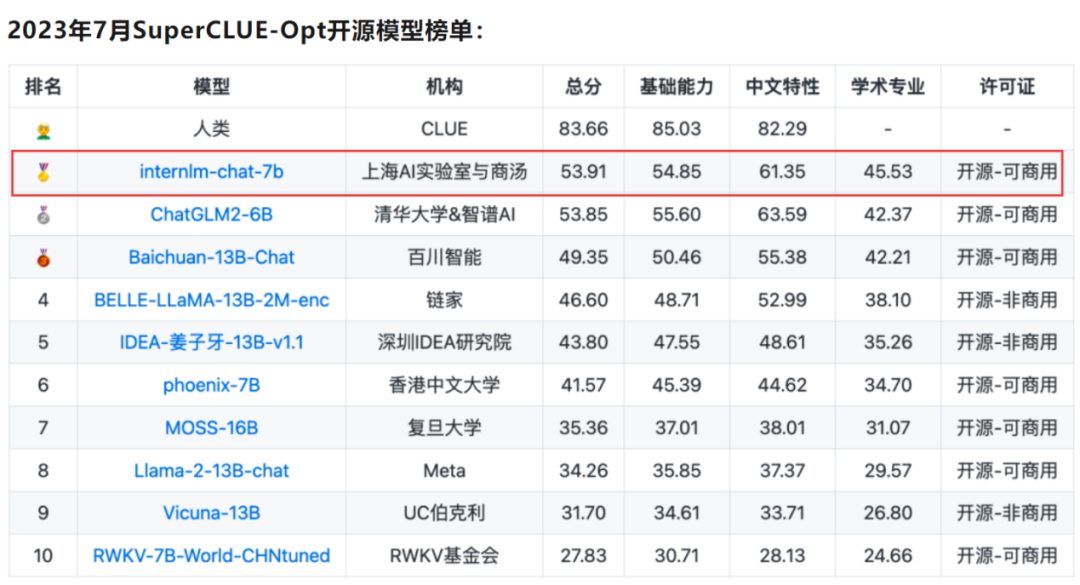
?SuperCLUE評(píng)測(cè)從基礎(chǔ)能力、專業(yè)能力、中文特性能力三個(gè)不同維度對(duì)國內(nèi)外通用大模型產(chǎn)品進(jìn)行評(píng)價(jià),考察大模型在70余個(gè)任務(wù)上的綜合表現(xiàn)。
“書生·浦語”InternLM-chat-7B在7月公布SuperCLUE評(píng)測(cè)榜單中表現(xiàn)出色,在SuperCLUE-Opt開源大模型榜單拔得頭籌。
?作為SuperCLUE綜合性三大基準(zhǔn)之一,SuperCLUE-Opt評(píng)測(cè)基準(zhǔn)每期有3700+道客觀題(選擇題),由基礎(chǔ)能力(10個(gè)子任務(wù))、中文特性能力(10個(gè)子任務(wù))、學(xué)術(shù)專業(yè)能力(50+子任務(wù))組成,采用封閉域測(cè)試方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在學(xué)術(shù)專業(yè)方面取得較大領(lǐng)先,同時(shí)全面領(lǐng)先于第三名Baichuan-13B-Chat。

相關(guān)閱讀,戳這里
《讓大模型“百花齊放”,商湯大裝置SenseCore提供一片沃土》《商湯發(fā)布多模態(tài)多任務(wù)通用大模型“書生2.5”》
《商湯聯(lián)合發(fā)布通才AI智能體通關(guān)<我的世界>》

原文標(biāo)題:大語言模型“書生·浦語”多項(xiàng)專業(yè)評(píng)測(cè)拔頭籌
文章出處:【微信公眾號(hào):商湯科技SenseTime】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
商湯科技
+關(guān)注
關(guān)注
8文章
518瀏覽量
36175
原文標(biāo)題:大語言模型“書生·浦語”多項(xiàng)專業(yè)評(píng)測(cè)拔頭籌
文章出處:【微信號(hào):SenseTime2017,微信公眾號(hào):商湯科技SenseTime】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
云知聲山海大模型多項(xiàng)評(píng)測(cè)名列前茅
近日,智源研究院發(fā)布并解讀了國內(nèi)外100余個(gè)開源和商業(yè)閉源的語言、視覺語言、文生圖、文生視頻、語音語言大模型綜合及專項(xiàng)評(píng)測(cè)結(jié)果。
大語言模型開發(fā)語言是什么
在人工智能領(lǐng)域,大語言模型(Large Language Models, LLMs)背后,離不開高效的開發(fā)語言和工具的支持。下面,AI部落小編為您介紹大語言
云知聲山海大模型多項(xiàng)能力全球領(lǐng)跑
國內(nèi)人工智能權(quán)威機(jī)構(gòu)清華大學(xué)基礎(chǔ)模型研究中心發(fā)布SuperBench九月綜合榜單。本次評(píng)測(cè)選取海內(nèi)外24個(gè)具有代表性的大模型,結(jié)果顯示,山海大模型對(duì)齊、智能體、安全等

【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 俯瞰全書
松。
入門篇主要偏應(yīng)用,比如大語言模型的三種交互方式,分析了提示工程、工作記憶和長短期記憶,此篇最后講了ChatGPT的接口和擴(kuò)展功能應(yīng)用,適合大語言模型應(yīng)用技術(shù)人員閱讀。
進(jìn)階篇就非
發(fā)表于 07-21 13:35
大模型助力國際術(shù)語專業(yè)化,前后聯(lián)動(dòng)實(shí)現(xiàn)所見即所得
、西班牙語、法語、德語、越南語。其中每個(gè)語言包的詞條都有上萬條,且隨著新需求的開發(fā)迭代也在不斷的新增,語言包的不斷擴(kuò)展和詞條的不斷增加,詞條翻譯的簡潔性、
名單公布!【書籍評(píng)測(cè)活動(dòng)NO.34】大語言模型應(yīng)用指南:以ChatGPT為起點(diǎn),從入門到精通的AI實(shí)踐教程
聯(lián)系,視為放棄本次試用評(píng)測(cè)資格!
2018 年,OpenAI 發(fā)布了首個(gè)大語言模型——GPT,這標(biāo)志著大語言模型革命的開始。這場(chǎng)革命在 20
發(fā)表于 06-03 11:39
大語言模型:原理與工程時(shí)間+小白初識(shí)大語言模型
種語言模型進(jìn)行預(yù)訓(xùn)練,此處預(yù)訓(xùn)練為自然語言處理領(lǐng)域的里程碑
分詞技術(shù)(Tokenization)
Word粒度:我/賊/喜歡/看/大語言模型
發(fā)表于 05-12 23:57
【大語言模型:原理與工程實(shí)踐】大語言模型的應(yīng)用
,它通過抽象思考和邏輯推理,協(xié)助我們應(yīng)對(duì)復(fù)雜的決策。
相應(yīng)地,我們?cè)O(shè)計(jì)了兩類任務(wù)來檢驗(yàn)大語言模型的能力。一類是感性的、無需理性能力的任務(wù),類似于人類的系統(tǒng)1,如情感分析和抽取式問答等。大語言
發(fā)表于 05-07 17:21
【大語言模型:原理與工程實(shí)踐】大語言模型的評(píng)測(cè)
大語言模型的評(píng)測(cè)是確保模型性能和應(yīng)用適應(yīng)性的關(guān)鍵環(huán)節(jié)。從基座模型到微調(diào)模型,再到行業(yè)
發(fā)表于 05-07 17:12
【大語言模型:原理與工程實(shí)踐】探索《大語言模型原理與工程實(shí)踐》2.0
讀者更好地把握大語言模型的應(yīng)用場(chǎng)景和潛在價(jià)值。盡管涉及復(fù)雜的技術(shù)內(nèi)容,作者盡力以通俗易懂的語言解釋概念,使得非專業(yè)背景的讀者也能夠跟上節(jié)奏。圖表和示例的運(yùn)用進(jìn)一步增強(qiáng)了書籍的可讀性。本
發(fā)表于 05-07 10:30
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
全面剖析大語言模型的核心技術(shù)與基礎(chǔ)知識(shí)。首先,概述自然語言的基本表示,這是理解大語言模型技術(shù)的前提。接著,詳細(xì)介紹自然
發(fā)表于 05-05 12:17
【大語言模型:原理與工程實(shí)踐】揭開大語言模型的面紗
大語言模型(LLM)是人工智能領(lǐng)域的尖端技術(shù),憑借龐大的參數(shù)量和卓越的語言理解能力贏得了廣泛關(guān)注。它基于深度學(xué)習(xí),利用神經(jīng)網(wǎng)絡(luò)框架來理解和生成自然語言文本。這些
發(fā)表于 05-04 23:55
【大語言模型:原理與工程實(shí)踐】探索《大語言模型原理與工程實(shí)踐》
《大語言模型》是一本深入探討人工智能領(lǐng)域中語言模型的著作。作者通過對(duì)語言模型的基本概念、基礎(chǔ)技術(shù)
發(fā)表于 04-30 15:35
名單公布!【書籍評(píng)測(cè)活動(dòng)NO.31】大語言模型:原理與工程實(shí)踐
放棄本次試用評(píng)測(cè)資格!
緣起:為什么要寫這本書
OpenAI的ChatGPT自推出以來,迅速成為人工智能領(lǐng)域的焦點(diǎn)。ChatGPT在語言理解、生成、規(guī)劃及記憶等多個(gè)維度展示了強(qiáng)大的能力。這不僅體現(xiàn)在
發(fā)表于 03-18 15:49
名單公布!【書籍評(píng)測(cè)活動(dòng)NO.30】大規(guī)模語言模型:從理論到實(shí)踐
評(píng)測(cè)資格!
2022年11月,ChatGPT的問世展示了大模型的強(qiáng)大潛能,對(duì)人工智能領(lǐng)域有重大意義,并對(duì)自然語言處理研究產(chǎn)生了深遠(yuǎn)影響,引發(fā)了大模型研究的熱潮。
距ChatGPT問世不
發(fā)表于 03-11 15:16





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論