 螞蟻集團開源高性能多語言序列化框架Fury解讀
螞蟻集團開源高性能多語言序列化框架Fury解讀
作者 | 楊朝坤(慕白) 策劃 | 鄧艷琴
Fury 是一個基于 JIT 動態編譯和零拷貝的多語言序列化框架,支持 Java/Python/Golang/JavaScript/C++ 等語言,提供全自動的對象多語言 / 跨語言序列化能力,和相比 JDK 最高 170 倍的性能。
代碼主倉庫的 GitHub 地址為:https://github.com/alipay/fury
背景
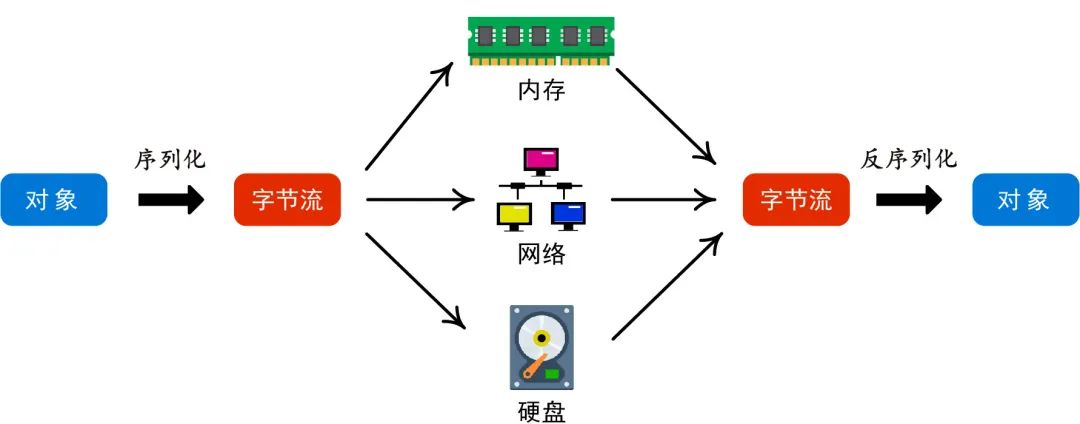
序列化是系統通信的基礎組件,在大數據、AI 框架和云原生等分布式系統中廣泛使用。當對象需要跨進程、跨語言、跨節點傳輸、持久化、狀態讀寫、復制時,都需要進行序列化,其性能和易用性影響運行效率和開發效率。
靜態序列化框架 protobuf/flatbuffer/thrift 由于不支持對象引用和多態、需要提前生成代碼等原因,無法作為領域對象直接面向應用進行跨語言開發。而動態序列化框架 JDK 序列化 /Kryo/Fst/Hessian/Pickle 等,盡管提供了易用性和動態性,但不支持跨語言,且性能存在顯著不足,并不能滿足高吞吐、低延遲和大規模數據傳輸場景需求。
因此,我們開發了一個新的多語言序列化框架 Fury,并正式在 Github 開源。通過一套高度優化的序列化基礎原語,結合JIT 動態編譯和 Zero-Copy等技術,同時滿足了性能、功能和易用性的需求,實現了任意對象自動跨語言序列化,并提供極致的性能。
Fury 簡介
Fury 是一個基于 JIT 動態編譯和零拷貝的多語言序列化框架,提供極致的性能和易用性:
支持主流編程語言Java/ Python/ C++/ Golang/ JavaScript,其它語言可輕易擴展;
統一的多語言序列化核心能力:
高度優化的序列化原語;
Zero-Copy 序列化支持,支持 Out of band 序列化協議,支持堆外內存讀寫;
基于JIT 動態編技術在運行時異步多線程自動生成序列化代碼優化性能,增加方法內聯、代碼緩存和消除死代碼,減少虛方法調用 / 條件分支 /Hash 查找 / 元數據寫入 / 內存讀寫等,提供相比別的序列化框架最高 170 倍的性能;
多協議支持:兼顧動態序列化的靈活性和易用性,以及靜態序列化的跨語言能力。
Java 序列化:
無縫替代 JDK/Kryo/Hessian,無需修改任何代碼,但提供最高 170x 的性能,可以大幅提升高性能場景RPC 調用、數據傳輸和對象持久化效率;
100% 兼容 JDK 序列化,原生支持 JDK 自定義序列化方法 writeObject/ readObject/ writeReplace/ readResolve/ readObjectNoData
跨語言對象圖序列化:
多語言 / 跨語言自動序列化任意對象,無需創建 IDL 文件、手動編譯 schema 生成代碼以及將對象轉換為中間格式;
多語言 / 跨語言自動序列化共享引用和循環引用,不需要關心數據重復或者遞歸錯誤;
支持對象類型多態,多個子類型對象可以同時被序列化;
行存序列化:
提供緩存友好的二進制隨機訪問行存格式,支持跳過序列化和部分序列化,適合高性能計算和大規模數據傳輸場景;
支持和 Arrow 列存自動互轉 ;
序列化核心能力
盡管不同的場景對序列化有需求,但序列化的底層操作都是類似的。因此 Fury 定義和實現了一套序列化的基礎能力,基于這套能力能夠快速構建不同的多語言序列化協議,并通過編譯加速等優化具備高性能。同時針對一種協議在基礎能力上的性能優化,也能夠讓所有的序列化協議都受益。
序列化原語
序列化涉及的常見操作主要包括:
bitmap 位操作
整數編解碼
整數壓縮
字符串創建 * 拷貝優化
字符串編碼:ASCII/UTF8/UTF16
內存拷貝優化
數組拷貝壓縮優化
元數據編碼 & 壓縮 & 緩存
Fury 針對這些操作在每種語言內部都做了大量的優化,結合 SIMD 指令和語言高級特性,將性能推到極致,從而方便不同協議使用。
零拷貝序列化
在大規模數據傳輸場景,一個對象圖內部往往有多個 binary buffer,而序列化框架在序列化過程當中會把這些數據寫入一個中間 buffer,引入多次耗時內存拷貝。Fury 借鑒了 pickle5、ray 以及 arrow 的零拷貝設計,實現了一套Out-Of-Band 序列化協議,能夠把一個對象圖當中的所有 binary buffer 直接抓取出來,避免掉這些 buffer 的中間拷貝,將序列化期間的內存拷貝開銷降低到 0。
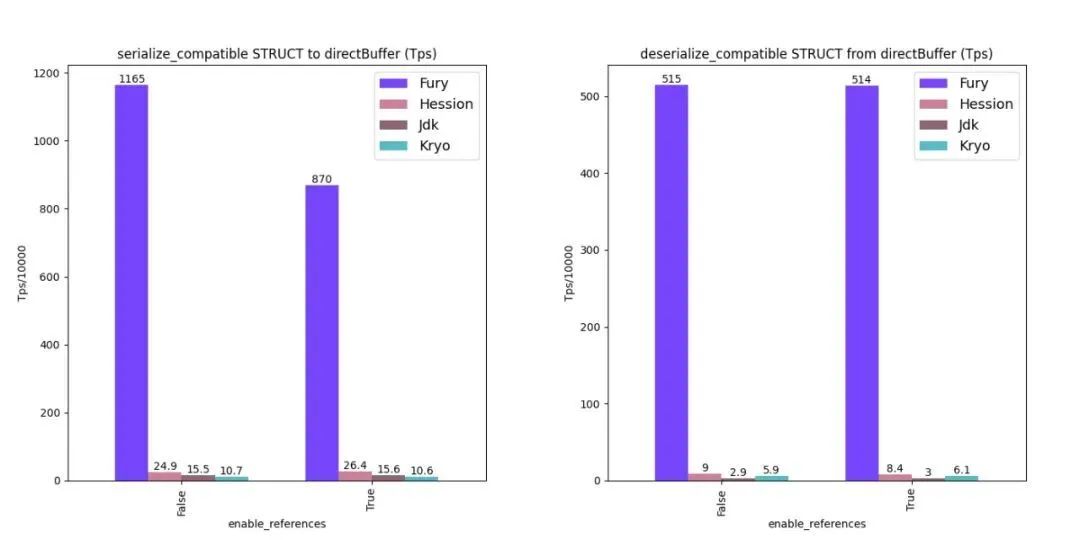
下圖是 Fury 關閉引用支持時 Zero-Copy 的大致序列化過程。
目前 Fury 內置了以下類型的 Zero-Copy 支持:
Java:所有基本類型數組、ByteBuffer、ArrowRecordBatch、VectorSchemaRoot
Python:array 模塊的所有 array、numpy 數組、pyarrow.Table、pyarrow.RecordBatch
Golang:byte slice
用戶也可以基于 Fury 的接口擴展新的零拷貝類型。
JIT 動態編譯加速
對于要序列化的自定義類型對象,其中通常包含大量類型信息,Fury利用這些類型信息在運行時直接生成高效的序列化代碼,將大量運行時的操作在動態編譯階段完成,從而增加方法內聯和代碼緩存,減少虛方法調用 / 條件分支 /Hash 查找 / 元數據寫入 / 內存讀寫等,最終大幅加速了序列化性能。
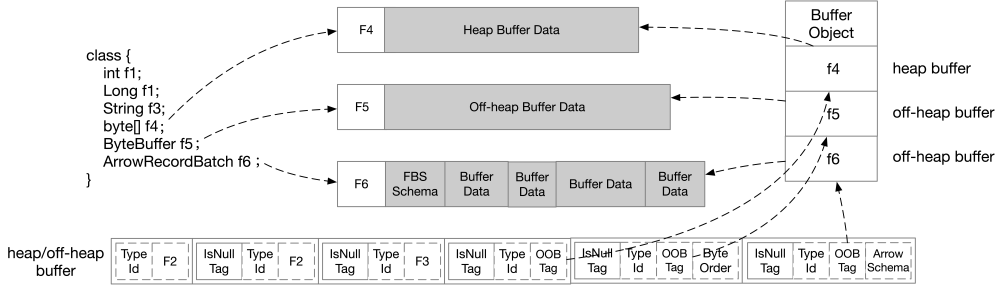
對于 Java 語言,Fury 實現了一套運行時代碼生成框架,定義了一套序列化邏輯的算子表達式 IR,在運行時基于對象類型的泛型信息進行類型推斷,然后構建一顆描述序列化代碼邏輯的表達式樹,根據表達式樹生成高效的 Java 代碼,再在運行時通過 Janino 編譯成字節碼,再加載到用戶的 ClassLoader 里面或者 Fury 創建的 ClassLoader 里面,最終通過 Java JIT 編譯成高效的匯編代碼。
由于 JVM JIT 會跳過大方法編譯和內聯,Fury 也實現了一套優化器,將大方法遞歸拆分成小方法,這樣就保證了 Fury 生成的所有代碼都可以被編譯和內聯,壓榨 JVM 的性能到極致。
同時 Fury 也支持異步多線程動態編譯,將不同序列化器的代碼生成任務提交到線程池執行,在編譯完成之前使用解釋模式執行,從而保證不會出現序列化毛刺,不需要提前預熱所有類型的序列化。
Python 和 JavaScript 場景也是采用的類似代碼生成方式,這樣的生成方式開發門檻低,更容易排查問題。
由于序列化需要密切操作每種編程語言的對象,而編程語言并沒有暴露內存模型的低階 API,通過 Native 方法調用存在較大開銷,因此我們并不能通過 LLVM 構建一個統一的序列化器 JIT 框架,而是需要在每種語言內部結合語言特性實現特定的代碼生成框架以及序列化器構建邏輯。
靜態代碼生成
盡管 JIT 編譯能夠大幅提升序列化效率,并且在運行時能夠根據數據的統計分布重新生成更優的序列化代碼,但 C++/Rust 等語言不支持反射,沒有虛擬機,也沒有提供內存模型的低階 API,因此我們無法針對這類語言通過 JIT 動態編譯生成序列化代碼。
對于此類場景,Fury 正在實現一套 AOT 靜態代碼生成框架,在編譯時根據對象的 schema 提前生成序列化代碼,然后使用生成的代碼進行自動序列化。對于 Rust,未來也會通過 Rust 的 macro 在編譯時生成代碼,提供更好的易用性。
緩存優化
在序列化自定義類型時,會把字段進行重排序,保證相同接口類型的字段依次序列化,增加緩存命中的概率,同時也促進了CPU 指令緩存,實現了更加高效的序列化。對于基本類型字段將寫入順序按照字節字段大小降序排列,這樣如果開始地址是對齊的,隨后的讀寫都會發生在內存地址對齊的位置,CPU 執行起來更加高效。
多協議設計與實現
基于 Fury 提供的多語言序列化核心能力,我們在這之上構建了三種序列化協議,分別適用于不同的場景:
Java 序列化:適合純 Java 序列化場景,提供最高百倍以上的性能提升;
跨語言對象圖序列化:適合面向應用的多語言編程,以及高性能跨語言序列化;
行存序列化:適合分布式計算引擎如 Spark/Flink/Dories/Velox/ 樣本流處理框架 / 特征存儲等;
后續我們也會針對一些核心場景添加新的協議,用戶也可以基于 Fury 的序列化能力構建自己的協議。
Java 序列化
由于 Java 在大數據、云原生、微服務和企業級應用的廣泛使用,對 Java 序列化的性能優化可以大幅降低系統延遲,提升吞吐率,降低服務器成本。
因此 Fury 針對 Java 序列化進行了大量極致性能優化,我們的實現具備以下能力:
極致性能:通過利用 Java 對象的類型和泛型信息,結合 JIT 編譯、Unsafe 低階操作,Fury 相比 JDK 最高有 170 倍的性能提升,相比 Kryo/Hessian 最高有 50~100 倍的性能提升。
100% JDK 序列化 API 兼容性:支持了所有 JDK 自定義序列化方法 writeObject/readObject/ writeReplace/ readResolve/readObjectNoData 的語義,保證任意場景替換 JDK 序列化的正確性。而已有的 Java 序列化框架如 Kryo/Hessian 在這些場景,都存在一定的正確性問題
類型前后兼容:在反序列化端和序列化端 Class Schema 不一致時,仍然可以正確反序列化,支持應用獨立升級部署,獨立增刪字段。并且我們對元數據進行了極致的壓縮和共享,類型兼容模式相比類型強一致模式做到了幾乎沒有任何性能損失。
元數據共享:在某個上下文 (TCP 連接) 下多次序列化之間共享元數據(類名稱、字段名稱、Final 字段類型信息等),這些信息會在該上下文下第一次序列化時發送到對端,對端可以根據該類型信息重建相同的反序列化器,后續序列化可以避免傳輸元數據,減小網絡流量壓力,同時也自動支持類型前后兼容。
零拷貝支持:支持 Out of band 零拷貝和堆外內存讀寫。
跨語言對象圖序列化
跨語言對象圖序列化主要用于對動態性和易用性有更高要求的場景。盡管 Protobuf/Flatbuffer 等框架提供了多語言序列化能力,但仍然存在一些不足:
需要提前編寫 IDL 并靜態編譯生成代碼,不具備足夠的動態性和靈活性;
生成的類不符合面向對象設計也無法給類添加行為,并不能作為領域對象直接用于多語言應用開發。
不支持子類序列化。面向對象編程的主要特點是通過接口調用子類方法。這類模式也無法得到很好的支持。盡管 Flatbuffer 提供了 Union,Protobuf 提供了 OneOf/Any 特性,這類特性需要在序列化和反序列化時判斷對象的類型,不符合面向對象編程的設計。
不支持循環和共享引用,需要針對領域對象重新定義一套 IDL 并自己實現引用解析,然后在每種語言里面編寫代碼實現領域對象和協議對象之間的相互轉換,如果對象圖嵌套層數較深,則需要編寫更多的代碼。
結合以上幾點,Fury 實現了一套跨語言的對象圖序列化協議:
多語言 / 跨語言自動序列化任意對象:在序列化和反序列化端定義兩個 Class,即可自動將一種語言的對象自動序列化為另一種語言的對象,無需創建 IDL 文件、編譯 schema 生成代碼以及手寫轉換代碼;
多語言 / 跨語言自動序列化共享引用和循環引用;
支持對象類型多態,符合面向對象編程范式,多個子類型對象可以同時被自動反序列化,無需用戶手動處理;
同時我們在這套協議上面也支持了 Out of band 零拷貝;
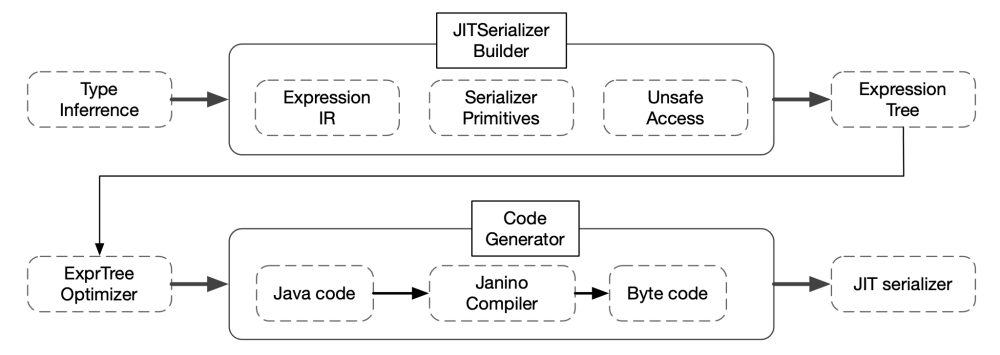
自動跨語言序列化示例:
行存序列化
對于高性能計算和大規模數據傳輸場景,數據序列化和傳輸往往是整個系統的性能瓶頸。如果用戶只需要讀取部分數據,或者根據對象某個字段進行過濾,反序列化整個數據將帶來額外開銷。因此 Fury 也提供了一套二進制數據結構,在二進制數據上直讀直寫,避開序列化。
Apache arrow 是一個成熟的列存格式,支持二進制讀寫。但列存并不能滿足所有場景需求,在線鏈路和流式計算場景的數據天然就是行存結構,同時列式計算引擎內部在涉及到數據變更和 Hash/Join/Aggregation 操作時,也會使用到行存結構。
而行存并沒有一個統一標準實現,計算引擎如 Spark/Flink/Doris/Velox 等都定義了一套行存格式,這些格式不支持跨語言,且只能被自己引擎內部使用,無法用于其它框架。盡管 Flatbuffer 能夠支持按需反序列化,但需要靜態編譯 Schema IDL 和管理 offset,無法滿足復雜場景的動態性和易用性需求。
因此 Fury 在早期借鑒了 spark tungsten 和 apache arrow 格式,實現了一套可以隨機訪問的二進制行存結構,目前實現了 Java/Python/C++ 版本,實現了在二進制數據上面直讀直寫,避免掉了所有序列化開銷。
下圖是 Fury Row Format 的二進制格式:
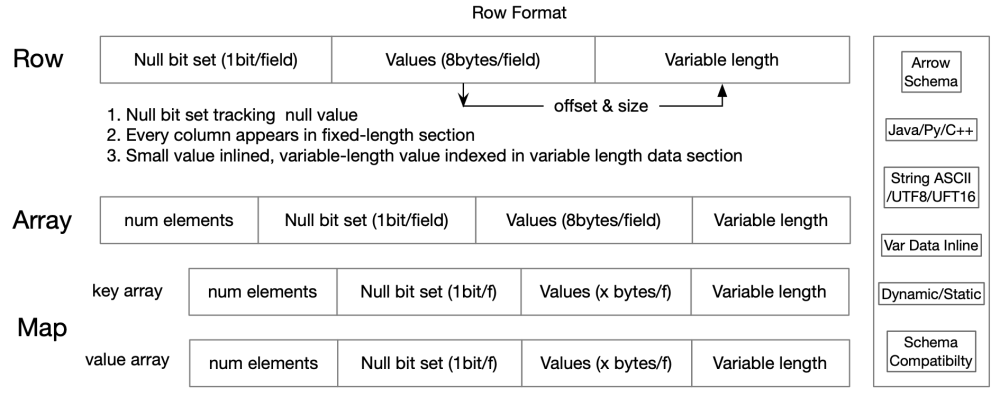
該格式密集存儲,數據對齊,緩存友好,讀寫更快。由于避免了反序列化,能夠減少 Java GC 壓力。同時降低 Python 開銷,同時由于 Python 的動態性,Fury 的數據結構實現了 _getattr__/getitem/slice/ 和其它特殊方法,保證了行為跟 python dataclass/list/object 的一致性,用戶沒有任何感知。
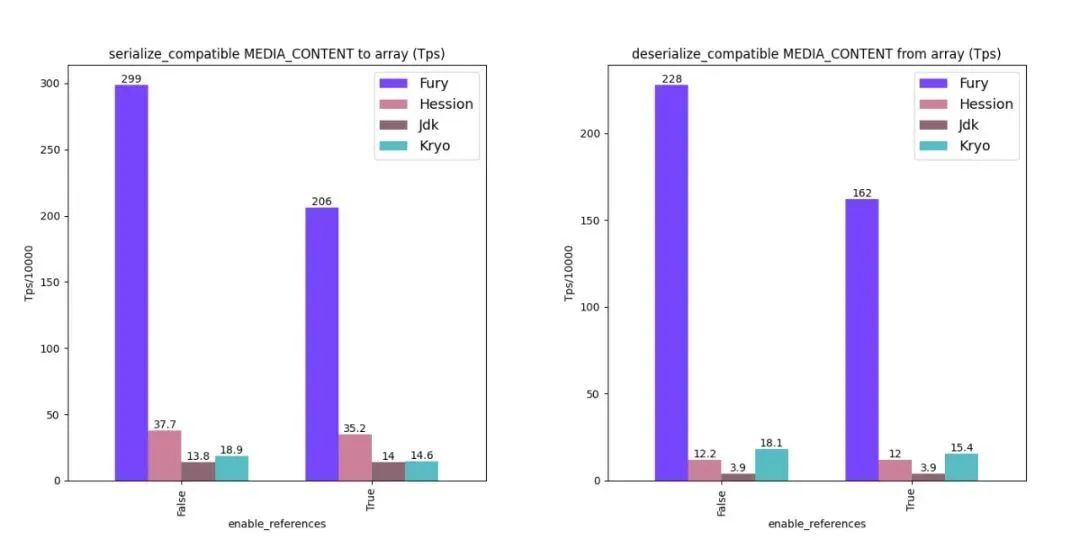
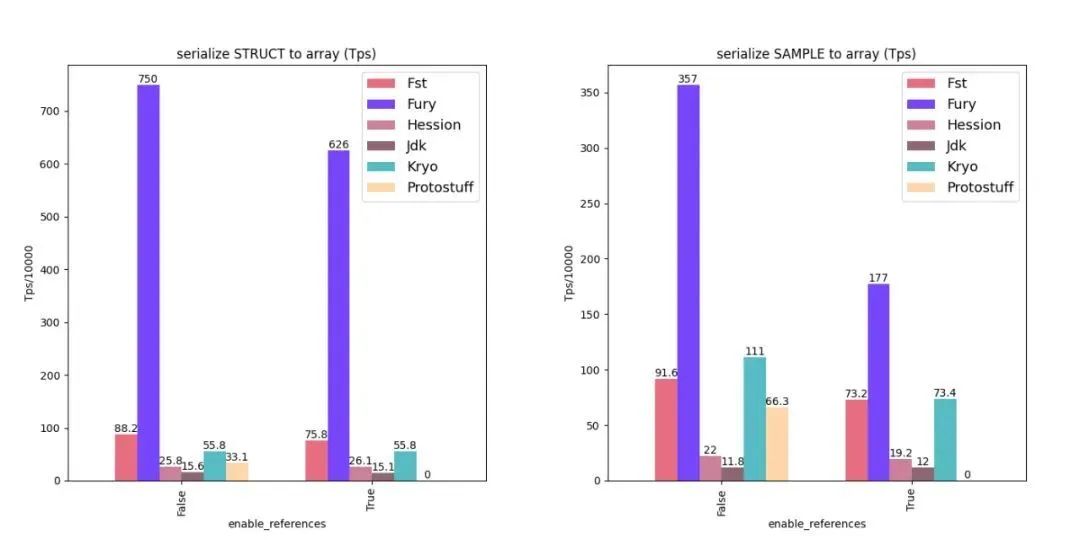
性能對比
這里給出部分 Java 序列化性能數據,其中標題包含 compatible 的圖表是支持類型前后兼容下的性能數據,標題不包含 compatible 的圖表是不支持類型前后兼容下的性能數據。為了公平起見,所有測試 Fury 關閉了零拷貝特性。
更多 benchmark 數據請參考 Fury Github 官方文檔
未來規劃
元數據壓縮和自動共享
跨語言序列化支持類型前后兼容
靜態代碼生成框架,用于提前生成 c++/golang/rust 代碼
C++/Rust 支持跨語言對象圖序列化
Golang/Rust/JavaScript 支持行存
兼容 ProtoBuffer 生態,支持根據 Proto IDL 自動生成 Fury 序列化代碼
新的協議實現:AI 特征存儲,知識圖譜序列化
持續改進我們的序列化基礎原語,提供更高性能實現
標準化協議,提供二進制兼容性
文檔和易用性改進
加入我們
我們致力于將 Fury 打造為一個開放中立、追求極致與創新的社區項目,后續的研發與討論等工作都會在社區以開源透明的方式進行。歡迎任何形式的參與,包括但不限于提問、代碼貢獻、技術討論等。非常期待收到大家的想法和反饋,一起參與到項目的建設中來,推動項目向前發展,打造最先進的序列化框架。
代碼主倉庫的 GitHub 地址為:https://github.com/alipay/fury
作者簡介
楊朝坤,螞蟻集團技術專家,Fury 框架作者。2018 年加入螞蟻集團,先后從事流計算框架、在線學習框架、科學計算框架和 Ray 等分布式計算框架開發,對批計算、流計算、Tensor 計算、高性能計算、AI 框架、張量編譯等有深入的理解。
審核編輯:湯梓紅
-
開源
+關注
關注
3文章
3402瀏覽量
42711 -
C++
+關注
關注
22文章
2114瀏覽量
73854 -
JDK
+關注
關注
0文章
82瀏覽量
16636 -
Rust
+關注
關注
1文章
230瀏覽量
6664 -
螞蟻集團
+關注
關注
0文章
99瀏覽量
3656
原文標題:比 JDK 最高快 170 倍,螞蟻集團開源高性能多語言序列化框架 Fury
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何使用Serde進行序列化和反序列化
多語言開發的流程詳解
Java序列化的機制和原理
SpringMVC JSON框架的自定義序列化與反序列化
SoC多語言協同驗證平臺技術研究
java序列化和反序列化范例和JDK類庫中的序列化API
Multilingual多語言預訓練語言模型的套路
什么是序列化 為什么要序列化
如何用C語言進行json的序列化和反序列化
基于LLaMA的多語言數學推理大模型
大語言模型(LLMs)如何處理多語言輸入問題






 工商網監
工商網監
評論