 Serverless冷啟動:如何讓函數計算更快更強?
Serverless冷啟動:如何讓函數計算更快更強?
問題背景
Serverless 計算也稱服務器無感知計算或函數計算,是近年來一種新興的云計算編程模式。其致力于大幅簡化云業務開發流程,使得應用開發者從繁雜的服務器運維工作中解放出來(例如自動伸縮、日志和監控等)。借助 Serverless 計算,開發者僅需上傳業務代碼并進行簡單的資源配置便可實現服務的快速構建部署,云服務商則按照函數服務調用量和實際資源使用收費,從而幫助用戶實現業務的快速交付(fastbuilt&Relia.Deliv.)和低成本運行。
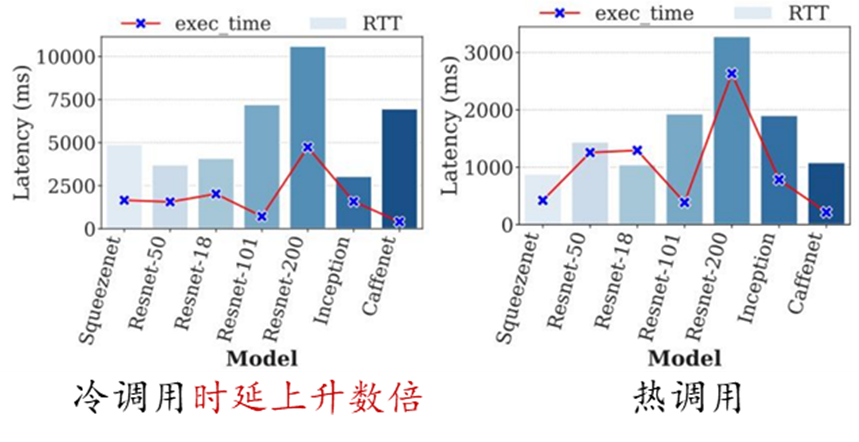
然而,Serverless 計算的無狀態函數編程在帶來高度彈性和靈活性的同時,也導致了不可避免的冷啟動問題。由于函數通常在執行完請求后被釋放,當請求到達時,如果沒有可用實例則需要從零開始啟動新的實例處理請求(即冷啟動)。當冷啟動發生時,Serverless 平臺需要執行實例調度、鏡像分發、實例創建、資源配置、運行環境初始化以及代碼加載等一系列操作,這一過程引發的時延通常可達請求實際執行時間的數倍。相對于冷啟動調用,熱調用(即請求到達時有可用實例)的準備時間可以控制在亞毫秒級。在特定領域例如 AI 推理場景,冷啟動調用導致的高時延問題則更為突出,例如,使用 TensorFlow 框架的啟動以及讀取和加載模型可能需要消耗數秒或數十秒。
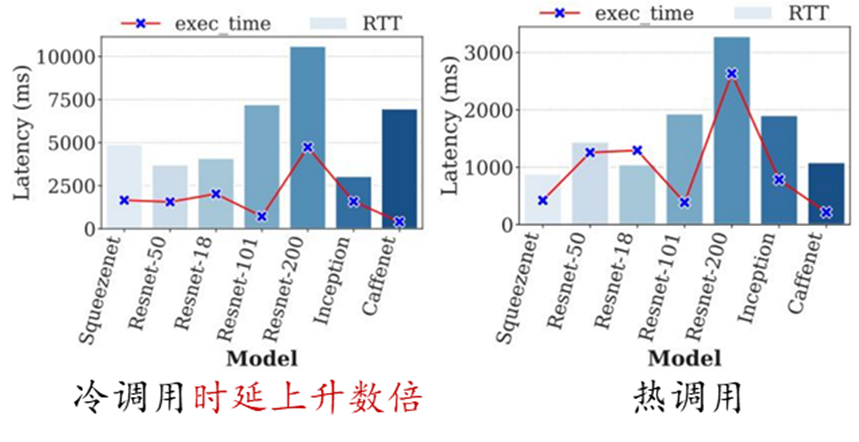
因此,如何緩解 Serverless 函數的冷啟動問題,改善函數性能是當前 Serverless 領域面臨的主要挑戰之一。
解決方案
從研究思路上看,目前工業界和學術界主要從兩個方面入手解決冷啟動問題:
(1)加快實例啟動速度:當冷啟動調用發生時,通過加速實例的初始化過程來減少啟動時延;
當冷啟動發生時,Serverless 平臺內部實例的初始化過程可以劃分為準備和加載兩個階段。其中,準備階段主要包括控制面決策調度/鏡像獲取、Runtime 運行時初始化、應用數據/代碼傳輸幾個部分。而加載階段位于實例內部,包括用戶應用框架和代碼的初始化過程。在工業界和學術界公開的研究成果中,針對實例啟動過程中的每個階段都有大量的技術手段和優化方法。如下圖所示,經過優化,實例冷啟動的準備階段和加載階段時間可被極大得縮短。
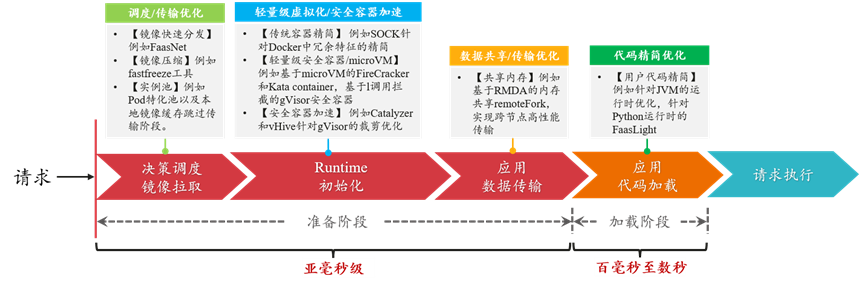
下面列舉了一些近年來發表在計算機系統領域知名會議的相關工作,主要可以分為五個方面:
1、調度優化/鏡像快速分發/本地池化:
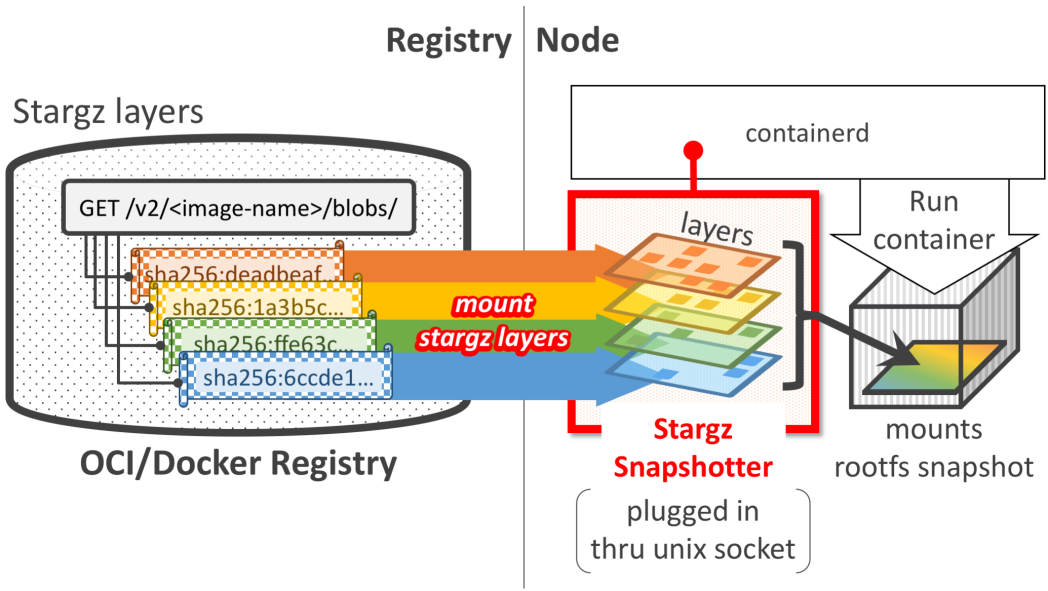
例如基于樹結構的跨節點快速鏡像分發FaasNet[ATC'21];Pod 池+特化實例跳過鏡像傳輸[華為 FunctionGraph]。其中,快速鏡像分發依賴于 VM 節點的上/下行網絡帶寬,Pod 池特化技術則是典型的以空間換時間的做法。
2、輕量級虛擬化/安全容器:
例如針對傳統容器 Docker 的精簡優化工作 SOCK[ATC'21];更側重安全性的輕量級虛擬化技術(KataContainers,gVisor 等);基于安全容器的進一步的精簡優化工作(Catalyzer[ASPLOS'20],REAP[ASPLOS'21])。通過裁剪優化,安全容器的啟動時延最快可以被壓縮至亞毫秒級。
3、數據共享/跨節點傳輸優化:
例如基于 RDMA 共享內存減少跨節點啟動過程的數據拷貝RemoteFork[OSDI'23];或者利用本地代碼緩存跳過代碼傳輸[華為 FunctionGraph,字節 ByteFaaS 等]。基于 RDMA 技術的跨節點數據傳輸時延可降低至微妙級。
4、用戶代碼精簡/快速加載:
例如針對 Java 語言的 JVM(JavaVirtualMachine)運行時優化技術[FunctionGraph];以及針對 Python 運行時庫的裁剪優化工作 FaasLight[arxiv'23]。通過特定的優化,JVM 啟動時間可由數秒降低至數十毫秒,而 Python 代碼的啟動加載時延可降低約 1/3。
5、其它非容器運行時技術:
例如 WASM(即 WebAssembly)技術以及針對 WASM 的內存隔離方面的優化工作 Faasm[ATC'20]。相比容器化技術,直接以進程和線程方式組織運行函數,可在保證低開銷函數運行的同時具備高度靈活性。
(2)降低冷啟動發生率:通過函數預熱、復用或實例共享等方法提高實例的利用效率,減少冷啟動調用的發生
盡管已有的一些實例啟動加速方法已經可以將運行時環境的初始化時間壓縮至數十毫秒甚至是數毫秒,然而用戶側的延遲卻仍然存在,例如程序狀態的恢復,變量或者配置文件的重新初始化,相關庫和框架的啟動。具體來講,在機器學習應用中,TensorFlow 框架的啟動過程往往需要花費數秒,即使實例運行時環境的啟動時間再短,應用整體的冷啟動時延對用戶而言依然是無法接受的(注:通常大于 200ms 的時延可被用戶察覺)。在這種情況下,可以從另一個角度入手解決冷啟動問題,即降低冷啟動調用的發生率。例如,通過緩存完整的函數實例,請求到達時可以快速恢復并處理請求,從而實現近乎零的初始化時延(例如 Dockerunpause 操作時延小于 0.5ms)。
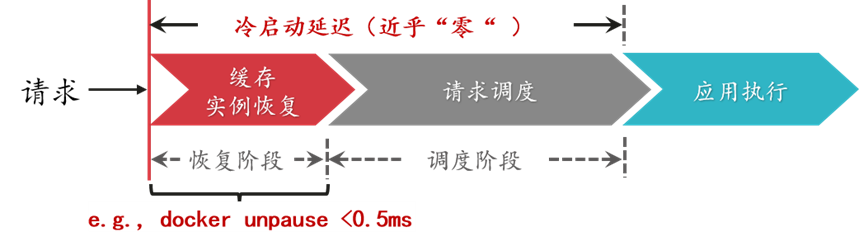
降低冷啟動發生率的相關研究可以分為如下幾個方面:
1、實例保活/實例預留:
例如基于 Time-to-Live 的 keepalive 保活機制[AWSLambda,OpenWhisk];或者通過并發配置接口預留一定數量的實例[AWSLabmda 等];這些方法原理簡單,易于實現,但是在面對負載變化時緩存效率較低。
2、基于負載特征學習的動態緩存:
例如基于請求到達間隔預測的動態緩存方案ServerlessintheWild[ASPLOS'20];學習長短期負載變化特征的動態緩存方案INFless[ASPLOS'22];基于優先級的可替換緩存策略 FaasCache[ATC'21];面向異構服務器集群的低成本緩存方案IceBreaker[ASPLOS'22]。這些動態緩存方案根據負載特征學習決定實例緩存數量或時長,從而在降低冷啟動調用率的同時改善緩存資源消耗。
3、優化請求分發提高命中率:
例如兼顧節點負載和本地化執行的請求調度算法CH-RLU[HPDC'22]。通過權衡節點負載壓力和緩存實例的命中率來對請求的分發規則進行優化設計,避免節點負載過高導致性能下降,同時兼顧冷啟動率。
4、改善并發/實例共享或復用:
例如允許同一函數工作流的多個函數共享 Sandbox 環境SAND[ATC'18];使用進程或線程編排多個函數到單個實例中運行Faastlane[ATC'21];提高實例并發處理能力減少實例創建Fifer[Middle'20];允許租戶復用其它函數的空閑實例減少冷啟動時間Pagurus[ATC'22]。這些實例共享或者復用技術可以同緩存方案結合使用,降低冷啟動帶來的性能影響。
總結
Serverless 的無狀態設計賦予了函數計算高度彈性化的擴展能力,然而也帶來了難以避免的冷啟動問題。消除 Serverless 函數的冷啟動開銷還是從降低函數冷啟動率和加速實例啟動過程兩個角度綜合入手。對于冷啟動開銷比較大的函數,在函數計算框架的設計機制中進行優化,盡量避免冷啟動發生;當冷啟動發生時,采用一系列啟動加速技術來縮短整個過程進行補救。在 Serverless 平臺的內部,冷啟動的管理在實踐中可以做進一步精細的劃分,例如針對 VIP 大客戶,針對有規律負載的,或是針對冷啟動開銷小的函數,通過分類做定制化、有目的的管理可以進一步改善系統效率。
編輯:黃飛
-
云計算
+關注
關注
39文章
7850瀏覽量
137875 -
服務器
+關注
關注
12文章
9308瀏覽量
86071 -
函數
+關注
關注
3文章
4346瀏覽量
62977 -
serverless
+關注
關注
0文章
65瀏覽量
4521
發布評論請先 登錄
相關推薦
單片機復位和冷啟動詳細介紹

基于阿里云Serverless架構下函數計算的最新應用場景詳解(一)
Bazaar:阿里云Serverless計算服務探秘
Serverless概念
北斗/GPS定位模塊冷啟動、熱啟動、溫啟動有什么區別?
全球公測,阿里云Serverless Kubernetes 更快、更強、更省心
函數計算性能福利篇(一) —— 系統冷啟動優化
函數計算性能福利篇(二) —— 業務冷啟動優化


華為云發布冷啟動加速解決方案:助力Serverless計算速度提升90%+
Serverless 冷啟動:如何讓函數計算更快更強?
基于DPU的容器冷啟動加速解決方案





 工商網監
工商網監
評論