 極致優化SSD并行讀調度
極致優化SSD并行讀調度
作者 | GL
導讀
提升廣告檢索漏斗一致性,要求在粗排階段引入更豐富的信號,這些信號的需求量已經遠遠超出了內存的承受能力。為此,我們考慮引入基于NVMe SSD的分層存儲。本文詳細探討了一種長尾可控的方法論,以及在這個方法論的約束下,如何極致優化讀調度。這些方法對于實施類似LargerThanMem的技術也將提供有價值的啟發。
01業務背景
業務需要更大存儲空間,需求量預期遠超過內存可承受。舉例來說,客戶落地頁是客戶營銷內容的核心陣地,增強對客戶落地頁內容特征理解,才能實現用戶興趣和客戶投放的精準匹配,提升用戶體驗和轉化率,鳳巢正排服務引入 URL 明文是關鍵一步。鳳巢正排服務檢索查詢完全基于內存,內存存儲著億級別廣告物料和檢索線程需要的上下文。鳳巢正排服務實例上萬,單實例內存 Quota 已高達云原生紅線,常態利用率 85+%,URL 明文引入后,即使業務上極致去重壓縮,單實例還需增加數十GB,預期隨廣告庫會繼續增長,內存已遠遠不夠。
廣告檢索過程引入基于 NVMe SSD 的分級存儲,長尾控制尤其關鍵。檢索效果對處理性能極為敏感,若查詢超時導致檢索 KPI 失效,將可能造成廣告丟失,從而帶來收入損失。以鳳巢正排服務來看,單 PV 召回廣告創意量在萬級別,正排服務通過多分庫分包實現并行,即使在單個包內,廣告創意數量也可達數百。從檢索系統的算力分配來看,針對百條 URL 明文的查詢,其長尾性能空間僅為 5ms。
02技術背景
SSD 作為內存存儲擴展,缺點是讀寫干擾不可控。SSD[1] 的操作要求必須按頁進行讀寫,否則會導致讀寫放大效應。此外,SSD 硬件特性還要求“擦除后寫”,因此寫數據會額外引起數據搬運損耗和擦除損耗,而擦除操作的耗時往往是讀操作時間的 1000 倍!更令人擔憂的是,對于那些需要極低隨機讀取的業務而言,SSD 就像一個無法調節的『黑匣子』,應用無法直接干預由讀寫干擾帶來的查詢長尾問題。
業界常用訪盤優化手段,未能控制讀長尾。業界常用軟件寫盤優化,確實可以顯著提升吞吐,但對長尾控制力度有限,主要手段是:① 把隨機寫轉化為對齊寫、順序寫,② 整文件大塊刪除,③ 流量低峰期觸發盤 GC。比如論文 FAST' 15《F2FS: A New File System for Flash Storage》[2] 介紹了一種面向 SSD 的全新文件系統F2FS,基于 Log-Structured File System 的技術,將所有的寫入操作轉換為日志記錄,從而減少寫放大效應,并提高了寫入吞吐。下圖中展示 F2FS v.s. ext4 在隨機寫場景(varmail、oltp)獲得吞吐優勢:
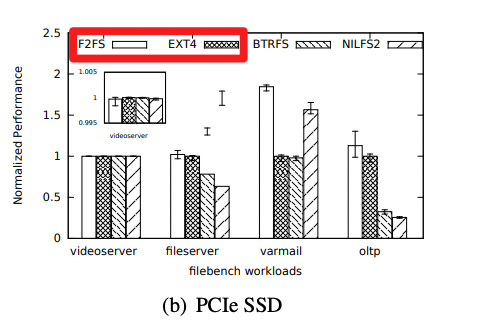
△F2FS: A New File System for Flash Storage》 圖4
業界涌現出新硬件控制讀長尾。硬件標準如 OpenChannel[3,4],在塊存儲之外還額外提供了接口,使得業務可以更加精細地控制數據位置和命令調度,從而結合業務特點,在一定程度上實現了讀寫隔離,進而控制了長尾效應。曾經,Linux LightNVM[5] 試圖標準化對 OpenChannel 的操作,但由于難以定義合理且簡單的塊操作接口,最終被放棄,這也催生了 Zoned Namespace SSD(ZNS)[6] 新的硬件標準。ZNS 硬件并不是傳統的塊存儲,而是一種稱為 Zone 存儲的概念。整個固態硬盤被劃分為多個等長的區域,稱為 Zone。Zone 內的數據必須以順序的頁對齊方式進行寫入,并且在進行 Zone 內數據復寫之前,需要對整個 Zone 進行 reset 操作。ZNS 硬件層面,也按 Zone 接口做了擦除單元隔離。
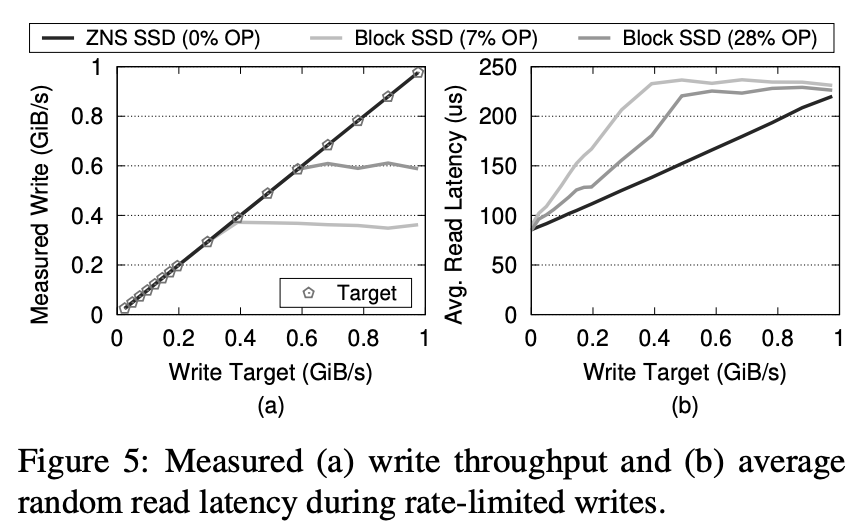
△《ZNS: Avoiding the Block Interface Tax for Flash-based SSDs》圖5
新硬件的引入和打磨需要較長的周期,短期的業務需求亟需滿足。從長遠來看,ZNS 固態硬盤是未來的發展趨勢,我們也已經和基礎架構團隊共同探索。然而,在當前情況下,我們需要充分利用現有的檢索池中的 Nvme 存儲。為此,我們發起了 Ecomm Uniform SSD Layer - SsdEngine 項目,其目標是在底層集成各種硬件(包括 NVMe、ZNS),在上層根據典型的商業業務場景封裝接口,讓商業業務最大限度用上硬件發展和軟硬件結合的技術紅利。
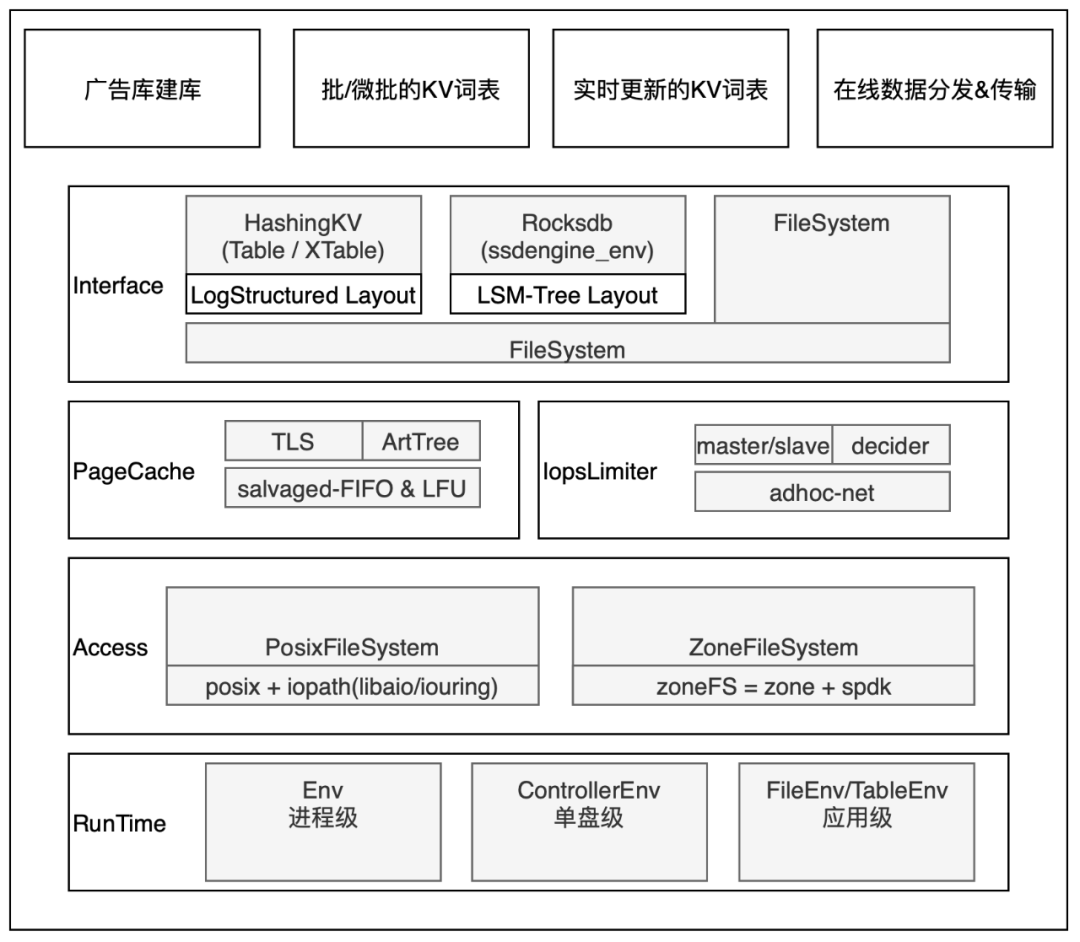
△SsdEngine整體架構
通用場景 NVMe 長尾完全不可控,檢索特化場景長尾可控。Nvme SSD 在實際應用中確實受到多種讀寫干擾因素的影響,其主要因素包括讀寫單元大小(ValueSize)、讀寫頻次(IOPS)、數據生命周期一致性(Lifetime)等等。這些影響因素的作用是復雜的,且無法簡單地通過公式化加以描述 [7]。然而,檢索業務也有應用特殊性:檢索業務屬于重讀輕寫的場景,在滿足足夠吞吐用于回溯止損的前提下,我們甚至愿意在一定程度上犧牲一部分寫吞吐,以換取更為穩定的讀性能。基于這一背景,結合檢索業務的獨特特點,我們采用了硬件友好的磁盤訪問模式(Disk Access Pattern),并設計了一套基準測試(Benchmark)方案,以此來進行系統性能評測。在評測中,我們針對占檢索池大頭的數種 NVMe 盤型號進行了測試,最終得出以下結論:通過控制讀單元大小(ValueSize = 4K)以及調整讀寫吞吐比(IOPS Pattern),能夠有效操控讀寫影響,從而實現對讀操作長尾的控制。下圖是對于Intel P3600 盤,在讀 999per 5ms 的情況下,物理盤最佳“讀寫配比”。
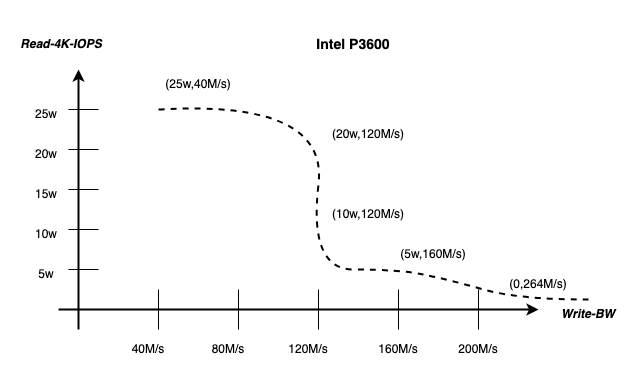
△Intel P3600 讀長尾可控的讀寫配比
混布環境下控制單盤 IOPS 是涉及多層次的復雜問題,本文只分享單實例實踐。在單個實例中,要嚴格控制讀寫吞吐,就要從默認的基于 PageCache 的讀寫模式,轉換為使用 Direct I/O(以下簡稱 DIO)模式,以便獲取硬件級別的讀寫控制權。操作系統將數據存儲在 PageCache 中,以供后續的 I/O 操作直接從內存中讀取或寫入,從而顯著提高讀寫性能。在切換到 DIO 讀寫模式時,為了彌補缺少 PageCache 的性能影響,我們引入了 Libaio/IoUring 異步訪問機制,充分發揮 SSD 的并行處理能力。下圖是隨機讀 randread 和順序讀 read 混合的評測,如果純順序讀,那么 PageCache 吞吐可達 1+G,且具備性能優勢,為此我們也進一步做了頁緩存的工作,此處先按下不表。
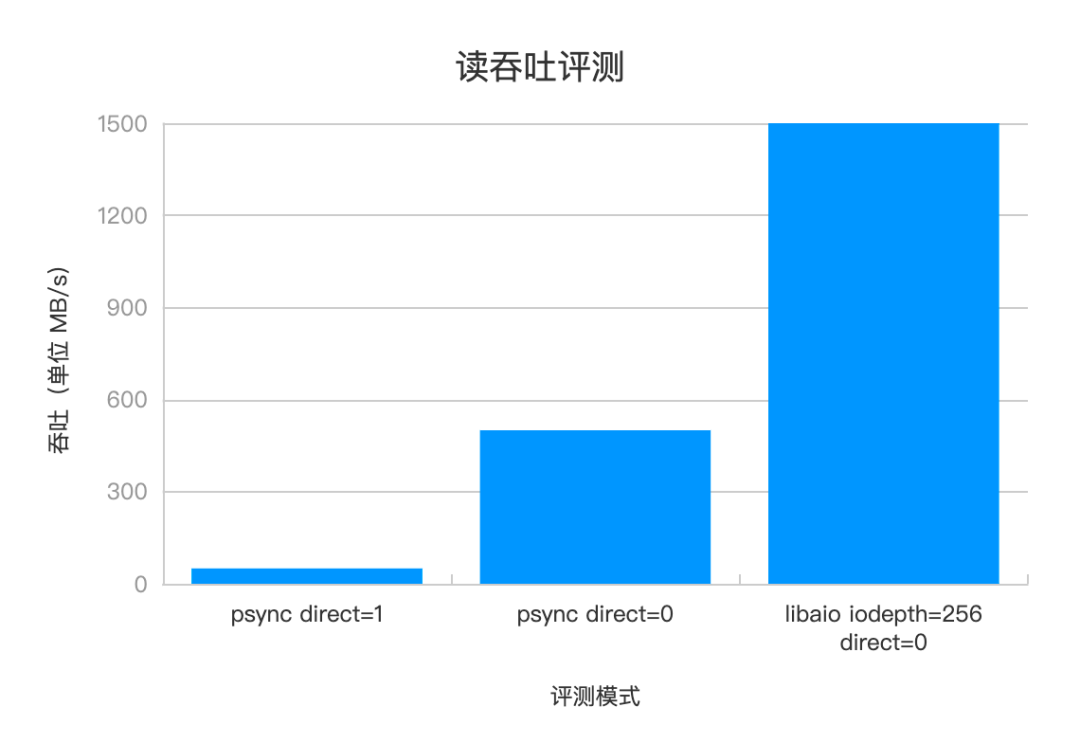
△單機吞吐評測數據
03解決方案
3.1集成 Libaio
Linux Libaio 的操作接口和工作原理十分直觀。常規操作接口分三步:
(1)通過 io_prepare 準備異步請求。
(2)io_submit 發送一批請求。
(3) io_getevents 采用 polling 的方式等待所有請求結束。
工作原理層面,io_submit 將所有請求都提交給了 IO 調度器,IO 調度器做完合并、排序類調度優化后,通過對應的設備驅動程序提交給具體的設備。經過一段時間,讀請求被設備處理完成,CPU 將收到中斷信號,設備驅動程序注冊的處理函數將在中斷上下文中被調用,調用 end_request 函數來結束這次請求,將 IO 請求的處理結果填回對應的 io_event 中,喚醒 io_getevents。
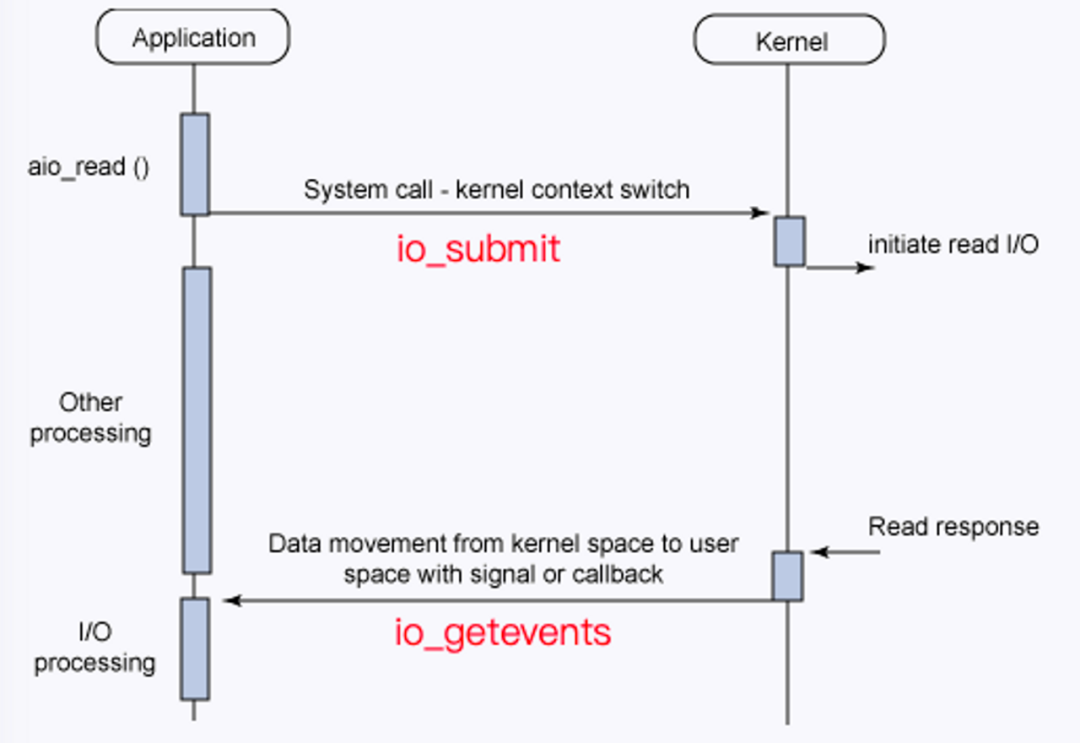
△Libaio 接口示例
SsdEngine 集成 Libaio 的方式也非常直觀。
(1)初始化 IO 任務隊列大小為 iodepth。
(2)批量設置 nr 個 IO 任務的讀參數,包含文件的句柄、大小、偏移量。
(3)一次性提交 nr 個 IO 任務的讀請求。
(4)針對提交的 IO 任務,我們采用分批次等待的方法,設置參數 min_wait_nr 和 batch_timeout,其中 min_wait_nr 的值為 min(nr >> 2, nr - completed) ,作用是減少 io_getevents 系統調用損耗,并實現 IO 任務與后續 CPU 任務的并行化。batch_timeout 會配合整體 timeout,控制整體超長耗時。
// 初始化 Libaio 隊列
io_queue_init(iodepth, context)
// 設置 nr 個 IO 任務的讀參數
for (int i = 0; i < nr; i++) {
io_prep_pread(iocb_list[i], fd, page[i], page_size[i], page_offset[i]);
}
// 提交 nr 個 IO 任務
io_submit(context, nr, iocb_list /*start*/);
// 分批次等待,設置最小等待個數 min_wait_nr,最大等待個數 max_nr - completed,以及超時 ts
while (completed < nr) {
int res = io_getevents(context, min_wait_nr, max_nr - completed/*nr*/, events, &ts);
// IO 任務正確性校驗
for (int = 0; i < res; i++) {
assert(events[i] == page_size[index]);
}
completed += res;
if (total_time_cost > pv_timeout) {
io_cancel();
}
}
3.2 初步集成 IoUring
IoUring 執行過程和 Libaio 大同小異,但更高性能。IoUring 通過實現兩個 Ring 結構,將其映射到用戶空間并與內核共享,以降低元數據復制和系統調用開銷。Submission Ring 包含應用程序發出的 I/O 請求。Completion ring 包含已完成的 I/O 請求的結果。應用程序可以通過更新 Ring 的頭/尾指針來插入和檢索 I/O 請求,而不需要使用系統調用。總結來說,IoUring 之所以比 Libaio 的性能更優,主要有以下三點:
1、系統調用少:Libaio 在設計上每次 IO 操作需要兩個系統調用,IoUring 僅在 IO 任務提交時有系統調用,等待 IO 任務完成則不需要,比 Libaio 少一次系統調用。
2、數據復制:Libaio 存在元數據的復制,IoUring 通過用戶空間和內核共享,則不需要數據復制。
3、數據中斷:Libaio 依賴基于數據中斷的完成通知,IoUring 在 polling 模式下不依賴硬件中斷;使用 polling 需要使用內核線程 kthread,我們是混部環境,該方式不采用。
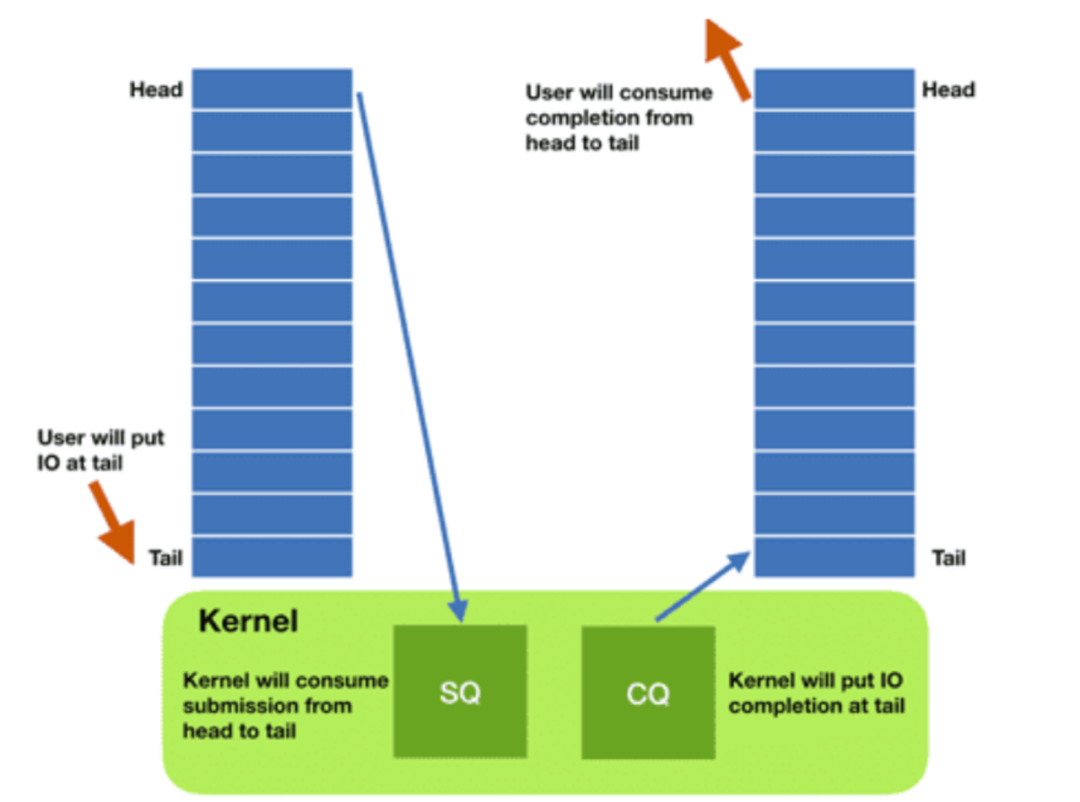
△IoUring 實現原理
SsdEngine 集成 IoUring 的過程卻經歷了一番探索。我們希望使用和 Libaio 同一語義的接口 io_uring_wait_cqes,IoUring Manual[14] 中解釋了該函數的核心參數為,最小等待 IO 任務數 wait_nr 和等待超時 timeout,但是對 timeout 發生時,已經完成多少個 IO 任務,以及對已完成 IO 任務的處理方式沒有做過多的介紹。我們先嘗試參考 Libaio 同語義接口和參數,假設返回的 IO 任務都在 cqe 隊列中直到 nullptr,又嘗試了作者在 ?issue?[15] 中的回答,使用宏 io_uring_for_each_cqe 處理已完成的 IO 任務,但都會在任務的結果校驗環節發生錯誤。最終通過對 kernel 5.10 源碼的跟蹤,我們發現在 io_uring_wait_cqes 函數實現中增加了 io_uring_prep_timeout 超時任務,需要業務單獨處理。我們還發現不同版本內核,超時任務處理并不相同。
io_uring_wait_cqes:填入 wait_nr 等待任務數和 ts 超時參數
1. __io_uring_submit_timeout(ring, wait_nr, ts);
該函數的一個重點是,給 sqe 隊列添加了一個超時任務:io_uring_prep_timeout,這個任務是管理 wait_nr 和 ts 的關鍵
2. __io_uring_get_cqe(ring, cqe_ptr, to_submit, wait_nr, sigmask);
2.1 _io_uring_get_cqe(ring, cqe_ptr, &data);
這個函數是最終調用的主要處理邏輯
2.1.1 __io_uring_peek_cqe(ring, &cqe, &nr_available);
該函數不阻塞直接獲取完成任務的隊列 head,并且表明當前隊列有 nr_available 個;
一個觀察是在返回值沒有 error, cqe 不為 null 時, nr_available 才有含義,因為通過打點,有 cqe 為 null,但 nr_aviailable 不為 0 的情況;
2.1.2 __sys_io_uring_enter2(ring->enter_ring_fd, data->submit, data->wait_nr, flags, data->arg,data->sz);
提交 sqe 隊列。io_uring_submit 最終調用的也是該函數,使用該接口不需要再顯示調用 io_uring_submit!
面向 io_uring_wait_cqes 實現的 kernel 版本自適應編程。總之,我們遇到的問題是在不同內核版本中 io_uring_wait_cqes 的內部實現方式有所不同。具體而言,在 kernel 5.10 及其之前的版本,會在函數實現中新增 io_uring_prep_timeout 任務處理超時,等待超時退出時,用戶需要感知并單獨處理該超時任務。而在 kernel 5.11 及其之后的版本中,函數實現則不再添加 io_uring_prep_timeout 任務。我們線上使用的內核版本屬于前者,因此,在集成 IoUring 時,我們采取添加超時任務標識(LIBURING_UDATA_TIMEOUT)判斷的方式來兼容這兩個內核版本。在超時退出時,低版本內核生成的超時任務會匹配 LIBURING_UDATA_TIMEOUT 的條件分支,此時我們會跳過對該任務的額外處理。而高版本內核則不會觸發這個條件分支。
// 初始化 IoUring 隊列
io_uring_queue_init(iodepth, io_uring, 0 /*flags*/);
// 設置 nr 個 IO 任務的讀參數
for (int i = 0; i < nr; i++) {
io_uring_prep_readv(sqe, fd, iovecs[i], 1, page_offset[i]);
}
// 一次性提交任務【debug 之后發現,使用 io_uring_wait_cqes 接口不需要再顯示的提交任務】
// - io_uring_submit(io_uring);
// 設置 ts 超時參數, wait_nr 等待任務數限制;該函數的返回,要么等到 wait_nr 個任務結束,要么等待超時
while (completed < nr) {
io_uring_wait_cqes(_s_p_local_io_uring, &wait_cqe, wait_nr, &ts, nullptr /*sigmask*/);
io_uring_for_each_cqe(io_uring, head, cqe) {
// 判斷是否為超時 IO 任務
if (cqe->user_data == LIBURING_UDATA_TIMEOUT) {
continue;
}
process(cqe);
io_uring_cq_advance(io_uring, 1);
completed++;
}
}
3.3 自適應切換 Libaio/IoUring
IoUring 有 8% 性能優勢。無論是 FIO 壓測效果,還是 SsdEngine 集成效果,都能看出在廠內機器環境下,IoUring 較 Libaio 可提升 8% 的吞吐。
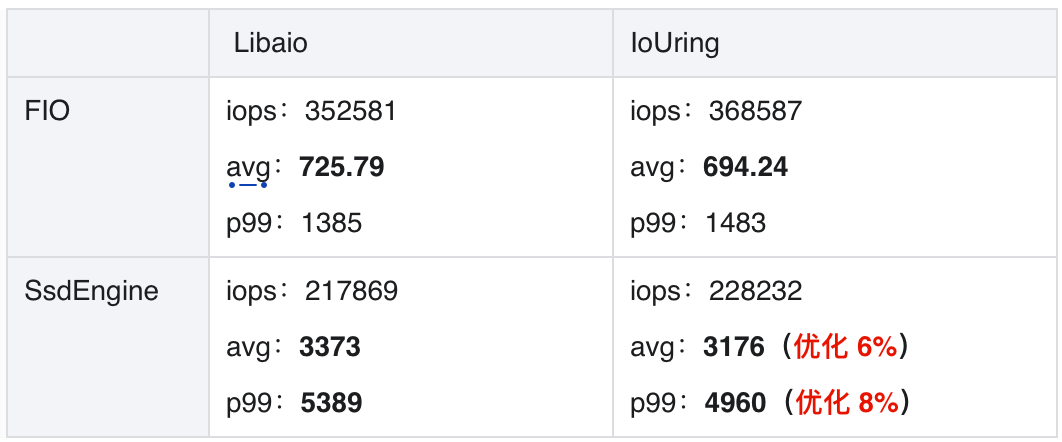
SsdEngine 要盡可能使用 IoUring。但 IoUring 依賴內核版本升級,這也是個較長期的過程。為此我們實現了自適應切換并行調度器,在 5 系之下內核的機器上,自動切換為 Libaio,在 5 系之上內核的機器,自動切換為 IoUring,并且優先 IoUring。
if (io_uring_queue_init(env_test_iodepth, &ring, 0) == 0) {
io_uring_queue_exit(&ring);
return new(std::nothrow) UringPageScheduler;
} else {
return new(std::nothrow) AioPageScheduler;
}
3.4流水線設計
在分層存儲中,存在兩種經典的索引方式:HashKV[8,9] 和 LSM[10]。HashKV 一般是全內存索引,基于哈希函數將鍵映射到存儲位置,因此適用于快速查找,但在范圍查詢上表現相對較差。相比之下,LSM(Log-Structured Merge)索引采用多層次、順序寫入的方式,適合高吞吐量的寫入操作和范圍查詢,但可能在單個鍵查找上略顯繁瑣。對于檢索多讀少寫且點查的場景下,我們采用了 HashKV。
檢索過程中,一次請求會有多個 KV 查詢操作,引入異步并行 IO 的簡易模式是:基于內存串行查詢 HashTable 獲取 value 存儲地址,一次性發起并行訪盤 IO 操作,再等待任務結束。
特別說明:
(1)對于跨多頁的大 Value,在構造查詢任務時候,會拆分為多個按頁大小子查詢任務。
(2)不足一頁按頁查詢。
(3)一次 PV 中重復頁面查詢會被去重。
簡易查詢模式抽象如下圖。橫軸代表時間線,縱軸從上到下依次為應用層代碼的調用順序,在一次批量查詢 IO 任務個數 batch_size 大于并行 IO 隊列的大小(iodepth)時,會重復進行調度流程:schedule- 批量(iodepth 個)查詢內存中的 HashKV 獲取 value 存儲地址, pread - 批量(iodepth 個)設置 IO 任務的參數,submit- 批量(iodepth 個)提交 IO 任務進行處理,wait- 根據 min_nr/max_nr 和 timeout 參數分批次等待 IO 任務的完成,在等待 IO 任務的過程中,并行進行這部分的數據校驗,直到等到所有(iodepth 個)IO 任務的完成。

△簡單查詢模式
我們的優化思路是:把當前的串行的 schedule-submit-wait 模式,改為流水線,增加 IO 和 CPU 的處理并行度。具體實現上,分批次提交任務,等待任務的過程中,執行 HashTable 查詢。面向用戶接口方面,我們額外引入了兩個流水線控制參數,這樣業務可選擇均衡小批量帶來的系統調用開銷和性能提升:
1、batch_submit,一次性提交的 IO 任務數。默認等于 iodepth,即一次性提交任務。
2、iodepth_low,默認等于 1,流水線跑起來之后,IO 任務隊列中低于 iodepth - iodepth_low 個任務的時候,就開始后續任務的填充。
引用流水線后,查詢模式抽象見下圖。核心變化集中在: submit - 原本攢夠 iodepth 個才提交任務,變成攢夠 batch_submit 個就提交任務,這使得 IO 任務可以提前進入 wait 狀態。wait- 原本等完 iodepth 個任務,變成等待 iodepth_low 個任務。schedule- 查詢 HashTable 也因此流水線起來,提升了整體的 IO 任務和 CPU 任務的并行空間(灰色區域)。

△流水線查詢模式
3.5流水線效果評測
評測環境
評測均采用單線程運行的進程,運行環境機型是 CPU INTEL Xeon Platinum 8350C 2.6GHZ ,L1d cache: 48K,L1i cache 32K,L2 cache:1280K,L3 cache:49152K,內核是 64 位 5.10 系,編譯器是 GCC 8.2,編譯優化選項是 -O2。
評測內容
為了充分驗證流水線效果,我們評測了兩種讀盤場景:場景一、海量 KV,大量讀盤和 HashTable 查詢;場景二、超大 Value,大量讀盤,但極少量 HashTable 查詢。
場景一、海量KV
設置一次查詢 pv 會發起 1024 次 kv,其中 value 大小為 4K,基本對應到 1024 次 HashTable 訪存查詢和 1024 個訪盤 IO 任務。設置 iodepth=512,iodepth_low=1,調整 batch_submit 為 512、256、128、64、32,觀察不同參數下,IO 任務的平響(io_us)、99 分位(io_us_99) ,評測數據見下。
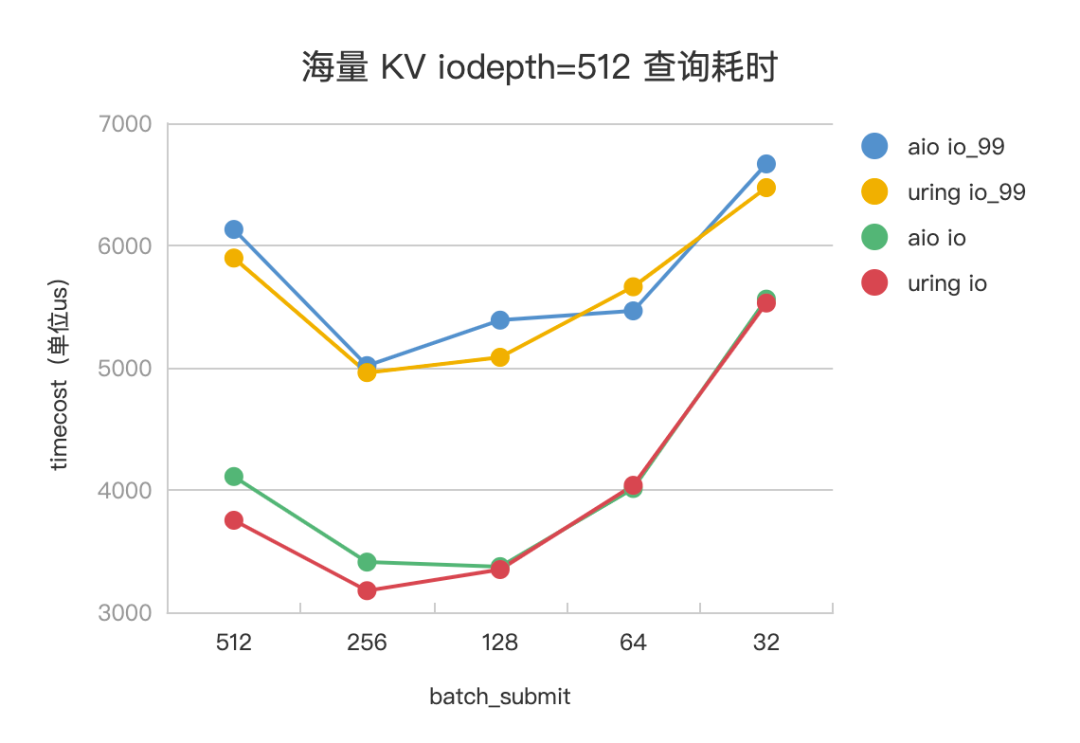
△海量 KV 查詢耗時
場景二、超大Value
設置一次查詢 pv 會發起 20 個 kv 查詢,其中 value 大小為 1M,基本對應到 20 次 HashTable 訪存查詢和 245*20=4900 個訪盤 IO 任務。設置 iodepth=512,iodepth_low=1,調整 batch_submit 為 512、256、128、64、32,觀察不同參數下,IO 任務的平響(io_us)、99 分位(io_us_99) ,評測數據見下。
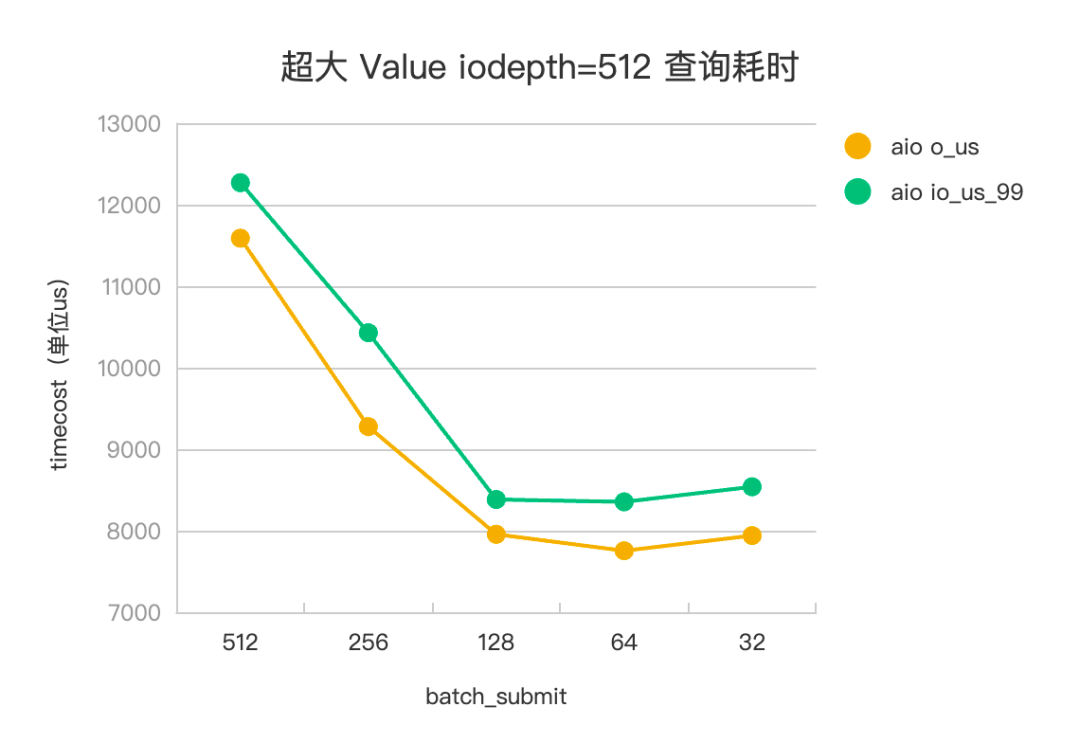
△超大 Value 查詢耗時
評測結論
以 Libaio 評測數據為例。在海量 KV 場景下,batch_submit=512(iodepth) 時,沒有開啟流水線,IO 任務平響 4110us,batch_submit=128 時,是開啟流水線的最佳平響參數,IO 任務平響 3373us,有 15%+ 的平響優化。在超大 Value 場景下,batch_submit=512 (iodepth)時,沒有開啟流水線,IO 任務平響 11.5ms, batch_submit=64 時,是開啟流水線的最佳平響參數,IO 任務平響 7.7ms,有 30%+ 的平響優化。IoUring 和 Libaio 的評測效果趨勢一致。
04應用場景
正如背景中所指出的,引入落地頁信號對于用戶體驗和總體收入都具有積極的影響。然而,在過去迫于鳳巢正排服務的內存容量限制,粗排環節僅能使用 64 位的簽名 Sign 推導出歸一化 URLID,整條計算鏈路環節過多,帶來了一致性方面的問題。經過最近一個季度的努力,通過在鳳巢正排服務中引入URL明文,得到了準確的 URLID,我們顯著提高了體驗評估的 QLQ 準確性,實驗組相較對照組提升了10.8pp,業務收入也得到了明顯增長。未來,我們還將把落地頁信號引入到更多的粗排 Q 中,進一步提升總體收入。
05相關工作
廣告基礎檢索系統的模塊,可被視為一種業務特化的內存數據庫。我們觀察到,在內存數據庫領域中出現了類似的發展趨勢:在上世紀 90 年代,隨著內存成本的降低和容量的增加,內存數據庫得到了發展。然而,隨著業務存儲量的不斷增加,內存的限制逐漸顯現。進入 2010 年代,LargerThanMem 分支應運而生[11,12,13],從歷屆論文看,該分支還比較學術,主要研究兩個關鍵問題:
1、如何引入分層存儲,但又避免引入過多的 I/O 開銷,即研究熱/冷執行路徑(Hot/Cold Execution Path)。
2、在分層存儲后,如何設計自適應的冷熱數據淘汰和檢索策略。
問題 1 是系統設計的技術問題,而當前的 SsdEngine 設計主要關注了這一問題,我們在緩存、調度和訪盤等方面都有明確的規劃和實現。在廣告檢索業務中,冷熱數據的分布特性明顯存在。當前,我們只針對廣告庫的場景,通過商業廣告同步系統的旁路實現,實現了業務分層。未來,在詞表場景中,我們還將探索問題 2 的解決方案。
長尾控制在某些特定生產環境中才會成為一個突出問題,我們可以將其視為 LargerThanMem 在廣告檢索中所特有的挑戰。如上所述,在混合部署的環境中,對單盤的 IOPS 進行控制是一個涉及多個層次的復雜任務。廣告基礎檢索服務的特點是寫少讀多且具備穩定量化的局部性,單實例頻控 + 超時控制,已足夠控制讀長尾。但隨著 SsdEngine 進一步推廣應用,包括單盤的 Adhoc 組網通信以及集群按照 IOPS 分配,也需要應用起來。
審核編輯:湯梓紅
-
存儲
+關注
關注
13文章
4353瀏覽量
86169 -
內存
+關注
關注
8文章
3055瀏覽量
74327 -
SSD
+關注
關注
21文章
2887瀏覽量
117856 -
文件系統
+關注
關注
0文章
287瀏覽量
19978 -
nvme
+關注
關注
0文章
222瀏覽量
22732
原文標題:極致優化SSD并行讀調度
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
SSD之優化篇
粒子群算法城鎮能源優化調度問題
基于MAPSO算法的水庫優化調度與仿真
SCADA系統在供水優化調度中的應用
城市軌道交通調度優化
并行調度能耗優化算法
基于MES作業計劃與調度優化

什么是指令調度(上)

什么是指令調度(下)
智能優化算法總結:數字孿生下的車間調度






 工商網監
工商網監
評論