 可觀測平臺如何存儲時序曲線?滴滴實踐全歷程分享
可觀測平臺如何存儲時序曲線?滴滴實踐全歷程分享
滴滴的時序曲線量從 2017 年 到 2023 年增長了幾十倍。整個過程中我們不斷地調整和改進以應對這樣的增長。例如時序數據庫的選型從最初的 InfluxDB,到 RRDtool,又開發了內存 TSDB 分擔查詢壓力,再到 2020 年開始使用 VictoriaMetrics。載體也從全公司最高配的物理機型到現在的全容器部署。其中經歷了很多的思考和取舍,下文將按時間順序,為大家講述這一系列的故事。
2017年 InfluxDB 時代
時序數據庫的一哥 InfluxDB,是我們最初選擇的時序數據庫。但隨著時序曲線的規模變大,InfluxDB 的局限性也開始暴露了出來。同時社區中關于 InfluxDB OOM 的討論也日益增多,其根本原因就在于熱點寫入和查詢,想象一個命中幾百萬曲線的查詢落在了一個 InfluxDB 實例上,OOM 幾乎是必然的。大家也可以在 InfluxDB 社區中搜索 OOM,有 400 多個結果“InfluxDB OOM”。
由于這些問題日益突出,我們不得不重新思考時序數據庫的選型。下圖為當時的可觀測系統在 Influxdb 掛掉后,看圖功能的表現:
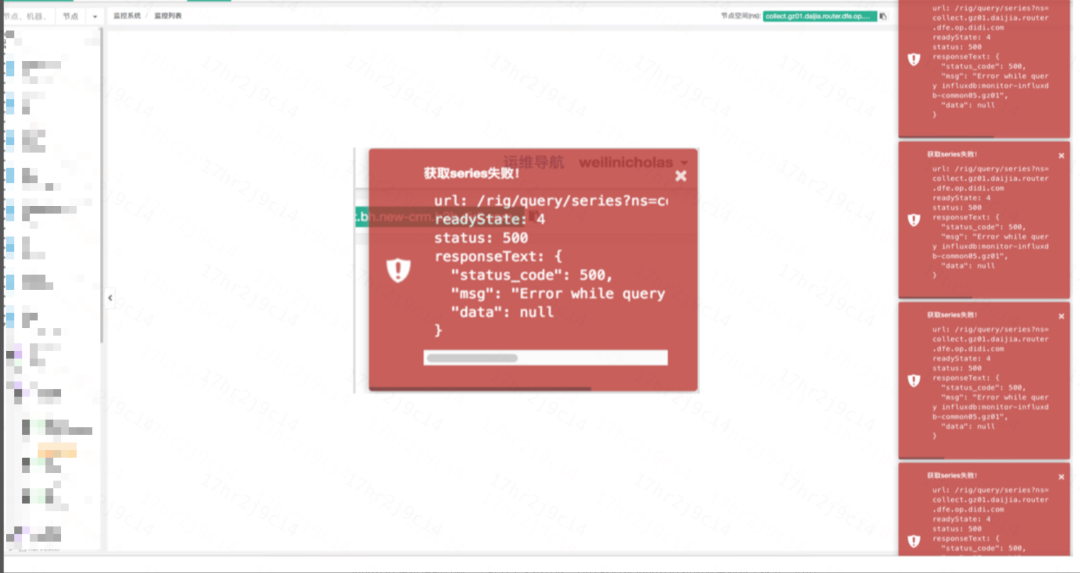
InfluxDBOOM,看圖功能的表現
2017~2018 Open-Falcon 時代
InfluxDB 單機性能有限,集群方案又不開放。盡管我們對 InfluxDB 按照業務線做了拆分,但仍面臨著單個服務節點曲線量巨大的情況,對于 InfluxDB 來說難以處理。
在經過深入探索和多次試驗后,我們決定采用 Open-Falcon 使用的 RRDtool 存儲方案,在存儲和查詢鏈路,使用相同的一致性哈希算法,將曲線打散到不同的實例中,從而解決了在 InfluxDB 時代因為熱點過高而導致 OOM 的難題。
2018~2020 后 Open-Falcon 時代
直至 2018 年 4月,RRDtool 方案都一直在滴滴運行著。但隨著曲線量的迅速增長,我們又面臨新的問題——成本問題。成本幾乎是每家互聯網公司在發展到一定階段都難以回避的問題。特別是作為非贏利產品的可觀測平臺,成本問題尤為突出。甚至自 2017 年之后的三年里,盡管我們的存儲集群內存使用率曾高達 90% 以上,仍無法獲取新機器的支援。其中一個原因是,我們需要的機器配置過高,甚至連當時配備的 NVMe 磁盤這種頂配機型的 IO 使用率也超過了 90%。預算委員會完全不相信會有一種服務同時對 CPU、內存和 IO 都有如此高的需求。
面對這種困境,我們陷入了兩難境地。一方面是用戶源源不斷的壓力,另一方面是無法滿足存儲所需求機型的要求。
在經過一段時間的思考與調研,我們發現 80% 以上的查詢請求都集中在最新的 2 個小時內。因此,我們嘗試將存儲進行冷熱分層,建設一個新服務來分擔存儲的壓力,正好在這個時候,我們了解到了 Facebook Gorilla 的論文,于是一個名為 Cacheserver 服務應運而生。
Cacheserver 的設計靈感來源于 Facebook Gorilla 論文,旨在與原有存儲服務共同承擔請求,只針對最新 2 小時數據的查詢請求,大大減輕了 RRDtool 服務集群的壓力。這種冷熱分層的架構不僅緩解了存儲成本問題,還提升了整體性能和查詢效率。
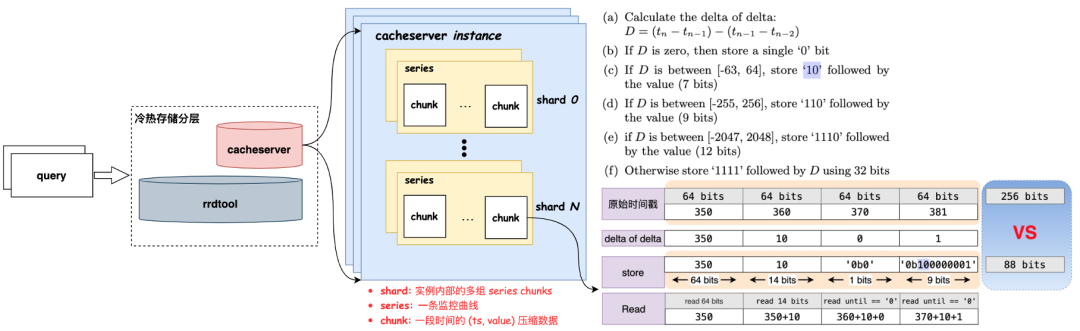
Cacheserver 架構
2020 ~ 今 VictoriaMetrics 時代
隨著滴滴容器時代的到來,我們面臨著更加艱巨的情況。
首先,隨著容器覆蓋率的不斷提高,時序曲線量瘋狂增長。而 2020 年隨著容器覆蓋率繼續提升,曲線增長預計會超過 100%。
此外,成本壓力繼續增大。盡管 RRDtool 架構可以橫向擴展,但可觀測自身的成本無法再隨業務增長而線性增長。
當前 RRDtool 架構高需低產,必須使用 SSD/NVMe 機型,使用普通磁盤在落盤時會直接 hang 死。而且功能上也僅支持 sum、avg、max、min 等有限的幾個函數,無法滿足用戶日趨豐富的需求。
為節省存儲空間,當時僅保留 2 小時原始數據。而用戶需要更長時間(例如 15天)的原始數據進行查看和分析,然而,更改降采策略會帶來 2 個問題:一是 RRDtool 的降采修改會導致所有數據丟失。二是存儲 15 天的原始點會使每條曲線存儲空間變為原來的 8.5 倍(120KB → 1MB)。
因此從 2020 年初開始,我們開始著手調研新的方案。需要更高效、靈活的存儲架構以應對以上種種問題。
有哪些備選方案?
在選擇新的存儲方案時,我們考慮了多個備選方案,包括:
Druid
Prometheus
Thanos/Cortex
M3
VictoriaMetrics
Druid?
Druid 是滴滴另一套系統 Woater 的時序存儲方案,由大數據團隊運維。然而,我們最終不考慮 Druid,主要原因如下:
模型不滿足:Woater 的存儲模型是預先定義好的 Schema(Dimensions),而我們需要的是動態 Schema,這是 Druid 原生不支持的,雖然大數據團隊表示可以開發支持,但有著諸多條件限制。
成本問題:將現有數據存儲到 Druid 成本將增長 10 倍。
性能問題:Druid 寫入性能還不如 RRDtool,寫入能力較差,因為 Druid 要做 Rollup,而 RRDtool 是直接 Append 數據。
“無用”的 Rollup:Druid 的亮點功能 Rollup,對于我們的場景并不適用,因為絕大部分查詢都是針對原始值而非 Rollup 結果。
Prometheus?
Prometheus 是可觀測領域的事實標準,其存儲模型、DSL 以及生態都吸引著眾多用戶和企業的關注。但在滴滴的場景下,我們也沒有選擇 Prometheus,主要原因在于:
沒有長期存儲:Prometheus 主要專注于對短期數據的存儲和查詢,而我們需要長期保留。
沒有集群方案:Prometheus 無內置的集群方案,要實現橫向擴展,需要依賴第三方架構如 Thanos、Cortex 等,這無疑增加了復雜性。
沒有高可用能力。
盡管針對這些問題,社區提供了一些解決方案,但在滴滴的體量下,這些解決方案都無法滿足我們的生產化需求。
Thanos、Cortex?
Thanos 和 Cortex 可以說是 Prometheus 當時唯二的,集群化和長期存儲方案。它們的設計目標都是要解決如下問題:
Global View:可以跨多個 Prometheus 實例進行查詢以實現全局視圖。
Long Term Storage:實現長期存儲以滿足長期分析和回溯的需求。
High Availability。
這些特性使得 Thanos 和 Cortex 成為 Prometheus 生態中重要的補充。
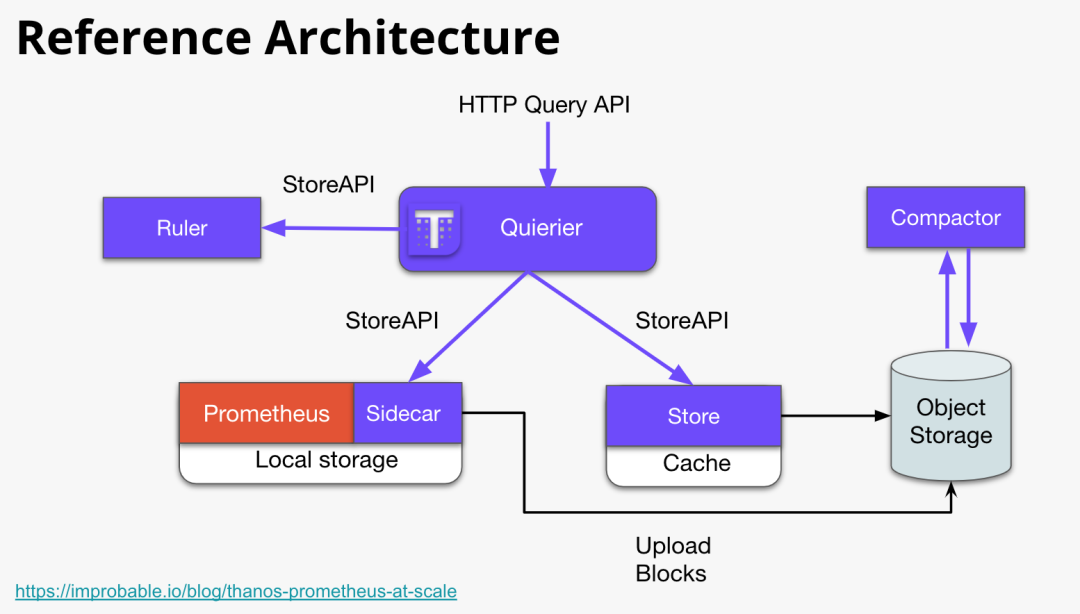
Thanos 架構
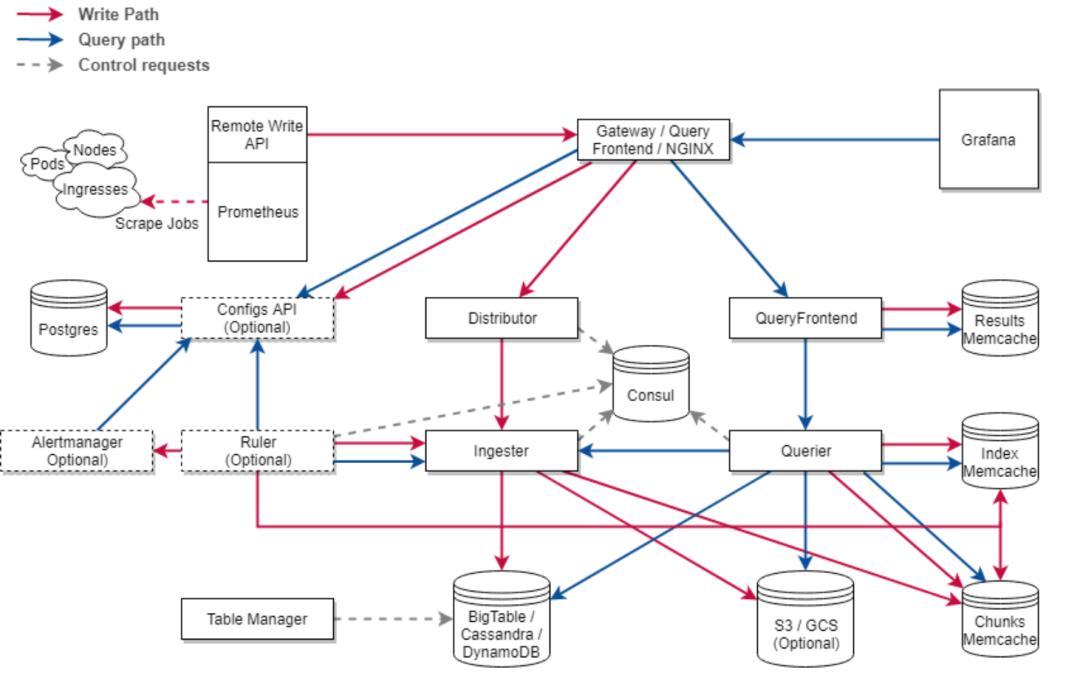
Cortex 架構
但 Thanos/Cortex 也存在一些問題:
Cortex 的存儲結構,其內部仍在探索當中,還不夠穩定,Blocks 在當時還處于 Experimental 狀態。
Thanos 和 Cortex 均需要引入對象存儲,可能帶來一些額外的管理成本,性能上也要畫一個問號。
Thanos Remote Read 內存開銷太多,例如當時有人提出如下圖所示的問題:
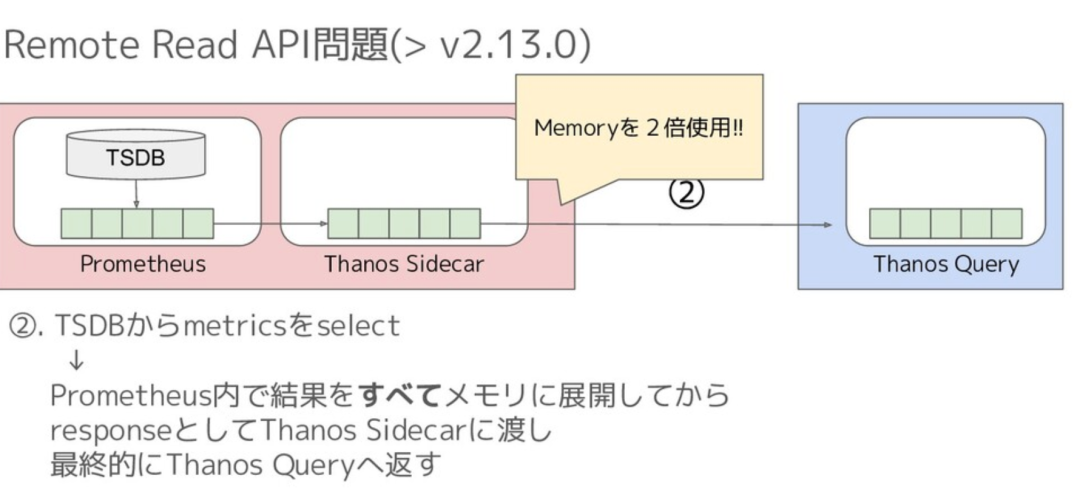
Thanos 內存問題
缺乏大規模生產環境的洗禮:Thanos 和 Cortex,這兩個看似美好的解決方案,都有他們的硬傷。也缺乏大規模生產環境的實際驗證,可靠性和穩定性可能還需更多的驗證和優化。
Uber M3?
M3 是 Uber 開源的 TSDB 解決方案,盡管有一些優勢,但也存在一些缺點,包括管理成本高(例如引入 etcd)和機器成本沒有優勢(仍需要高配 SSD)。
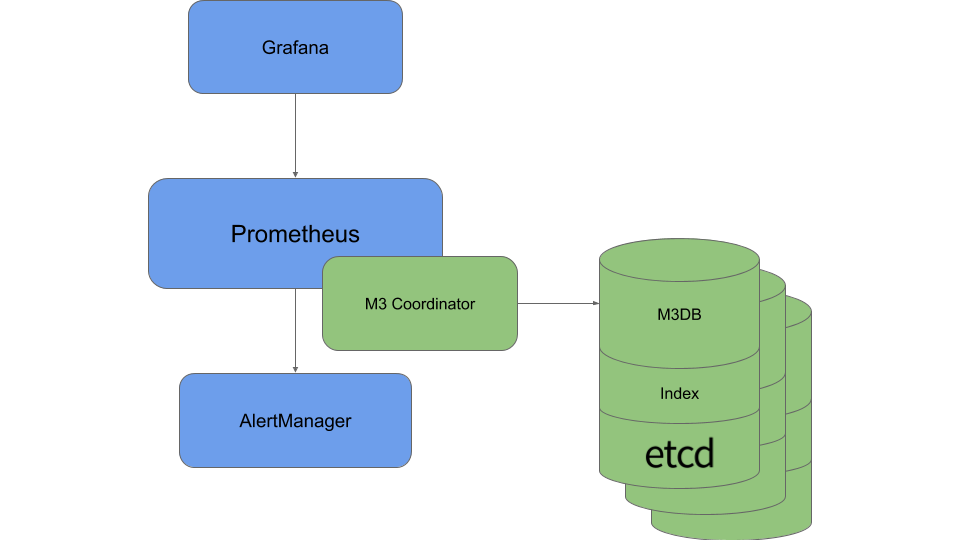
M3 架構
VictoriaMetrics?
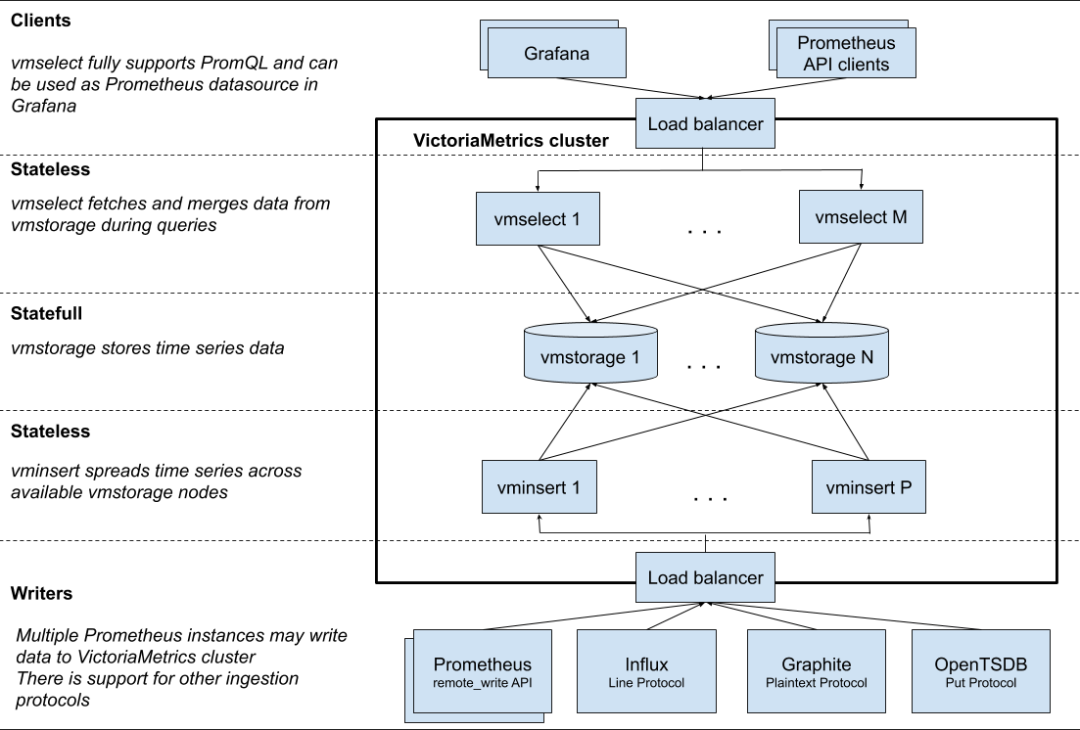
Victoriametrics 架構
VictoriaMetrics 是一個性能高、資源要求和運維成本都比較時序數據庫,其主要特色和原理包括:
要求資源低:VictoriaMetrics 可以在普通機型上運行,不需要使用 SSD/NVMe 等高性能硬件。
核心存儲模型:基于 LSM,類似 Clickhouse。它將數據緩沖在內存中,并每秒鐘將其刷寫到磁盤上的分區目錄中。較小的分區會在后臺逐漸合并成更大的分區。
列式存儲:VictoriaMetrics 采用列式存儲,使得讀寫性能非常高,1個CPU核心可以掃描 30M points/s。
寫入速度強:單實例 760K point/s 的寫能力(vs RRDtool 210~260K point/s)。
壓縮:采用改進版 Gorilla 結合通用壓縮算法(Facebook zstd),平均僅需 1.2~1.5 bytes/point,壓縮比達 13%。
集群容易擴展:采用 Share Nothing 設計。擴縮容機器方便。機器損壞時還可以自動 Rerouting。
無降采樣:不降采的設計,使得原始數據得以保留。
兼容 Prometheus:在寫入、寫入方式等都兼容 Prometheues。并針對 PromQL 做了增強(MetricsQL)
亂序時間戳的弱支持。
容量可計算:VictoriaMetrics 的容量是可計算的,我們可以更直觀和方便的預估存儲需求。

VictoriaMetrics Capacity Planning
如上所述,因為 VictoriaMetrics 在性能、壓縮率、查詢速度和擴展性等方面表現出色。在綜合考慮了各個方面的需求和考慮后,我們認為 VictoriaMetrics 是適合我們的時序數據存儲方案,能夠滿足我們的需求。
VictoriaMetrics 的問題及解決方案
盡管 VictoriaMetrics 作為時序數據庫解決方案有許多優勢,但也存在一些潛在問題,這里列舉幾點并簡要地給出了我們的解決方案:
資源占用問題:磁盤空間占用量與存儲點數成正比,存儲越多越長的數據,磁盤空間需求越多。為解決這個問題,我們針對不同的業務線,設置了不同的保留時長。
無降采樣:VictoriaMetrics 不支持數據降采樣,即不會自動對數據進行聚合或丟棄,而是保留原始數據。這在某些場景下可能會導致數據存儲需求較高,特別是在存儲長期數據時。不過,由于 VictoriaMetrics 查詢速度快且壓縮率較高,這個問題并沒有對成本和系統性能造成顯著影響。
活躍度有限、不夠主流:相對于其他一些主流的時序存儲方案,當時 VictoriaMetrics 的活躍度可能還不夠高。然而,通過對代碼的深入了解和與作者的多次交流,我們對VictoriaMetrics 的質量和性能表現逐漸建立信心。
多集群 VictoriaMetrics 設計
我們基于 VictoriaMetrics 設計并實現了一個多集群方案,旨在提高系統的可擴展性和可用性。例如下圖我們在 region 1 搭建了多套集群,分別處理不同業務線的數據,隔離了各業務線的資源競爭和影響,也縮小了故障域。多個 region 之間也可以選擇 mixer 來實現跨區域的數據讀取和合并。
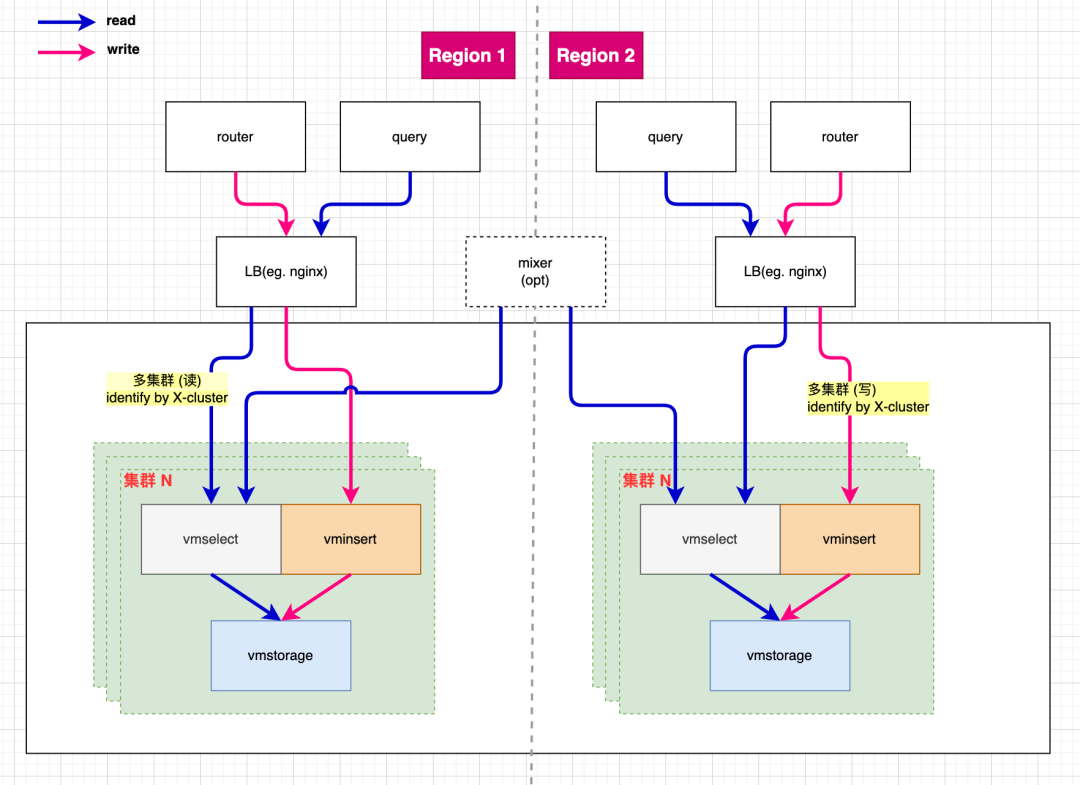
VictoriaMetrics 多集群設計
結尾
以上介紹了滴滴可觀測的時序存儲解決方案的發展歷程。希望通過這個分享,能夠為其他團隊和開發者提供一些有益的經驗和啟示,也歡迎一起交流和探討。
限于文章篇幅,無法在這里展開更多。例如 VictoriaMetrics 的容器化部署,故障管理,復制,數據遷移等。這些內容將在后續的文章中為大家介紹,敬請期待!
-
數據庫
+關注
關注
7文章
3848瀏覽量
64687 -
架構
+關注
關注
1文章
519瀏覽量
25554
原文標題:可觀測平臺如何存儲時序曲線?滴滴實踐全歷程分享
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于 eBPF 安全可觀測性,你需要知道的那些事兒
基于拓撲分割的網絡可觀測性分析方法
如何將可觀測性策略與APM工具結合起來
介紹eBPF針對可觀測場景的應用
六大頂級、開源的數據可觀測性工具
基調聽云攜手道客打造云原生智能可觀測性平臺聯合解決方案
華為云應用運維管理平臺獲評中國信通院可觀測性評估先進級
從技術到商業價值:基調聽云智能可觀測性平臺能力升級,持續滿足不斷變化的市場需求
使用APM無法實現真正可觀測性的原因
如何構建APISIX基于DeepFlow的統一可觀測性能力呢?
華為云發布全棧可觀測平臺 AOM,以 AI 賦能應用運維可觀測

【質量視角】可觀測性背景下的質量保障思路
華為云全棧可觀測平臺——9 月 10 月新功能特性






 工商網監
工商網監
評論