 大模型AI芯片 群雄逐鹿,誰主沉浮?英偉達NVIDIA?AMD?華為?
大模型AI芯片 群雄逐鹿,誰主沉浮?英偉達NVIDIA?AMD?華為?
★深度學習、機器學習、生成式AI、人工智能、大數據、高性能計算、ASIC、大模型訓練、盤古大模型、CPU、GPU、L40S服務器、華為、英偉達、A100、H100、A800、H800、穩態微聚束、SSMB、清華 SSMB-EUV 光源、非線性動力學、AI芯片、ChatGPT、Transformer、自監督訓練、高算力芯片、高粘性 CUDA、Graphcore、Habana、Cerebras、SambaNov、寒武紀、FPGA、Grace CPU、Hopper GPU、GH200、 SIGGRAPH 、HBM3e、MI300A、MI300X、Infinity Fabric、TPU、AWS、Inferentia、Trainium、Alexa、Meta、MTIA
隨著人工智能、大數據、高性能計算、生成式AI和大語言模型的快速發展,芯片技術和服務器市場變得越來越重要。大模型需要高性能芯片支持,而芯片技術的發展又為大模型應用和推廣提供可能。在這篇文章中,我們將探討推進芯片快速發展的技術(穩態微聚束加速器光源)、華為和英偉達顯卡的對比以及賦能生成式AI和LLM大模型負載L40S服務器。
在大模型下的芯片技術領域,GPU、CPU和ASIC等技術得到了廣泛應用。GPU作為圖形處理器,最初是為了處理圖像和游戲等任務而設計的。然而,隨著人工智能和深度學習的發展,GPU逐漸成為大模型訓練和推理的首選芯片。
華為和英偉達顯卡在大模型服務市場中具有重要地位。華為依托其強大的技術實力和品牌影響力,在顯卡市場中占據一席之地。英偉達則憑借其領先的GPU技術和廣泛的應用領域,成為了大模型服務市場的領導者。在銷售量和市場份額方面,英偉達略勝一籌,但是華為和其它競爭對手也在不斷追趕。
GPU L40S采用先進的芯片技術,可以快速、準確地處理大規模的數據。具有高度的可擴展性,根據需要增加或減少計算資源。此外,還采用先進的算法和模型優化技術,大大提高模型訓練的效率和精度。
穩態微聚束加速器光源
在芯片制造領域,光刻技術一直扮演著至關重要的角色。然而,傳統的光刻技術也存在一些明顯的局限性,這些局限性在新一代芯片制造中變得尤為明顯。傳統的光刻技術需要使用大型、昂貴的設備,如荷蘭ASML公司生產的***。這些設備的高成本使得芯片制造過程變得昂貴,不利于成本的降低。而且,傳統的光刻技術在追求更小的制程和更高的性能時遇到了困境,因為它們受到了光源功率上限的限制。這導致了制程的瓶頸,制約了芯片技術的發展。
清華大學的唐教授提出的“穩態微聚束加速器光源”為芯片制造帶來了一種全新的思路。這一方法的核心在于通過高能加速器對電子進行加速,然后讓這些電子穿過交替變化的磁場,從而產生高頻率和短波長的電磁波,包括可見光和X射線。簡單來說就是將電子加速到接近光速,從而獲得更短波長的光,為芯片制造提供了全新的工具。
一、加速器光源簡介
同步輻射是帶電粒子在高速運動時產生的電磁輻射,其特點包括高亮度、寬譜帶、高準直性和偏振性等。自20世紀70年代起,人們開始專門建設電子儲存環來產生同步輻射。一個同步輻射光源由電子注入器、電子儲存環和光束線站組成,追求高亮度和更好相干性,經歷四代的發展。中國大陸的北京同步輻射裝置屬于第一代,合肥光源屬于第二代,上海光源屬于第三代,正在建設的高能同步輻射光源屬于第四代。同步輻射的亮度定義為單位時間、單位面積、單位發散角、0.1%帶寬內的光子數。

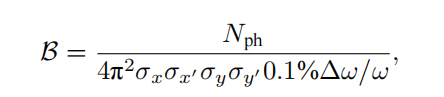
同步輻射光源的相干性包括橫向和縱向兩方面。橫向相干性與光源尺寸有關,縱向相干性與光源譜寬有關。為獲得更高亮度和相干性,需要提高輻射強度、縮小譜寬、減小電子束的發散角。同步輻射光源的發展已經降低電子束的橫向發散角,從而獲得良好的橫向相干性,但縱向相干性仍然較弱,導致束長遠超過相干長度,輻射功率較低。
自由電子激光克服這一缺點,利用電子束在波蕩器中自放大發射的原理,通過電子束和輻射波在波蕩器中相互作用形成微聚束,產生強相干輻射。這種正反饋過程導致輻射指數增長,與同步輻射相比,自由電子激光的峰值亮度提高8-10數量級,相干性更好,脈沖長度更短。其使用自由電子而不是束縛電子,輻射波長可以靈活調節。
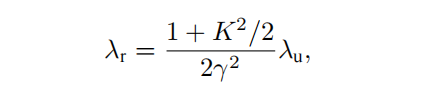
自由電子激光的輻射波長由電子束能量、波蕩器參數和相對論因子γ決定,而在X射線波段,自由電子激光是唯一的相干光源。可分為低增益模式和高增益模式,早期主要是低增益模式,輻射在共振腔內被多次放大,而當前主要發展的是高增益短波長自由電子激光,即電子束單次通過波蕩器就完成從發射到飽和的過程,特別是X射線自由電子激光。
高增益短波長自由電子激光對電子束質量的要求很高,需要電子束橫向發散度足夠小、能量散度足夠小、電流足夠大,以保證增益大于損耗。
自由電子激光裝置示意圖
高增益自由電子激光對電子束質量要求非常高,需要高峰值電流、低發散度和低能量散度。為滿足這些要求,主要依靠直線加速器產生電子束。與儲存環不同,自由電子激光的重復頻率較低,為獲取高重復頻率,正在研發采用超導射頻直線加速器的自由電子激光。
加速器光源已成為人類探索物質世界的最前沿工具之一,基于電子儲存環的同步輻射光源提供高重復頻率的輻射,基于直線加速器的自由電子激光提供高峰值亮度的輻射,是兩種主要類型的加速器光源。這兩類大科學裝置孕育眾多突破性基礎研究成果,在先進制造與產業發展中的作用難以估量。
全球有超過50個同步輻射光源和7個X射線自由電子激光裝置建成或在建,最先進的加速器光源因其光束質量、科研支撐作用、建設投入和技術復雜程度,已成為國家綜合實力和競爭力的重要體現。
二、穩態微聚束加速器光源原理
隨著加速器光源的發展,用戶需求也在不斷增長,除同步輻射和自由電子激光,人們也期待出現一種同時實現高峰值功率和高重復頻率的光源。2010年,Ratner和Chao首次提出一種新型儲存環光源——穩態微聚束(SSMB)。
SSMB使用激光而不是射頻腔來調制儲存環中的電子束。由于激光與電子束的傳播方向垂直,因此不能有效地交換能量。為縱向聚焦調制電子束,扭擺磁鐵被采用,實現激光調制,類似于射頻腔調制。
與傳統儲存環相比,SSMB儲存環的標志是使用激光調制器代替射頻腔。
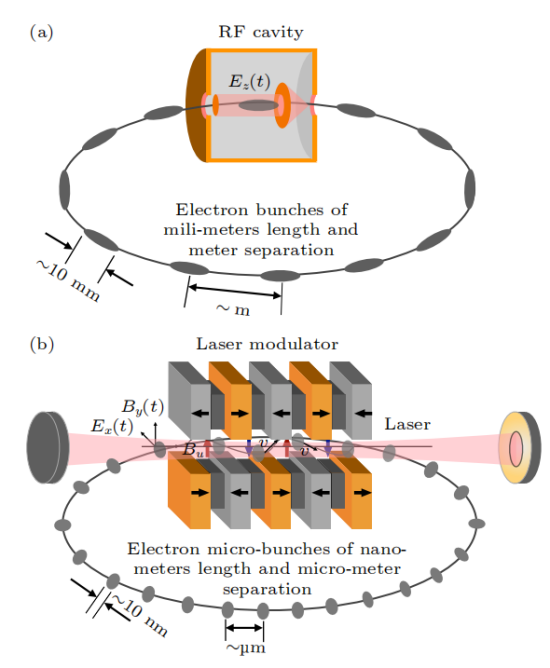
SSMB儲存環(b)與傳統儲存環(a)對比
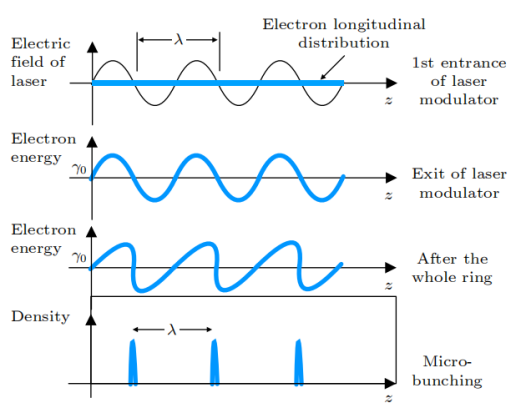
微聚束的原理示意圖
在SSMB儲存環中,由于激光波長比微波波長短了約6個數量級,通過精心設計的磁系統,電子束團長度可以達到亞微米至納米量級,形成微聚束。同時,束團間隔從微波波長縮短到激光波長,使得單位長度內的束團數目提高了6個數量級。與傳統束團相比,微聚束的特點是束團內電子縱向分布長度比輻射波長短,不同電子的輻射場保持相干并相干疊加,使得輻射強度與束長內電子數平方成正比,遠高于非相干輻射的線性關系。
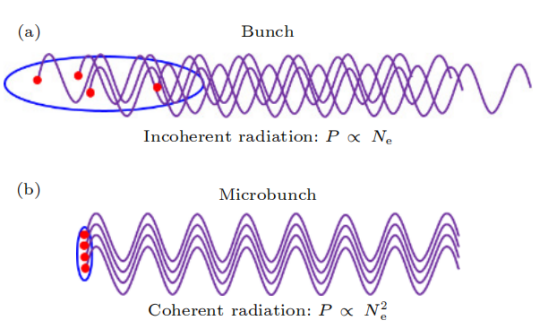
(a)普通束團非相干輻射及(b)微聚束相干輻射示意圖
微聚束產生強相干輻射的原因是含有N個電子的束團輻射功率包括與N線性相關的非相干輻射和與N的平方相關的相干輻射。相干輻射顯著高于非相干輻射需要束長小于輻射波長,因此納米級束長的微聚束可產生短波長相干輻射。
高增益自由電子激光中的微聚束源自束內不穩定性,難以長期維持,而SSMB中的微聚束來自激光主動調制,是穩定的相干輻射,可在環中重復利用。SSMB結合微聚束的強相干性和儲存環的高重復頻率,可提供高平均功率、窄帶寬的相干輻射,具有巨大的潛力。SSMB輻射的多項特性可為加速器光子科學研究和應用帶來新機遇,如EUV光刻的光源等。
三、SSMB 原理的實驗驗證
穩態微聚束(SSMB)從概念到應用必須進行原理驗證實驗。清華大學等自2017年開始進行SSMB原理驗證研究,利用德國的MLS準等時儲存環完成了SSMB的原理驗證。
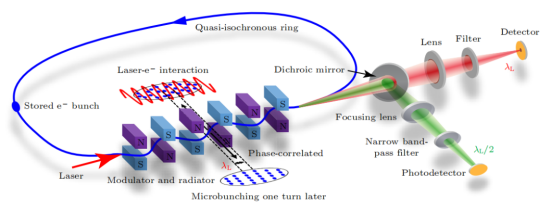
SSMB原理驗證實驗示意圖
在SSMB原理驗證實驗中,利用德國的MLS準等時儲存環,電子束被激光調制能量后,形成微米量級的調制周期密度調制,即微聚束。微聚束在波蕩器中發出強相干輻射,通過檢測該輻射驗證微聚束形成。
實驗結果顯示,被激光調制的電子束輻射信號得到放大,同時窄帶濾波后的信號比寬譜輻射更大,證明了微聚束的窄帶相干輻射。此外,還研究了輻射強度與束流強度的關系。通過這一原理驗證實驗,首次展示了激光調制可在環中產生微聚束并發出相干輻射的效應,完成SSMB核心概念的實驗驗證。
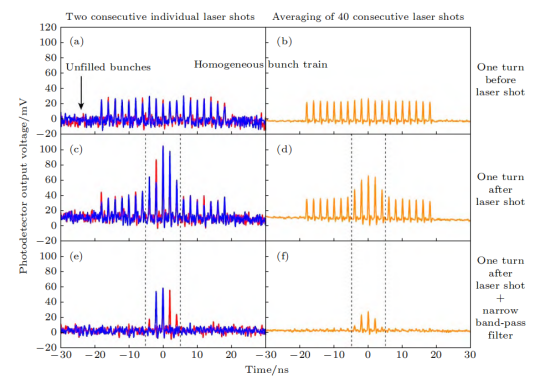
SSMB原理驗證實驗結果
在實驗中,還測量了輻射功率與電荷量的依賴關系,結果顯示了與電荷量平方成正比的特點,這正是相干輻射最重要的特征。此外,輻射呈現窄帶特性。這兩點有力地證明了微聚束的形成。最近,我們還進一步實現了微聚束在儲存環中多圈穩定存在,電子束實現了多圈相干發射。通過檢測輻射功率關系和頻譜特性,驗證了微聚束形成并相干發射。進而展示微聚束可在環中多圈穩定,完成SSMB核心概念的多圈相干發射驗證。
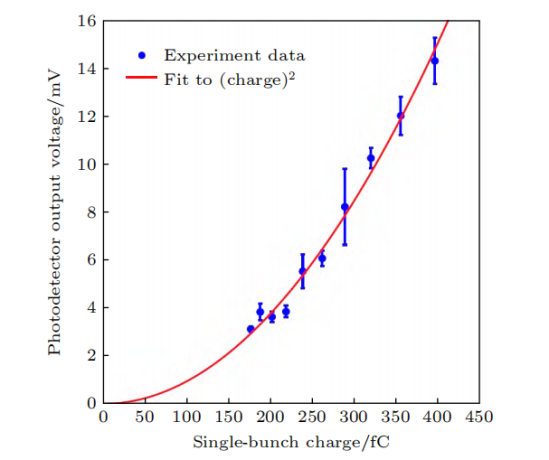
SSMB原理驗證實驗結果
實驗成功實現微聚束的形成和多圈穩定存在,這證明了電子縱向位置能以精確于激光波長的精度在環中關聯,使電子穩定受困于激光形成的勢場。這一實驗與直線段上的微聚束實驗不同,重點在于展示了:
1)微聚束是經過一整圈形成的,驗證粒子動力學的one-turn map概念;
2)微聚束基于預先儲存的電子束形成,電子束參數由儲存環決定。
該實驗僅展示one-turn map的一次迭代形成微聚束,而SSMB需要多次迭代實現穩態微聚束。這是從0到1的驗證,標志著SSMB發展的第一個里程碑。即使在非優化環中,SSMB機理也展現出強大的魯棒性,這激勵我們構建專用環進一步完美實現SSMB。
四、SSMB 儲存環的核心物理問題及關鍵技術挑戰
SSMB原理驗證實驗的成功證明SSMB光源的可行性。為進一步推進SSMB光源的實際建設,需要深入研究其核心物理并解決關鍵技術挑戰。相比傳統儲存環,SSMB中的束長縮短6個數量級,為加速器物理和技術的發展帶來了新的機遇。下一步需要關注SSMB在環中的產生機理、SSMB的輻射特性以及技術實現方面的關鍵挑戰。
1、SSMB 在儲存環中的產生
1)SSMB是一個多次通過的裝置,與電子束團單次通過的高增益FEL不同
要求超短束團在輻射段能夠一圈接一圈地重復出現,即超短束團在輻射段中呈現的是該儲存在環中的本征態。為了實現在較低調制激光功率下的束團壓縮,對于儲環的lattice設計而言,探索橫縱向耦合在每一圈中的利用方式是一個新穎且有趣的課題。
2)非線性動力學效應在SSMB儲存環中起著重要作用
由于對束團的操控要求精微,非線性滑相因子、非線性橫縱向耦合等都可能影響束團動力學,如六維動力學孔徑以及束流在六維相空間的分布。在傳統儲存環中,主要關注橫向動力學孔徑的優化,而SSMB則需要同時關注橫向和縱向,即六維相空間的優化。
因此,需要發展相關的理論并結合先進的數值方法(如機器學習、遺傳算法)進行SSMB的非線性動力學優化。此外,集體效應也是SSMB儲存環中需要關注的問題。由于SSMB儲存環中束團極短,束流的峰值流強和平均流強相對較高,相干同步輻射、束內散射以及阻抗壁尾場等都可能會對微束團結構的穩態參數以及穩定存儲產生影響從而限制束流能量和強度。此外,SSMB儲存環內的束流分布模式不同于傳統儲存環,微束團的輻射可以追上其前方的一個或多個微束團,使得通常被認為是短程的相干同步輻射在SSMB的語境下變為長程。這些因素要求對相干同步輻射、橫縱向耦合導致的束團長度變化、三維任意耦合以及縱向強聚焦lattice中的IBS等進行仔細的評估和研究。
3)誤差容忍度和噪聲分析在非線性效應顯著的SSMB中也變得非常重要
噪聲對電子束團的影響按頻率可分為兩部分:高頻噪聲導致束團在相空間的擴散從而引起發射度的增長,而低頻噪聲會導致束團的質心運動。對于高頻噪聲,需要保證其對束流穩態發射度的貢獻處于可接受的范圍內以實現超短電子束團的形成;對于低頻噪聲,需要保證其對束流的影響滿足絕熱條件,從而使電子束團在質心受噪聲影響發生移動時保證發射度不變。如果噪聲對電子束的影響超出了可接受范圍,需要采用相應的反饋系統或其他阻尼機制來降低噪聲的影響。需要注意的是,由于SSMB的工作模式(如縱向強聚焦、強縱橫耦合)不同于一般儲存環,其噪聲和誤差容忍度的解析分析也將相對復雜。如傳統射頻腔相噪分析中采用的正則微擾論在縱向強聚焦儲存環中就無法直接應用因為該動力系統是不可積的(混沌的)。另一方面借助于現有計算機的強大計算能力可以對噪聲的影響進行直接的數值模擬研究。
2、SSMB 的輻射特性
在形成穩態微聚束后,需要研究SSMB的輻射特性。SSMB的微聚束縱向發散極小,輻射在縱向上高度相干,其束流分布模式獨特。為指導設計與優化,需要研究束流在六維相空間的分布對SSMB輻射參數的影響。研究實驗者已經進行相關的理論推導和程序開發。計算結果顯示,在適當的參數下,SSMB可以直接實現平均功率1kW以上的EUV輸出,這為SSMB的光源設計提供了指導。
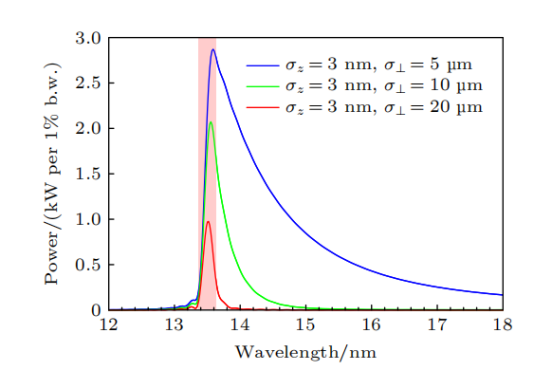
SSMB-EUV光源輻射能譜樣例
3、SSMB關鍵技術挑戰
要實現SSMB光源的真正技術可行性,需要掌握幾項核心技術。
1)激光調制器是SSMB與傳統儲存環之間最重要的區別
為實現SSMB,需要高激光功率、相位鎖定,并采用連續波或高占空比的調制激光以提高束流占空比和輻射光的平均功率。因此,SSMB的激光調制系統采用了光學增益腔。
2)長脈沖注入系統是實現高輻射功率所必需
由于SSMB的平均流強較高,約為1A,因此需要專門設計大電荷量、長脈沖(百納秒量級)注入束流。為了減少SSMB出光過程中的功率變化,希望其工作在流強基本恒定不變的top-up模式,同時也可降低對單次注入束流強度的要求。
3)直線感應加速器是實現SSMB束流能量補充的可行選擇之一
為了提高SSMB儲存環的束流占空比,需要采用連續激光,并對長脈沖電子束的能量補充提出不同于傳統儲存環的要求。此外,高精度磁鐵、高精度控制系統等也需要在現有的同步輻射光源的基礎上進一步發展。
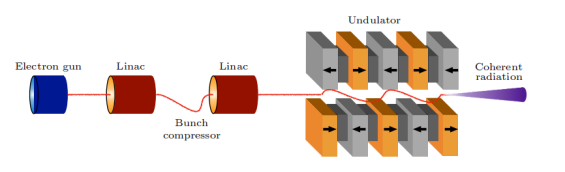
五、清華 SSMB-EUV 光源
自2017年以來,清華團隊開始研究面向EUV光刻的大功率SSMB-EUV光源。在原理驗證、束流動力學、物理設計和關鍵技術方面取得了重要進展。在束流動力學研究中,團隊解決了實現超短束所需關注的核心物理問題,完成了能夠穩定儲存納米級束的儲存環設計,并開展了集體效應等方面的研究。輻射理論和數值計算表明,SSMB可以實現千瓦級的EUV輸出。在關鍵技術方面,團隊搭建了光學腔平臺,研制出樣機,并合作研發了MHz感應加速單元等。
基于這些研究成果,團隊提出了SSMB-EUV光源方案。該方案采用微波電子槍和直線加速器產生束流,經展束環調整分布后注入主環,在主環中激光調制形成穩態微聚束。微聚束在輻射段被進一步壓縮,實現13.5nm EUV強相干發射,輸出功率達到千瓦量級。這一創新為EUV光源技術的發展提供了新的途徑。
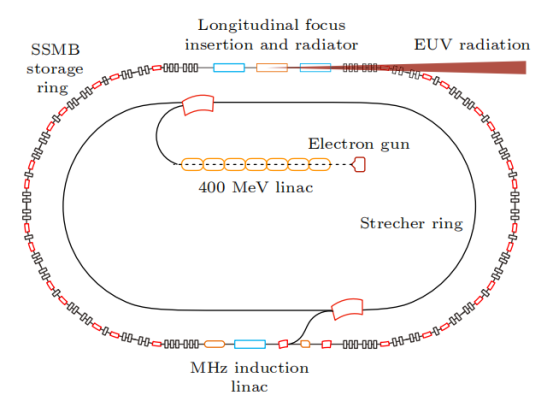
清華 SSMB-EUV 光源示意圖
下面簡要介紹各分系統的功能和實現方式:
1)直線注入器
直線注入器產生的能量約400MeV,它能在約10厘米間隔內提供數百個等電荷量的微脈沖束團,微脈沖束團的脈沖長度在百納秒量級,總電荷量也是百納庫量級,平均流強為1A。
2)展束環
多脈沖束團被注入到展束環中,通過優化微脈沖束團的能散和展束環的滑相因子,使微束團長度在展束環中被拉長,相鄰的束團流強分布首尾相連相互重疊,形成近似均勻流強的長度百納秒量級的準直流電子束,然后注入到SSMB儲存環中。
3)SSMB主環
被注入的束流被調制激光的勢阱俘獲(光學 micro-bucket),經過輻射阻尼及量子激發到達平衡,形成間隔為激光波長(約 )的微束團。SSMB主環的設計極小化了全局及局部滑相因子,從而控制全環縱向函數,使電子束實現極低的穩態縱向發射度和束團長度(十納米到數十納米)。儲存環的非線性動力學經過仔細優化,能實現足夠大的六維動力學孔徑,以保證束團能穩定且具有足夠壽命地儲存在光學 micro-bucket 中。
4)束團壓縮及輻射單元
對SSMB主環中的束團進行進一步壓縮,在輻射段實現長度約為3nm的微束團,從而產生波長為13.5nm的強相干EUV光。具體的壓縮方案包括縱向強聚焦、橫縱向耦合(廣義縱向強聚焦)等。輻射元件采用優化設計的波蕩器,能產生大功率窄帶寬的EUV光。
5)調制激光系統
采用窄線寬種子激光和高精細度光學增益腔,實現約1MW的平均存儲功率,滿足SSMB-EUV光源需求。
6)能量補充系統
采用MHz重頻的直線感應加速器,補償平均流強約為1A的束流平均功率數千瓦到十千瓦的輻射損失。
六、SSMB-EUV 光源對科學研究及芯片光刻潛在的變革性影響
目前全球唯一的 EUV ***供應商是荷蘭的 ASML 公司,其采用激光等離子體(LPP)的 EUV 光源。具體來說,ASML 通過一臺功率大于 20 kW 的 CO 氣體激光器轟擊液態錫形成等離子體,從而產生 13.5 nm 的 EUV 光。
通過不斷優化驅動激光功率、EUV 光轉化效率、收集效率以及控制系統,LPP-EUV 光源目前能夠在中間焦點處實現 350 W 左右的 EUV 光功率,該功率水平剛達到工業量產的門檻指標。產業界認為 LPP 光源未來可以達到的 EUV 功率最高為 500 W 左右,如果想要繼續將 EUV 光刻向 3 nm 以下工藝節點推進,LPP-EUV 光源的功率將遇到瓶頸。
由于基于等離子體輻射的 EUV 光源功率進一步突破困難,因此基于相對論電子束的各類加速器光源逐漸進入產業界的視野,如基于超導直線加速器技術的高重頻 FEL 以及 SSMB 等。
SSMB-EUV 光源用于 EUV 光刻具有以下特點和潛在優勢:
1、高平均功率
SSMB儲存環支持安裝多條EUV光束線,可同時作為光刻大功率照明光源及掩模、光學器件的檢測光源,還可以為EUV光刻膠的研究提供支撐
2、窄帶寬與高準直性
SSMB光源容易實現EUV光刻所需的小于2%的窄帶寬要求,并且波蕩器輻射集中于mrad的角度范圍內。窄帶寬以及高準直的特性可為基于SSMB的EUV光刻光學系統帶來創新性的設計,同時可以降低EUV光學反射鏡的工藝難度
3、高穩定性的連續波輸出
SSMB輸出的是連續波或準連續波輻射,可以避免輻射功率大幅漲落而引起的對芯片的損傷。儲存環光源的穩定性好,采用top-up運行模式的SSMB儲存環可使光源的長時間可用性得到進一步提升
4、輻射清潔
與LPP-EUV光源相比,波蕩器輻射的高真空環境對光刻的光學系統反射鏡不會產生污染,鏡子的使用壽命可以大大延長
5、可拓展性
SSMB原理上容易往更短波長拓展,為下一代采用波長6.x nm的Blue-X光刻技術留有可能
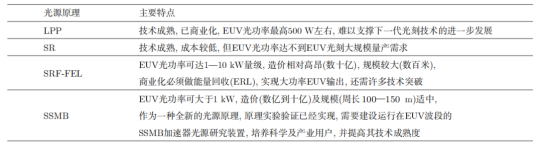
各類 EUV 光源特點
SSMB-EUV光源的成功研制將有望推動我國EUV光刻技術的跨越式進步。與此同時,SSMB加速器光源能夠產生高平均功率、窄線寬的從太赫茲到軟X射線的相干輻射,并且其時間結構可調范圍廣泛,這將對物理、化學、能源、環境等學科的基礎研究與應用研究帶來全新的研究工具和手段。
計算機視覺的目標是設計能識別和處理視覺信號的程序,使計算機"看"得更好。典型任務有圖像分類、物體檢測、分割、追蹤和姿態估計。ImageNet數據集包含超過2萬個物體類別,用于圖像分類。MS-COCO數據集包含檢測、分割等任務。
在計算機中,視覺信號以像素密集采樣的方式來存儲光強度。然而,像素并不代表語義信息,因此這種存儲形式與人類理解之間存在巨大的差距
華為盤古大模型介紹
AI正在逐漸深入到企業的核心生產系統中,并發揮出更大的價值。預計到2025年,企業采用AI的比例將達到86%,而當前這一數字僅為4%。在眾多的AI項目中,有600+已經得到實踐,其中30%已經進入了生產系統。然而,AI在各行各業的應用仍然面臨諸多挑戰,如場景碎片化、作坊式開發方式導致規模化復制困難、行業知識與AI技術結合難度大、以及人們對AI模型安全性、隱私和潛在攻擊的擔憂。

近年來,云計算市場迅速發展,客戶需求從資源需求向智能和業務方案需求轉變。市場前景廣闊,但業務數量眾多、場景復雜也帶來挑戰。隨著市場的成熟,定制化解決方案相較于統一方案更具優勢,中小型供應商也具有了競爭力。然而,在保證業務規模的同時,如何控制成本、提高效率和質量成為核心難題。
另一方面,傳統行業也在積極利用AI技術解決問題,這需要算法具備通用性。然而,目前AI開發主要采取的是針對每個場景獨立開發的模式,缺乏通用知識的積累。這也導致低水平開發者難以掌握規范流程和優化技巧,進而影響模型的效果。
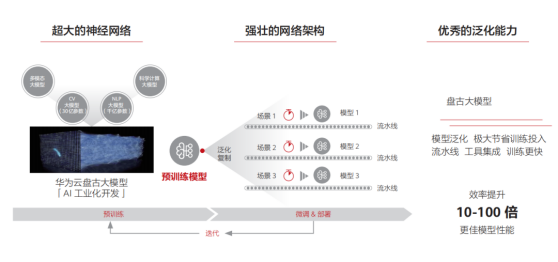
為解決AI算法落地面臨的碎片化問題,預訓練大模型應運而生。這種模型通過無監督學習從大規模數據中提取通用知識,并將其儲存在參數量巨大的模型中。在遇到具體任務時,只需要調用統一的流程來應用這些知識,并結合領域經驗來解決具體問題。近年來,預訓練模型的研究和應用持續爆發,有望在AI領域發揮統領作用。然而,要實現預訓練模型的商業規模應用,還有一段路要走,這需要技術和商業模式雙輪驅動。我們設想大模型可以成為AI的操作系統,管理硬件資源,支撐算法應用,從而使AI開發更加規范和普及。
一、大模型 是 AI 發展的必然趨勢
1、人工智能發展趨勢的總體研判
人工智能存在著邏輯演繹、歸納統計和類腦計算三大流派,各具優勢并持續爭議。類腦計算目標遠大,但缺乏生命科學支撐。歸納演繹方式與人類相似,可解釋性強,是前兩次繁榮的主角。隨著對人工智能困難性的理解,邏輯方法的局限性被放大,統計學習在第三次繁榮期占據主導地位。深度學習進一步推崇“拋棄先驗,擁抱數據”的思想。
深度學習是當代產物,得益于大數據和大算力的支持,其核心是深度神經網絡,通過通用骨干網絡與特定目的頭部網絡的配合,實現了對各個子領域的統一解決問題。然而,其本質仍是統計學習的框架,缺乏人類基于知識的推斷方式,導致通用性受限,且開發成本高昂,難以惠及細分行業。
預訓練大模型是深度學習時代的集大成者,分為上游(模型預訓練)和下游(模型微調)兩個階段,旨在解決上述問題。雖然預訓練大模型不直接導向人工智能,但兩個重要判斷對其未來發展有著深遠影響。
1)在下一個劃時代的計算模型出現以前,大模型將是人工智能領域最有效的通用范式, 并將產生巨大的商業價值
根據實際操作經驗,預訓練大模型加持下的人工智能算法(包括計算機視覺和自然語言處理等領域)相比于普通開發者從頭搭建的算法,精度顯著提高、數據和計算成本明顯降低,并且開發難度大大降低。以計算機視覺為例:在以前,要在100張圖像上訓練基礎物體檢測算法,需要8塊GPU運行5個小時,一名開發者需要工作1個星期才能完成。然而,有了預訓練模型的支持,現在只需要1塊GPU運行2個小時,而且幾乎不需要人力干預。綜合人力和算力開銷的考慮,上述案例的開發成本降低90%甚至99%。
2)對大模型的研究,將有可能啟發下一個通用計算模型
在2011年之前,統計學習方法盛行,詞袋模型的參數達到了10億量級。然而,2012年只有6000萬參數的深度網絡打敗了詞袋模型,推動了計算機視覺領域的發展。深度網絡相比詞袋模型,在特征提取效率上取得了突破性進展。我們預測,隨著大模型不斷發展,結合知識后可能會出現新的突破,推動統計學習的進化。
目前看來,預訓練大模型代表了統計學習的最高成就,也是當前人工智能的最強武器。在新技術出現之前,預訓練大模型將繼續引領人工智能研發。中美兩國已經在大模型的研發和應用方面展開了競爭。
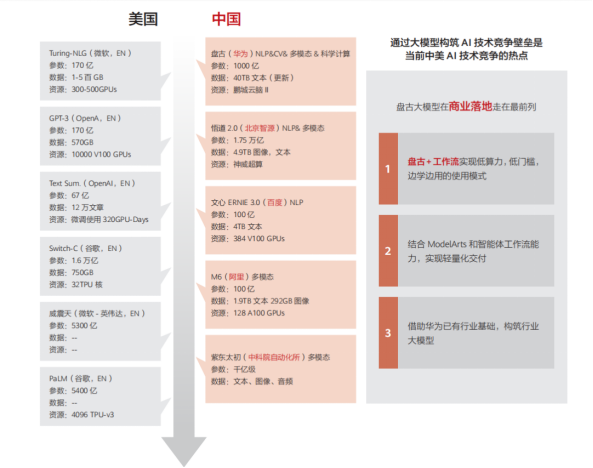
二、盤古大模型家族介紹
華為云團隊在2020年啟動大模型研發項目,并于2021年4月首次公開了名為“盤古預訓練大模型”的成果。盤古大模型集合了華為在AI領域的多項研究成果,并深度結合昇騰芯片、MindSpore語言和ModelArts平臺。下面將簡要介紹盤古大模型的組成部分,并剖析構建大模型的關鍵技術。
1、視覺大模型
計算機視覺的目標是設計能夠識別和處理視覺信號的程序,從而使計算機能夠更好地“看”。其典型任務包括圖像分類、物體檢測、分割、追蹤和姿態估計。ImageNet數據集包含超過2萬個物體類別,用于圖像分類任務,而MS-COCO數據集則包含檢測和分割等任務。

在計算機中,視覺信號以像素密集采樣的方式來存儲光強度。然而,像素并不代表語義信息,因此這種存儲形式與人類理解之間存在巨大的差距,這被稱為語義鴻溝,是計算機視覺的核心問題。進一步分析圖像信號的特點,發現以下幾點:
內容較復雜
圖像的基本組成單元是像素,但單個像素通常不足以傳達語義。
信息密度低
圖像信號雖然能客觀地反映出事物的特征,但其中相當一部分數據用于表達圖像中的低頻區域(如天空)或無明確語義的高頻區域(如隨機噪聲)。
域豐富多變
圖像信號受到各種域的影響,這種影響通常具有全局性質,難以與語義區分開來。例如,同樣的語義內容在不同的光照條件下會呈現出完全不同的表征。同時,相同的物體以不同的尺寸、視角和姿態出現時,會在像素層面產生巨大差異,給視覺識別算法帶來困難。

基于此使用了卷積網絡和Transformer等主流視覺模型架構。自動機器學習算法支持不同規模模型,最大規模近30億參數,最小僅數十萬,可適配不同任務。
訓練數據主要來自互聯網,不含準確語義標簽。采用自監督學習方法,通過設計代理任務讓模型在無標簽數據上擬合分布。在對比學習基礎上改進了自監督算法,引入等級化語義相似度挑選更優質的正樣本,并使用混合數據增強技術減少噪聲影響。還擴大了正樣本數目,避免負樣本對訓練的影響。
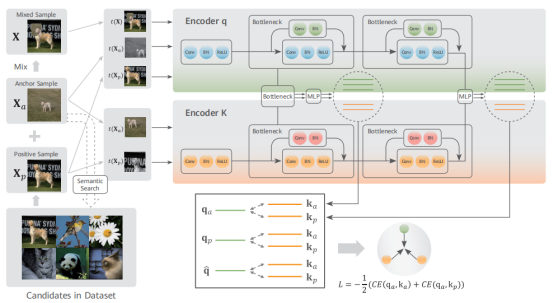
基于等級化語義聚集的對比度自監督學習
2、語音語義大模型
自然語言是人類存儲和交換信息的重要方式,通過文字和語音兩種形式實現。因此,語音語義處理分為自然語言處理和語音處理兩個領域,目標都是讓機器像人類一樣理解和使用語言。自然語言處理和語音處理都包含理解和生成兩個方面,但處理的信號類型不同,一個是文本,一個是音頻。雖然文本和音頻大多數情況下高度相關,但也有一些獨特的表達情況。

語音語義處理的核心是將文字和聲音轉化為機器可處理的格式。在深度學習之前,主要通過特征工程實現,但這種方法依賴于專家知識且難以擴展。隨著深度學習的發展,自動學習語言的向量表示逐漸成為主流。編碼器-解碼器框架被用于處理文字和音頻信號,其中編碼器將語言映射到低維向量,解碼器將低維向量映射回語言。設計合適的網絡結構和學會參數是深度學習中的關鍵技術問題。在小型模型時代,CNN和RNN技術占主導地位,而LSTM模型因處理遠距離依賴的能力而備受關注。然而,RNN的優化不穩定且難以并行計算,因此限制了構建大型語言模型的規模。
2017年,自注意力Transformer模塊被提出,結合已有方法優點,在速度和表達能力上具有巨大優勢,迅速在自然語言處理和語音識別領域得到應用。隨著大規模語料庫的出現和自監督學習方法的成熟,2018年出現了預訓練模型BERT并進入大模型時代。現在,預訓練大模型憑借出色的泛化能力和基于提示的微調技術,簡化各種下游任務的實現方式,推動自然語言處理和語音識別領域的巨大發展,成為語音語義處理領域的最佳方案。
1)數據收集
自然語言處理和語音識別類似于計算機視覺,也需要大規模數據集作為基礎。爬取40TB原始網頁數據,通過解析和清洗,使用正則表達式等方法過濾噪聲、去重和規范長度,最終得到約647GB文本數據。語音部分,爬取超過7萬小時普通話音頻數據,轉換為音頻文件,共計約11TB,視頻來源多樣。

2)預訓練方法
對于語義部分,使用基于Transformer的編碼-解碼器神經網絡模型。編碼器采用雙向自注意力機制來理解文本,解碼器則通過單向自注意力逐詞生成文本。提出多任務融合策略來讓模型從海量文本數據中獲取語言知識。遮罩語言模型用于訓練理解能力,即對原文進行挖空并預測缺失的部分。回歸語言模型用于訓練生成能力,給定上文,預測下文。為提高零樣本推理能力,收集了100+下游任務數據并加入預訓練中。
對于語音部分,解碼器與文本解碼器相似,但音頻編碼器采用了卷積與Transformer結合的網絡結構。底層卷積神經網絡提取局部信息,上層Transfomer提取全局信息。使用對比學習策略,將音頻中的片段挖空并與隨機負例進行比較,以找出正確的被挖掉的片段。
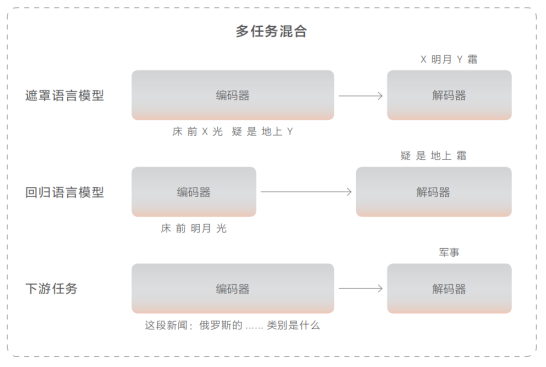
3、多模態大模型
多模態任務不同于計算機視覺或自然語言處理等單一模態任務,需要在海量多模態數據上進行預訓練,并將預訓練知識遷移到下游各項任務中,以提升下游任務的精度。典型的多模態任務包括跨模態檢索(如以文搜圖或以圖搜文)、視覺問答(通過圖像內部信息回答問題)和視覺定位(在圖像中定位描述的對應區域)。

1)數據收集
與視覺和語音語義大模型一樣,多模態大模型的訓練也需要在大量高質量數據上進行。采用了業界常用的做法,從互聯網上爬取大量圖文數據,通過過濾算法消除不符合要求的數據,最終得到高質量的圖文配對數據,用于多模態大模型的預訓練。具體來說,設定了大量文本關鍵字,在搜索引擎上獲取與之匹配的圖像,并將圖像對應的文本存儲下來,形成圖文配對數據池。在去掉重復數據后,進一步篩選出分辨率高、文本長度適中的數據。接著,使用已有的多模態預訓練模型對配對數據的相似度進行判斷,如果相似度太低,就丟棄文本描述并使用圖像自動描述算法來生成文本數據。經過上述預處理過程,最終得到了約3.5億高質量的圖文配對數據,占據約60TB存儲空間。

2)預訓練方法
多模態大模型預訓練的關鍵在于不同模態數據的高效交互和融合。當前主流的多模態大模型架構分為單塔架構和雙塔架構。單塔架構使用一個深度神經網絡(一般是 Transformer)實現圖像和文本之間的交互融合,屬于信息前融合方案;而雙塔架構使用不同的神經網絡來完成不同模態的信息抽取,并在最后一層進行信息交互和融合,屬于信息后融合方案。
盤古大模型采用雙塔架構,具有模型獨立性強、訓練效率高等優勢。實現方式簡單,使用相應網絡抽取圖像和文本特征,然后將一個批次的圖像和文本特征送入判別器,在對比損失函數的作用下,使得配對的跨模態特征聚集在一起,而不配對跨模態特征被拉遠。在大數據集上充分迭代后,模型就能學會將圖像和文本對齊到同一空間。此時,圖像和文本的編碼器可以獨立用于各自下游任務,或協同用于跨模態理解類下游任務。
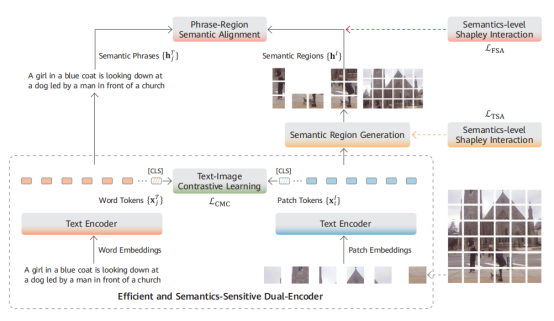
4、科學計算大模型
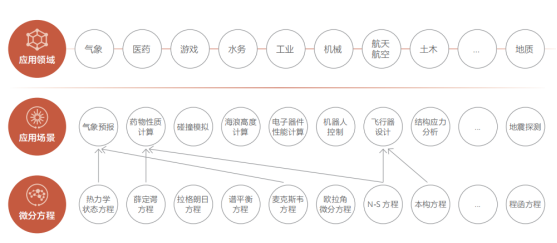
視覺大模型、自然語言大模型和多模態大模型主要用于解決通用的人工智能問題,如音頻分析、圖像識別和語義理解等。人類能夠標注大規模數據集供深度神經網絡學習這些問題。然而,在自然科學領域中,還存在許多人類無法解決的問題,比如湍流模擬、天氣預報和大形變應力建模等。這些問題具有廣泛的應用前景,如下所示:
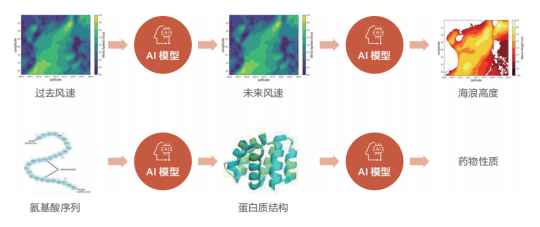
近年來,隨著人工智能技術的迅速發展,業界出現了AI+科學計算方法,即使用嵌入科學方程的深度神經網絡,直接從觀測和仿真數據中學習問題蘊含的規律,以分析復雜的科學數據并了解科學過程的內部機理。
從預訓練大模型的角度看,科學計算大模型與其他大模型有許多相似之處。都依賴于大規模數據集、需要設計具有大量參數的神經網絡、經歷復雜的優化過程,并將知識存儲在網絡參數中。接下來,將簡單描述科學計算的獨特之處。
1)數據收集
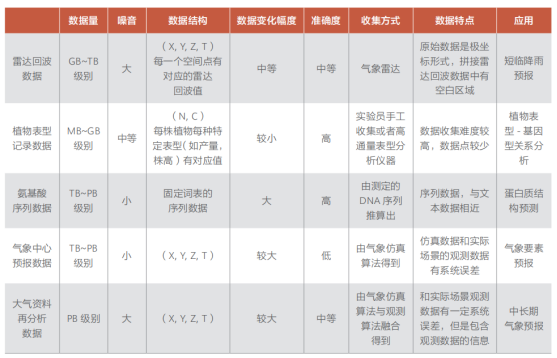
在AI+科學計算場景中,數據分為觀測和仿真兩類。觀測數據由工具產生,如游標卡尺等,仿真數據由算法產生。這些數據、融合數據和機理知識都可以作為AI模型的學習對象。不同場景的觀測數據差異大,需使用專業儀器與實驗系統收集,如蛋白質結構預測中的X射線衍射和核磁共振等。仿真數據來自算法輸出,蘊含豐富的數學物理信息。同一個問題使用不同算法可產生不同仿真數據,精度受限。相對于觀測數據,仿真數據通常更大,可有效擴充數據。在某些場景中,觀測和仿真數據結合機理知識生成融合數據,如氣象再分析數據。
2)模型構建
根據輸入數據的性質,算法會選擇合適的基礎模型進行海浪預測等科學計算任務。對于二維球面數據,適合使用二維網絡模型;而三維數據則需使用三維網絡模型。這兩種模型可借鑒計算機視覺領域的卷積神經網絡和視覺 Transformer 模型進行預訓練。同時,科學計算的特點在于利用人類經驗形成約束性質的偏微分方程組,將其嵌入神經網絡中可增強模型的魯棒性并降低擬合難度和不穩定。
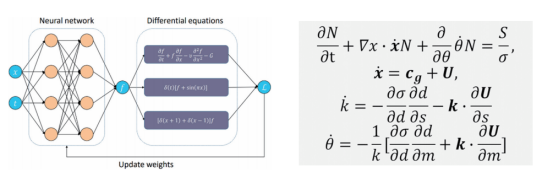
左圖為嵌入偏微分方程的神經網絡示意圖,右圖為海浪預報問題使用的偏微分方程
3)案例和效果展示
下面我們來探討一個典型的科學計算案例,即全球海浪高度預測系統。海浪預測的輸入和輸出都是經緯度網格點上的氣象要素數據,數據形式與視頻數據相似。但海浪數據是浮點數,不同于視頻數據的像素值。此外,海浪數據還滿足球坐標條件下的一系列不變性,因此需要選定滿足特定不變性的CNN或者Transformer架構。
盤古海浪預測模型的主體是考慮了旋轉不變性的視覺Transformer架構,參數量約為五億。模型的損失函數由兩部分組成:實際數據上的預測誤差和海浪預測本身需要滿足的偏微分方程。通過使用全球近10年的實時海浪高度數據進行訓練,模型在驗證集上預測的平均誤差小于5cm,與傳統預測方法相當,完全可以滿足實際應用需求。更重要的是,AI算法的預測時間較傳統方法大幅減少:在單張華為昇騰芯片上,1s之內即可得到全球海浪高度預測,1分鐘內能夠完成超過100次海浪預測任務,推理效率較傳統方法提升了4-5個數量級。
使用AI算法可以迅速得到不同可能的風速條件下的海浪高度,進行實時預測和未來情況模擬,對漁業養殖、災害防控等場景具有極大的價值。
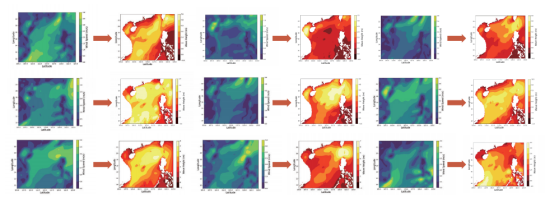
使用昇騰 AI 芯片,AI 模型可以在一秒內給出成百上千組“隨機”風速分布下的海浪分布
AI芯片:群賢畢至,花落誰家?
最近,由ChatGPT引領的AI熱潮再次興起,國內外科技公司紛紛投入到大語言模型和生成式AI的研發中,展開一場對計算能力的競賽。GPT背后的核心算法是谷歌在2017年提出的Transformer,這種算法通過采用自我監督預訓練的方式,近乎無需人工干預,因此需要大量訓練數據,再加上少量的有監督微調和強化學習相結合。隨著更為復雜和多元化模型的涌現,高算力的AI芯片將充分受益于這種發展趨勢。然而,如果這些技術在消費端的應用僅僅停留在表面,那么其意義并不大。
一、英偉達的兩大護城河:高算力芯片和高粘性 CUDA 軟件生態
根據AI論文中不同芯片的引用數據,英偉達的芯片在AI研究領域廣受歡迎。其產品的使用率是ASIC的131倍,高出Graphcore、Habana、Cerebras、SambaNova和寒武紀五家公司總和的90倍,是谷歌TPU的78倍,是FPGA的23倍。通常,在人工智能領域,新模型的推出都會在相關論文中進行發表,以便于信息交流與學術合作。英偉達在人工智能相關論文中的引用數量遙遙領先,這反映新算法需要采用英偉達GPU的必要性,以及其在學術界長期以來的重要地位和影響力。
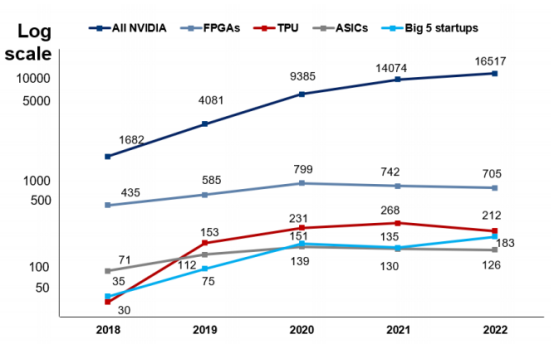
英偉達芯片在 AI 論文中的引用數量遙遙領先
英偉達一直致力于開發高性能計算芯片的迭代,不斷在產品工藝、計算能力和存儲帶寬等方面進行創新。針對高性能計算和深度學習應用場景,英偉達基于其芯片架構,推出一系列GPU產品,以提升張量核心和稀疏矩陣計算等功能。2023年,英偉達不滿足于單GPU的更新換代,推出結合Grace CPU與Hopper GPU的GH200超級芯片,實現高達900GB/s的總帶寬,加速大規模AI和HPC應用計算。在SIGGRAPH上,英偉達的AI芯片再次迎來升級,推出全球首次采用HBM3e內存的GH200超級芯片。該芯片的帶寬高達每秒5TB,并提供141GB的內存容量,適用于復雜的生成式人工智能工作負載,如大型語言模型、推薦系統和矢量數據庫等。
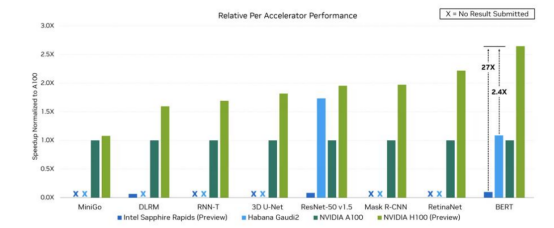
英偉達 H100 與部分同業產品在運行不同 AI 負載時表現
二、MI300A 和 GH200:CPU+GPU AI 芯片架構仿生人腦結構
MI300系列是AMD旗下的GPU產品,包括兩款產品:MI300X和MI300A。MI300X是一款純GPU產品,由12個chiplets(8個GPU+4個IO+Cache)組成,與英偉達的GPU H100相媲美。而MI300A是一款CPU+GPU產品,由13個chiplets(6個GPU+3個CPU+4個IO+Cache)組成,采用APU架構(Zen 4 CPU + CNDA 3 GPU),與英偉達的異構CPU+GPU芯片GH200競爭。
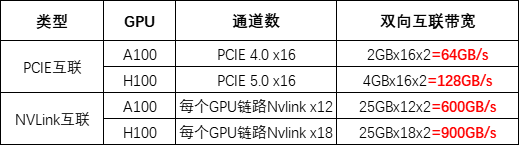
在參數上,MI300系列有許多值得關注的亮點。首先,MI300X的192GB HBM3內存領先于英偉達H100雙卡NVL的188GB HBM3,更遠超過H100 PCIe和SMX的80GB HBM3,而MI300A的128GB HBM3內存也具有競爭力。其次,MI300X的晶體管數量為1530億,MI300A的晶體管數量為1460億,與H100的800億相比具有明顯優勢。此外,內存帶寬5.2TB/s與英偉達H100的2-7.2TB/s相近,Infinity Fabric互聯帶寬的896GB/s與NVLink的900GB/s相差無幾,但比H100高2.4X的HBM密度以及1.6X HBM帶寬則展示了AMD在GPU技術方面的優勢。AMD在2023 CES大會上首次推出CPU+GPU的MI300,后改稱MI300A。作為MI系列的第一款CPU+GPU異構產品,CPU+GPU架構已成為AI芯片的趨勢。
在AI應用中,GPU算力較高,適用于并行計算,在視頻處理、圖像渲染等方面具有優勢,但并不是所有工作負載都只需要單純的GPU處理,還需要由CPU進行控制調用,發布指令。因此,在CPU+GPU架構中,CPU可以負責控制和發出指令,指示GPU處理數據和完成運算(如矩陣運算)。值得一提的是,MI300A中的CPU采用的是x86架構,而GH200中的CPU采用的是ARM架構。兩種架構各有優勢,一般來說,ARM架構主要應用于移動端,因此相比x86能耗較低,這一點在AI和數據中心的應用中都會受到青睞。
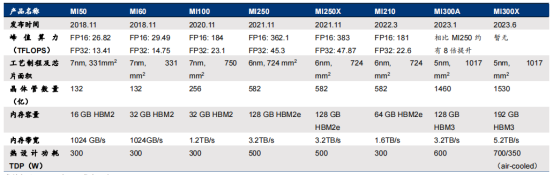
AMD Instinct MI 系列 GPU 發展歷程
三、谷歌 TPU:少數能與英偉達高算力 GPU 匹敵的 AI 芯片
谷歌的TPU(Tensor Processing Unit)是云廠商自研AI芯片的典型例子之一,從2017年開始已具備訓練和推理能力。谷歌TPU是少數能夠與英偉達高算力GPU相匹敵的AI芯片。在架構與性能參數上不斷迭代,第一代TPU從2015年開始被使用于谷歌云計算數據中心的機器學習應用中,當時僅面向推理端,但從2017年推出第二代開始,TPU已同時擁有訓練和推理能力。第三代TPU于2018年發布,旨在提高性能和能效以滿足不斷增長的機器學習任務需求。第四代TPU于2021年發布,而專為中大規模訓練和推理而構建的TPUv5e于2023年發布。與TPUv4相比,TPUv5e可為大語言模型提供高達2倍的訓練性能和2.5倍的推理性能,并能節約一半以上的成本。谷歌目前僅通過谷歌云服務平臺向外部客戶提供TPU的算力租賃服務,而未有將其作為硬件產品出售。
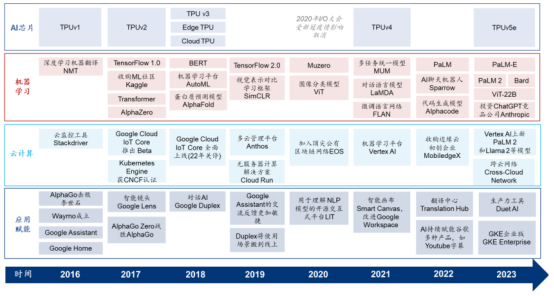
2016 年至今谷歌云計算、AI 芯片、機器學習及 AI 應用賦能進程梳理
四、亞馬遜 AWS:Trainium & Inferentia,訓練推理雙管齊下
AWS于2018年和2020年分別發布AI推理芯片Inferentia和訓練芯片Trainium,隨后在2023年推出第二代Inferentia,并在AWS云上提供給客戶使用。亞馬遜在2015年收購以色列芯片設計公司AnnapumaLabs,從而開始自研AI芯片的旅程,而第一代Inferentia正是源自該公司的技術。AWS的AI芯片搭配AWSNeuron開發軟件包,其中包含可用于兼容TensorFlow和PyTorch的編譯器。2023年5月,亞馬遜表示計劃將其自研的大語言模型“AlexaTeacherModel”(AlexaTM)接入智能語音助手Alexa。Alexa此前已經接入亞馬遜Echo智能音箱等智能硬件設備,并使用Inferentia進行推理。
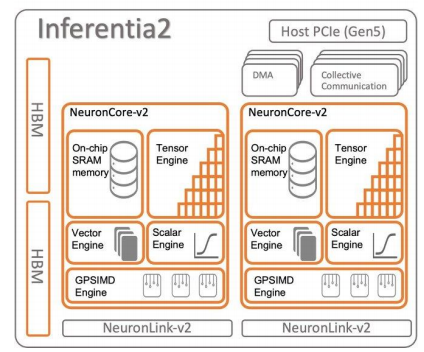
AWS Inferentia2 芯片架構
Trainium是一款在云端進行訓練的AI芯片,其表現相較于A100更為優秀,同時也具有更高的性價比。Trainium是AWS專為超過1000億參數規模的大模型打造的AI芯片,于2020年發布,目前仍處于第一代。每個Trainium配備了容量為32GB、帶寬為820GB/s的HBM2e,提供了FP16算力190TFLOPS(英偉達A100的FP16算力為624TFLOPS)和FP32算力47.5TFLOPS,并支持包括可配置的FP8在內的多種數據精度。Trainium使用的互聯技術是AWS的NeuronLink(超高速非阻塞互連技術,v2代),互聯速度達到了768GB/s,相比之下,NVLink4.0的互聯速度為900GB/s。根據AWS官網的信息,Trainium實例的內存容量比英偉達A100實例高出60%,互聯帶寬高出2倍。使用130個Trainium實例訓練GPT-3只需要2周,而根據英偉達與微軟的論文《Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM》,使用1024顆A100進行訓練需要34天。2022年,AWS推出的Trn1AI平臺可以部署最多16個Trainium,在AWS云上進行AI模型訓練。相較于同類型的AmazonEC2實例,以Trainium為支撐的Trn1實例可以節約50%的訓練成本,而在亞馬遜廣告模型訓練中,這一成本節約甚至高達70%。
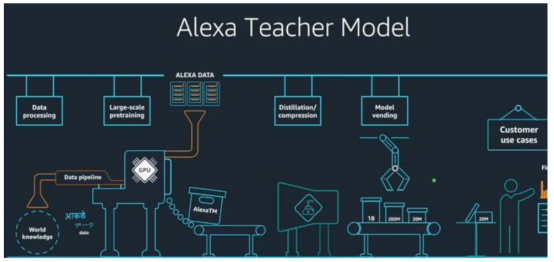
AWS 的 in-house 大語言模型 Alexa Teacher Model
Inferentia 推理卡已經迭代兩代,并被用于亞馬遜硬件終端的 AI 服務。2018 年推出的第一代 Inferentia 配備了 8 GB 帶寬為 50GB/s 的 DDR4 內存,而 2023 年 4 月正式推出的第二代 Inferentia 2 則配備了 32 GB 帶寬為 820GB/s 的 HBM2e 內存,FP16 算力達到 190 TFLOPS,相比一代 Inferentia(64 TFLOPS)提高2 倍,主要針對高性能深度學習推理應用程序進行設計。
根據亞馬遜官網的信息,相比第一代 Inferentia,第二代的延遲降低十分之一,吞吐量提高四倍。由于大規模終端設備 AI 模型對云端推理能力要求較高,而自研 AI 芯片等信息基礎設施和自身應用可以進行針對性的相互適配與優化,Amazon 人工智能助手 Alexa 使用以 Inferentia 為支撐的 Inf 實例進行推理負載。
除與 AWS 生態捆綁外,客戶還可以通過開發工具包 AWS Neuron,以及使用 Amazon Sagemaker(AWS 機器學習平臺)、Amazon Elastic Container Service(ECS,AWS 容器托管方案)、Amazon Elastic Kubernetes Service(EKS)等服務來快速開始使用 Inf 和 Trn 實例,并分別使用底層 Inferentia 和 Trainium 芯片能力。目前 AWS 上使用 Inferentia 承擔推理工作負載的客戶包括 Airbnb(愛彼迎,房屋租賃平臺)、Snap(圖片類社交媒體平臺)、Sprinklr(SCRM 社交媒體營銷公司)、Money Forward(金融科技公司)和 Finch Computing(AI 初創公司)等;而使用 Inferentia2 的客戶則包括 Hugging Face(機器學習公司)、Qualtrics(自動化管理軟件公司)和 Finch Computing(亦為 Inf1 客戶)等。
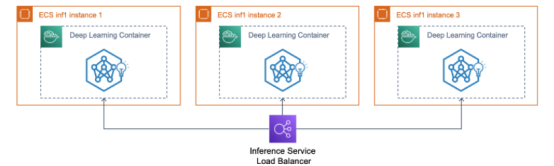
使用 inf1 實例將推理服務部署到 AWS ECS 容器托管集群
五、Meta:首個自研推理端芯片 MTIA 將于 2025 年問世
Meta 在 2023 年 5 月發布自主研發的 AI 芯片 MTIA,該芯片主要針對推理工作,從 2020 年開始設計,預計于 2025 年正式推出,采用臺積電 7nm 制程。MTIAv1 是針對推理端的產品,使用最高 128GB 的 LPDDR5 內存,采用 RISC-V 架構,并配合基于 PyTorch 的軟件包。與其他云廠商自主研發的 AI 芯片類似,MTIA 是針對公司內部應用和模型量身定制的 ASIC,尤其是針對 Meta 旗下產品所需的 feed(例如 Instagram 的用戶瀏覽界面)貼文推薦算法進行了優化。與通用芯片相比,MTIA 可以實現降本增效。
Meta 的超級計算機由約 16,000 片英偉達 A100 GPU 構成,已被用于訓練 LLaMA 模型。目前,Meta 沒有推出專用于訓練階段的芯片,而是使用基于英偉達 A100 GPU 的內部生產集群進行訓練。Meta 的 AI 超級計算機 RSC(Research Super Cluster)由約 16,000 片英偉達 A100 GPU 構成(2000 臺英偉達 DGX A100),通過 NVIDIA Quantum InfiniBand 16 Tb/s 網絡結構進行連接。Meta 表示,其使用 RSC(除此外還包括由 A100 GPU 組成的內部生產集群)來訓練其在 2023 年 2 月發布的 70-650 億參數的開源大模型 LLaMA。其中,650 億參數的 LLaMA 模型在 2048 片英偉達 A100 GPU 上花費 21 天完成預訓練。2023 年 7 月,Meta 發布了免費可商用的 LLaMA2 版本,與第一代相比,LLaMA2 作為升級版本包括 70 億、130 億和 700 億三個參數版本,使用了 1.4 倍容量的數據集,并采用了分組查詢注意力機制,同樣使用 RSC 工作負載進行預訓練。據 Meta 評估,多項測評結果顯示 LLaMA 2 在推理、精通性、編碼和知識測試等諸多外部基準測試中均優于其他開源語言模型。
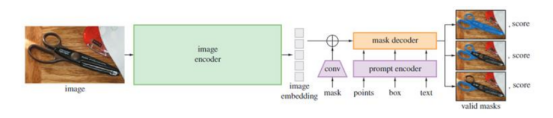
SAM 模型總覽示意圖
英偉達顯卡與華為對比
當談到千卡集群GPT3模型訓練性能時,華為當代Atlas集群以其卓越的表現領先于NV DGXA800集群1.2倍。華為當代Atlas集群作為一種先進的計算平臺,以其出色的計算能力和高效的數據處理能力而聞名,為大規模深度學習模型的訓練任務提供了有力的支持。
華為當代Atlas集群的卓越性能源于其先進的硬件設計和優化的軟件架構。該集群采用了高性能的GPU加速器和高速互聯網絡,這使得數據傳輸和計算速度得以顯著提升。這種卓越的硬件設計與華為自主研發的優化算法和分布式訓練框架相結合,進一步提升了模型訓練的效率。
與NV DGXA800集群相比,華為當代Atlas集群在千卡集群GPT3模型訓練性能上具有明顯的優勢。使用華為當代Atlas集群進行訓練任務,能夠以更快的速度完成模型訓練,從而提高工作效率。這種領先性能的差距不僅體現在訓練時間上,還可以在模型的收斂速度和訓練結果的質量上得到體現。
華為當代Atlas集群的領先性能使其成為深度學習研究人員和工程師的首選。無論是進行大規模數據訓練還是進行復雜模型的訓練任務,華為當代Atlas集群都能夠提供卓越的性能和可靠的支持,幫助用戶更快地實現預期的訓練目標。

藍海大腦大模型訓練平臺
藍海大腦大模型訓練平臺提供強大的算力支持,包括基于開放加速模組高速互聯的AI加速器。配置高速內存且支持全互聯拓撲,滿足大模型訓練中張量并行的通信需求。支持高性能I/O擴展,同時可以擴展至萬卡AI集群,滿足大模型流水線和數據并行的通信需求。強大的液冷系統熱插拔及智能電源管理技術,當BMC收到PSU故障或錯誤警告(如斷電、電涌,過熱),自動強制系統的CPU進入ULFM(超低頻模式,以實現最低功耗)。致力于通過“低碳節能”為客戶提供環保綠色的高性能計算解決方案。主要應用于深度學習、學術教育、生物醫藥、地球勘探、氣象海洋、超算中心、AI及大數據等領域。
一、為什么需要大模型?
1、模型效果更優
大模型在各場景上的效果均優于普通模型
2、創造能力更強
大模型能夠進行內容生成(AIGC),助力內容規模化生產
3、靈活定制場景
通過舉例子的方式,定制大模型海量的應用場景
4、標注數據更少
通過學習少量行業數據,大模型就能夠應對特定業務場景的需求
二、平臺特點
1、異構計算資源調度
一種基于通用服務器和專用硬件的綜合解決方案,用于調度和管理多種異構計算資源,包括CPU、GPU等。通過強大的虛擬化管理功能,能夠輕松部署底層計算資源,并高效運行各種模型。同時充分發揮不同異構資源的硬件加速能力,以加快模型的運行速度和生成速度。
2、穩定可靠的數據存儲
支持多存儲類型協議,包括塊、文件和對象存儲服務。將存儲資源池化實現模型和生成數據的自由流通,提高數據的利用率。同時采用多副本、多級故障域和故障自恢復等數據保護機制,確保模型和數據的安全穩定運行。
3、高性能分布式網絡
提供算力資源的網絡和存儲,并通過分布式網絡機制進行轉發,透傳物理網絡性能,顯著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用嚴格的權限管理機制,確保模型倉庫的安全性。在數據存儲方面,提供私有化部署和數據磁盤加密等措施,保證數據的安全可控性。同時,在模型分發和運行過程中,提供全面的賬號認證和日志審計功能,全方位保障模型和數據的安全性。
三、常用配置
1、處理器CPU:
Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
AMD EPYC? 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
AMD EPYC? 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
2、顯卡GPU:
NVIDIA L40S GPU 48GB
NVIDIA NVLink-A100-SXM640GB
NVIDIA HGX A800 80GB
NVIDIA Tesla H800 80GB HBM2
NVIDIA A800-80GB-400Wx8-NvlinkSW
審核編輯 黃宇
-
芯片
+關注
關注
456文章
51166瀏覽量
427206 -
amd
+關注
關注
25文章
5496瀏覽量
134629 -
華為
+關注
關注
216文章
34531瀏覽量
252984 -
NVIDIA
+關注
關注
14文章
5076瀏覽量
103714 -
AI
+關注
關注
87文章
31511瀏覽量
270306
發布評論請先 登錄
相關推薦

英偉達加速Rubin平臺AI芯片推出,SK海力士提前交付HBM4存儲器
AMD發布英偉達競品AI芯片,預期市場規模將大幅增長
英偉達Blackwell可支持10萬億參數模型AI訓練,實時大語言模型推理
英偉達醞釀新芯片,AI PC市場競爭升溫
英偉達:NVIDIA目標不是AI芯片,而是AI工廠





 工商網監
工商網監
評論