 TCP相關的內核參數總結
TCP相關的內核參數總結
在Linux上做網絡應用的性能優化時,一般都會對TCP相關的內核參數進行調節,特別是和緩沖、隊列有關的參數。很多文章會告訴你需要修改哪些參數,但我們經常是知其然而不知其所以然,每次照抄過來后,可能很快就忘記或混淆了它們的含義。
下面我以server端為視角,從 連接建立、 數據包接收 和 數據包發送 這3條路徑對參數進行歸類梳理。
一、連接建立
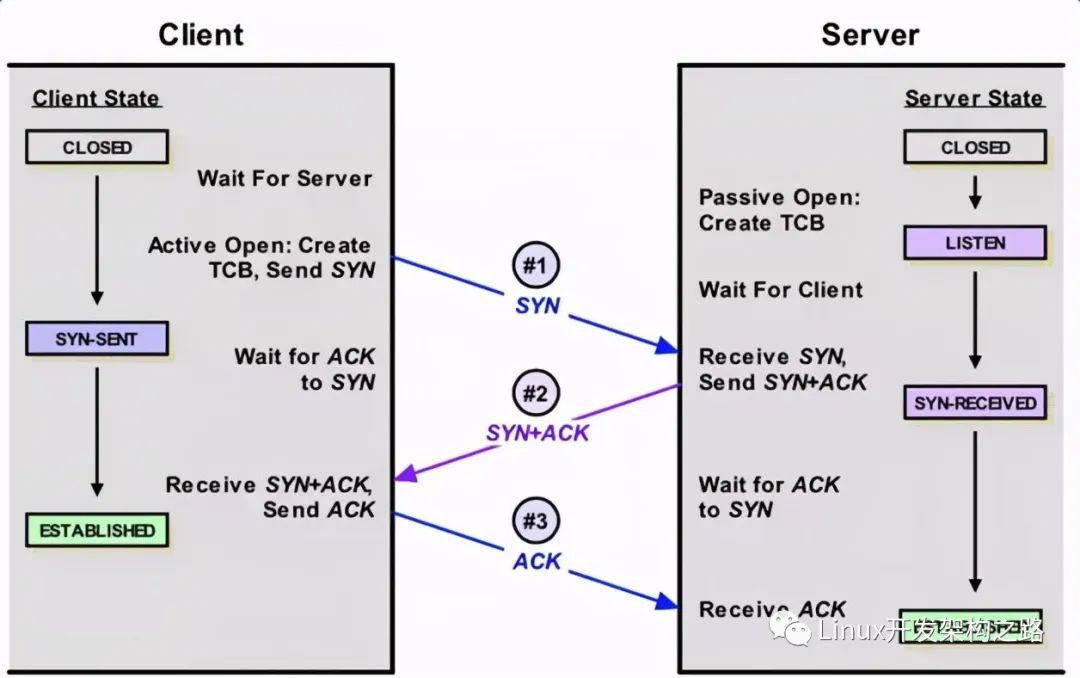
簡單看下連接的建立過程,客戶端向server發送SYN包,server回復SYN+ACK,同時將這個處于SYN_RECV狀態的連接保存到半連接隊列。客戶端返回ACK包完成三次握手,server將ESTABLISHED狀態的連接移入accept隊列,等待應用調用accept()。可以看到建立連接涉及兩個隊列:
- 半連接隊列,保存SYN_RECV狀態的連接。隊列長度由net.ipv4.tcp_max_syn_backlog設置
- accept隊列,保存ESTABLISHED狀態的連接。隊列長度為min(net.core.somaxconn,backlog)。其中backlog是我們創建ServerSocket(intport,int backlog)時指定的參數,最終會傳遞給listen方法:#include int listen(int sockfd, int backlog); 如果我們設置的backlog大于net.core.somaxconn,accept隊列的長度將被設置為net.core.somaxconn
另外,為了應對SYNflooding(即客戶端只發送SYN包發起握手而不回應ACK完成連接建立,填滿server端的半連接隊列,讓它無法處理正常的握手請求),Linux實現了一種稱為SYNcookie的機制,通過net.ipv4.tcp_syncookies控制,設置為1表示開啟。簡單說SYNcookie就是將連接信息編碼在ISN(initialsequencenumber)中返回給客戶端,這時server不需要將半連接保存在隊列中,而是利用客戶端隨后發來的ACK帶回的ISN還原連接信息,以完成連接的建立,避免了半連接隊列被攻擊SYN包填滿。對于一去不復返的客戶端握手,不理它就是了。
二、數據包的接收
先看看接收數據包經過的路徑:

數據包的接收,從下往上經過了三層:網卡驅動、系統內核空間,最后到用戶態空間的應用。Linux內核使用sk_buff(socketkernel buffers)數據結構描述一個數據包。當一個新的數據包到達,NIC(networkinterface controller)調用DMAengine,通過RingBuffer將數據包放置到內核內存區。RingBuffer的大小固定,它不包含實際的數據包,而是包含了指向sk_buff的描述符。當RingBuffer滿的時候,新來的數據包將給丟棄。一旦數據包被成功接收,NIC發起中斷,由內核的中斷處理程序將數據包傳遞給IP層。經過IP層的處理,數據包被放入隊列等待TCP層處理。每個數據包經過TCP層一系列復雜的步驟,更新TCP狀態機,最終到達recvBuffer,等待被應用接收處理。有一點需要注意,數據包到達recvBuffer,TCP就會回ACK確認,既TCP的ACK表示數據包已經被操作系統內核收到,但并不確保應用層一定收到數據(例如這個時候系統crash),因此一般建議應用協議層也要設計自己的確認機制。
上面就是一個相當簡化的數據包接收流程,讓我們逐層看看隊列緩沖有關的參數。
1、網卡Bonding模式 當主機有1個以上的網卡時,Linux會將多個網卡綁定為一個虛擬的bonded網絡接口,對TCP/IP而言只存在一個bonded網卡。多網卡綁定一方面能夠提高網絡吞吐量,另一方面也可以增強網絡高可用。Linux支持7種Bonding模式:
詳細的說明參考內核文檔LinuxEthernet Bonding Driver HOWTO。我們可以通過
cat/proc/net/bonding/bond0查看本機的Bonding模式:

一般很少需要開發去設置網卡Bonding模式,自己實驗的話可以參考這篇文檔。
- Mode 0(balance-rr) Round-robin策略,這個模式具備負載均衡和容錯能力
- Mode 1(active-backup) 主備策略,在綁定中只有一個網卡被激活,其他處于備份狀態
- Mode 2(balance-xor) XOR策略,通過源MAC地址與目的MAC地址做異或操作選擇slave網卡
- Mode 3 (broadcast) 廣播,在所有的網卡上傳送所有的報文
- Mode 4 (802.3ad) IEEE 802.3ad動態鏈路聚合。創建共享相同的速率和雙工模式的聚合組
- Mode 5 (balance-tlb) Adaptive transmit loadbalancing
- Mode 6 (balance-alb) Adaptive loadbalancing
2、網卡多隊列及中斷綁定
隨著網絡的帶寬的不斷提升,單核CPU已經不能滿足網卡的需求,這時通過多隊列網卡驅動的支持,可以將每個隊列通過中斷綁定到不同的CPU核上,充分利用多核提升數據包的處理能力。
首先查看網卡是否支持多隊列,使用lspci-vvv命令,找到Ethernetcontroller項:

如果有MSI-X, Enable+ 并且Count > 1,則該網卡是多隊列網卡。
然后查看是否打開了網卡多隊列。使用命令cat/proc/interrupts,如果看到eth0-TxRx-0表明多隊列支持已經打開:

最后確認每個隊列是否綁定到不同的CPU。cat/proc/interrupts查詢到每個隊列的中斷號,對應的文件/proc/irq/${IRQ_NUM}/smp_affinity為中斷號IRQ_NUM綁定的CPU核的情況。以十六進制表示,每一位代表一個CPU核:
(00000001)代表CPU0(00000010)代表CPU1(00000011)代表CPU0和CPU1
如果綁定的不均衡,可以手工設置,例如:
echo "1" > /proc/irq/99/smp_affinity echo "2" > /proc/irq/100/smp_affinity echo "4" > /proc/irq/101/smp_affinity echo "8" > /proc/irq/102/smp_affinity echo "10" > /proc/irq/103/smp_affinity echo "20" > /proc/irq/104/smp_affinity echo "40" > /proc/irq/105/smp_affinity echo "80" > /proc/irq/106/smp_affinity
3、RingBuffer
Ring Buffer位于NIC和IP層之間,是一個典型的FIFO(先進先出)環形隊列。RingBuffer沒有包含數據本身,而是包含了指向sk_buff(socketkernel buffers)的描述符。可以使用ethtool-g eth0查看當前RingBuffer的設置:

上面的例子接收隊列為4096,傳輸隊列為256。可以通過ifconfig觀察接收和傳輸隊列的運行狀況:

- RXerrors:收包總的錯誤數
- RX dropped:表示數據包已經進入了RingBuffer,但是由于內存不夠等系統原因,導致在拷貝到內存的過程中被丟棄。
- RX overruns:overruns意味著數據包沒到RingBuffer就被網卡物理層給丟棄了,而CPU無法及時的處理中斷是造成RingBuffer滿的原因之一,例如中斷分配的不均勻。當dropped數量持續增加,建議增大RingBuffer,使用ethtool-G進行設置。
4、InputPacket Queue(數據包接收隊列)
當接收數據包的速率大于內核TCP處理包的速率,數據包將會緩沖在TCP層之前的隊列中。接收隊列的長度由參數
net.core.netdev_max_backlog設置。
5、recvBuffer
recv buffer是調節TCP性能的關鍵參數。BDP(Bandwidth-delayproduct,帶寬延遲積) 是網絡的帶寬和與RTT(roundtrip time)的乘積,BDP的含義是任意時刻處于在途未確認的最大數據量。RTT使用ping命令可以很容易的得到。為了達到最大的吞吐量,recvBuffer的設置應該大于BDP,即recvBuffer >= bandwidth * RTT。假設帶寬是100Mbps,RTT是100ms,那么BDP的計算如下:
BDP = 100Mbps * 100ms = (100 / 8) * (100 / 1000) = 1.25MB
Linux在2.6.17以后增加了recvBuffer自動調節機制,recvbuffer的實際大小會自動在最小值和最大值之間浮動,以期找到性能和資源的平衡點,因此大多數情況下不建議將recvbuffer手工設置成固定值。
當
net.ipv4.tcp_moderate_rcvbuf設置為1時,自動調節機制生效,每個TCP連接的recvBuffer由下面的3元數組指定:
net.ipv4.tcp_rmem =
最初recvbuffer被設置為,同時這個缺省值會覆蓋net.core.rmem_default的設置。隨后recvbuffer根據實際情況在最大值和最小值之間動態調節。在緩沖的動態調優機制開啟的情況下,我們將net.ipv4.tcp_rmem的最大值設置為BDP。
當
net.ipv4.tcp_moderate_rcvbuf被設置為0,或者設置了socket選項SO_RCVBUF,緩沖的動態調節機制被關閉。recvbuffer的缺省值由net.core.rmem_default設置,但如果設置了net.ipv4.tcp_rmem,缺省值則被覆蓋。可以通過系統調用setsockopt()設置recvbuffer的最大值為net.core.rmem_max。在緩沖動態調節機制關閉的情況下,建議把緩沖的缺省值設置為BDP。
注意這里還有一個細節,緩沖除了保存接收的數據本身,還需要一部分空間保存socket數據結構等額外信息。因此上面討論的recvbuffer最佳值僅僅等于BDP是不夠的,還需要考慮保存socket等額外信息的開銷。Linux根據參數
net.ipv4.tcp_adv_win_scale計算額外開銷的大小:

如果
net.ipv4.tcp_adv_win_scale的值為1,則二分之一的緩沖空間用來做額外開銷,如果為2的話,則四分之一緩沖空間用來做額外開銷。因此recvbuffer的最佳值應該設置為:

三、數據包的發送
發送數據包經過的路徑:

和接收數據的路徑相反,數據包的發送從上往下也經過了三層:用戶態空間的應用、系統內核空間、最后到網卡驅動。應用先將數據寫入TCP sendbuffer,TCP層將sendbuffer中的數據構建成數據包轉交給IP層。IP層會將待發送的數據包放入隊列QDisc(queueingdiscipline)。數據包成功放入QDisc后,指向數據包的描述符sk_buff被放入RingBuffer輸出隊列,隨后網卡驅動調用DMAengine將數據發送到網絡鏈路上。
同樣我們逐層來梳理隊列緩沖有關的參數。
1、sendBuffer
同recvBuffer類似,和sendBuffer有關的參數如下:net.ipv4.tcp_wmem =
net.core.wmem_defaultnet.core.wmem_max 發送端緩沖的自動調節機制很早就已經實現,并且是無條件開啟,沒有參數去設置。如果指定了tcp_wmem,則net.core.wmem_default被tcp_wmem的覆蓋。sendBuffer在tcp_wmem的最小值和最大值之間自動調節。如果調用setsockopt()設置了socket選項SO_SNDBUF,將關閉發送端緩沖的自動調節機制,tcp_wmem將被忽略,SO_SNDBUF的最大值由net.core.wmem_max限制。
2、QDisc
QDisc(queueing discipline )位于IP層和網卡的ringbuffer之間。我們已經知道,ringbuffer是一個簡單的FIFO隊列,這種設計使網卡的驅動層保持簡單和快速。而QDisc實現了流量管理的高級功能,包括流量分類,優先級和流量整形(rate-shaping)。可以使用tc命令配置QDisc。
QDisc的隊列長度由txqueuelen設置,和接收數據包的隊列長度由內核參數
net.core.netdev_max_backlog控制所不同,txqueuelen是和網卡關聯,可以用ifconfig命令查看當前的大小:

使用ifconfig調整txqueuelen的大小:
ifconfig eth0 txqueuelen 2000
3、RingBuffer
和數據包的接收一樣,發送數據包也要經過RingBuffer,使用ethtool-g eth0查看:

其中TX項是RingBuffer的傳輸隊列,也就是發送隊列的長度。設置也是使用命令ethtool-G。
4、TCPSegmentation和Checksum Offloading
操作系統可以把一些TCP/IP的功能轉交給網卡去完成,特別是Segmentation(分片)和checksum的計算,這樣可以節省CPU資源,并且由硬件代替OS執行這些操作會帶來性能的提升。一般以太網的MTU(MaximumTransmission Unit)為1500 bytes,假設應用要發送數據包的大小為7300bytes,MTU1500字節- IP頭部20字節 -TCP頭部20字節=有效負載為1460字節,因此7300字節需要拆分成5個segment:

Segmentation(分片)操作可以由操作系統移交給網卡完成,雖然最終線路上仍然是傳輸5個包,但這樣節省了CPU資源并帶來性能的提升:

可以使用ethtool-k eth0查看網卡當前的offloading情況:

上面這個例子checksum和tcpsegmentation的offloading都是打開的。如果想設置網卡的offloading開關,可以使用ethtool-K(注意K是大寫)命令,例如下面的命令關閉了tcp segmentation offload:sudo ethtool -K eth0 tso off
5、網卡多隊列和網卡Bonding模式
在數據包的接收過程中已經介紹過了。
-
Linux
+關注
關注
87文章
11345瀏覽量
210395 -
參數
+關注
關注
11文章
1859瀏覽量
32427 -
TCP
+關注
關注
8文章
1378瀏覽量
79302 -
數據包
+關注
關注
0文章
267瀏覽量
24500
發布評論請先 登錄
相關推薦
Linux TCP隊列相關參數的總結

關于TCP/IP協議的知識總結
Linux內核網絡的TCP傳輸控制塊相關資料分享
總結一些常見網絡相關的內核參數

如何修復Linux內核存在的TCP漏洞?
TCP IP相關知識的詳細資料說明免費下載
如何用eBPF寫TCP擁塞控制算法?
關于TCP協議總結的硬核干貨
Linux TCP內核的參數設置與調優






 工商網監
工商網監
評論