") Linux線程、線程與異步編程、協(xié)程與異步介紹
Linux線程、線程與異步編程、協(xié)程與異步介紹
協(xié)程不是系統(tǒng)級線程,很多時(shí)候協(xié)程被稱為“輕量級線程”、“微線程”、“纖程(fiber)”等。簡單來說可以認(rèn)為協(xié)程是線程里不同的函數(shù),這些函數(shù)之間可以相互快速切換。
協(xié)程和用戶態(tài)線程非常接近,用戶態(tài)線程之間的切換不需要陷入內(nèi)核,但部分操作系統(tǒng)中用戶態(tài)線程的切換需要內(nèi)核態(tài)線程的輔助。
協(xié)程是編程語言(或者 lib)提供的特性(協(xié)程之間的切換方式與過程可以由編程人員確定),是用戶態(tài)操作。協(xié)程適用于 IO 密集型的任務(wù)。常見提供原生協(xié)程支持的語言有:c++20、golang、python 等,其他語言以庫的形式提供協(xié)程功能,比如 C++20 之前騰訊的 fiber 和 libco 等等
Linux 線程資源消耗分析
大腦 && 流水線 && 分工
上下文切換可以類比于人腦的工作方式。工作中不斷切換工作內(nèi)容與場景一般非常累且效率低下(這是流水線發(fā)明的初衷也是勞動(dòng)分工要解決的問題),但在同一個(gè)場景下有關(guān)聯(lián)的幾個(gè)子任務(wù)之間相互切換并不耗神,這與線程和協(xié)程的切換非常相似
人腦支持異步處理,我們的饑餓感可以認(rèn)為是系統(tǒng)中斷;我們的生物鐘可以認(rèn)為是類似于定時(shí)器一樣的后臺(tái)硬件;我們的感情、知識(shí)、意識(shí)都在潛移默化中慢慢發(fā)生變化,這說明大腦也有“后臺(tái)任務(wù)”
進(jìn)程、線程上下文切換
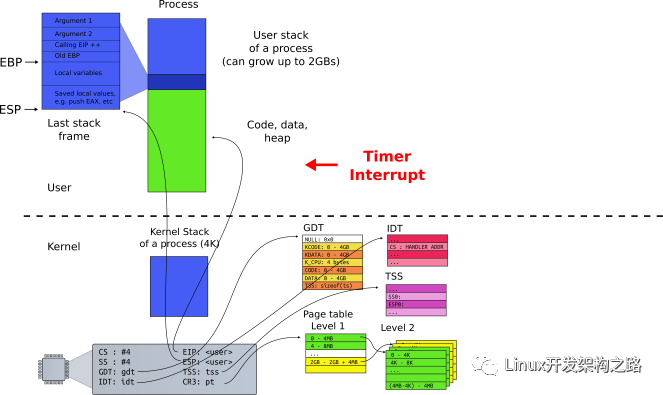
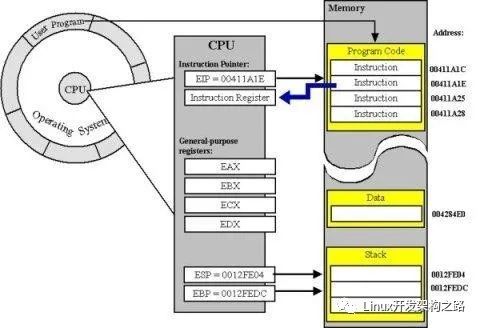
下圖展示了進(jìn)程/線程在運(yùn)行過程 CPU 需要的一些信息(CPU Context,CPU 上下文),比如通用寄存器、棧信息(EBP/ESP)等。進(jìn)程/線程切換時(shí)需要保存與恢復(fù)這些信息
進(jìn)程/內(nèi)核態(tài)線程切換的時(shí)候需要與 OS 內(nèi)核進(jìn)行交互,保存/讀取 CPU 上下文信息。內(nèi)核態(tài)(Kernel)的一些數(shù)據(jù)是共享的,讀寫時(shí)需要同步機(jī)制,所以操作一旦陷入內(nèi)核態(tài)就會(huì)消耗更多的時(shí)間
進(jìn)程需要與操作系統(tǒng)中所有其他進(jìn)程進(jìn)行資源爭搶,且操作系統(tǒng)中資源的鎖是全局的;線程之間的數(shù)據(jù)一般在進(jìn)程內(nèi)共享,所以線程間資源共享相比如進(jìn)程而言要輕一些。雖然很多操作系統(tǒng)(比如 Linux)進(jìn)程與線程區(qū)別不是非常明顯,但線程還是比進(jìn)程要輕
Linux 線程切換耗時(shí)分析
線程的切換(Context Switch)相比于其他操作而言并不是非常耗時(shí),如下圖所示(2018 年):

Linux 2.6 之后 Linux 多線程的性能提高了很多,大部分場景下線程切換耗時(shí)在 2us 左右。下面是 Linux 下線程切換耗時(shí)統(tǒng)計(jì)(2013 年)
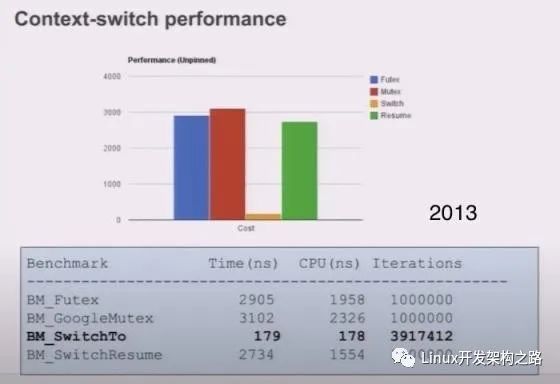
正常情況下線程有用的 CPU 時(shí)間片都在數(shù)十毫秒級別,線程切換占總耗時(shí)的千分之幾以內(nèi)。協(xié)程的使用可以將這個(gè)損耗進(jìn)一步降低(主要是去除了其他操作,比如 futex 等)
雖然線程切換對于常見業(yè)務(wù)而言并不重要,但不是所有語言或者系統(tǒng)都支持一次創(chuàng)建很多線程。32 位系統(tǒng)即使使用了虛內(nèi)存空間,因?yàn)檫M(jìn)程能訪問的虛內(nèi)存空間大概是 3GB,所以單進(jìn)程最多創(chuàng)建 300 多條線程(假設(shè)系統(tǒng)為每條線程分配 10M 棧空間)。太多線程也有線程切換觸發(fā)了缺頁中斷的風(fēng)險(xiǎn)
創(chuàng)建很多線程(比如 64 位系統(tǒng)下創(chuàng)建 1 萬條線程),不考慮優(yōu)先級且假設(shè) CPU 有 10 個(gè)核心,那么每個(gè)線程每秒有 1ms 的時(shí)間片,整個(gè)業(yè)務(wù)的耗時(shí)大概是 (n-1) * 1 + n * 0.001(n?1)?1+n?0.001 秒(n 是線程在處理業(yè)務(wù)的過程中被調(diào)度的次數(shù)),如果大量線程之間存在資源競爭,那么系統(tǒng)行為將難以預(yù)測。所以在有限的資源下創(chuàng)建大量線程是不合理的,服務(wù)線程的個(gè)數(shù)和 CPU 核心數(shù)應(yīng)該在一個(gè)合理的比例內(nèi)。

內(nèi)存資源占用
默認(rèn)情況下 Linux 系統(tǒng)給每條線程分配的棧空間最大是 6~8MB,這個(gè)大小是上限,也是虛內(nèi)存空間,并不是每條線程真實(shí)的棧使用情況。線程真實(shí)棧內(nèi)存使用會(huì)隨著線程執(zhí)行而變化,如果線程只使用了少量局部變量,那么真實(shí)線程棧可能只有幾十個(gè)字節(jié)的大小。系統(tǒng)在維護(hù)線程時(shí)需要分配額外的空間,所以線程數(shù)的增加還是會(huì)提高內(nèi)存資源的消耗
總結(jié)
如果線程之間沒有競爭關(guān)系、線程占用的內(nèi)存資源較少且對延時(shí)不是非常敏感或者說線程創(chuàng)建不頻繁(數(shù)分鐘創(chuàng)建一次),那么直接在使用的時(shí)候創(chuàng)建新的線程(std::thread+detach/std::async)也是不錯(cuò)的選擇
如果業(yè)務(wù)處理時(shí)間遠(yuǎn)小于 IO 耗時(shí),線程切換非常頻繁,那么使用協(xié)程是不錯(cuò)的選擇
協(xié)程的優(yōu)勢并不僅僅是減少線程之間切換,從編程的角度來看,協(xié)程的引入簡化了異步編程。協(xié)程為一些異步編程提供了無鎖的解決方案,這些將在下文進(jìn)行介紹
線程與異步編程
同步與異步

同步與異步的區(qū)別是順序與并行,同步編程意味著只有前置操作執(zhí)行完成才能執(zhí)行后續(xù)流程,如上圖 AB 和 CD;異步說明二者可以同時(shí)執(zhí)行,如上圖中的 AC(這里不區(qū)分并發(fā)、并行的區(qū)別)
常見異步編程方式
C++11 async && future

async 與 future 相關(guān)知識(shí)可參考其他文章,這里不做詳細(xì)介紹。術(shù)語 future(期貨)&& promise(承諾) 源自金融領(lǐng)域
下面代碼使用多線程實(shí)現(xiàn)數(shù)據(jù)的累加。線程的創(chuàng)建/調(diào)度與其他操作會(huì)造成了一些消耗,所以少量數(shù)據(jù)不建議使用多線程
int64_t multi_thread_acc(const std::vector< int >& data) {
if (data.size() < ELEM_NUM_MULTI_TH_LIMIT) { // 少于一定數(shù)量的累加直接使用單線程會(huì)更好
return std::accumulate(data.begin(), data.end(), int64_t(0));
} else {
auto step = data.size() / USED_CORE_NUM; // or std::hardware_currency
std::vector< std::future< int64_t >> ret_vec;
ret_vec.reserve(USED_CORE_NUM);
for (int i = 0; i < USED_CORE_NUM; i++) {
auto lhs_it = data.begin() + i * step;
auto rhs_it = (i == USED_CORE_NUM - 1) ? data.end() : lhs_it + step;
ret_vec.emplace_back(
// 持續(xù)創(chuàng)建少量線程并不會(huì)給系統(tǒng)造成太大的壓力
std::async([lhs_it, rhs_it] {
return std::accumulate(lhs_it, rhs_it, int64_t(0));
}));
}
int64_t ret = 0;
// 阻塞調(diào)用
for (auto& fu : ret_vec) {
ret += fu.get();
}
return ret;
}
}
從上面的代碼中可以看出,常規(guī)的異步編程手段還是需要一個(gè)同步的過程來搜集異步線程的執(zhí)行結(jié)果
Reactor/Proactor
網(wǎng)絡(luò)編程的發(fā)展與模式大概有下面幾種:
- 每個(gè)請求一個(gè)線程/進(jìn)程,阻塞式 IO
- 阻塞式 IO,線程池
- 非阻塞式 IO && IO 復(fù)用,類似于 Reactor
- Leader/Folloer 等模式
Reactor 編程模式是事件驅(qū)動(dòng)的,并以回調(diào)(handle)的方式完成具體業(yè)務(wù),Reactor 有幾個(gè)基本概念
- nonblockingIO+I(xiàn)Omultiplexing,請參考 epoll
- Event loop,一個(gè)監(jiān)控事件源(epoll fd)的“死循環(huán)”
// ... 前置設(shè)置略
while(true) { // event loop
nfds = epoll_wait(epollFd, events, MAX_EVENTS, -1);
if(nfds == -1){
printf("epoll_wait failedn");
exit(EXIT_FAILURE);
}
for(int i = 0; i < nfds; i++){
if(events[i].data.fd == listenFd){
connectFd = accept(listenFd, (sockaddr*)NULL, NULL);
printf("Connected ...n");
pthread_t thread;
// 使用線程池可以減少系統(tǒng)消耗
pthread_create(&thread, NULL, handleConnection, (void *) &connectFd);
}
else {
if() // readable
if() // writeable
}
}
}
優(yōu)點(diǎn)與缺點(diǎn)
優(yōu)點(diǎn):
- 線程數(shù)目基本固定,可以在程序啟動(dòng)的時(shí)候設(shè)置,不會(huì)頻繁創(chuàng)建與銷毀
- 可以很方便地在線程間調(diào)配負(fù)載
- IO 事件發(fā)生的線程是固定的,同一個(gè) TCP 連接不必考慮事件并發(fā)
缺點(diǎn):
基于事件的模型有個(gè)非常明顯的缺陷,回調(diào)函數(shù)(handle)不能阻塞(非搶占式調(diào)度),否則線程或者進(jìn)程有耗盡的風(fēng)險(xiǎn),即使不耗盡,也會(huì)給系統(tǒng)帶來負(fù)擔(dān)。參考上文的介紹,創(chuàng)建大量進(jìn)程/線程是不合理的
響應(yīng)式編程(基于回調(diào))
響應(yīng)式編程( Reactive Programming)主要關(guān)注的是數(shù)據(jù)流的變換和流轉(zhuǎn),因此它更注描述數(shù)據(jù)輸入和輸出之間 的關(guān)系。輸入和輸出之間用函數(shù)變換來連接,函數(shù)之間也只對輸入輸出負(fù)責(zé),因此我們可以很輕松地通過將這些 函數(shù)調(diào)用分發(fā)到其他線程上的方法來實(shí)現(xiàn)異步
響應(yīng)式編程中的邏輯單元也不能阻塞,否則也有耗盡工作線程的風(fēng)險(xiǎn);非阻塞式 handle 又有陷入回調(diào)地獄的風(fēng)險(xiǎn)
回調(diào)地獄
大部分異步編程框架都是基于回調(diào)的,當(dāng)一個(gè)業(yè)務(wù)需要多個(gè)步驟時(shí)回調(diào)函數(shù)會(huì)分布在不同的執(zhí)行單元中,這對代碼的維護(hù)與理解造成了壓力。當(dāng)執(zhí)行鏈條非常長時(shí)回調(diào)鏈路也會(huì)很深
基于事件與回調(diào)的編碼風(fēng)格將業(yè)務(wù)割裂到不同的 handle 函數(shù)中,理解與維護(hù)起來比較麻煩
Coroutine
通過上面的敘述,在資源有限的前提下,高性能服務(wù)需要解決的問題如下:
- 減少線程的重復(fù)高頻創(chuàng)建
- 常規(guī)解決辦法:線程池
- 盡量避免線程的阻塞
- Reactor && 非阻塞回調(diào),解決問題的能力有限
- 響應(yīng)式編程,容易陷入回調(diào)地獄,割裂業(yè)務(wù)邏輯
- 其他方法,例如協(xié)程
- 提升代碼的可維護(hù)與可理解性,盡量避免回調(diào)地獄
- 少使用回調(diào)函數(shù),減少回調(diào)鏈深度
使用協(xié)程可以解決上面 2/3 兩個(gè)問題。協(xié)程可以用同步編程的方式實(shí)現(xiàn)異步編程才能實(shí)現(xiàn)的功能
協(xié)程與狀態(tài)機(jī)
A computer is a state machine. Threads are for people who can’t program state machines ——Alan Cox
無棧協(xié)程是對計(jì)算機(jī)是狀態(tài)機(jī)的實(shí)踐
協(xié)程的原理
協(xié)程的切換和線程進(jìn)程的切換機(jī)制是相似的(CPU 上下文與棧信息的保存與恢復(fù)),協(xié)程在切換出去的時(shí)候需要保存當(dāng)前的運(yùn)行狀態(tài),比如 CPU 寄存器、棧信息等等
Stackless && Stackful
有棧協(xié)程與無棧協(xié)程是協(xié)程的兩種實(shí)現(xiàn)方式,這里的棧是“邏輯棧”,不是內(nèi)存棧
比如協(xié)程 A 調(diào)用了協(xié)程 B,如果只有 B 完成之后才能調(diào)用 A 那么這個(gè)協(xié)程就是 Stackful,此時(shí) A/B 是非對稱協(xié)程;如果 A/B 被調(diào)用的概率相同那么這個(gè)協(xié)程就是 Stackless,此時(shí) A/B 是對稱協(xié)程
下面主要介紹無棧協(xié)程的實(shí)現(xiàn)方法,如果對有棧協(xié)程有興趣,可以看 libco 等庫等實(shí)現(xiàn)。C++20 引入的是無棧協(xié)程
使用 setjmp/longjmp 實(shí)現(xiàn)的簡單協(xié)程
下面代碼模擬了單線程并發(fā)執(zhí)行兩個(gè) while(true){...} 函數(shù),細(xì)節(jié)可以查看原始 文檔 和 代碼
setjmp/longjmp 不能作為協(xié)程實(shí)現(xiàn)的底層機(jī)制,因?yàn)?setjmp/longjmp 對棧信息的支持有限
int max_iteration = 9;
int iter;
jmp_buf Main;
jmp_buf PointPing;
jmp_buf PointPong;
void Ping(void);
void Pong(void);
int main(int argc, char* argv[]) {
iter = 1;
if (setjmp(Main) == 0) Ping();
if (setjmp(Main) == 0) Pong();
longjmp(PointPing, 1);
}
void Ping(void) {
if (setjmp(PointPing) == 0) longjmp(Main, 1); // 可以理解為重置,reset the world
while (1) {
printf("%3d : Ping-", iter);
if (setjmp(PointPing) == 0) longjmp(PointPong, 1);
}
}
void Pong(void) {
if (setjmp(PointPong) == 0) longjmp(Main, 1);
while (1) {
printf("Pongn");
iter++;
if (iter > max_iteration) exit(0);
if (setjmp(PointPong) == 0) longjmp(PointPing, 1);
}
}
通過命令 gcc test.c 編譯后執(zhí)行 ./a.out 7 ,輸出如下:
1 : Ping-Pong
2 : Ping-Pong
3 : Ping-Pong
4 : Ping-Pong
5 : Ping-Pong
6 : Ping-Pong
7 : Ping-Pong
協(xié)程的特點(diǎn)
- 協(xié)程可以自動(dòng)讓出 CPU 時(shí)間片。注意,不是當(dāng)前線程讓出 CPU 時(shí)間片,而是線程內(nèi)的某個(gè)協(xié)程讓出時(shí)間片供同線程內(nèi)其他協(xié)程運(yùn)行
- 協(xié)程可以恢復(fù) CPU 上下文。當(dāng)另一個(gè)協(xié)程繼續(xù)執(zhí)行時(shí),其需要恢復(fù) CPU 上下文環(huán)境
- 協(xié)程有個(gè)管理者,管理者可以選擇一個(gè)協(xié)程來運(yùn)行,其他協(xié)程要么阻塞,要么 ready,或者 died
- 運(yùn)行中的協(xié)程將占有當(dāng)前線程的所有計(jì)算資源
- 協(xié)程天生有棧屬性,而且是 lock free
其他協(xié)程庫
ucontext,CPU 上下文管理
下面關(guān)于 ucontext 的介紹源自:
http://pubs.opengroup.org/onlinepubs/7908799/xsh/ucontext.h.html 。ucontext lib 已經(jīng)不推薦使用了,但依舊是不錯(cuò)的協(xié)程入門資料。其他底層協(xié)程庫實(shí)現(xiàn)可以查看 Boost.Context / tbox 等,協(xié)程庫的對比可以參考:https://github.com/tboox/benchbox/wiki/switch
linux 系統(tǒng)一般都有 ucontext 這個(gè) c 語言庫,這個(gè)庫主要用于操控當(dāng)前線程下的 CPU 上下文。和 setjmp/longjmp 不同,ucontext 直接提供了設(shè)置函數(shù)運(yùn)行時(shí)棧的方式(makecontext),避免不同函數(shù)棧空間的重疊
ucontext 只操作與當(dāng)前線程相關(guān)的 CPU 上下文,所以下文中涉及 ucontext 的上下文均指當(dāng)前線程的上下文。一般 CPU 有多個(gè)核心,一個(gè)線程在某一時(shí)刻只能使用其中一個(gè),所以 ucontext 只涉及一個(gè)與當(dāng)前線程相關(guān)的 CPU 核心
ucontext.h 頭文件中定義了 ucontext_t 這個(gè)結(jié)構(gòu)體,這個(gè)結(jié)構(gòu)體中至少包含以下成員:
ucontext_t *uc_link // next context
sigset_t uc_sigmask // 阻塞信號阻塞
stack_t uc_stack // 當(dāng)前上下文所使用的棧
mcontext_t uc_mcontext // 實(shí)際保存 CPU 上下文的變量,這個(gè)變量與平臺(tái)&機(jī)器相關(guān),最好不要訪問這個(gè)變量
同時(shí),ucontext.h 頭文件中定義了四個(gè)函數(shù),下面分別介紹:
int getcontext(ucontext_t *); // 獲得當(dāng)前 CPU 上下文
int setcontext(const ucontext_t *);// 重置當(dāng)前 CPU 上下文
void makecontext(ucontext_t *, (void *)(), int, ...); // 修改上下文信息,比如設(shè)置棧指針
int swapcontext(ucontext_t *, const ucontext_t *);
getcontext & setcontext
#include < ucontext.h >
int getcontext(ucontext_t *ucp);
int setcontext(ucontext_t *ucp);
getcontext 函數(shù)使用當(dāng)前 CPU 上下文初始化 ucp 所指向的結(jié)構(gòu)體,初始化的內(nèi)容包括 CPU 寄存器、信號 mask 和當(dāng)前線程所使用的棧空間
返回值:getcontext 成功返回 0,失敗返回 -1。注意,如果 setcontext 執(zhí)行成功,那么調(diào)用 setcontext 的函數(shù)將不會(huì)返回,因?yàn)楫?dāng)前 CPU 的上下文已經(jīng)交給其他函數(shù)或者過程了,當(dāng)前函數(shù)完全放棄了 對 CPU 的“所有權(quán)”
應(yīng)用:當(dāng)信號處理函數(shù)需要執(zhí)行的時(shí)候,當(dāng)前線程的上下文需要保存起來,隨后進(jìn)入信號處理階段。可移植的程序最好不要讀取與修改 ucontext_t 中的 uc_mcontext,因?yàn)椴煌脚_(tái)下 uc_mcontext 的實(shí)現(xiàn)是不同的
makecontext & swapcontext
#include < ucontext.h >
void makecontext(ucontext_t *ucp, (void *func)(), int argc, ...);
int swapcontext(ucontext_t *oucp, const ucontext_t *ucp);
makecontext 修改由 getcontext 創(chuàng)建的上下文 ucp。如果 ucp 指向的上下文由 swapcontext 或 setcontext 恢復(fù),那么當(dāng)前線程將執(zhí)行傳遞給 makecontext 的函數(shù) func(...)
執(zhí)行 makecontext 后需要為新上下文分配一個(gè)棧空間,如果不創(chuàng)建,那么新函數(shù)func執(zhí)行時(shí)會(huì)使用舊上下文的棧,而這個(gè)棧可能已經(jīng)不存在了。argc 必須和 func 中整型參數(shù)的個(gè)數(shù)相等。
swapcontext 將當(dāng)前上下文信息保存到 oucp 中并使用 ucp 重置 CPU 上下文
返回值:swapcontext 成功則返回 0,失敗返回 -1 并置 errno。如果 ucp 所指向的上下文沒有足夠的棧空間以執(zhí)行余下的過程,swapcontext 將返回 -1
進(jìn)一步學(xué)習(xí)
有很多協(xié)程庫的實(shí)現(xiàn)是基于 ucontext 的,我們可以在學(xué)習(xí)這些庫的時(shí)候順便學(xué)習(xí)一下 ucontext 庫的使用方法
coroutine,簡單的 C 協(xié)程庫
coroutine 是基于 ucontext 的一個(gè) C 語言協(xié)程庫實(shí)現(xiàn)。包含示例代碼在內(nèi),全部代碼行數(shù)不超過 300 行,Mac&&Linux 可以直接編譯運(yùn)行
下面是一段示例代碼:
#include < stdio.h >
#include "coroutine.h"
struct args { int n; };
static void foo(struct schedule* S, void* ud) {
struct args* arg = ud;
int start = arg- >n;
int i;
for (i = 0; i < 5; i++) {
printf("coroutine %d : %dn", coroutine_running(S), start + i);
coroutine_yield(S);
}
}
int main() {
struct schedule* S = coroutine_open(); // 創(chuàng)建協(xié)程管理對象
struct args arg1 = {0};
struct args arg2 = {100};
int co1 = coroutine_new(S, foo, &arg1); // 注冊協(xié)程函數(shù)
int co2 = coroutine_new(S, foo, &arg2);
printf("main startn");
while (coroutine_status(S, co1) || coroutine_status(S, co2)) {
coroutine_resume(S, co1); // 執(zhí)行協(xié)程
coroutine_resume(S, co2);
}
printf("main endn");
coroutine_close(S);
return 0;
}
fiber/libco 等
協(xié)程常用于異步編程,libco 等庫利用協(xié)程劫持并封裝了底層網(wǎng)絡(luò) IO 相關(guān)的函數(shù),以同步編程的方式實(shí)現(xiàn)了網(wǎng)絡(luò)事件的異步處理
具體細(xì)節(jié)請參考其他資料,本文不展開介紹
N:1 && N:M 協(xié)程
和線程綁定的協(xié)程只有在對應(yīng)線程運(yùn)行的時(shí)候才有被執(zhí)行的可能,如果對應(yīng)線程中的某一個(gè)協(xié)程完全占有了當(dāng)前線程,那么當(dāng)前線程中的其他所有協(xié)程都不會(huì)被執(zhí)行
協(xié)程的所有信息都保存在上下文(Contex)對象中,將不同上下文分發(fā)給不同的線程就可以實(shí)現(xiàn)協(xié)程的跨線程執(zhí)行,如此,協(xié)程被阻塞的概率將減小
借用 BRPC 中對 N:M 協(xié)程的介紹,來解釋下什么是 N:M 協(xié)程
我們常說的協(xié)程特指 N:1 線程庫,即所有的協(xié)程運(yùn)行于一個(gè)系統(tǒng)線程中,計(jì)算能力和各類 eventloop 庫等價(jià)。由于不跨線程,協(xié)程之間的切換不需要系統(tǒng)調(diào)用,可以非常快(100ns-200ns),受 cache 一致性的影響也小。但代價(jià)是協(xié)程無法高效地利用多核,代碼必須非阻塞,否則所有的協(xié)程都被卡住…… bthread 是一個(gè) M:N 線程庫,一個(gè) bthread 被卡住不會(huì)影響其他 bthread。關(guān)鍵技術(shù)兩點(diǎn):work stealing 調(diào)度和 butex,前者讓 bthread 更快地被調(diào)度到更多的核心上,后者讓 bthread 和 pthread 可以相互等待和喚醒。這兩點(diǎn)協(xié)程都不需要。更多線程的知識(shí)查看這里
總結(jié)
協(xié)程的組成
通過上面的描述,N:M 模式下的協(xié)程其實(shí)就是可用戶確定調(diào)度順序的用戶態(tài)線程。與系統(tǒng)級線程對照可以將協(xié)程框架分為以下幾個(gè)模塊
- 協(xié)程上下文,對應(yīng)操作系統(tǒng)中的 PCB/TCB(Process/Thread Control Block)
- 保存協(xié)程上下文的容器,對應(yīng)操作系統(tǒng)中保存 PCB/TCB 的容器,一般是一個(gè)列表。協(xié)程上下文容器可以使用一個(gè)也可以使用多個(gè),比如普通協(xié)程隊(duì)列、定時(shí)的協(xié)程優(yōu)先隊(duì)列等
- 協(xié)程的執(zhí)行器
- 協(xié)程的調(diào)度器,對應(yīng)操作系統(tǒng)中的進(jìn)程/線程調(diào)度器
- 執(zhí)行協(xié)程的 worker 線程,對應(yīng)實(shí)際線程/進(jìn)程所使用的 CPU 核心
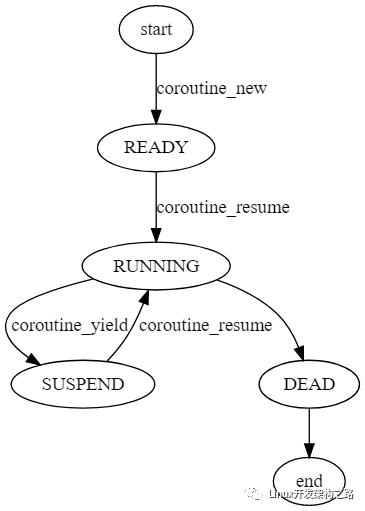
協(xié)程的調(diào)度
協(xié)程的調(diào)度與 OS 線程調(diào)度十分相似,如下圖協(xié)程調(diào)度示例所示
協(xié)程工具
系統(tǒng)級線程有鎖(mutex)、條件變量(condition)等工具,協(xié)程也有對應(yīng)的工具。比如 libgo 提供了協(xié)程之間使用的鎖 Co_mutex/Co_rwmutex 。不同協(xié)程框架對工具的支持程度不同,實(shí)現(xiàn)方式也不盡相同,本文不做深入介紹
系統(tǒng)級線程和協(xié)程處于不同的系統(tǒng)層級,所以兩者的同步工具不完全通用,如果在協(xié)程中使用了線程的鎖(例如:std::mutex),則整個(gè)線程將會(huì)被阻塞,當(dāng)前線程將不會(huì)再調(diào)度與執(zhí)行其他協(xié)程
協(xié)程 vs 線程
- 調(diào)度方式
- 協(xié)程由編程者控制,協(xié)程之間可以有優(yōu)先級;線程由系統(tǒng)控制,一般沒有優(yōu)先級
- 調(diào)度速度
- 協(xié)程幾乎比線程快一個(gè)數(shù)量級。協(xié)程調(diào)用由編碼者控制,可以減少無效的調(diào)度
- 資源占用
- 協(xié)程可以控制內(nèi)存占用量,靈活性更好;線程由系統(tǒng)控制
- 創(chuàng)建數(shù)量
- 協(xié)程的使用更靈活(有優(yōu)先級控制、資源使用可控),調(diào)度速度更快,相比于線程而言調(diào)度損耗更小,所以真實(shí)可創(chuàng)建且有效的協(xié)程數(shù)量可以比線程多很多,這是使用協(xié)程實(shí)現(xiàn)異步編程的重要基礎(chǔ)。同樣因?yàn)檎{(diào)度與資源的限制,有效協(xié)程的數(shù)量也是有上限的
協(xié)程與異步
C++20 只引入了協(xié)程需要的底層支持,所以直接使用相對比較難,不過很多庫已經(jīng)提供了封裝,比如 ASIO 和 cppcoro 。C++20 協(xié)程的性能還是非常高的,等 C++23 提供簡化后的 lib,就可以方便使用協(xié)程了
編譯協(xié)程相關(guān)代碼需要 g++10 或者更高版本(clang++12 對協(xié)程支持有限)
- Mac,brew install gcc@10
- Ubuntu,apt install gcc-10 / apt install g++-10
將協(xié)程的使用做了封裝,大部分情況下我們都不會(huì)和底層協(xié)程工具打交到,代碼的編寫風(fēng)格和常規(guī)的同步編碼風(fēng)格相同
協(xié)程對 CPU/IO 的影響
協(xié)程的目的在于剔除線程的阻塞,盡可能提高 CPU 的利用率
很多服務(wù)在處理業(yè)務(wù)時(shí)需要請求第三方服務(wù),向第三方服務(wù)發(fā)起 RPC 調(diào)用。RPC 調(diào)用的網(wǎng)絡(luò)耗時(shí)一般耗時(shí)在毫秒級別,RPC 服務(wù)的處理耗時(shí)也可能在毫秒級別,如果當(dāng)前服務(wù)使用同步調(diào)用,即 RPC 返回后才進(jìn)行后續(xù)邏輯,那么一條線程每秒處理的業(yè)務(wù)數(shù)量是可以估算的
假設(shè)每次業(yè)務(wù)處理花費(fèi)在 RPC 調(diào)用上的耗時(shí)是 20ms,那么一條線程一秒最多處理 50 次請求。如果在等待 RPC 返回時(shí)當(dāng)前線程沒有被系統(tǒng)調(diào)度轉(zhuǎn)換為 Ready 狀態(tài),那當(dāng)前 CPU 核心就會(huì)空轉(zhuǎn),浪費(fèi)了 CPU 資源。通過增加線程數(shù)量提高系統(tǒng)吞吐量的效果非常有限,而且創(chuàng)建大量線程也會(huì)造成其他問題
協(xié)程雖然不一定能減少一次業(yè)務(wù)請求的耗時(shí),但一定可以提升系統(tǒng)的吞吐量:
- 當(dāng)前業(yè)務(wù)只有一次第三方 RPC 的調(diào)用,那么協(xié)程不會(huì)減少業(yè)務(wù)處理的耗時(shí),但可以提升 QPS
- 當(dāng)前業(yè)務(wù)需要多個(gè)第三方 RPC 調(diào)用,同時(shí)創(chuàng)建多個(gè)協(xié)程可以讓多個(gè) RPC 調(diào)用一起執(zhí)行,則當(dāng)前業(yè)務(wù)的 RPC 耗時(shí)由耗時(shí)最長的 RPC 調(diào)用決定
ASIO C++ 網(wǎng)絡(luò)編程(同步/異步/協(xié)程)
ASIO 是一個(gè)跨平臺(tái)的 C++ 網(wǎng)絡(luò)庫,有非常大的可能進(jìn)入 C++ 標(biāo)準(zhǔn)庫。ASIO 不僅僅提供了網(wǎng)絡(luò)功能(TCP/UDP/ICMP 等)也提供了很多編程工具,比如串口、定時(shí)器等。ASIO 可以脫離 Boost 編譯,且只需要[頭文件](
https://sourceforge.net/projects/asio/files/asio/1.19.2 (Development)/),使用起來很方便。下面的代碼均基于 [ASIO 1.19.2](https://sourceforge.net/projects/asio/files/asio/1.19.2 (Development)/)
阻塞型網(wǎng)絡(luò)服務(wù)(Echo)
參考代碼:blocking_tcp_echo_server ,每個(gè)請求一個(gè)線程。海量請求對系統(tǒng)而言負(fù)擔(dān)比較重
// g++-10 -I. echo_server.cpp
void session(tcp::socket sock) {
// 同步讀寫操作,下面代碼忽略了錯(cuò)誤處理邏輯
for (;;) {
size_t length = sock.read_some(asio::buffer(data), error);
asio::write(sock, asio::buffer(data, length));
}
}
void server(asio::io_context& io_context, unsigned short port) {
tcp::acceptor a(io_context, tcp::endpoint(tcp::v4(), port));
// 注意這里的 a.accept() 是阻塞型操作,accept 返回后才會(huì)創(chuàng)建線程
for (;;) std::thread(session, a.accept()).detach();
}
int main(int argc, char* argv[]) {
asio::io_context io_context;
server(io_context, std::atoi(argv[1]));
return 0;
}
非阻塞型 Echo
參考代碼:async_tcp_echo_server ,基于事件與回調(diào)。所有回調(diào)函數(shù)中都有對其他接口的調(diào)用(比如 do_read 中調(diào)用了 do_write),業(yè)務(wù)邏輯被割裂在不同的回調(diào)中
// g++-10 -I. echo_server.cpp
class session : public std::enable_shared_from_this< session > {
public:
session(tcp::socket socket) : socket_(std::move(socket)) {}
void start() { do_read(); }
private:
void do_read() {
auto self(shared_from_this());
socket_.async_read_some(asio::buffer(data_, max_length),
[this, self](...) { if (!ec) do_write(length);});
}
void do_write(std::size_t length) {
auto self(shared_from_this());
asio::async_write(socket_, asio::buffer(data_, length),
[this, self](...) { if (!ec) do_read(); });
}
tcp::socket socket_;
enum { max_length = 1024 };
char data_[max_length];
};
class server {
public:
server(asio::io_context& io_context, short port)
: acceptor_(io_context, tcp::endpoint(tcp::v4(), port)) { do_accept(); }
private:
void do_accept() {
acceptor_.async_accept([this](std::error_code ec, tcp::socket socket) {
if (!ec) std::make_shared< session >(std::move(socket))- >start();
do_accept();
});
}
tcp::acceptor acceptor_;
};
int main(int argc, char* argv[]) {
asio::io_context io_context;
server s(io_context, std::atoi(argv[1]));
io_context.run();
return 0;
}
協(xié)程版 Echo
ASIO 1.19.2 已經(jīng)支持 C++20 的協(xié)程,作者 github 倉庫中已經(jīng)包含了協(xié)程的使用示例(coroutines_ts),下面是其中 echo_server 的示例,使用支持 C++20 標(biāo)準(zhǔn)的編譯器可直接編譯運(yùn)行
// g++-10 -fcoroutines -std=c++20 -I. echo_server.cpp
awaitable< void > echo(tcp::socket socket) {
try {
char data[1024];
size_t n = 0;
for (;;) {
n = co_await socket.async_read_some(asio::buffer(data), use_awaitable);
co_await async_write(socket, asio::buffer(data, n), use_awaitable);
}
} catch (std::exception& e) { ... }
}
awaitable< void > listener() {
auto executor = co_await this_coro::executor;
tcp::acceptor acceptor(executor, {tcp::v4(), 55555});
for (;;) {
tcp::socket socket = co_await acceptor.async_accept(use_awaitable);
co_spawn(executor, echo(std::move(socket)), detached);
}
}
int main() {
asio::io_context io_context(1);
asio::signal_set signals(io_context, SIGINT, SIGTERM);
signals.async_wait([&](auto, auto) { io_context.stop(); });
co_spawn(io_context, listener(), detached);
io_context.run();
return 0;
}
-
Linux
+關(guān)注
關(guān)注
87文章
11345瀏覽量
210403 -
編程
+關(guān)注
關(guān)注
88文章
3637瀏覽量
93988 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4346瀏覽量
62977 -
線程
+關(guān)注
關(guān)注
0文章
505瀏覽量
19758
發(fā)布評論請先 登錄
相關(guān)推薦
Linux開發(fā)_采用線程處理網(wǎng)絡(luò)請求
談?wù)?b class='flag-5'>協(xié)程的那些事兒

異步程序到底是什么
協(xié)程和線程有什么區(qū)別
如何使用多線程和異步操作等并發(fā)設(shè)計(jì)方法來最大化程序的性能
linux多線程編程課件
linux多線程編程開發(fā)

單線程也能開發(fā)異步任務(wù)?ACE JS框架到底是如何做到的





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論