 芯片的變革機會在哪里?算力芯片如何突圍?
芯片的變革機會在哪里?算力芯片如何突圍?
01.成熟賽道,后進趕超先進,很難
1.1 CPU的江湖恩仇
上世紀70年代,Intel發明了CPU。通過對CPU的持續投入,Intel逐漸獲得了市場的優勢,并逐漸構建起了自己的x86生態,這包括外圍的硬件合作伙伴、BIOS等固件開發、操作系統軟件、工具鏈以及應用軟件生態等等。
RISC是一個失敗的例子。X86是CISC架構,隨著CISC指令的復雜度越來越高,越來越難以控制,RISC架構逐漸興起。RISC架構處理器提倡簡化指令集設計、固定指令長度、統一指令編碼格式、加速常用指令。RISC架構成為很多處理器的首選,并且也成為了許多計算機教材的經典CPU設計案例。但即便如此,在市場競爭上,RISC架構仍然輸給了CISC。
安騰是Intel自己的一個失敗的例子。安騰是Intel于2001年推出的64位架構的CPU處理器。雖然是Intel的親兒子,雖然是功能強大的64位CPU架構,雖然安騰的架構和微架構設計非常優秀,但因為安騰和x86的不兼容,完全一個新的生態,也不可避免的走向了失敗。最后成就了AMD64的成功。
ARM的成功,更多源于商業模式。最開始,ARM自研的處理器性能都非常差,其自研的處理器性能通常是低于一些巨頭客戶自研的ARM架構CPU。但因為ARM是一個中立的CPU架構和IP供應商,很多巨頭愿意扶持著它向前邁進。最后在智能手機時代,ARM大獲成功。有了資金實力之后,ARM后續CPU的性能才逐漸趕上并且部分超越了自己的巨頭客戶。
RISC-V,后起之秀,明日之星,未來可能的成功也是依賴于更優的商業模式。跟ARM當年的處境類似,目前的RISCv性能和生態都要弱于x86和ARM,但因為更優的商業模式(完全開源開放的,并且得到廣泛共識的免費的處理器),其發展也是相當迅猛。
1.2 NVIDIA,從十年磨一劍到市值萬億
傳統的GPU是圖形加速卡,本質上是眾多各種領域各種場景加速卡中的一員。除了GPU之外,其他眾多的各類加速卡,幾乎沒有成功的案例。GPU之所以最終成功,來自于00年代NVIDIA的轉型:一方面,是GPU從傳統的圖像加速卡,改造成面向并行計算的GPGPU;此外,為了降低開發的門檻,把更多的資源投向了CUDA,并且對外宣稱自己是一家軟件公司。
即便策略正確,最終的成功驗證也差不多是十年之后。CUDA的最早期版本是在2005年前后發布的,直到2012年深度學習的崛起,GPU才開始真正脫穎而出,也直到2018年大模型興起,以及2013年ChatGPT的火爆,才把NVIDIA推上了最高的神壇。
1.3 簡單總結
經常有企業喊出口號是“要做中國的xxx”,但“學我者生,像我者死”,芯片是一個國際化的市場,全球競爭,這樣亦步亦趨的學習巨頭企業的做法,無異于“邯鄲學步”。
在成熟的賽道,后進如果靠模仿先進前進,那必然無法成功。后進需要有差異化,有創新,有優勢,才有可能成功。并且,后進要想成功,其難度遠高于先進者當年的難度。
02.技術的變革,是最后進趕超先進的關鍵時機
國產新能源汽車,是后進趕超先進的經典案例。據中國汽車工業協會整理的海關總署數據顯示,2023年上半年,汽車整車出口234.1萬輛,同比增長76.9%;1~7月,汽車出口總值3837.3億元,增長118.5%。中國汽車出口首次超過日本,躍居世界首位。新能源汽車是中國汽車出口的核心增長點。2023年1~6月出口新能源車80萬輛,同比增長105%。
在成熟賽道,先進具有技術優勢、市場優勢、專利優勢、品牌優勢等等,后進趕超先進很難。但如果是技術的變革期,后進就可以在新的技術領域提前布局,讓雙方站在同一個起跑線,以此來獲得“公平”競技的機會,從而有可能實現超越。國產汽車,就是抓住了新能源和智能汽車這一波浪潮,迅速地達到了汽車出口量全球第一。
那么,芯片的變革機會在哪里?
03.AGI大模型的挑戰
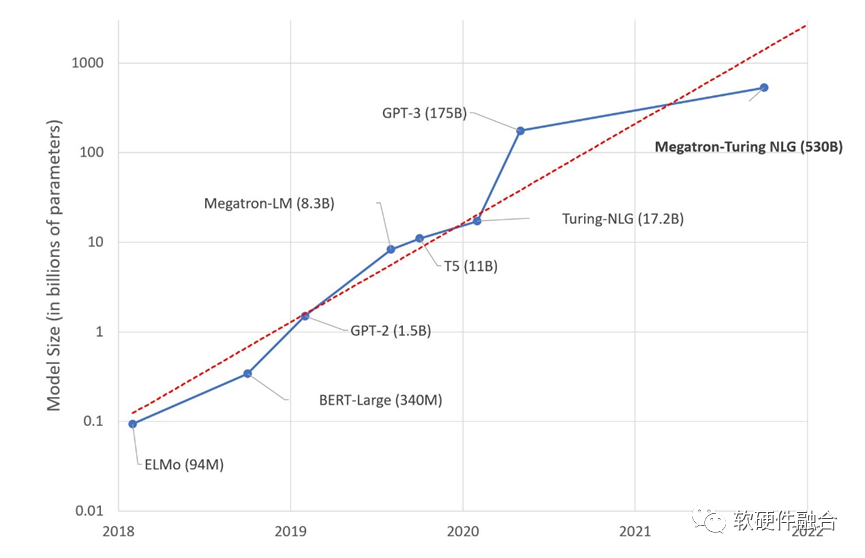
2023年初的AI大模型,“不約而同”的參數規模停留在千億級,為什么?
核心的原因在于,這是目前的GPU計算集群所能支撐的算力上限:
一方面,單芯片算力已經瓶頸,算力增長極度緩慢。
另一方面,受限于目前的服務器以CPU為中心的架構約束,以及網絡的交互效率所限,集群規模也已經達到了上限。
還有一個很重要的原因,就是算力的建設和運營成本,也已經達到了一個天文數字。
目前CPU性能早已瓶頸,GPU性能即將見頂并且成本高昂,而AI芯片太過于專用,不適用于快速變化的模型算法/算子和業務邏輯。
如何解決?我們也可以給一個簡單的答案:
一方面,持續不斷的Scale up,通過更多的處理器內聚,數量級的提升單芯片的性能;
另一方面,持續不斷地增強芯片的內部交互(打破已有的以CPU為中心的架構)和外部交互(增強高性能網絡)。數量級的提升集群中服務器的數量。
此外,大芯片需要通用。能否實現足夠的通用性,是大芯片能夠大規模落地的最重要因素。
還有一個很重要的,要通過一些機制,數量級的降低算力的成本。
04.芯片工藝的快速進步
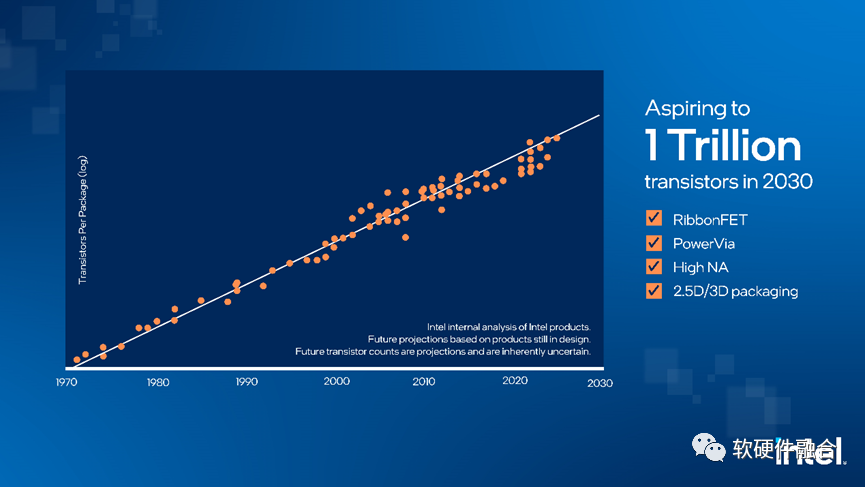
工藝持續進步,Chiplet先進封裝也越來越成熟。從2D的工藝到3D的封裝再到Chiplet的4D封裝,芯片的底層實現技術仍在快速發展。
目前的大算力芯片,通常在500億晶體管左右。Intel的規劃是在2030年,達到1萬億晶體管。這意味著,相比目前的芯片,計算規模再提升20倍。
如此大規模的晶體管資源,我們該如何更好地利用?
05.算力芯片變革的歷史機遇
5.1 系統架構創新
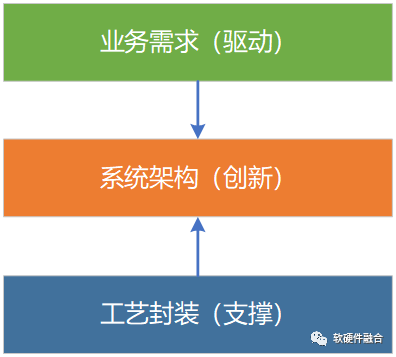
一方面是需求牽引,一方面是工藝支撐,兩方面的因素,都需要我們在系統架構層次,做更多的創新。
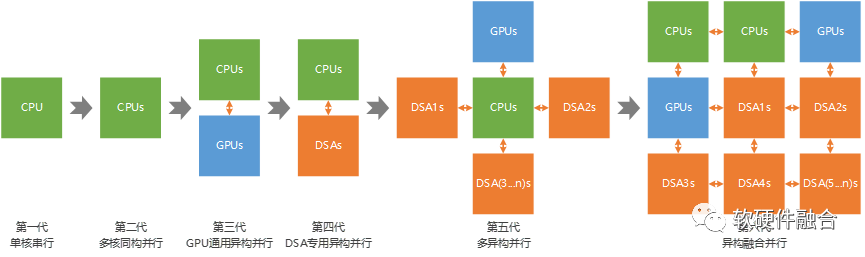
從單核到多核、從同構到異構,從單異構到多異構,再從多異構到異構融合,是一個計算架構從簡單到復雜的繼承并發展的過程。

芯片設計規模越來越大,單芯片集成更多架構的處理器成為一種非常常見的設計。這種多異構混合計算架構,Intel稱為超異構計算。在2023年9月份發布的《異構融合計算技術白皮書》中,采用了更嚴謹更準確的一種叫法,“異構融合計算”。深刻揭示了多異構混合計算的關鍵,在于異構處理器之間的協同和融合。
5.2 大芯片如何能夠通用?
系統規模越來越大,變化越來越快,從而使得在大算力芯片,通用性比性能更重要。而定制的加速算力芯片覆蓋場景少,生命周期短,難以大規模落地。
此外,相比專用,通用是更高級的能力。通用計算,需要從眾多需求中提煉和拆解出通用的部分和組件,通過軟件編程,靈活地組合出用戶所需的形形色色的功能。并且還要實現性能和靈活性的兼顧。
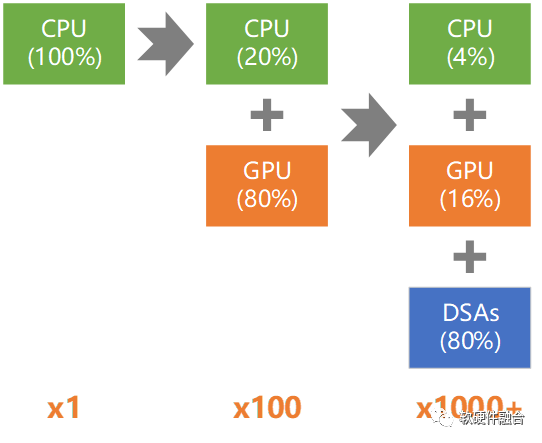
那么,如何實現通用?能夠通用的本質原因是什么?
系統規模越大,“二八定律”特征越明顯。這樣,我們可以把確定性的共性的部分硬件加速實現,相對不確定的個性的部分通過軟件編程實現。

在六代計算架構的基礎上,增加“通用”約束,變成三代通用計算架構:
第一代單核和第二代多核合并成CPU同構。
取消專用的DSA異構計算階段,異構計算僅保留GPU的通用異構。
多異構要想成功,就需要融合;異構融合要想成功,就需要通用。因此,從終局思維思考,最終可落地的方案,會是通用的異構融合計算。
5.3從單兵作戰到團隊協作
受限于先進工藝,我們無法實現最強算力的芯片。但我們可以通過更多資源的協作,來實現更強的群體智能:
方法一,異構融合。通過異構融合的計算架構創新,實現更多處理器核心的協同和融合。可以在工藝落后1-2代的情況下,實現單個芯片的算力更優。
方法二,算力網絡。通過算力網絡、東數西算,實現跨集群的算力調度和算力協同,可以實現算力資源的高效利用。
方法三,智能網聯。通過終端的智能網聯,實現云端協同。清華的***院士提出的智能網聯汽車中國方案,強調車(終端)、路(MEC接入)、邊、云的深度協同,在單體算力有限的情況下,可以實現更智能化的用戶服務體驗。
方法四,云網邊端融合。更龐大算力節點,更高性能更低延遲的網絡,更強大的算力基礎設施,實現更強大的宏觀數字系統。
5.4 總結
從異構到異構融合計算,計算架構的變革,給了我們“彎道超車”的時機;歷史機遇稍縱即逝,需要快馬加鞭,加大投入。
抓住計算架構變革的歷史時機,實現算力芯片的彎道超車!
編輯:黃飛
-
新能源汽車
+關注
關注
141文章
10625瀏覽量
100130 -
cpu
+關注
關注
68文章
10904瀏覽量
213026 -
NVIDIA
+關注
關注
14文章
5076瀏覽量
103726 -
RISC
+關注
關注
6文章
465瀏覽量
83874 -
算力芯片
+關注
關注
0文章
47瀏覽量
4584
原文標題:算力芯片,如何突圍?
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
半導體產業未來10年的機會在哪里?
移動互聯網的機會在哪里?馬云和比爾·蓋茨看好哪些行業?
Mini LED量產競爭激烈,華燦突圍優勢在哪?
國產手術機器人彎道超車的機會在哪里?
芯片的用途主要用在哪里
大算力芯片如何加速上車
存算一體或將成為國產芯片算力彎道超車機會
ai芯片和算力芯片的區別
大算力芯片里的HBM,你了解多少?

高算力芯片:未來科技的加速器?

揭秘芯片算力:為何它如此關鍵?

算力調度的基礎知識






 工商網監
工商網監
評論