 基于大語言模型的共情回復生成:實證研究和改進
基于大語言模型的共情回復生成:實證研究和改進
0. 省流版
對以ChatGPT為代表的LLMs在共情回復生成上的表現進行了全面的實證研究,LLMs在現有的基準數據集上,對比以往的SOTA模型,表現極其優越。
在LLMs的基礎上,針對性地提出了三種改進方法(語義相似的上下文學習、兩階段交互生成以及與知識庫相結合),實驗證明了它們的有效性。
探索了GPT-4模擬人類評估員的可能性。
1. 動機介紹
共情對話(Empathetic Dialogue)有利于構建助人的AI。共情回復生成(Empathetic Response Generation)主要涉及理解用戶的經歷和感受,并生成適當的回復。而使用對話系統提供共情回復具有訪問方便、無時間限制等優點。圖1展示了一個共情對話示例。

圖1 共情對話示例
先前大多數研究者基于可靠的理論知識設置了精細的模型,但是,使用的基礎模型大多是小規模的。最近,大語言模型(Large Language Models, LLMs)以優異的性能被廣泛應用于自然語言處理。尤其是ChatGPT的出現引起了學術界和工業界極大的關注和興趣,它在多種任務中表現出了非凡的能力,特別是對話生成。這些LLMs在大量語料上訓練,包含了豐富的知識。在具體任務中,甚至無需微調,采用一些gradient-free技術(例如,In-context Learning, ICL)依舊可以獲得出色的性能。因此,有必要實證探索LLMs在具體領域的表現,因為解決問題的方式可能會發生極大變化。已經有一些初步的嘗試[1,2]將LLMs應用于共情回復生成。然而,他們的方法主要關注預訓練或對訓練數據進行微調,以及簡單地探索單個LLM的能力。
為了研究LLMs在共情回復生成中的能力,本工作在現有共情對話的基準數據集上對LLMs的性能進行實證研究。我們首先采用在零樣本(zero-shot)和少樣本(few-shot)上下文學習設置下的LLMs和大量基線模型進行比較。令人驚喜的是,僅僅是上下文學習設置下的GPT-3.5系列LLMs的表現已經全面超越了最先進的模型。這表明LLMs帶來的范式轉變也適用于共情對話。進一步,在最佳性能設置的LLM基礎上,我們提出了三種可嘗試的方法來繼續提升其性能。具體來說,分別是借助語義相似性的ICL、兩階段交互生成以及和知識庫相結合的方法來進行改進。大量的自動和人工評估實驗表明,LLMs可以從我們提出的方法中受益,從而產生更具共情性、連貫性和信息性的回復。此外,人工評估一直是共情對話中極其重要的一環,但其昂貴且耗時。鑒于LLMs在共情回復生成上的杰出表現,我們嘗試利用GPT-4來模擬人類評估員對結果進行評測。Spearman和Kendall-Tau相關性結果表明GPT-4有潛力代替人類評估員。
2. 方法部分
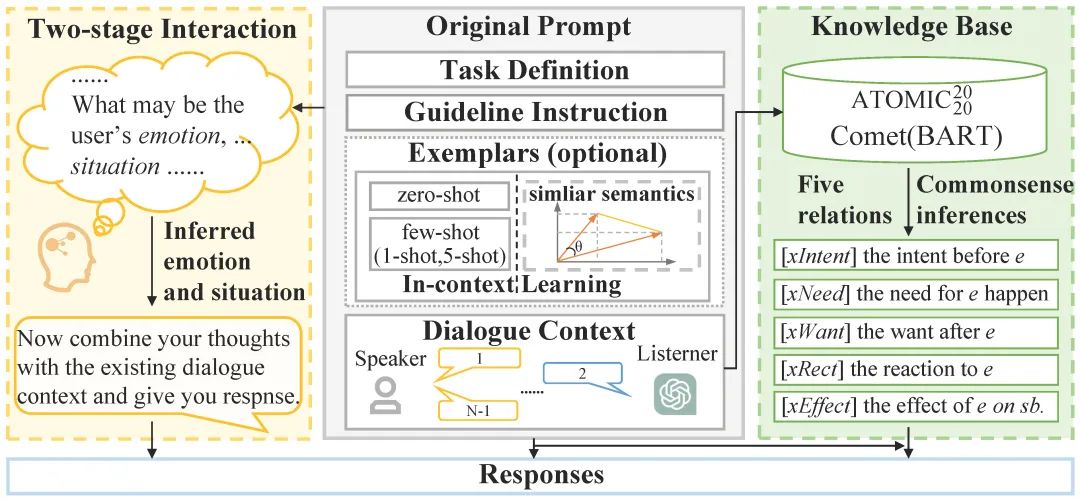
圖2 整體架構圖
我們提出的方法整體如圖2所示,其中包括共情回復生成的統一模板和三種改進方法。左邊部分描述了借助兩階段交互生成的改進,中間部分展示了所設計的統一模板的組成部分和借助語義相似的上下文學習進行的改進,右邊部分說明了通過知識庫進行改進的細節。
2.1 初步探索
LLMs具有上下文學習(ICL)的能力,通過向LLMs提供任務指令和一些示例,它們可以在不進行微調的情況下執行相關任務。這種能力極大地緩解了對訓練數據的需求。我們首先探索了LLMs在零樣本ICL和少樣本ICL設置上的表現。由于不同的提示(Prompts)可能會影響性能,我們在設計提示時盡量保持一致的風格。我們設計的共情對話提示模板由以下部分組成:

其中,Task Definition是研究者對該任務的標準定義,Guideline Instruction是我們期望模型遵循的指令,Exemplars是用于幫助模型更好地理解任務的對話示例,Dialogue Context是說話者和傾聽者的歷史對話,最后一句是說話者的話語,我們的目標是讓對話系統生成傾聽者的下一輪話語。
2.2 進階探索
2.2.1 借助語義相似的上下文學習的提升
正如[3]所言,少量精心挑選的數據也可以提高LLMs的性能。我們合理推測,除了示例的數量,示例的質量也會對模型的性能產生影響。因此,在選擇示例時,我們從訓練集中選擇與現階段對話上下文語義最接近的示例。我們將對話內容拼接成一個長句,用句子編碼器獲得向量表示,通過兩個句子的向量表示的余弦相似性衡量語義相似性:
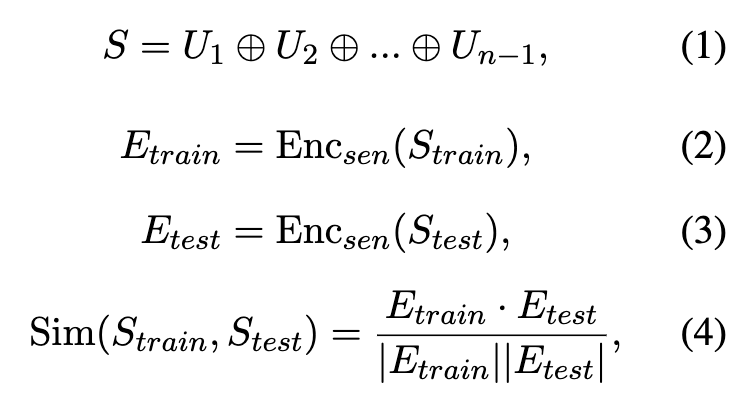
2.2.2 借助兩階段交互生成的提升
在共情對話任務的設置中,傾聽者需要推斷說話者的情緒是什么,以及是什么情境導致了這種情緒,從而提供合適的回復。受開放域對話中一些多階段方法的啟發,結合共情對話的特點,我們與LLMs進行兩階段對話交互。具體來說,在第一階段,我們先讓LLMs推測用戶的情緒狀態和經歷的情境,在第二階段,結合推斷的結果生成最終回復。我們設計的兩階段提示大致如下:

模型在第一階段生成的推測可以用來分析不同的關鍵因素(情緒和情境)對最終結果的影響,提高可解釋性。
2.2.3 借助知識庫的提升
僅僅從歷史對話中推斷說話者的情緒和情境是不夠的,一個直接的證據是,在基準數據集中,最終回復與歷史對話幾乎沒有非停用詞的重疊[4]。因此對話系統需要更多的外部信息來進行共情對話,而我們人類天然具備一定的外部信息。LLMs通過權重存儲了大量知識,因此在執行具體任務時,如何更好地激發相關知識對于效果的提升影響很大。一種解決方案是針對具體任務微調LLMs,但這個過程通常需要昂貴的硬件、時間和訓練數據。受最近的共情對話工作[5]的啟發,我們考慮用常識知識庫來增強對話上下文,動態利用外部相關知識來刺激LLMs編碼的相關知識,從而產生更共情的回復。具體來說,我們采用BART版本的COMET,其在常識知識庫ATOMIC2020上訓練得到,可以為看不見的實體生成具有代表性的常識推斷,其中,我們選用了五種關系(xIntent, XNeed, xWant, xEffect, xReact)[6]。我們根據不同的對話上下文動態拼接得到的相對應的常識推理,從而豐富輸入表示,激發LLMs的相關知識,來產生更合適的回復:
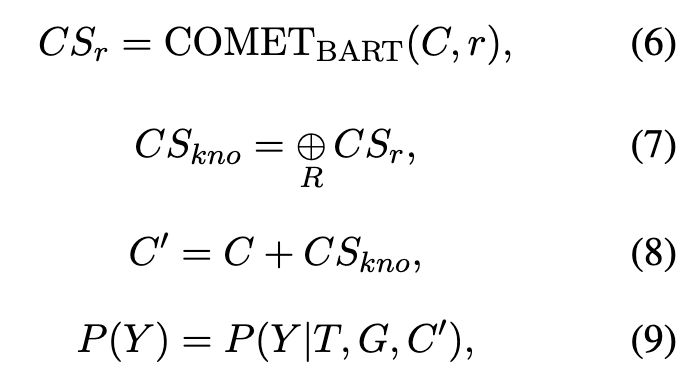
3. 實驗與分析
3.1 實驗設置
數據集。我們采用大型英文多輪共情對話基準數據集EMPATHETICDIALOGUES[7]。數據集中的每個對話都有一個情緒標簽(總共32種類型)和與情緒標簽對應的情境。說話者討論他們的處境,傾聽者試圖理解說話者的感受并給出合適的回復。
評估相關。我們進行了自動評估和人工評估。人工評估包含指標評分和指標層面的偏好測試。
其他。 本文涉及到的LLMs有關實驗,有償求助了身處國外的朋友進行操作。
3.2 結果分析
3.2.1 初步探索結果
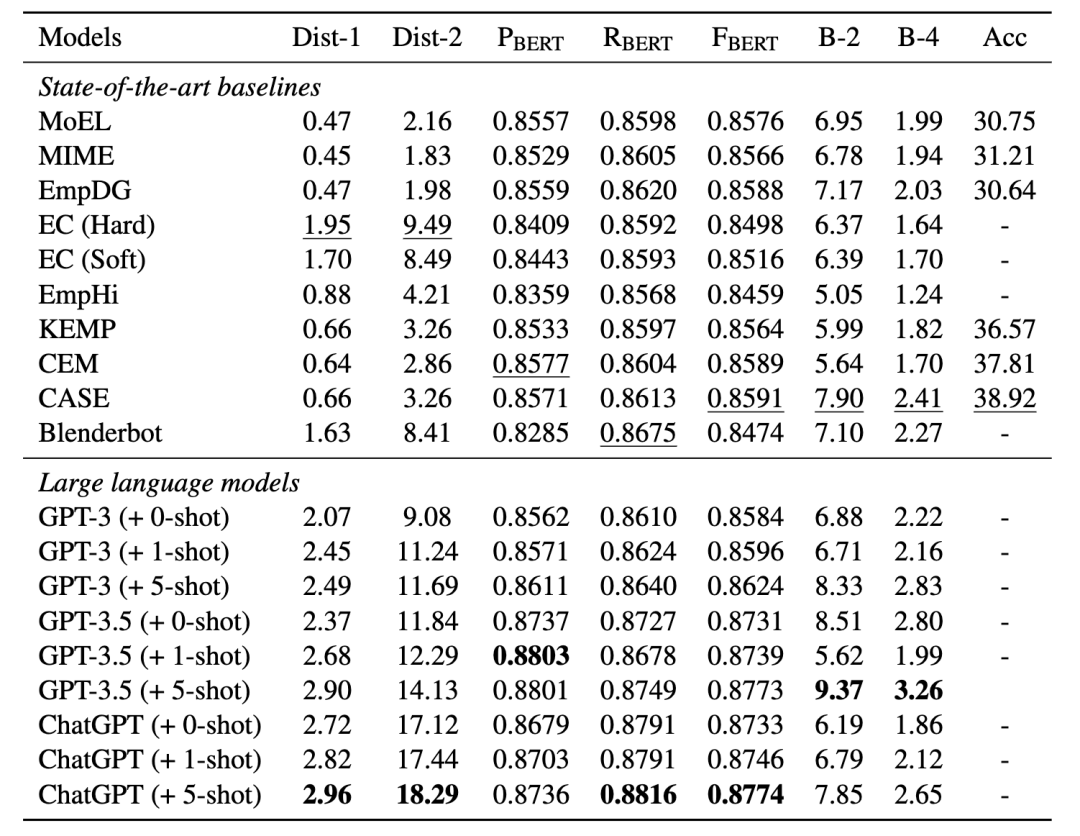
表1 LLMs和基線模型的自動評估結果
表1顯示了LLMs和基線模型的自動評估結果,其中,LLMs顯著優于現有的SOTA (state-of-the-art) 模型,并在所有的自動指標上實現了顯著提升,尤其是diversity。對于DIST-1/2,LLMs分別獲得了51.8%[=(2.96-1.95)/1.95]和92.7%[=(18.29-9.49)/9.49]的提升,這表明LLMs在多樣的語言表達中具有顯著優勢(主要是unigrams和bigrams)。就BERTScore和BLEU而言,LLMs分別實現了2.1%[=(2.6+1.6+2.1)/3]和26.95%[=(18.6+35.3)/2]的平均改善。這強調了LLMs具備強大的上下文能力,可以快速應用于未見的特定任務。此外,我們觀察到示例數量和多樣性的性能呈正相關,這表明示例的增加可能會影響LLMs的語言習慣。
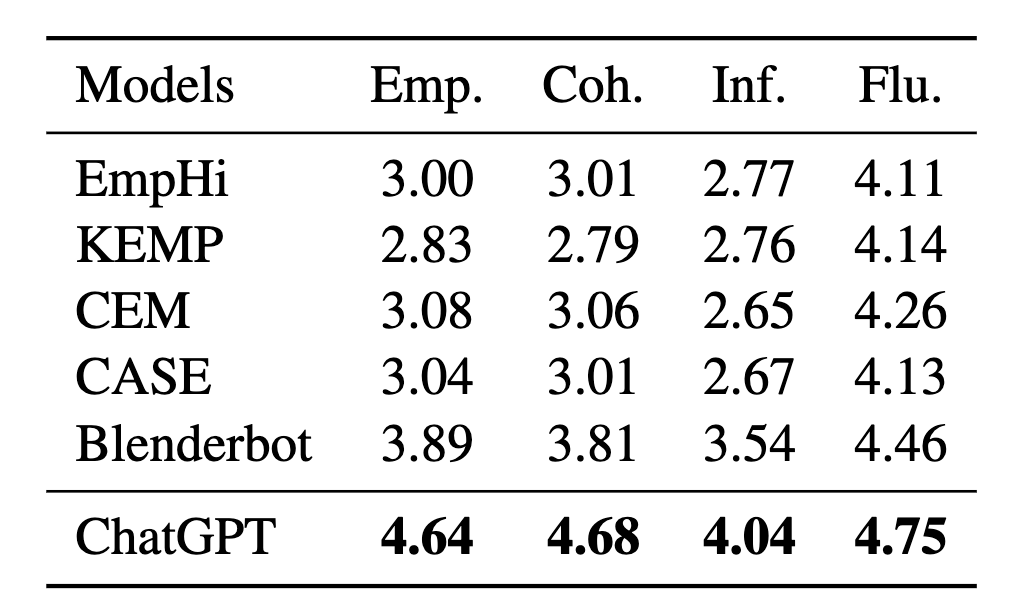
表2 ChatGPT和對比的基線模型的人工評分結果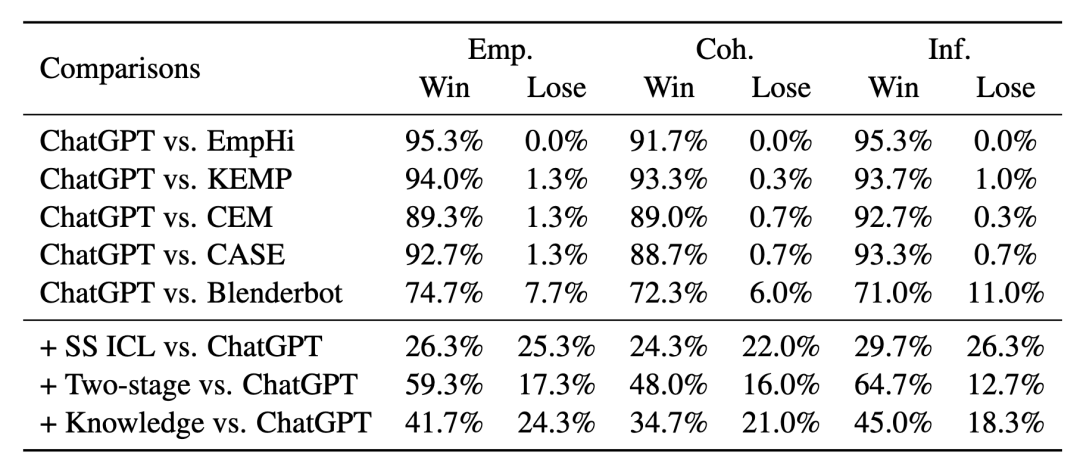
表3 指標層面的人類偏好測試結果
在人工評估中,我們選擇在大多數自動指標上領先的ChatGPT (+5-shot) 作為LLMs的代表。表2和表3的上部分分別列出了人工評分和指標層面的偏好測試的結果。我們觀察到ChatGPT在所有人工指標上也極大地優于基線模型,這進一步證明了LLMs在產生共情、連貫和具備信息量的回復上的優越性。此外,我們注意到基線模型的分數低于以往研究中的數值。這是因為ChatGPT的卓越表現相對提高了標準。在偏好測試中,超過70%的情況下,人類評估員更喜歡ChatGPT生成的回復,這一現象也可以驗證上述觀點。
3.2.2 進階探索結果
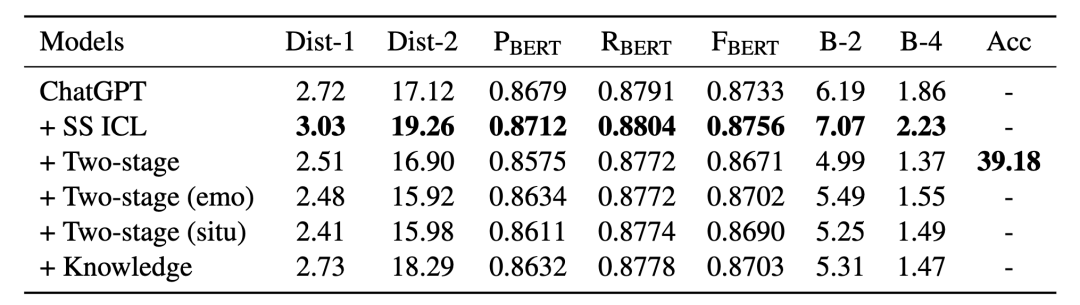
表4 進階探索的自動評估結果
進階探索的實驗結果如表4和表3的下部分所示。總的來說,我們的改進方法生成的回復更容易被人類評估員接受。這些結果驗證了上下文學習示例的選擇、兩階段交互生成和上下文相關知識的增強的有效性。
3.2.3LLM模擬人類評估員的分析
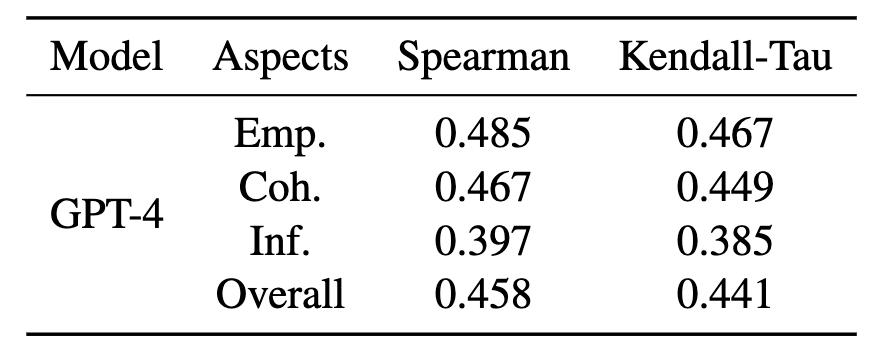
表5 人類評估員和GPT-4在不同方面的Spearman和Kendall-Tau相關性
LLMs在生成共情回復中展現了杰出的性能,自然地,我們想到是否可以使用LLMs模擬人類評估員來評估其他模型的性能。與人類評估員相比,LLMs具有更低的成本和更短的時間消耗。為此,我們考慮更強大的GPT-4作為評估器,在相同的設置下進行偏好測試。我們采用Spearman和Kendall-Tau相關來評估人類評估員和GPT-4的表現,結果如表5所示。我們觀察到,GPT-4在各個方面都取得了較好的結果(參考[8]),這表明LLMs有潛力模擬人類評估員。
4. 結論
在這項工作中,我們實證研究了LLMs在共情回復生成方面的表現,并提出了三種改進方法。自動和人工評估結果表明,LLMs顯著優于最先進的模型,并驗證了我們提出的改進方法的有效性。我們的工作可以有助于更深入地理解和應用LLMs進行共情對話,并為類似的任務提供一些見解。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3667瀏覽量
135242 -
GPT
+關注
關注
0文章
360瀏覽量
15505 -
ChatGPT
+關注
關注
29文章
1568瀏覽量
8057 -
LLM
+關注
關注
0文章
299瀏覽量
400
原文標題:EMNLP'23 | 基于大語言模型的共情回復生成:實證研究和改進
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的應用
為什么生成模型值得研究
一種結合回復生成的對話意圖預測模型

使用DeepSpeed和Megatron驅動MT-NLG語言模型
NVIDIA NeMo最新語言模型服務幫助開發者定制大規模語言模型
大型語言模型能否捕捉到它們所處理和生成的文本中的語義信息

大模型對話系統的內功與外功






 工商網監
工商網監
評論