") 英偉達發(fā)布最新AI芯片H200:性能提升2倍,成本下降50%
英偉達發(fā)布最新AI芯片H200:性能提升2倍,成本下降50%
周一,半導體行業(yè)巨頭英偉達發(fā)布了新一代人工智能芯片 H200,旨在為各種 AI 模型提供訓練和部署支持。
H200 芯片是目前用于訓練最先進的大型語言模型 H100 芯片的升級版,搭載了 141GB 的內存,專注于執(zhí)行“推理”任務。在進行推理或生成問題答案時,H200 的性能相比 H100 提升了 1.4 至 1.9 倍不等。
性能拉升無極限?
據英偉達官網消息,基于英偉達的“Hopper”架構,H200 是該公司首款采用 HBM3e 內存的芯片。這種內存速度更快、容量更大,使其更適用于大語言模型。相信過去一年來花大價錢購買過 Hopper H100 加速器的朋友都會為自己的沖動而后悔。為了防止囤積了大量 H100 的客戶們當場掀桿而起,英偉達似乎只有一種辦法:把配備 141 GB HBM3e 內存 Hopper 的價格,定為 80 GB 或 96 GB HBM3 內存版本的 1.5 到 2 倍。只有這樣,才能讓之前的“冤種”們稍微平衡一點。

下圖所示,為 H100 與 H200 在一系列 AI 推理工作負載上的相對性能比較:
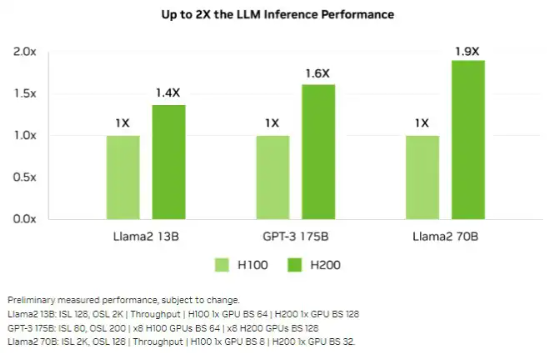
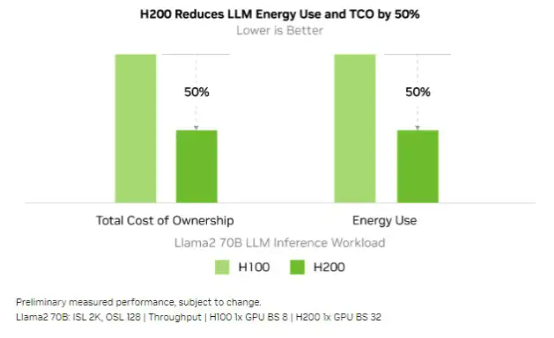
可以看到,相較于 H100,H200 的性能提升最主要體現(xiàn)在大模型的推理性能表現(xiàn)上。在處理 Llama 2 等大語言模型時,H200 的推理速度比 H100 提高了接近 2 倍。 很明顯,如果能在相同的功率范圍之內實現(xiàn) 2 倍的性能提升,就意味著實際能耗和總體擁有成本降低了 50%。所以從理論上講,英偉達似乎可以讓 H200 GPU 的價格與 H100 持平。
得益于 Tansformer 引擎、浮點運算精度的下降以及更快的 HBM3 內存,今年起全面出貨的 H100 在 GPT-3 175B 模型的推理性能方面已經較 A100 提升至 11 倍。而憑借更大、更快的 HBM3e 內存,無需任何硬件或代碼變更的 H200 則直接把性能拉升至 18 倍。 哪怕是與 H100 相比,H200 的性能也提高至 1.64 倍,而這一切都純粹源自內存容量和帶寬的增長。
想象一下,如果未來的設備擁有 512 GB HBM 內存和 10 TB/ 秒帶寬,性能又會來到怎樣的水平?大家愿意為這款能夠全力施為的 GPU 支付多高的價錢?最終產品很可能要賣到 6 萬甚至是 9 萬美元,畢竟很多朋友已經愿意為目前未能充分發(fā)揮潛力的產品掏出 3 萬美元了。
英偉達需要順應 大內存的發(fā)展趨勢
出于種種技術和經濟方面的權衡,幾十年來各種處理器在算力方面往往配置過剩,但相應的內存帶寬卻相對不足。實際內存容量,往往要視設備和工作負載需求而定。
Web 基礎設施類負載和那些相對簡單的分析 / 數據庫工作負載大多能在擁有十幾條 DDR 內存通道的現(xiàn)代 CPU 上運行良好,但到了 HPC 模擬 / 建模乃至 AI 訓練 / 推理這邊,即使是最先進 GPU 的內存帶寬和內存容量也相對不足,因此無法實質性提升芯片上既有向量與矩陣引擎的利用率。于是乎,這些 GPU 只能耗費大量時間等待數據交付,無法全力施展自身所長。
所以答案就很明確了:應該在這些芯片上放置更多內存!但遺憾的是,高級計算引擎上的 HBM 內存成本往往比芯片本身還要高,因此添加更多內存自然面臨很大的阻力。特別是如果添加內存就能讓性能翻倍,那同樣的 HPC 或 AI 應用性能將只需要一半的設備即可達成,這樣的主意顯然沒法在董事會那邊得到支持。這種主動壓縮利潤的思路,恐怕只能在市場供過于求,三、四家廠商爭奪客戶預算的時候才會發(fā)生。但很明顯,現(xiàn)狀并非如此。
好在最終理性還是占據了上風,所以英特爾才推出了“Sapphire Rapids”至強 SP 芯片變體,配備有 64 GB HBM2e 內存。雖然每核分配到的內存才剛剛超過 1 GB,但總和內存帶寬卻可達到每秒 1 TB 以上。對于各類對內存容量要求較低的工作負載,以及主要受帶寬限制、而非容量限制的工作負載(主要體現(xiàn)在 HPC 類應用當中),只需轉向 HBM2e 即可將性能提升 1.8 至 1.9 倍。于是乎,Sapphire Rapids 的 HBM 變體自然成為 1 月份產品發(fā)布中最受關注、也最具現(xiàn)實意義的內容之一。英特爾還很有可能在接下來推出的“Granite Rapids”芯片中發(fā)布 HBM 變體,雖然號稱是以多路復用器組合列(MCR)DDR5 內存為賣點,但這種內存擴容的整體思路必將成為 Granite Rapids 架構中的重要部分。
英偉達之前在丹佛舉行的 SC23 超級計算大會上宣布推出新的“Hopper”H200 GPU 加速器,AMD 則將于 12 月 6 日發(fā)布面向數據中心的“Antares”GPU 加速器系列——包括搭載 192 GB HBM3 內存的 Instinct MI300X,以及擁有 128 GB HBM3 內存的 CPU-GPU 混合 MI300A。很明顯,英偉達也必須順應這波趨勢,至少也要為 Hopper GPU 配備更大的內存。
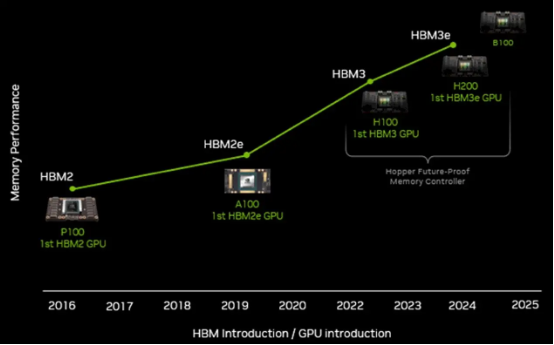
英偉達在一個月前的財務會議上放出技術路線圖時,我們都知道 GH200 GPU 和 H200 GPU 加速器將成為“Blackwell”GB100 GPU 及 B100 GPU 之前的過渡性產品,而后者計劃在 2024 年內發(fā)布。人們普遍認為 H200 套件將擁有更大的內存,但我們認為英偉達應該想辦法提升 GPU 引擎本身的性能。事實證明,通過擴大 HBM 內存并轉向速度更快的 HBM3e 內存,英偉達完全可以在現(xiàn)有 Hopper GPU 的設計之上帶來顯著的性能提升,無需添加更多 CUDA 核心或者對 GPU 超頻。 明年還有新的大冤種?
身處摩爾定律末期,在計算引擎中集成 HBM 內存所帶來的高昂成本已經嚴重限制了性能擴展。英偉達和英特爾在 Sapphire Rapids 至強 Max CPU 上都公布了相應的統(tǒng)計數字。而無論英偉達接下來的 Blackwell B100 GPU 加速器具體表現(xiàn)如何,都基本可以斷定會帶來更強大的推理性能,而且這種性能提升很可能來自內存方面的突破、而非計算層面的升級。下面來看 B100 GPU 在 GPT-3 175B 參數模型上的推理能力提升:
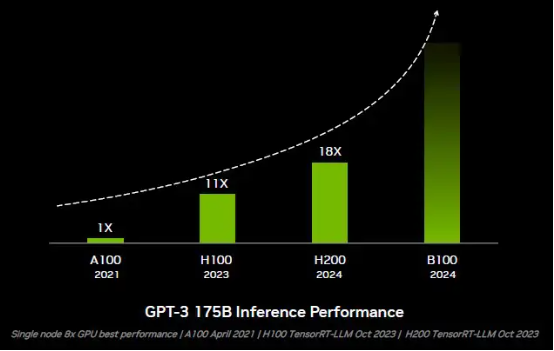
因此,從現(xiàn)在到明年夏季之間砸錢購買英偉達 Hopper G200 的朋友,肯定又要被再割一波“韭菜”(當然,這也是數據中心持續(xù)發(fā)展下的常態(tài))。
最后:H200 GPU 加速器和 Grace-Hopper 超級芯片將采用更新的 Hopper GPU,配備更大、更快的內存,且計劃于明年年中正式上市。也正因為如此,我們才認定 Blackwell B100 加速器雖然會在明年 3 月的 GTC 2024 大會上首次亮相,但實際出貨恐怕要等到 2024 年底。當然,無論大家決定為自己的系統(tǒng)選擇哪款產品,最好現(xiàn)在就提交訂單,否則到時候肯定會一無所獲。
-
人工智能
+關注
關注
1796文章
47683瀏覽量
240325 -
英偉達
+關注
關注
22文章
3848瀏覽量
91995 -
AI芯片
+關注
關注
17文章
1906瀏覽量
35219
原文標題:囤H100的都成了大冤種!英偉達發(fā)布最新AI芯片H200:性能提升2倍,成本下降50%
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦





 工商網監(jiān)
工商網監(jiān)
評論