 使用 NVIDIA IGX Orin 開發者套件在邊緣部署大語言模型
使用 NVIDIA IGX Orin 開發者套件在邊緣部署大語言模型
隨著大語言模型(LLM)的功能日益強大,減少其計算需求的技術也日趨成熟,由此產生了兩個引人注目的問題:能夠在邊緣運行和部署的最先進的 LLM 是什么?現實世界中的應用如何才能充分利用這些成果?
即使采用較低的 FP16 精度,運行像 Llama 270b 這樣最先進的開源 LLM,也需要超過 140 GB 的 GPU 顯存(VRAM)(700 億參數 x 2 字節 = FP16 精度下的 140 GB,還要加上 KV 緩存所增加的顯存需求)。對于大多數開發者和較小的公司來說,要獲得這么大的 VRAM 并不容易。此外,無論是由于成本、帶寬、延遲還是數據隱私問題,應用程序的特定要求可能會排除使用云計算資源托管 LLM 這一選項。
NVIDIA IGX Orin 開發者套件和 NVIDIA Holoscan SDK 可應對這些挑戰,將 LLM 的強大功能帶到邊緣。NVIDIA IGX Orin 開發者套件可提供一個滿足工業和醫療環境需求的工業級邊緣 AI 平臺。內置的 NVIDIA Holoscan 是一套能夠協調數據移動、加速計算、實時可視化和 AI 推理的 SDK。
該平臺讓開發者能夠將開源 LLM 添加到邊緣 AI 流式傳輸工作流和產品中,為實時 AI 傳感器處理帶來了新的可能性,同時確保敏感數據保持在 IGX 硬件的安全邊界內。
適用于實時流式傳輸的開源 LLM
近來開源 LLM 的快速發展已經改變了人們對實時流式傳輸應用可能性的看法。之前,人們普遍認為,任何需要類似人類能力的應用,都只能由數據中心規模的企業級 GPU 驅動的閉源 LLM 實現。但由于近期新型開源 LLM 的性能暴漲,Falcon、MPT、Llama 2 等模型現在已經可以替代閉源黑盒 LLM。
有許多可能的應用可以利用這些邊緣的開源模型,其中大多都涉及到將流式傳輸傳感器數據提煉為自然語言摘要。可能出現的應用有:讓家屬隨時了解手術進展的手術實時監控視頻、為空中交通管制員匯總最近的雷達交流情況,以及將足球比賽的實況解說轉換成另一種語言。
隨著強大開源 LLM 的出現,一個致力于提高這些模型準確性,并減少運行模型所需計算量的社群應運而生。這個充滿活力的社群活躍在“Hugging Face 開放式 LLM 排行榜”上,該排行榜經常會更新最新的頂尖性能模型。
豐富的邊緣 AI 功能
NVIDIA IGX Orin 平臺在利用激增的可用開源 LLM 和支持軟件方面具有得天獨厚的優勢。
強大的 Llama 2 模型有 NVIDIA IGX Orin 平臺安全措施的加持,并可以無縫集成到低延遲的 Holoscan SDK 管道中,因此能夠應對各種問題和用例。這一融合不僅標志著邊緣 AI 能力的重大進步,而且釋放了多個領域變革性解決方案的潛力。
其中一個值得關注的應用能夠充分利用新發布的 Clinical Camel,這是一個經過微調的 Llama 2 70B 模型變體,專門用于醫學知識研究。基于該模型創建本地化的醫療聊天機器人,可確保敏感的患者數據始終處于 IGX 硬件的安全邊界內。對隱私、帶寬或實時反饋要求極高的應用程序是 IGX 平臺真正的亮點所在。
想象一下,輸入患者的病歷,并向機器人查詢類似病例,獲得有關難以診斷的患者的新洞察,甚至為醫療專業人員篩選出不會與當前處方產生相互作用的藥物——所有這些都可以通過 Holoscan 應用實現自動化。該應用可將醫患互動的實時音頻轉換成文本,并將其無縫地輸入到 Clinical Camel 模型中。

圖 1. Clinical Camel 模型
根據示例對話生成的臨床筆記
NVIDIA IGX 平臺憑借對低延遲傳感器輸入數據的出色優化,將 LLM 的功能擴展到純文本應用之外。醫療聊天機器人已經足以展現出它的強大,而 IGX Orin 開發者套件更強大的地方在于,它能夠無縫集成來自各種傳感器的實時數據。
IGX Orin 專為邊緣環境打造,可以處理來自攝像頭、激光雷達傳感器、無線電天線、加速度計、超聲探頭等的流信息。這一通用性使各種先進的應用能夠無縫地將 LLM 的強大功能與實時數據流融合。
在集成到 Holoscan 操作系統后,這些 LLM 可顯著增強 AI 傳感器處理管道的能力和功能。具體示例如下:
多模態醫療助手:增強 LLM 的能力,使其不僅能夠解釋文本,還能解釋醫學影像,如 Med-Flamingo 等項目所驗證的那樣,它能解釋核磁共振、X 射線和組織學影像。
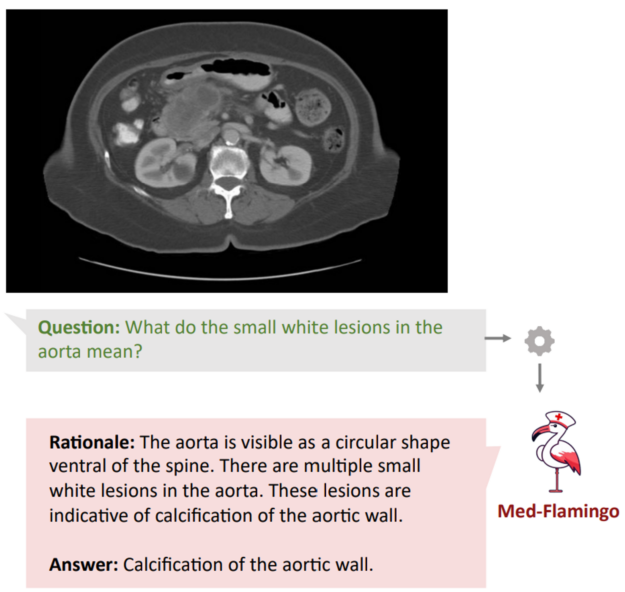
圖 2. LLM 可解釋文本
并從醫學影像中獲得相關洞察
信號情報(SIGINT):從通信系統和雷達捕獲的實時電子信號中獲得自然語言摘要,提供銜接技術數據與人類理解的深入洞察。
手術病例記錄生成:將內窺鏡視頻、音頻、系統數據和患者記錄傳輸到多模態 LLM 中,生成綜合全面的手術病例,并自動上傳到患者的電子病歷中。
智慧農業:使用土壤傳感器監測 pH 值、濕度和營養水平,使 LLM 能夠為優化種植、灌溉和病蟲害防治策略提供可操作的深入洞察。
用于教育、故障診斷或提高生產力的軟件開發助手是 LLM 的另一個新穎用例。這些模型可以幫助開發者開發更高效的代碼和詳盡的文檔。
Holoscan 團隊最近發布了 HoloChat,這個 AI 驅動的聊天機器人在 Holoscan 的開發過程中充當開發者的“助手”。它能對有關 Holoscan 和編寫代碼的問題做出類似人類的回答。詳情請訪問GitHub上的nvidia-holoscan/holohub:https://github.com/nvidia-holoscan/holohub/tree/main/applications/holochat_local
HoloChat 的本地托管模式旨在為開發者提供與常見的閉源聊天機器人相同的優勢,同時杜絕了將數據發送到第三方遠程服務器處理所帶來的隱私和安全問題。
通過模型量化
實現最佳精度與內存使用
隨著大量開源模型通過 Apache 2、MIT 和商業許可發布,任何人都可以下載并使用這些模型權重。但對絕大多數開發者來說,“可以”并不意味著“可行”。
模型量化提供了一種解決方案。通過用低精度數據類型(int8 和 int4)來表示權重和激活值,而不是高精度數據類型(FP16 和 FP32),模型量化減少了運行推理的計算和內存成本。
然而,從模型中移除這一精度確實會導致模型的準確性下降。但研究表明,在內存預算既定的情況下,當參數以 4 位精度存儲時,使用盡可能大且與內存匹配的模型才能實現最佳的 LLM 性能。更多詳情,參見 4 位精度案例:k 位推理縮放法則:https://arxiv.org/abs/2212.09720
因此,Llama 2 70B 模型在以 4 位量化實施時,達到了精度和內存使用之間的最佳平衡,將所需的 RAM 降低至 35 GB 左右。對于規模較小的開發團隊甚至個人來說,這一內存需求是可以達到的。
開源 LLM 打開新的開發機遇
由于能夠在商用硬件上運行最先進的 LLM,開源社區中出現了大量支持本地運行的新程序庫,并提供能夠擴展這些模型功能的工具,而不僅僅是預測句子的下一個單詞。
您可以通過 Llama.cpp、ExLlama 和 AutoGPTQ 等程序庫量化自己的模型,并在本地 GPU 上快速運行推理。不過,是否量化模型完全取決于您自己的選擇,因為 HuggingFace.co/models 中有大量量化模型可供使用。這在很大程度上要歸功于像 /TheBloke 這樣的超級用戶,他們每天都會上傳新的量化模型。
這些模型本身就帶來了令人興奮的開發機會,更不用說還能使用大量新建程序庫中的附加工具來對其進行擴展,使它們更加強大。例如:
-
LangChain:一個在 GitHub 上獲得 58,000 顆星評分的程序庫,提供從實現文檔問答功能的矢量數據庫集成,到使 LLM 能夠瀏覽網頁的多步驟代理框架等所有功能。
-
Haystack:支持可擴展的語義搜索。
-
Oobabooga:一個用于在本地運行量化 LLM 的網絡用戶界面。
只要您有 LLM 用例,就可以使用一個開源庫來提供您所需的大部分功能。
開始在邊緣部署 LLM
使用 NVIDIA IGX Orin 開發者套件在邊緣部署最先進的 LLM,可以解鎖尚未被挖掘的開發機會。如要開始部署,請先查看"使用 IGX Orin 在邊緣部署 Llama 2 70B 模型"綜合教程,其詳細介紹了在 IGX Orin 上創建簡單聊天機器人應用:https://github.com/nvidia-holoscan/holohub/tree/main/tutorials/local-llama
該教程演示了如何在 IGX Orin 上無縫集成 Llama 2,并指導您使用 Gradio 開發 Python 應用。這是使用本文中提到的任何優質 LLM 庫的第一步。IGX Orin 提供的彈性、非凡性能和端到端的安全性,使開發者能夠圍繞在邊緣運行的先進 LLM,構建創新的 Holoscan 優化應用。
GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會議中心舉行,線上大會也將同期開放。點擊“閱讀原文”或掃描下方海報二維碼,立即注冊 GTC 大會。
原文標題:使用 NVIDIA IGX Orin 開發者套件在邊緣部署大語言模型
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3847瀏覽量
91968
原文標題:使用 NVIDIA IGX Orin 開發者套件在邊緣部署大語言模型
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA Jetson Orin Nano開發者套件的新功能

NVIDIA發布小巧高性價比的Jetson Orin Nano Super開發者套件
NVIDIA 推出高性價比的生成式 AI 超級計算機

Arm推出GitHub平臺AI工具,簡化開發者AI應用開發部署流程
Orin芯片的編程語言支持
NVIDIA RTX AI套件簡化AI驅動的應用開發
Mistral AI與NVIDIA推出全新語言模型Mistral NeMo 12B
基于AX650N/AX630C部署端側大語言模型Qwen2
NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業軟件支持
NVIDIA將全球數百萬開發者轉變為生成式 AI 開發者
NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業軟件支持,實現邊緣實時醫療、工業和科學 AI 應用

NVIDIA NIM 革命性地改變模型部署,將全球數百萬開發者轉變為生成式 AI 開發者

NVIDIA與微軟擴展合作,幫助開發者更快構建和部署AI應用
英特爾開發套件『哪吒』在Java環境實現ADAS道路識別演示 | 開發者實戰

【轉載】英特爾開發套件“哪吒”快速部署YoloV8 on Java | 開發者實戰






 工商網監
工商網監
評論