 SQL改寫消除相關子查詢實踐
SQL改寫消除相關子查詢實踐
一、子查詢
GaussDB (DWS) 根據子查詢在 SQL 語句中的位置把子查詢分成了子查詢、子鏈接兩種形式。
子查詢 SubQuery:對應于查詢解析樹中的范圍表 RangeTblEntry,更通俗一些指的是出現在 FROM 語句后面的獨立的 SELECT 語句。
子鏈接 SubLink:對應于查詢解析樹中的表達式,更通俗一些指的是出現在 where/on 子句、targetlist 里面的語句。
1.1 非相關子查詢
子查詢的執行不依賴于外層父查詢的任何屬性值。這樣子查詢具有獨立性,可獨自求解,形成一個子查詢計劃先于外層的查詢求解。示例:
select t1.c1,t1.c2
from t1
where t1.c1 in (
select c2
from t2
where t2.c2 IN (2,3,4)
);
1.2 相關子查詢
子查詢的執行依賴于外層父查詢的一些屬性值(如下列示例 t2.c1 = t1.c1 條件中的 t1.c1)作為內層查詢的一個 AND-ed 條件。這樣的子查詢不具備獨立性,需要和外層查詢按分組進行求解。
select t1.c1,t1.c2
from t1
where t1.c1 in (
select c2
from t2
where t2.c1 = t1.c1 AND t2.c2 in (2,3,4)
);
二、調優實戰
2.1 案例:
UPDATE t1 SET (c1,c2)=( SELECT COALESCE(t2.c1, t1.c2),c2 FROM t2 WHERE t1.i1 = t2.i1 -- 相關標量子查詢 );其中子查詢 SELECT COALESCE (t2.c1, t1.c2),c2 FROM t2 WHERE t1.i1 = t2.i1 依賴于外層父查詢的 t1 表,因此屬于相關子查詢。執行計劃:
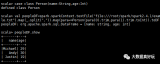
QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------------------------------------------- id | operation | A-time | A-rows | E-rows | E-distinct | Peak Memory | E-memory | A-width | E-width | E-costs ----+-----------------------------------------------+----------------+--------+--------+------------+----------------+----------+---------+---------+--------- 1 | -> Streaming (type: GATHER) | 8.998 | 0 | 1 | | 24KB | | | 17 | 9.83 2 | -> Update on public.t1 | [0.086, 0.096] | 2 | 2 | | [308KB, 308KB] | | | 17 | 9.74 3 | -> Seq Scan on public.t1 | [0.058, 0.074] | 2 | 2 | | [32KB, 32KB] | 1MB | | 17 | 3.73 4 | -> Result [3, SubPlan 1] | [0.033, 0.034] | 2 | 10 | | [16KB, 16KB] | 1MB | | 6 | 1.36 5 | -> Materialize | [4.167, 4.458] | 20 | 10 | | [16KB, 16KB] | 16MB | [24,24] | 6 | 1.36 6 | -> Streaming(type: BROADCAST) | [4.105, 4.406] | 10 | 10 | | [48KB, 48KB] | 2MB | | 6 | 1.33 7 | -> Seq Scan on public.t2 | [0.013, 0.013] | 5 | 5 | | [32KB, 32KB] | 1MB | | 6 | 1.02 8 | -> Result [3, SubPlan 2] | [0.006, 0.021] | 2 | 10 | | [16KB, 16KB] | 1MB | | 6 | 1.36 9 | -> Materialize | [0.055, 0.061] | 20 | 10 | | [16KB, 16KB] | 16MB | [24,24] | 6 | 1.36 10 | -> Streaming(type: BROADCAST) | [0.034, 0.040] | 10 | 10 | | [48KB, 48KB] | 2MB | | 6 | 1.33 11 | -> Seq Scan on public.t2 | [0.005, 0.009] | 5 | 5 | | [32KB, 32KB] | 1MB | | 6 | 1.02
2.2 子查詢消除
改寫策略就是解除子查詢與父查詢依賴關系,改寫方案參考:
UPDATE t1 SET (c1,c2)=(t3.c1,t3.c2) FROM ( SELECT t2.i1,COALESCE(t2.c1, t1.c2) c1,t2.c2 FROM t1,t2 WHERE t1.i1 = t2.i1 )t3 WHERE t1.i1 = t3.i1;改寫后,子查詢獨立,不再依賴父查詢中元素。執行計劃:
QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------------------------------------------------- id | operation | A-time | A-rows | E-rows | E-distinct | Peak Memory | E-memory | A-width | E-width | E-costs ----+-----------------------------------------------------+----------------+--------+--------+------------+----------------+----------+---------+---------+--------- 1 | -> Streaming (type: GATHER) | 13.141 | 0 | 1 | | 24KB | | | 33 | 10.56 2 | -> Update on public.t1 | [6.242, 6.362] | 2 | 2 | | [308KB, 308KB] | | | 33 | 10.47 3 | -> Streaming(type: RESTORE) | [6.186, 6.310] | 2 | 2 | | [48KB, 48KB] | 2MB | | 33 | 4.46 4 | -> Nested Loop (5,11) | [4.082, 4.801] | 2 | 2 | | [32KB, 32KB] | 1MB | | 33 | 4.44 5 | -> Streaming(type: BROADCAST) | [3.804, 4.541] | 4 | 4 | | [48KB, 48KB] | 2MB | | 27 | 2.36 6 | -> Nested Loop (7,8) | [2.972, 4.267] | 2 | 2 | | [32KB, 32KB] | 1MB | | 27 | 2.20 7 | -> Seq Scan on public.t1 | [0.010, 0.011] | 2 | 2 | | [16KB, 16KB] | 1MB | | 14 | 1.01 8 | -> Materialize | [2.724, 4.055] | 6 | 4 | | [16KB, 16KB] | 16MB | [28,28] | 13 | 1.17 9 | -> Streaming(type: BROADCAST) | [2.667, 4.008] | 4 | 4 | | [48KB, 48KB] | 2MB | | 13 | 1.17 10 | -> Seq Scan on public.t1 | [0.008, 0.012] | 2 | 2 | | [16KB, 16KB] | 1MB | | 13 | 1.01 11 | -> Materialize | [0.018, 0.022] | 12 | 5 | | [16KB, 16KB] | 16MB | [32,32] | 14 | 2.03 12 | -> Seq Scan on public.t2 | [0.007, 0.009] |
審核編輯:劉清
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
SQL
+關注
關注
1文章
774瀏覽量
44250
原文標題:數倉調優實踐丨 SQL改寫消除相關子查詢
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
在Delphi中動態地使用SQL查詢語句
在Delphi中動態地使用SQL查詢語句在一般的數據庫管理系統中,通常都需要應用SQL查詢語句來提高程序的動態特性。下面介紹如何在Delphi中實現這種功能。在Delphi中,使用
發表于 05-10 11:10
SQL語言實現數據庫記錄的查詢
絕大部分DBMS都支持SQL語言,LabVIEW數據庫工具包實現的實質也是基于SQL語言,它為不熟悉SQL語言的用戶把SQL語言封裝了起來,以方便他們使用。所以,我們也可以利用
發表于 07-01 21:25
SQL查詢慢的原因分析總結
sql 查詢慢的48個原因分析 1、沒有索引或者沒有用到索引(這是查詢慢最常見的問題,是程序設計的缺陷)。 2、I/O吞吐量小,形成了瓶頸效應。 3、沒有創建計算列導致查詢不優化。 4
發表于 03-08 11:58
?0次下載
SQL語句怎么搞定跨實例查詢?
這個SQL的語法完全兼容MySQL,只是在From的表名前面帶上DBLink。所以,業務方只需要使用DMS跨數據庫查詢SQL便可輕松解決拆庫之后的跨庫查詢難題,業務基本無需改造。
發表于 11-03 10:22
?5796次閱讀
SQL子查詢優化是怎么回事
子查詢 (Subquery)的優化一直以來都是 SQL 查詢優化中的難點之一。 關聯子查詢的基本執行方式類似于 Nested-Loop,但是這種執行方式的效率常常低到難以忍受。 當數據

簡述Django查詢生成原始SQL查詢的3種方法
我們使用Django ORM使查詢數據庫變得非常容易,但是如果我們知道幕后發生了什么或對某些Django查詢執行了什么SQL查詢,對我們提升查詢
Spark SQL的概念及查詢方式
的SQL查詢。 Hive的繼承,Spark SQL通過內嵌的hive或者連接外部已經部署好的hive案例,實現了對hive語法的繼承和操作。 標準化的連接方式,Spark SQL可
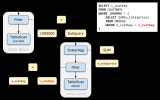
一文終結SQL子查詢優化
子查詢(Subquery)的優化一直以來都是 SQL 查詢優化中的難點之一。關聯子查詢的基本執行方式類似于 Nested-Loop,但是這種執行方式的效率常常低到難以忍受。
sql查詢語句大全及實例
SQL(Structured Query Language)是一種專門用于數據庫管理系統的標準交互式數據庫查詢語言。它被廣泛應用于數據庫管理和數據操作領域。在本文中,我們將為您詳細介紹SQL查
sql語句where條件查詢
SQL是一種用于管理和操作關系型數據庫的編程語言。其中,WHERE子句是用于過濾查詢結果的重要部分。通過WHERE條件,我們可以指定一系列條件,以僅返回滿足條件的記錄。本文將探討WHERE條件查詢
oracle執行sql查詢語句的步驟是什么
Oracle數據庫是一種常用的關系型數據庫管理系統,具有強大的SQL查詢功能。Oracle執行SQL查詢語句的步驟包括編寫SQL語句、解析
查詢SQL在mysql內部是如何執行?
我們知道在mySQL客戶端,輸入一條查詢SQL,然后看到返回查詢的結果。這條查詢語句在 MySQL 內部到底是如何執行的呢?本文跟大家探討一下哈,我們先來看下MySQL基本架構~





 工商網監
工商網監
評論