 詳細分析算力網絡的發展
詳細分析算力網絡的發展
2023年12月底,由國家發展改革委、國家數據局、中央網信辦、工業和信息化部、國家能源局五部門聯合印發的《關于深入實施“東數西算”工程 加快構建全國一體化算力網的實施意見》正式公布。
算力網絡是未來數字經濟發展的核心基礎設施。要想實現算力網絡的偉大愿景,還有非常多的底層技術挑戰需要解決。
接下來若干篇系列文章,“軟硬件融合”公眾號將從技術的視角,詳細分析算力網絡的發展。
本篇是系列文章的第一篇,算力提升綜述。
01.宏觀算力綜述
算力和性能的區別在哪里?性能是一個微觀話題,通常的說法是“芯片的性能”,較少說“芯片的算力”(隨著算力的概念深入人心,也有不少人采用單芯片算力的算法)。同時,算力是一個宏觀概念,比如評價一個數據中心,通常則采用“算力”這個說法,很少會用“性能”這個說法。
總之,算力和性能本質上是一體的,區別在于性能是微觀概念,算力是宏觀概念。那么算力和性能之間的聯系是什么?
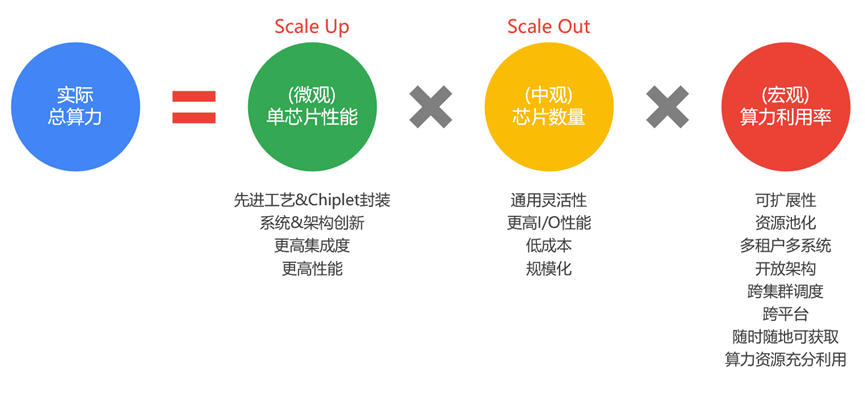
如上圖所示,我們定性分析,可以在性能和算力之間構建一個關聯的公式。從上述公式可以看到,要想提升宏觀的實際總算力,可以通過三個方法:
方法一,Scale Up方式,提升單芯片的性能。一方面底層先進工藝和Chiplet封裝支撐,另一方面越來越多的大算力場景需求,都驅動著在系統架構和微架構方面的創新,來實現單芯片層次更高的性能。這是算力提升最本質的做法。
方法二,Scale Out方式,提升芯片落地的規模/數量。通過增加芯片落地規模的方式提升總算力,比較好理解。挑戰在于,如何讓芯片更好地增加數量?芯片要想大規模落地:需要覆蓋非常多的業務場景和業務迭代,這就需要芯片具有非常高的通用性;此外,芯片需要支持更大規模的集群計算。
方法三,則是提高算力利用率。提升算力利用率有很多方法,例如,資源擴展性、資源池化、開放架構等等。算力網絡,是提升算力利用率的綜合解決方案。
本系列文章聚焦算力網絡,因此,篇幅分配會有很大不同。本篇文章中,將簡要介紹提升算力的三種方式。
02.如何提升單芯片性能?

定性的分析,一個芯片的性能有三個維度:
維度一,指令復雜度。依據指令復雜度,典型的處理器引擎分為CPU、協處理器、GPU、FPGA、DSA和ASIC六大類。理論上,指令復雜度越高,性能越好。但實際上,需要考慮系統的通用性,以及目標工作任務的靈活性特征,來選擇合適的處理器引擎。
維度二,運行頻率。運行頻率提升,主要是先進工藝,以及更復雜的流水線設計。
維度三,并行度。提高并行度比較好理解,并行也主要有同構并行、(兩個處理器的)異構并行和(三個以上)更多異構的并行。
這三個維度里,指令復雜度提升和運行頻率提升,都受到到各種因素的制約,真正對性能影響最大的則是并行度。提升并行度,不是簡單的復制,而是需要全面考慮系統工作任務特征,尋找合適的處理引擎,實現復雜的并行計算:
同構并行,僅指CPU同構并行(其他處理器無法單獨存在,需要CPU協助),摩爾定律已經失效,CPU并行性能有局限。
異構并行,指CPU+其他加速處理器的并行計算,異構并行是兩類處理器的協同計算。
異構融合并行,指的是CPU+兩種以上不同類型或子類型的處理器組成的計算架構。因為處理器增多,則需要考慮各個處理器之間的協同問題。因此,異構融合計算,中心在于處理器之間的深度協作和融合。
03.如何提升芯片的落地規模?
通用靈活性
芯片只有大規模落地,才能顯著地提升宏觀算力;不能落地芯片,即使性能再高,與宏觀算力的提升也毫無意義。芯片要想大規模落地,一定是要覆蓋非常多的業務場景,以及非常多的業務迭代。這樣,勢必需要芯片具有非常高的通用靈活性。 同時,芯片大規模落地,成本也是一個非常重要的因素。跟小芯片相比,大算力芯片的成本主要是前期的研發投入的均攤成本,芯片實際的生產成本反而占比相對較少。只有實現了相對通用的芯片設計,才能覆蓋更多的場景和迭代,才能攤薄成本。成本下降之后,反過來,進一步促進芯片的大規模落地。
高性能網絡
與此同時,大算力芯片,需要支持大規模集群和跨集群的計算。更多計算節點組成的集群/跨集群計算,內部流量占據絕大部分。 以目前流行的大模型計算集群為例,其東西向(內部)流量占比超過96%,南北向(外網)流量占比僅有3%左右。并且,隨著集群規模的進一步擴大,南北向流量占比仍在進一步減少。 此外,隨著系統規模的擴大,南北向的流量也是逐漸增加的。兩相疊加,需要個體的芯片的網絡帶寬指數級提升,同時需要支持高效的內網和外網高性能網絡。 總之,只有實現了足夠的通用靈活性,以及高性能網絡,才能支撐更高性能更高效率的超大規模的集群/跨集群計算,才能真正支撐宏觀算力的顯著提升,與此同時降低算力的成本。
04.如何提升算力利用率?
如果每個計算節點都是孤島,即使某一個節點算力利用率很高,但更多的節點可能處于閑置或者低利用率狀態,宏觀地看,其算力利用率必然很低。要想真正提升算力利用率,首先勢必需要把計算節點池化,形成算力資源池,才好談高利用率的問題。
我們來系統分析一下如何有效地提升算力利用率。
資源可擴展性
資源可擴展性是一個非常重要的前提條件。 以CPU為例,通過虛擬化,一個物理的CPU核可以分為數以百計的邏輯CPU核,一個邏輯核可以當作CPU的最小粒度;同時,一個CPU芯片有數十個甚至上百個CPU核,常見的服務器通常有1-8個CPU芯片,并且還有眾多服務器組成的計算集群。因此,CPU是可以從1個邏輯核擴展到成千上萬的邏輯核的。這就是CPU極致可擴展性的體現。 其他的資源,如各類GPU、DSA等各類加速器計算資源、內存(Memory)資源、網絡I/O資源、存儲(Storage)I/O資源等。這些資源,也需要像CPU一樣,具有非常好的擴展性。
資源池化
資源具有足夠好的可擴展性,物理的資源通過合適粒度進行邏輯切分,并且跨物理資源、跨芯片、跨計算節點,甚至跨集群的資源資源可以組成一個整體,最終形成統一的宏觀資源池。只有形成足夠好的可擴展性才能支持靈活的資源池化和資源的靈活分配。
多租戶多系統
多租戶多系統是云計算非常重要的特征,通過多租戶多系統實現資源的共享和成本分攤,以此來提高算力利用率和降低成本。
開放架構
隨著CPU的性能瓶頸,越來越多的異構算力成為算力提升的主力。即使某個處理器具有足夠高的可擴展性,但一種架構的資源,就意味著一個獨立的資源池。這樣,多樣性的異構算力,會導致架構和生態的碎片化。通過開放架構,可以盡可能地實現架構的收斂,才能最大化地發揮資源池化的價值。
跨集群調度
算力網絡,最核心的價值在于把非常多的各種計算集群連接到一起。因此跨集群的資源共享和業務調度是必然要支持的能力。算力網絡,需要實現跨不同的集群、跨不同的數據中心、跨云網邊端。
跨平臺
隨著異構的資源越來越多,從一個計算階段遷移到本集群或者其他集群其他計算節點的時候,它的資源種類不一定和當前節點資源一致。這樣,對業務能力跨不同架構處理器運行提出了更高的要求。比如,業務可以跨x86、ARM和riscv CPU處理器運行,業務還可以跨CPU、GPU、DSA處理器運行,等等。
便利性,隨時隨地可獲取
相比傳統自建機房,云計算已經實現了算力的方便獲取。但還不夠。隨著AI大模型、自動駕駛、元宇宙XR等各類大算力場景越來越多,對算力的多樣性要求也越來越大,云端算力、多層次的邊緣算力,甚至更加便利的終端算力,都需要納入算力網絡的范疇,提供宏觀的算力資源整合方案,方便用戶隨時隨地輕松獲取。 總結一下。通過上述這些方式,以及其他可能的上面沒有提到的方式,來實現宏觀算力資源的充分利用,從而為客戶提供極致成本的海量算力。
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19406瀏覽量
231163 -
芯片
+關注
關注
456文章
51166瀏覽量
427204 -
網絡
+關注
關注
14文章
7599瀏覽量
89241 -
算力
+關注
關注
1文章
1012瀏覽量
14954
原文標題:算力網絡系列文章(一):算力提升綜述
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論