 如何高效處理LMEM中的數據?這篇文章帶你學會!
如何高效處理LMEM中的數據?這篇文章帶你學會!
Weight Reorder是TPU-MLIR的一個pass(參考TPU-MLIR編譯流程圖),其完成了對部分常量數據的Layout變化和合并。本文介紹其中Convlotion Kernel的Reorder行為以及合并Bias機制,幫助大家理解Conv2D.cpp代碼中的原理。
在SOPHON硬件中,存儲單元多種多樣,包括LMEM(本地存儲器)、SMEM(靜態SRAM)和GMEM(全局存儲器,即片外DDR存儲)。其中,LMEM作為一種高速SRAM,因其靠近執行單元(EU)而提供了高帶寬和低延遲的訪問特性。為了實現這種高速訪問,SOPHON BM1684X處理器將LMEM劃分為64個分區,每個分區均可由相應的NPU單元獨立訪問。每個NPU包含多個EU,并且在不同的計算類型下,EU處理的數據各不相同。NPU無法跨分區訪問數據。下圖展示了這種結構的概覽。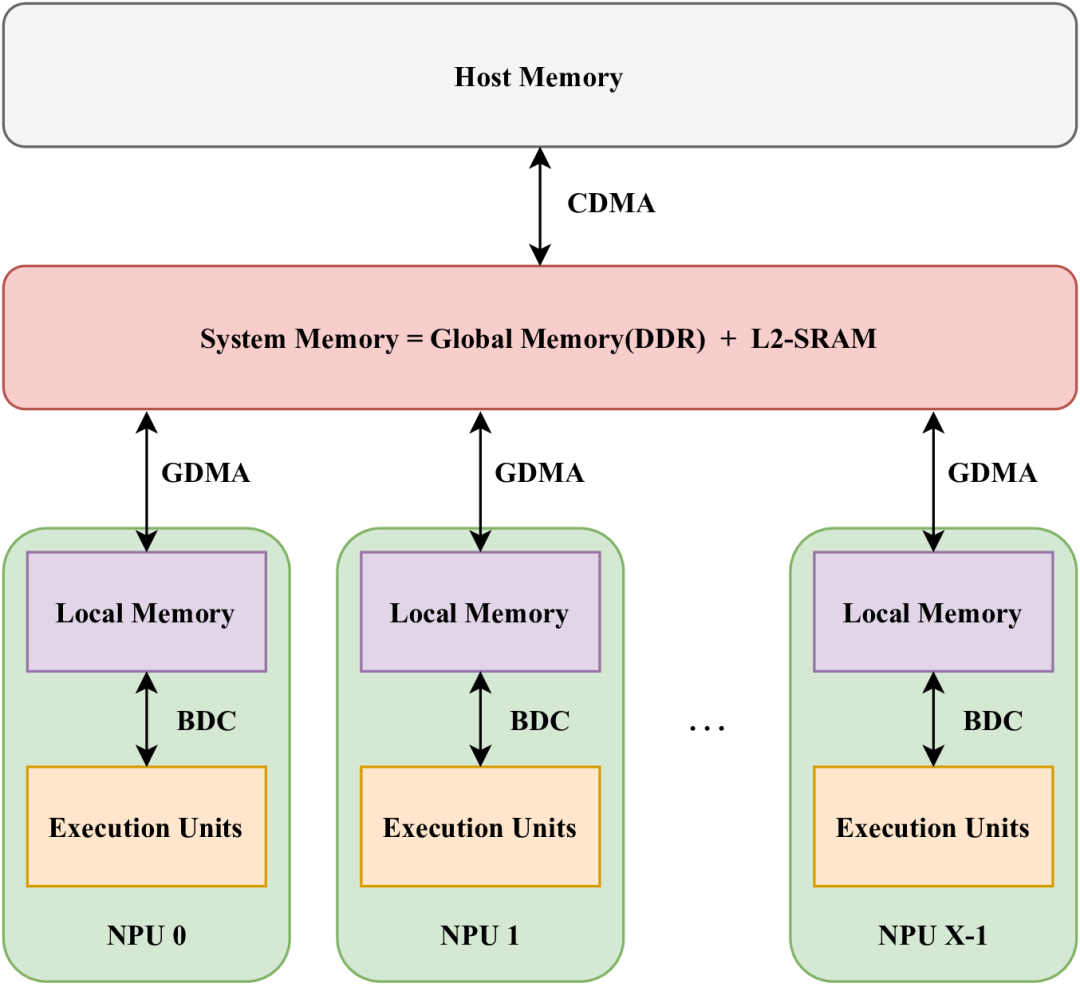
64個分區的地址是連續編碼的,即第一個分區的下一個地址便是第二個分區的起始地址。為了簡化編程,SOPHON定義了數據在LMEM中的布局(Layout)。為了更直觀地描述這種布局,本文將采用numpy中的ndarray形式來演示,并使用numpy定義的操作來說明數據在存儲器中的布局與神經網絡中定義的數據存在的差異。
本文涉及的ndarray操作包括reshape和transpose,并定義了一個resize函數來整理數據布局。resize函數可以對數據的指定維度進行擴展。例如:
tensor_a.shape=(1,2,3,4)#對應于d0=1,d1=2,d2=3,d3=4
tensor_b=resize(tensor_a,(2,4,3,8))
此時,在d0、d1、d3維度上使用0進行填充,以達到最終尺寸。
In[1]:tensor_a
Out[1]:
array([[[[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9,10,11]],
[[12,13,14,15],
[16,17,18,19],
[20,21,22,23]]]])
In[2]:resize(tensor_a,(1,3,3,6))
Out[2]:
array([[[[0, 1, 2, 3, 0, 0],
[4, 5, 6, 7, 0, 0],
[8, 9,10,11, 0, 0]],
[[12,13,14,15, 0, 0],
[16,17,18,19, 0, 0],
[20,21,22,23, 0, 0]],
[[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]]]])
resize函數的一個參考實現如下:
defresize(src,shape):
out=np.zeros(shape,dtype=src.dtype)
_src_slice=tuple(slice(0,min(i,j))fori,jinzip(src.shape,shape))
out[_src_slice]=src
returnout
LMEM中四維數據的排布
在LMEM中,一個四維數據(n,c,h,w)的Channel維度會被分散到不同的lane上。以一個shape為(2,5,2,3)的數據為例,假設NPU數量為4,每個NPU中EU數量為4,并且數據在h,w維度上需要與EU對齊:
shape=(2,5,2,3)
a=np.arange(np.prod(shape)).reshape(shape)
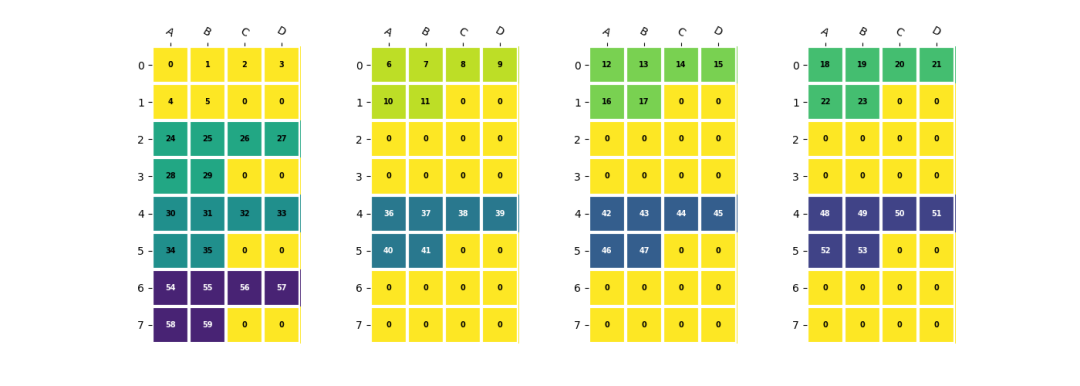
b=a.reshape(2,5,6)#數據hw合并
b=(
resize(b,(2,8,8)) #channel對齊到NPU,hw對齊到EU
.reshape(2,2,4,2,4)
.transpose(2,0,1,3,4)#(4,2,2,2,4)<-?(npu_id,?n^,?c^,?h^,?w^)
)
其中(n^, c^, h^, w^)為每個lane上數據的實際shape,對應的stride也滿足處理器中的定義。可以參考TPUKernel用戶開發手冊中的描述。npu_id維度是一個隱含維度,其值為npu數量,此處為4。
在4個NPU上對齊EU的數據排列
卷積權重的排列
為了確保EU能夠高效地使用,BM1684X處理器中卷積的權重需要按照EU對齊的方式優先存儲IC維度的數據,然后將OC維度分布到不同的NPU上。相應的存儲方式可以表示為:
c=a.reshape(2,5,6)
c=(
resize(c,(1*4,2*4,6)) #npu,eu_align,h*w
.reshape(1,4,2,4,6)
.transpose(1,0,2,4,3) #<4x1x2x6x4>
)
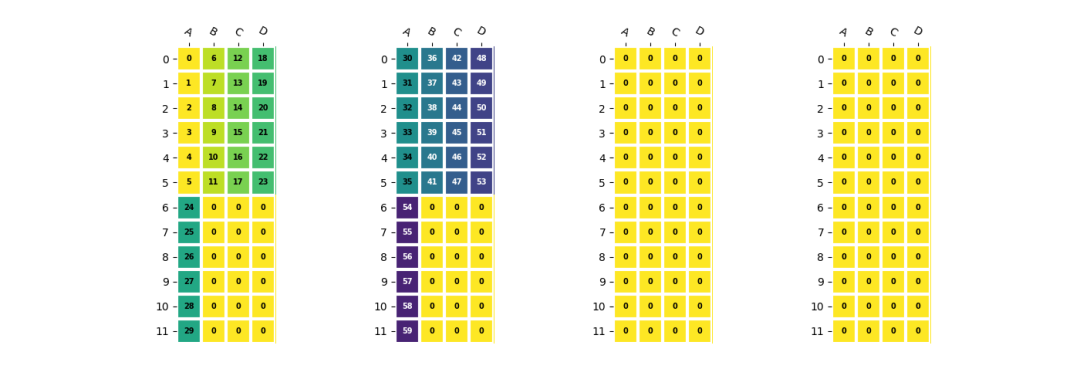 卷積權重的存儲方式
卷積權重的存儲方式
卷積權重與偏置的合并
在BM1684X中,權重需要按照EU對齊方式存儲,而偏置則采用緊湊模式。由于偏置數據量較小,直接拷貝效率不高。因為兩種模式下數據的stride不一致,無法直接將它們拼接在一起。在TPU-MLIR中,通過預先將權重和偏置合并,形成最終在LMEM中的存儲形式,然后通過一條DMA指令直接加載到LMEM中。
d=np.arange(60,65).reshape(1,5,1,1)
d=(
resize(d,(1,2*4,1,1)) #npu,eu_align
.reshape(1,2,4,1,1)
.transpose(2,0,3,4,1) #<4x1x1x1x2>
.resize(4,1,2,1,4)#EUalign<4x1x1x1x4>
)
e=np.concatenate((d.reshape(4,1,4),c.reshape(4,12,4)),axis=1)
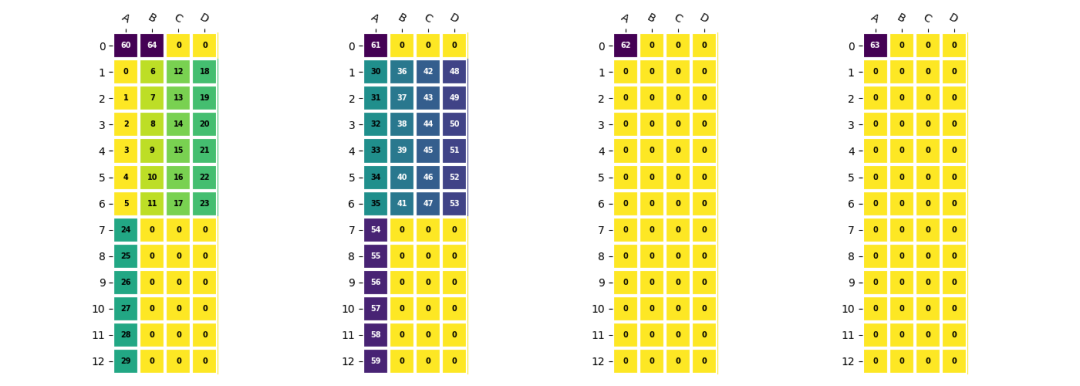 卷積權重和偏置合并后的形式
卷積權重和偏置合并后的形式
通過上述方法,我們可以有效地組織LMEM中的數據,以適應SOPHON BM1684X處理器的計算需求,從而提高整體的執行效率和性能。
-
處理器
+關注
關注
68文章
19407瀏覽量
231183 -
存儲器
+關注
關注
38文章
7528瀏覽量
164343 -
編譯
+關注
關注
0文章
661瀏覽量
33040
發布評論請先 登錄
相關推薦
康謀分享 | 如何應對ADAS/AD海量數據處理挑戰?

輕松學會單片機
從0開始,181頁知識帶你輕松搞定C++語言
如何處理好FPGA設計中跨時鐘域間的數據
帶你玩轉RT-Thread,開發教程匯總(共13篇)
帶你深入探索okio組件高效的奧秘
無法讓SWO數據在MCUXpresso上高效工作怎么處理?
基于ARM處理器的高效異常處理解決方案

關于選擇處理器的八個認知錯誤
Python數據清洗和預處理入門完整指南
labview處理excel數據中的粗大誤差
盛顯科技:拼接處理器如何實現高效數據拼接操作?






 工商網監
工商網監
評論