 如何利用chiplet技術構建大芯片?
如何利用chiplet技術構建大芯片?
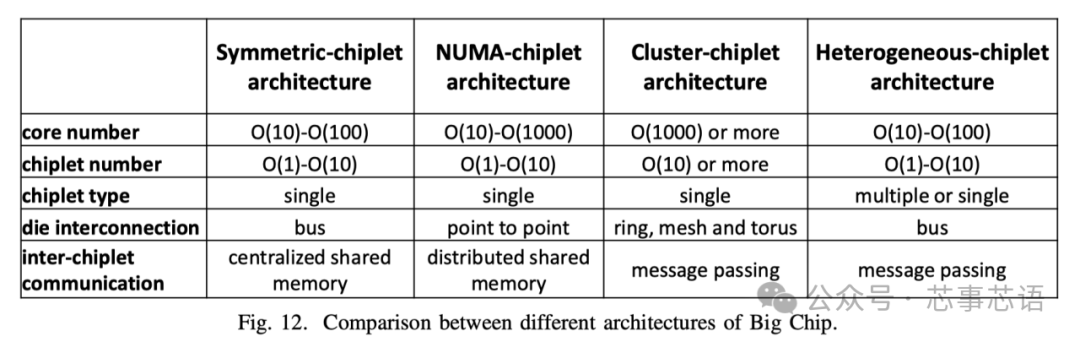
大芯片的架構設計對性能有重大影響,與存儲器訪問模式密切相關。在內存訪問模式方面,與傳統的多核處理器設計考慮將多核集成在單個裸片上訪問內存不同,大芯片設計側重于多個多核裸片訪問內存系統。根據內存訪問模式,大芯片可以分為對稱chiplet架構、NUMA(非均勻內存訪問)chiplet架構、集群chiplet架構和異構chiplet架構。在接下來的章節中,我們將以利用chiplet技術構建大芯片為例,從性能、可擴展性、可靠性、通信等方面討論這些大芯片架構的特點。
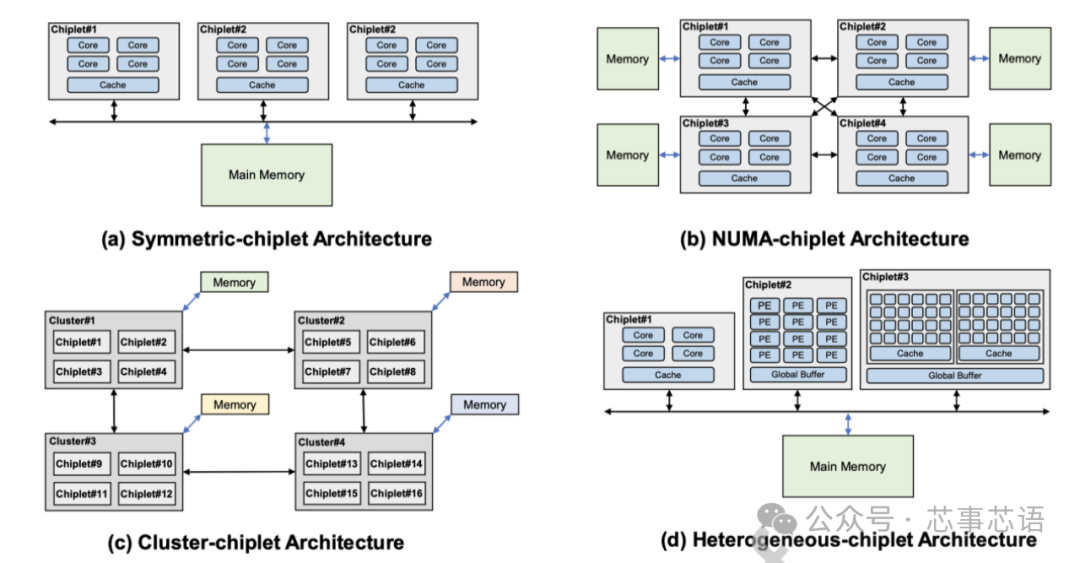
Symmetric-chiplet architecture
對稱小芯片架構(Symmetric-chiplet architecture)。如圖11(a)所示,對稱chiplet架構由許多相同的計算chiplet組成,通過路由器網絡或chiplet間資源(例如中介層)訪問共享的統一存儲器或IO。Chiplet可以設計為具有本地緩存的多核結構,或者具有多個處理元件的NoC結構。統一內存可以被所有chiplet平等地訪問,這體現了UMA(統一內存訪問)的效果。我們現在討論對稱小芯片架構的三個主要優點。
首先,對稱chiplet架構允許多個chiplet執行指令以提供高計算能力。工作負載可以分成小塊,然后分配給不同的Chiplet,以加快應用程序的執行速度,同時保持不同Chiplet之間的工作負載平衡。
其次,這種對稱的chiplet架構提供了從不同chiplet到內存的統一延遲,無需考慮NUMA等分布式共享內存系統中的遠程訪問或內存復制,從而節省了由于不必要的數據移動而導致的延遲和能耗。
第三,對稱chiplet處理器還提供冗余設計,其他chiplet可以接管故障chiplet的工作,從而提高系統可靠性。由于共享內存,對稱小芯片處理器可以在不增加額外私有內存的情況下增加小芯片的數量。然而,當對稱chiplet架構繼續擴大chiplet數量時,互連設計將受到物理布線的嚴重限制。解決高帶寬小芯片間通信和內存請求沖突也具有挑戰性。請注意,增加Chiplet的數量可能會增加不同Chiplet對內存的請求沖突,這會損害系統性能。平均而言,內存帶寬由小芯片劃分。增加小芯片的數量會減少每個小芯片的分區內存帶寬。工業界和學術界的一些設計采用了對稱芯片架構。Apple M1 Ultra處理器[43]采用小芯片集成設計,具有兩個相同的M1 Max芯片,具有統一的內存架構設計。芯片上的內核可以訪問高達128GB的統一內存。Fotouhi [44]提出了一種基于小芯片集成的統一內存架構,以克服距離相關的功耗和延遲問題。Sharma [45]提出了一種通過板載光學互連共享統一存儲器的多芯片系統。
NUMA-chiplet architecture
NUMA-chiplet架構(NUMA-chiplet architecture)。NUMA小芯片架構包含通過點對點網絡或中央路由器互連的多個小芯片,并且NUMA小芯片架構的存儲器系統由所有小芯片共享但分布在架構中,如圖11(b)所示。Chiplet可以采用共享緩存的多核設計,或者通過NoC互連的PE的設計。而且,每個chiplet可以占用自己的本地存儲器,例如DRAM、HBM等,這是其區別于對稱chiplet架構的最明顯特征。盡管這些連接到不同chiplet的存儲器分布在系統中,但存儲器地址空間是全局共享的。共享內存的這種分布式放置會導致NUMA效應,即訪問遠程內存比訪問本地內存慢[46]。NUMA-chiplet架構考慮了一些優點。從單個chiplet的角度來看,每個chiplet都擁有自己的內存,具有相對私有的內存帶寬和容量,減少了與其他chiplet的內存請求的沖突。此外,芯片與內存的緊密放置提供了數據移動的低延遲和低功耗。
此外,在NUMA-chiplet架構中,通過高帶寬點對點網絡或路由器互連的多個chiplet可以并行執行任務,從而提高系統性能和兼容性。這種NUMA小芯片架構具有很高的可擴展性,因為每個小芯片都有自己的內存。然而,隨著NUMA-chiplet架構擴展到更多的chiplet,設計chiplet到chiplet互連網絡變得具有挑戰性。
此外,隨著chiplet數量的增加,編程模型的成本和難度也隨之增加。有一些設計采用NUMAchiplet架構。AMD的第一代EPYC處理器將四個相同的小芯片與本地內存連接起來[39]。對內存的本地訪問和遠程訪問之間的延遲差異可達51ns [46]。
在AMD第二代EPYC處理器中,計算Chiplet通過IO Chiplet連接到內存,這顯示了NUMA-chiplet架構[34]。另一種典型的NUMAchiplet架構設計是Intel Sapphire Rapids [47]。它由四個小芯片組成,通過MDFIO(多芯片結構IO)連接。四個小芯片組織為2x2陣列,每個芯片充當NUMA節點。Zaruba [48]架構了4個基于RISC-V處理器的小芯片,每個小芯片都有三個分別與其他三個小芯片的鏈接,以提供非統一的內存訪問。
Cluster-chiplet architecture
集群小芯片架構(Cluster-chiplet architecture)。如圖11(c)所示,集群chiplet架構包含許多chiplet集群,總共有數千個核心。采用環形、網狀、一維/二維環面等高速或高吞吐量網絡拓撲來連接集群,以滿足此類超大規模系統的高帶寬和低延遲通信需求。每個集群由許多互連的小芯片和單獨的內存組成,并且每個集群都可以運行單獨的操作系統。集群可以通過消息傳遞的方式與其他集群進行通信。通過高性能互連實現強大集群互連的集群-chiplet架構顯示出高可擴展性并提供巨大的計算能力。
作為一種可擴展性很強的架構,clusterchiplet架構是許多設計的基礎。IntAct [30]集成了96個內核,這些內核在有源中介層上分為6個小芯片。6個小芯片通過NoC連接。Tesla [49]發布了用于億級計算的Dojo系統微架構。在Dojo中,一個訓練圖塊由25個D1小芯片組成,這些小芯片排列為5x5矩陣樣式。通過2D網格網絡互連的許多訓練塊可以形成更大的系統。Simba [1]通過MCM集成,利用網狀互連構建了6x6小芯片系統。Chiplet內的PE使用NoC連接。
Heterogeneous-chiplet architecture
異構小芯片架構(Heterogeneous-chiplet architecture)。異構chiplet架構集成了異構chiplet,由不同種類的chiplet組成,如圖11(d)所示。同一中介層上的不同種類的chiplet可以與其他種類的chiplet互補,協同執行計算任務。華為鯤鵬920系列SoC[25]是基于計算chiplet、IOchiplet、AIchiplet等的異構系統。Intel Lakefield[50]提出了將計算chiplet堆疊在基礎chiplet上的設計。計算chiplet集成了許多處理核心,包括CPU、GPU、IPU(基礎設施處理單元)等,基礎chiplet包含豐富的IO接口,包括PCIe Gen3、USB type-C等。在Ponte Vecchio [51]中,兩個基礎塊使用EMIB(嵌入式多芯片互連橋)互連。計算瓦片和RAMBO瓦片堆疊在每個基礎瓦片上。Intel Meteor Lake處理器[52]集成了GPUtile、CPUtile、IOtile和SoCtile。
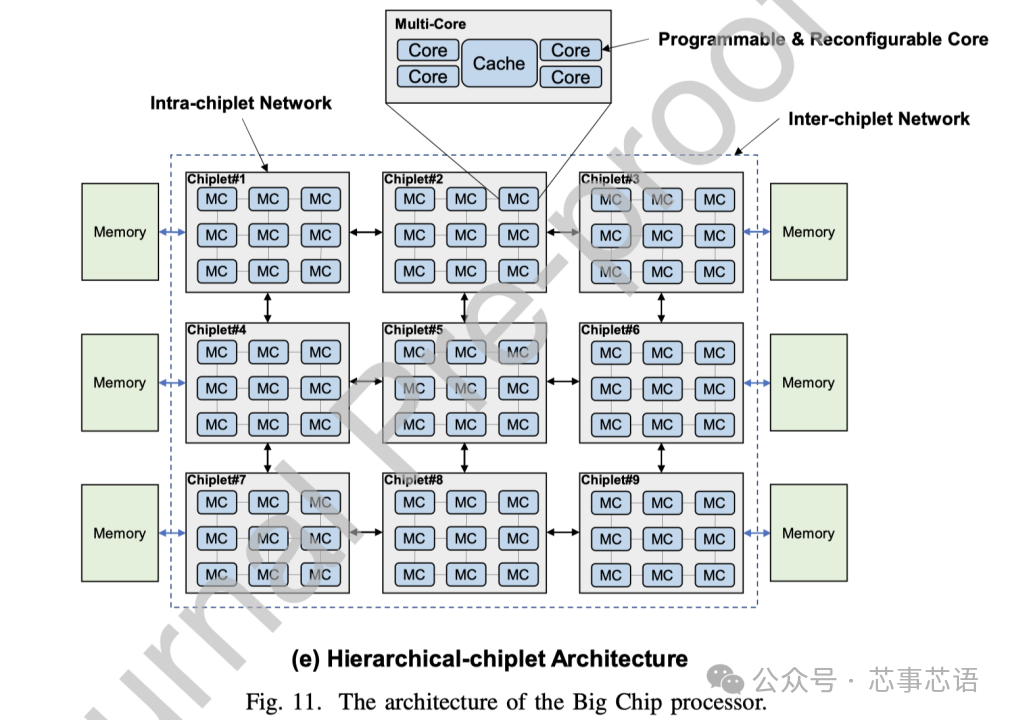
hierarchical-chiplet architecture
對于當前和未來的億億級計算,我們預測分層chiplet架構(hierarchical-chiplet architecture)將是一種強大而靈活的解決方案。如圖11(e)所示,分層chiplet架構被設計為具有分層互連的許多內核和許多chiplet。在chiplet內部,內核使用超低延遲互連進行通信,而chiplet之間則通過先進封裝技術的低延遲互連,從而可以在這種高可擴展性系統中降低片上(let)延遲和NUMA效應最小化。存儲器層次結構包含核心存儲器、片內存儲器和片外存儲器。這三個級別的內存在內存帶寬、延遲、功耗和成本方面有所不同。
在分層chiplet架構的概述中,多個核心通過交叉交換機連接并共享緩存。這就形成了一個pod結構,并且pod通過chiplet內網絡互連。多個pod形成一個chiplet,chiplet通過chiplet間網絡互連,然后連接到片外存儲器。需要仔細設計才能充分利用這種層次結構。合理利用內存帶寬來平衡不同計算層次的工作負載可以顯著提高chiplet系統的效率。正確設計通信網絡資源可以確保chiplet協同執行共享內存任務。
VI.構建大芯片:我們的實現
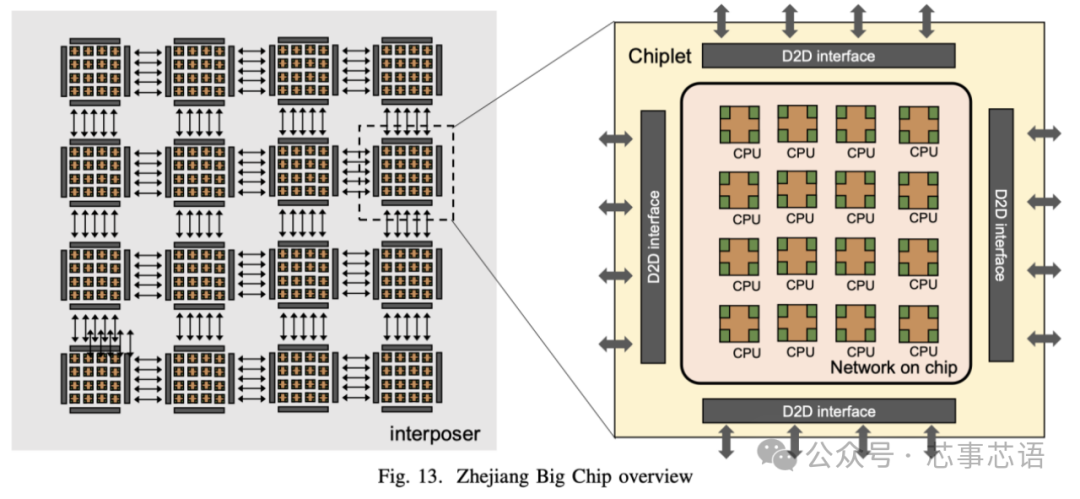
為了探索大芯片的設計和實現技術,我們構建并設計了一個基于16個小芯片的256核處理器系統,名為浙江大芯片。在這里,我們介紹了擬議的Big Chip處理器。
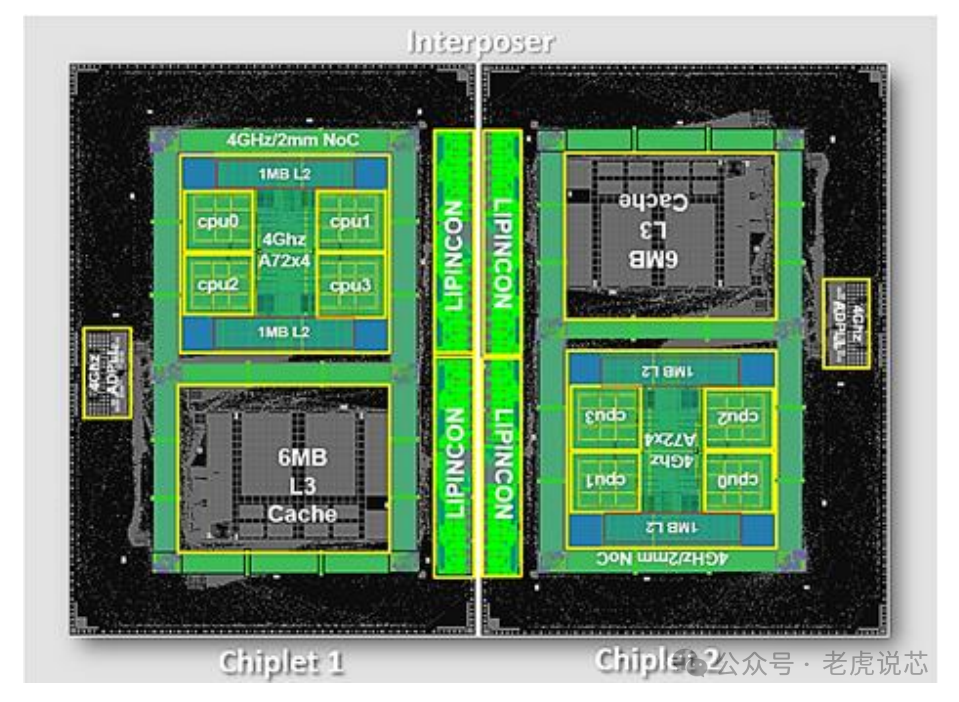
浙江大芯片采用可擴展的基于tile的架構,如圖13所示。該處理器由16個chiplet組成,并且有可能擴展到100個chiplet。每個chiplet中都有16個CPU處理器,通過片上網絡(NOC)連接,每個tile完全對稱互連,以實現多個chiplet之間的通信。CPU處理器是基于RISC-V指令集設計的。此外,該處理器采用統一內存系統,這意味著任何區塊上的任何核心都可以直接訪問整個處理器的內存。
為了連接多個小芯片,采用了芯片間(D2D)接口。該接口采用基于時分復用機制的通道共享技術進行設計。這種方法減少了芯片間信號的數量,從而最大限度地減少了I/O bumps和內插器布線(interposer wiring)資源的面積開銷,從而顯著降低了基板設計的復雜性。小芯片終止于構建微型I/Opads的頂部金屬層。浙江大芯處理器采用22 nm CMOS工藝設計和制造。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19406瀏覽量
231160 -
存儲器
+關注
關注
38文章
7528瀏覽量
164337 -
芯片設計
+關注
關注
15文章
1028瀏覽量
55004 -
路由器
+關注
關注
22文章
3744瀏覽量
114465 -
chiplet
+關注
關注
6文章
434瀏覽量
12631
原文標題:大芯片:挑戰、模型與架構----構建大芯片
文章出處:【微信號:Rocker-IC,微信公眾號:路科驗證】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是Chiplet技術?chiplet芯片封裝為啥突然熱起來
北極雄芯開發的首款基于Chiplet異構集成的智能處理芯片“啟明930”
chiplet是什么意思?chiplet和SoC區別在哪里?一文讀懂chiplet
國產封測廠商競速Chiplet,能否突破芯片技術封鎖?
Chiplet技術給EDA帶來了哪些挑戰?
半導體Chiplet技術及與SOC技術的區別

如何助力 Chiplet 生態克服發展的挑戰
Chiplet關鍵技術與挑戰
Chiplet究竟是什么?中國如何利用Chiplet技術實現突圍
chiplet和cowos的關系
先進封裝 Chiplet 技術與 AI 芯片發展
什么是Chiplet技術?Chiplet技術有哪些優缺點?
什么是Chiplet技術?
解鎖Chiplet潛力:封裝技術是關鍵






 工商網監
工商網監
評論