 如何解決FPGA布局布線的擁塞問題呢?有哪些方法?
如何解決FPGA布局布線的擁塞問題呢?有哪些方法?
解決布線擁塞問題
1.問題①的解決方法
14.2節提到的問題①,即設計中有很大的扇出,對于如何獲知該扇出信號有多種途徑。常見的途徑是通過FPGAEditor(Xilinx)或者Fitter里Resource Section中的Control Signals 或者 Non Global Hign Fan-out Signal(Altera)查看扇出信號的大小排序。以Altera為例(下面的例子只是一個示范,并非說該例子是扇出過大導致布線問題),編譯完成后,查看Fitter報告即可查看扇出,如圖14-2所示。
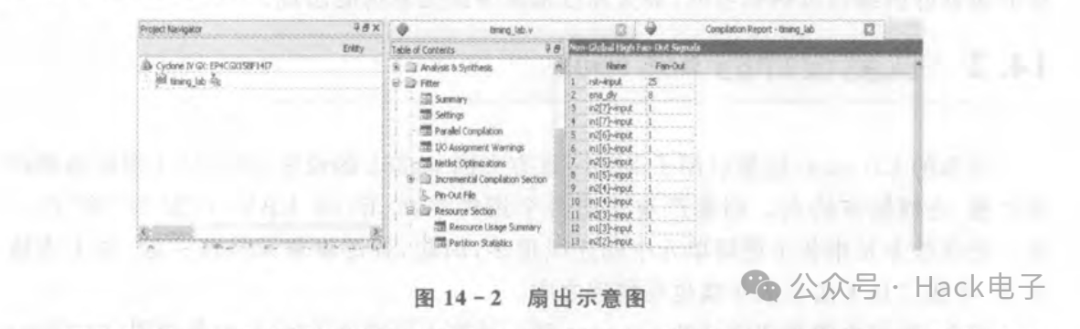
可以看到,rst這個復位信號的扇出有33個,ena_dly有8個。該設計對應的RTL代碼如下:


從代碼中可以看到,控制信號enadly有效時才對輸入信號inl和in2的寄存信號進行或操作,因此該控制信號直接控制著輸出寄存器ut[7:0]的翻轉,該控制信號的扇出量為8個寄存器。所以,通過對編譯結果的查詢可以知道扇出信號較大的為哪些,結合代碼對其進行修改即可。注意,本段RTL代碼只是舉例說明如何查找和定位扇出信號,并不表明扇出信號為8就會導致時序問題。實際上非全局信號的扇出多少才是合理的要看具體的布線情況,且要視FPGA器件而定。在編寫代碼階段要養成時刻警惕扇出過大的問題,一般而言,如果一個信號扇出到幾百個寄存器或者邏輯單元,則
最好對該信號做邏輯復制。知道如何定位控制信號的扇出后,我們就要著手于如何修改。對于此類修改,一般有兩種方法:第一種是讓工具自己做扇出復制;第二種是設計者在代碼中手動修改,讓工具自己做扇出復制。以Altera為例,在settings中,單擊Fitter Settings,然后單擊More Settings,彈出如圖 14-3的界面。
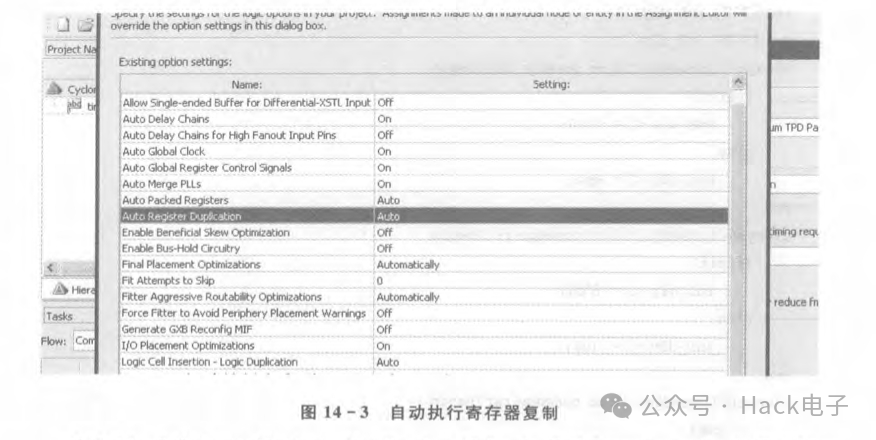
對圖14-3 中 Auto Register Duplication 和 Logic Cell Insertion -Logic Duplication中的Auto全部改為On,則工具會對由扇出引起的布線時序問題做邏輯復制。而在手動做扇出寄存器/信號復制的情況下,則對該信號做復制。以上面的RTL為例子,假設要把enable信號的扇出控制到4,那么只須做如下調整:



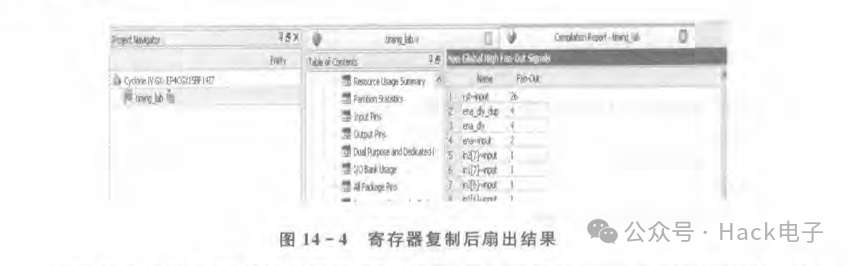
可以看到,對ena_dly做了寄存器復制,多了一個ena_dly_dup,這樣ena_dly的信號扇出就減少了一半,另外一半由ena_dly_dup代替。注意,聲明該寄存器時有“/*synthesispreserve*/;"語句,這是為了告訴編譯器不要對該信號做優化,因為在通常情況下,編譯器會對多余或者等效的寄存器做優化,只保留一個。從圖14-4可以看出,ena_dly的扇出減少了一半。
2.問題②的解決方法
關于第二個問題,即復位信號造成的布局布線問題,一般有如下解決方法:
對于復位信號,如果是異步復位、同步釋放,那么將會對removal路徑做時序分析,該路徑要求所有的復位信號在同一個節拍內撤離且滿足removal的時序要求。對于這種情況,如果能夠確定設計里所有的寄存器在復位不在同一個節拍內無效的情況下也能正常工作,那么可以對該路徑做falsepath處理,即在時序約束里對復位信號到所有相關寄存器的路徑做不分析處理。
另外一個方式是降低復位信號的扇出,沒有必要對所有的寄存器都加上復位信號,作者推薦數據路徑上的流水線寄存器可以不加復位信號,只對控制路徑上的寄存器(如計數器、數據使能信號)等加上復位信號,從而大幅度降低復位信號的扇出。另外,在Xilinx器件中,不推薦對BIockRAM、DSP48中的流水線寄存器等加入復位信號。
3.問題③解決方法
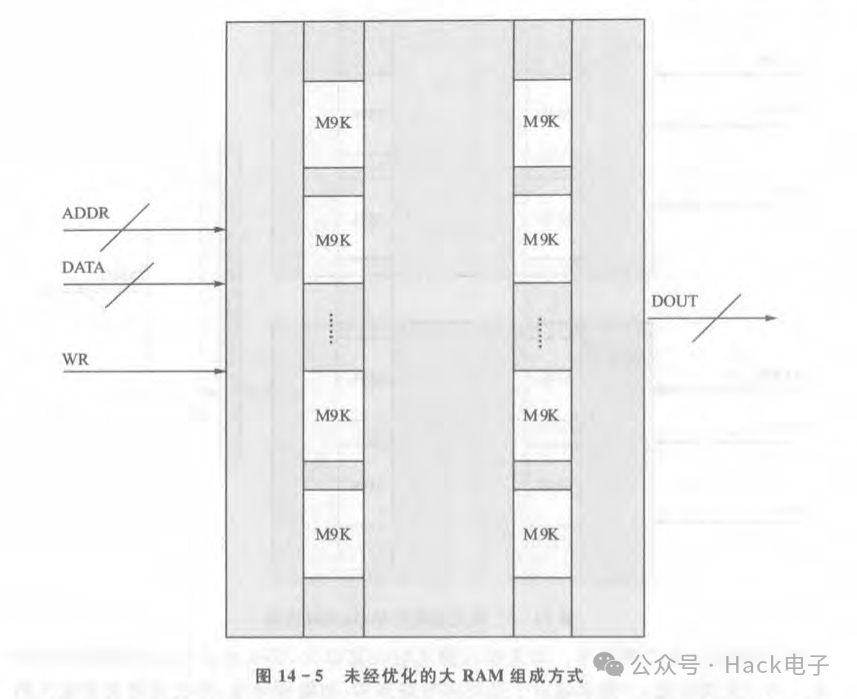
關于第三個問題的解決思路,一般來說設計者應該極力避免使用FPGA的BlockRAM IP來生成大容量的BlockRAM。比如說,用Block Memory Generator生成一個位寬為16,深度為1M的BIockRAM。因為在這種情況下,IP生成工具是把很多Block RAM單元(以AlteraCycloneIV為例,其BlockRAM基本單元為 M9K,即一個BlockRAM的存儲容量為9kbit,其最大讀寫位寬和深度是確定的)拼接在一起形成-個大的BIocKRAM。這種情況下,IP生成工具生成的BlockRAM由于多片拼接在起,有可能造成各個BlockRAM基本單元間的距離過大,進而造成走線過長,從而產生擁塞和布線困難問題,如圖14-5所示。
如圖14-5所示,FPGA中每個BlockRAM單元(以M9K為例)在基底中都是列狀分布,如果生成的BIocKRAM容量太大,那么將會使用一列甚至是兩列M9K來拼接。而對于外部信號來說,就只有ADDR總線、DATA總線、WR信號等對其操作,這就要求ADDR、DATA、WR等信號的輸出寄存器到各個M9K的時序路徑都要滿足而如果M9K過多,那么基本上這是不可能達到的,如此即會造成布線擁塞。
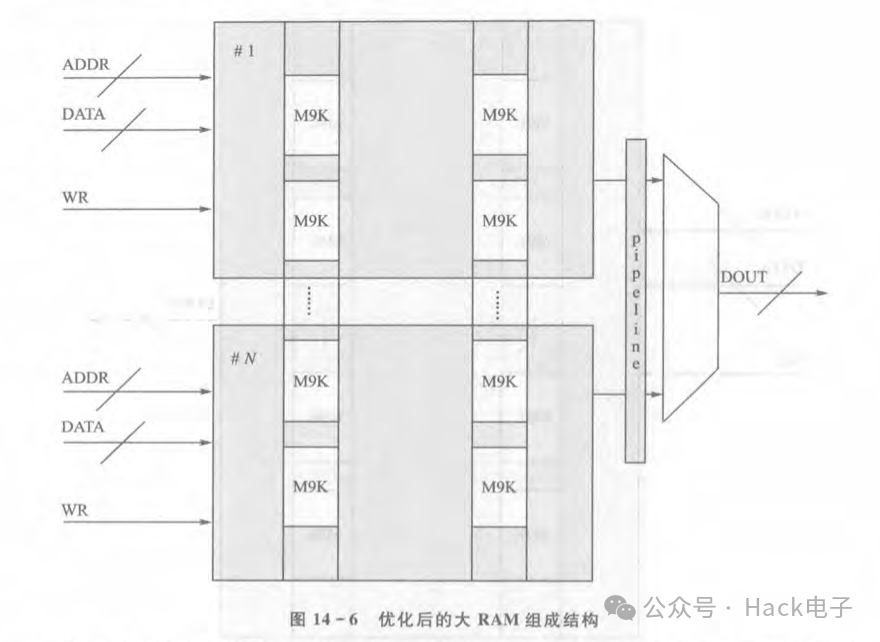
正確的解決方法是把一個大的BlockRAM手動拼接,假設要生成一個位寬為16bit、深度為1M的Block RAM,那么可以把其拆分成10個位寬為16bit、深度為100K的Block RAM,然后再由這些較小的BlockRAM來組成一個大的BIockRAM。讀者可能會問,這跟上面的有何區別?區別就是設計者可以對ADDR、DATA、WR等信號進行邏輯復制,即一共有10個相同的ADDR,DATA,WR分別操作這10個BlockRAM,然后根據操
作結果進行選擇輸出,從而降低了ADDR、DATA、WR等信號到達各個M9K的扇出提高布線成功率,如圖14-6所示。如圖14-6所示,原來一個大的BIockRAM被拆分成了N個,每個都由一套等效的ADDR、DATA和WR進行控制,從而降低了ADDR、DATA和WR在操作大的BlockRAM時的扇出,增加了可布線和時序收斂性。另外,在各個BIockRAM的輸出MUX里要多打幾級pipeline,有助于時序收斂。同理,對于DSP硬CORE使用過多造成的布線時序問題,作者推薦對DSP硬CORE的輸入輸出進行多級pipeline。
4.問題④的解決方法
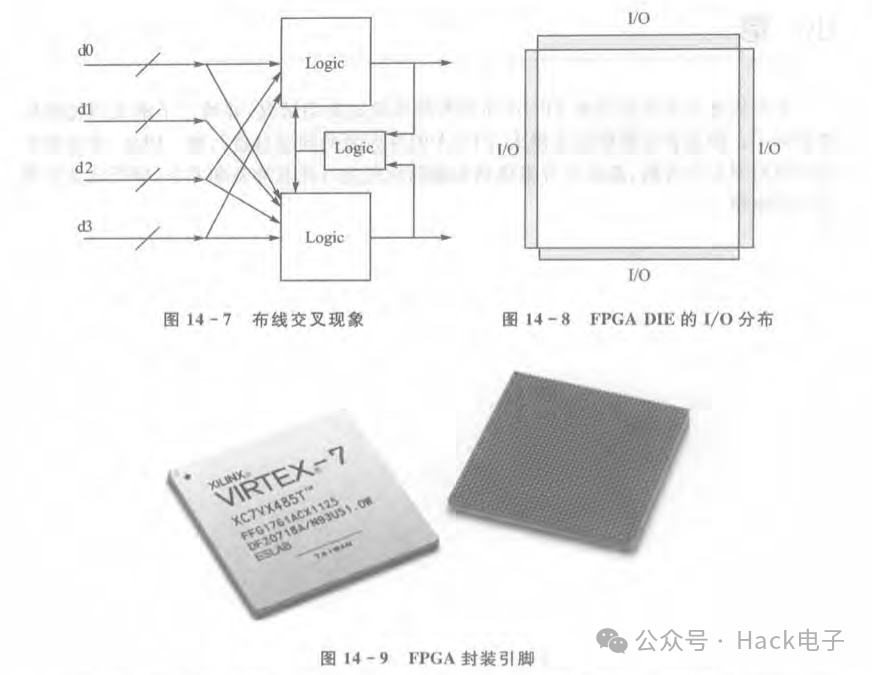
對于設計中的電路交叉線過多引起的布局布線問題的解決,有可能需要對電路/邏輯結構進行優化或者再設計。這跟PCB布局布線是一個道理,如果一個設計在PCB布線時發現,原理圖設計者對IC之間引腳的連線比較隨意,造成交叉線過多,比如說MCU的通用I/O跟外部芯片的連接,那么這時候可以選擇調換MCU通用I/O引腳來降低連線之間的交叉,進而降低布局布線難度。比如說,一個邏輯設計的結構如圖14-7所示。
這種結構的數據流很容易造成布線擁塞或者布線困難,因為輸入數據流之間是交
叉的,而輸出又有反饋環節。如果輸入輸出的位寬很大,那么將會導致布線困難的問題。對于此類問題,一般來說由于是邏輯電路架構/功能所導致,修改需要花費很大的力氣。一般來說,在不修改整體架構的情況下,在數據的輸入輸出之間最好做多級流水線寄存器,目的并不是減少組合邏輯的層數,而是減少寄存器到寄存器之間的走線。圖14-7的硬件結構存在大量交叉,因此很多內部互連需要繞很遠,從而大大增加了走線延時。這樣就只能增加寄存器的流水級數,降低寄存器到寄存器之間的走線延時。
5.問題⑤的解決方法
還有一種情況是FPGA引腳分配不合理導致數據流出現大量交叉進而導致時序收斂困難或者布線失敗。在FPGA的基底里面,引腳的排布跟外面封裝的引腳排布是不一樣的,FPGA基底里面的引腳排布大部分位于芯片的左邊、右邊、上邊和下邊,如圖14-8所示。
對于很多BGA封裝的FPGA,盡管從其封裝圖上看,引腳分布在芯片內部,如圖14-9所示,但是實際上在芯片內部,引腳的排布卻是跟圖14-8類似。因此,當引腳分配不合理時,在FPGA內部的數據流有可能造成交叉,或者輸入輸出混在一起,如圖14-10所示。
如果引腳分配不合理,輸入和輸出的I/O在FPGA的基底引腳中的距離都放得很近的話,那么當數據很多且內部邏輯處理占用資源較多時,將會帶來很大的布線問題因此可酌情對引腳進行調整,力爭做到數據流是順著的,如圖14-11所示。
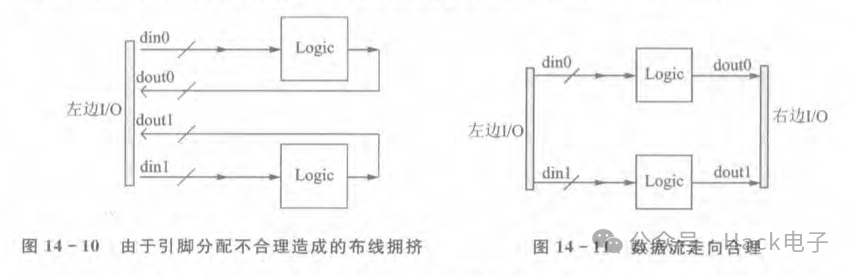
其實這一步應該在FPGA原理圖設計階段的FPGAPinLocation時就要考慮到寧可在前期的方案設計方面多花一點功夫,也不要匆匆上馬,欠缺考慮,只有在前期做足準備,到后面才會事半功倍。
小 結
本章講述了常見的導致FPGA布局布線失敗的典型情況,并給出了解決問題的思路和例子。隨著設計規模越來越大,FPGA時序收斂的問題日益凸現。因此,在遇到此類問題時要心中有數,最好在方案規劃和編碼階段就對此有準備和考慮,降低此類問題發生的概率。
審核編輯:劉清
-
FPGA
+關注
關注
1630文章
21796瀏覽量
605983 -
寄存器
+關注
關注
31文章
5363瀏覽量
121151 -
RTL
+關注
關注
1文章
385瀏覽量
59948 -
PCB布線
+關注
關注
21文章
463瀏覽量
42132
原文標題:FPGA布局布線失敗怎么辦(三)
文章出處:【微信號:Hack電子,微信公眾號:Hack電子】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA去耦電容如何布局布線
如何應對FPGA的擁塞問題
如何解決高速信號的手工布線和自動布線之間的矛盾
FPGA設計的塑封式布局和布線介紹
FPGA的布局布線
MCM布局布線的軟件實現
FPGA布線為什么會擁塞呢?如何解決呢
FPGA布線擁塞主要原因及解決方法
PCB布局布線技巧104問
如何解決高速信號的手工布線和自動布線之間的矛盾?
fpga布局布線算法加速
FPGA布局布線的可行性 FPGA布局布線失敗怎么辦






 工商網監
工商網監
評論