 請問高端網絡芯片如何處理數據包呢?
請問高端網絡芯片如何處理數據包呢?
*本文系SDNLAB編譯自瞻博網絡技術專家兼高級工程總監Sharada Yeluri的博客
隨著網絡芯片帶寬的持續提升,其內部數據包處理單元的工作負載也隨之增加。然而,如果處理單元無法與網絡接口的傳入速率相匹配,將無法及時處理數據包,這不僅會導致數據包隨機丟失,更會降低網絡的吞吐量。
本文將深入探討與數據包處理相關的各項工作和挑戰,分析處理單元吞吐量的需求演變,以及在網絡芯片中執行這些功能的多種方法和技術。
數據包處理
網絡芯片中的數據包處理是指,當網絡數據包通過路由器、交換機或防火墻中的芯片時,芯片對網絡數據包執行的一系列操作。網絡芯片主要檢查數據包的L2/L3報頭信息。從宏觀層面來看,數據包處理的主要功能可以概述如下:
解析
第一步是對數據包報頭進行分析,以了解其結構和所采用的協議(如以太網、VLAN、IP、TCP/UDP 以及現有的封裝)。解析過程中會識別出后續處理步驟中需要使用的關鍵字段,例如源地址和目標地址、端口號和協議類型。
封裝是網絡通信中的一種常見做法,即在數據包外部添加額外的一層報頭信息,通常是為了提供額外的功能,例如安全性(在 VPN 的情況下)和隧道(如 GRE 或 VXLAN)。這樣就形成了具有外部報頭和一個/多個內部報頭的數據包。在這種情況下,解析邏輯需要同時檢查外部報頭和內部報頭。此功能對于嚴重依賴封裝技術對網絡流量進行分段、保護和管理的現代網絡基礎設施至關重要。
分類
首先要確定數據包的來源。
數據包的來源包括其主機身份、接收接口(邏輯和物理)及其轉發域。通常,會執行第 2 層地址和數據包進入的物理接口之間的綁定檢查。然后根據數據包的報頭字段(例如源/目標 IP 地址、端口號和協議類型)對數據包進行分類。分類決定了如何處理數據包,例如應用哪些服務質量 (QoS) 策略。
隧道終止
通過比較隧道報頭字段與隧道端點信息,邏輯確定是否需要終止隧道。
對于需要終止的隧道,其封裝的數據包將被解封裝,恢復到原始格式后再被發送至最終目的地。外部/內部報頭有許多變體,網絡芯片可以根據其部署用例支持不同的隧道終止子集。一些常見的受支持的隧道技術包括 MPLS、VXLAN、GRE、MPLSoverUDP、IPinIP 等。
過濾
許多設備通過訪問控制列表 (ACL) 實現數據包過濾。ACL通常由一組規則(即ACL條目)組成,每個ACL條目定義了一種訪問控制策略,包括允許或拒絕特定類型的流量或訪問請求。ACL通常基于源地址、目標地址、協議類型、端口號、時間等條件來控制網絡訪問。
路由查找
根據數據包的目標地址和路由表,處理器決定數據包的下一跳,并據此進行轉發。這一過程涉及對 IPv4/IPv6 數據包執行最長前綴匹配查找,以及在轉發 MPLS 數據包時執行索引查找,或者在基于目標 MAC 地址進行 L2 轉發時進行精確匹配。查找結果可以直接指示數據包應離開的發送接口,或者指向一系列下一跳指令,這些指令被執行后將找到正確的發送接口。
下一跳處理
下一跳處理(執行存儲在大內存中的一系列下一跳指令)決定了如何將數據包轉發到其目的地。該處理過程會得出數據包必須離開的目標端口、實現ECMP 或 LAG 的負載平衡,以及確定推送或交換的 MPLS 標簽等。此外,數據包可選擇性地執行策略控制和計數。
重寫
最后一步,數據包報頭將被修改以剝離封裝報頭(在隧道終止的情況下)、更新TTL 遞減、V4 校驗和更新、時間戳更新等。
入站數據包處理
在入站數據包處理完成后,如果目標隊列擁塞,或者該數據包被選擇為 WRED 丟棄對象,則數據包可能會被丟棄。當數據包被允許轉發時,它會在片上緩沖區或外部內存緩沖區內排隊等待。無論是入站處的數據包排隊/出站的可選排隊,還是出站調度,這些過程都極大地依賴于網絡芯片的架構特性。
出站數據包處理
當數據包從緩沖區中讀出,并準備離開出站接口時,它會在出站階段進行進一步的處理,以便在傳輸前對數據包進行必要的修改。這些修改包括添加新的 L2 報頭和/或 VLAN 標簽、封裝(當網絡設備位于隧道入口點時)、添加 MPLS 標簽等。此外,數據包還可以選擇性地通過出站過濾/策略執行。這些實現方式因設備而異。
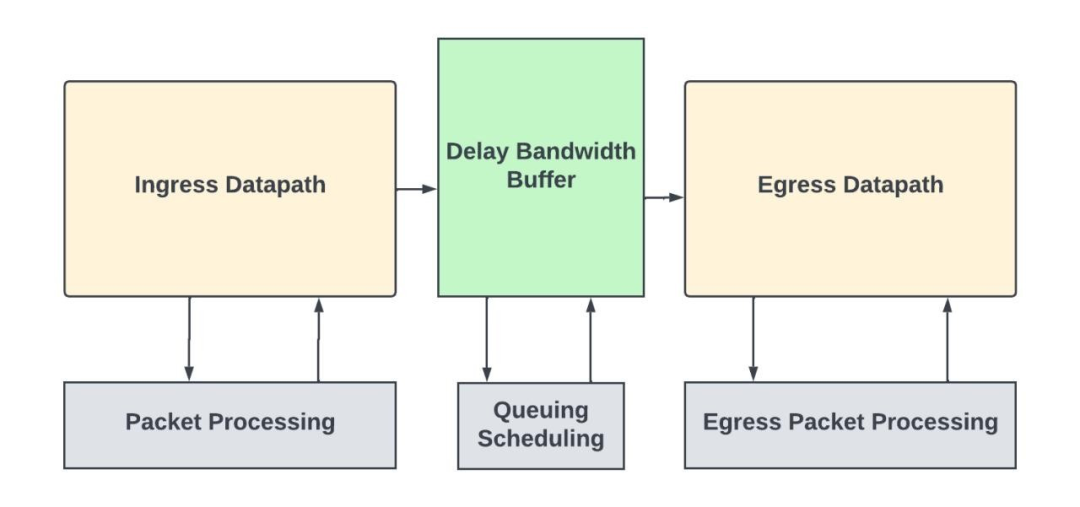
具有入站/出站數據路徑和數據包處理子系統的獨立網絡交換機
大型路由器可以使用多個模塊化路由芯片通過switch fabric相互連接,這些模塊化路由芯片可使用術語“數據包轉發實體(PFE)”來指代。在這些系統中,入站數據包處理發生在網絡流量進入的 PFE 中,出站數據包處理發生在流量離開的 PFE 中。
數據包處理實現
數據包處理的實現方式取決于所需的靈活性、設備的總吞吐量、以及該功能的功耗/性能/面積預算。
專用處理引擎
大約二十年前,隨著網絡協議快速演化,新的可選/擴展報頭和隧道標準也隨之涌現。數據包的處理是通過大量高度靈活且可編程的專用處理引擎實現的。這些專用處理引擎通常包含存儲在片上和/或片外指令存儲器中的微碼指令。與 RISC 和 X86 指令集不同,微碼是一種低級指令集,通常以非常長的指令字 (VLIW)的形式打包。處理引擎通過這些微碼指令序列解析存儲在本地存儲器中的數據包頭的不同字段,以確定數據包的結構,并執行上述所有入站和出站處理功能。處理引擎的硬件并不了解任何網絡協議,它只是盲目地執行指令以形成新的數據包頭并計算輸出接口。 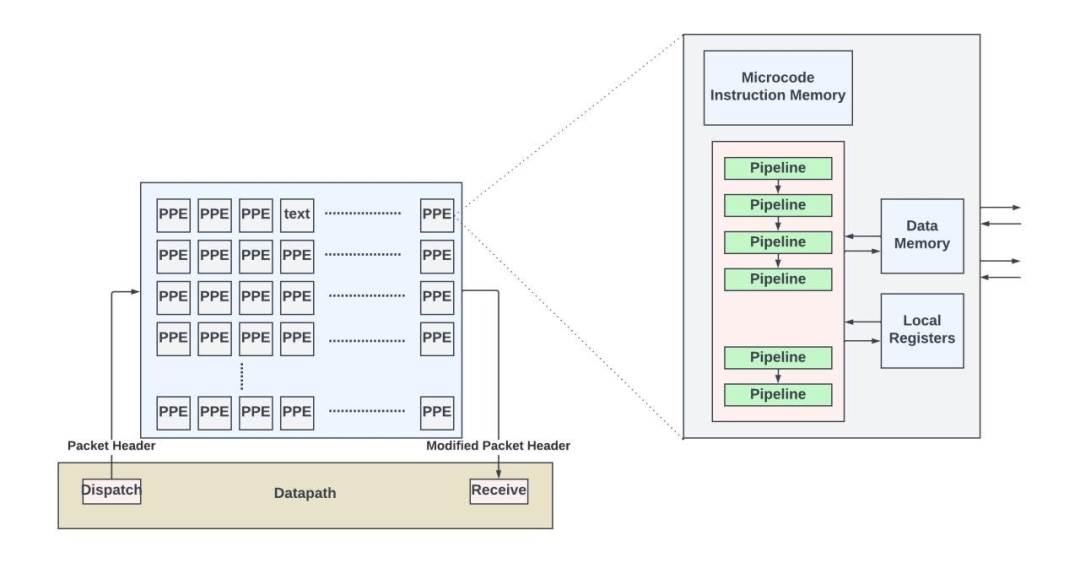
用于數據包處理的PPE
雖然基于微碼的處理提供了無限的靈活性,但在芯片面積或每 Gbps 功耗方面效率較低。在混合方法中,一些功能(如過濾/最長前綴匹配查找、策略執行等)可以在硬件本地(硬件加速器)中實現,同時使用微代碼指令進行數據包解析和其余的數據包轉發功能。
數據包處理Pipeline
隨著高端芯片開始封裝更多的 WAN 帶寬,混合方法無法滿足每 Gbps 的功率/面積目標。十多年前,一些網絡供應商開始使用硬件pipeline(同時以本地/功能特定的指令/排序操作的形式提供有限的靈活性)本地實現所有數據包處理功能。
下圖是基于Juniper的Express Architecture pipeline實現的入站數據包處理pipeline的概念圖。 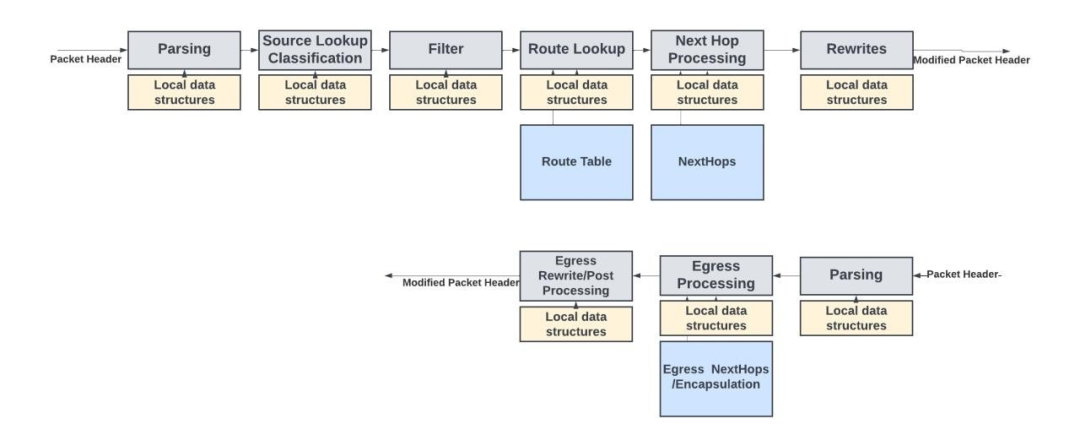
入站和出站數據包處理pipeline及其數據結構
該pipeline包含一系列后續塊或模塊,其中每個模塊負責上文描述的特定功能。通常,整個數據包存儲在數據路徑存儲器中,而報頭(通常是數據包的前128字節)則通過數據包處理pipeline。由于數據包處理只關注 L4 的報頭信息,因此不需要通過pipeline發送整個數據包。
根據吞吐量需求的不同,數據包報頭以每周期一個數據包的速率或更低的速率通過pipeline發送。每個模塊都有許多存儲在 SRAM 中的本地數據結構/配置。
Pipeline的靈活性
網絡是一個不斷發展的領域,為了適應新技術和新需求,經常會開發/標準化新協議和現有協議的擴展。從新的 RFC 標準發布到其實際在網絡芯片中得到應用,通常會有3-4 年的延遲時間。這就是為什么在這些pipeline中具有一定的靈活性非常重要。
例如,除了對已知的L2-L4報頭的標準解析之外,硬件還可以支持靈活的解析功能,以解析未來的協議報頭或現有協議的擴展。這可以通過一系列CAM(內容可尋址存儲器)和規則集來實現,它們指定了要查找新協議的Type/Length/Value字段的字節偏移量。
并非所有的網絡應用程序都經過相同的數據包處理。例如,某些數據包可能需要多次查找。第一次查找可能是 LPM(最長前綴匹配)查找,以確定數據包的下一個目的地。第二次查找可能涉及更具體的路由策略,比如基于策略的路由,其中決策基于數據包中的其他字段或應用類型。
類似地,在 MPLS 網絡中,第一次查找可能涉及讀取 MPLS 標簽以在 MPLS 網絡內做出轉發決策。當數據包到達 MPLS 網絡的邊緣,并且標簽被彈出時,需要進行第二次查找,以便根據數據包的原始 IP 報頭確定數據包的下一跳。
Express 數據包處理pipeline中的查找功能提供了這樣的選項,其中第一次查找的操作可以指示后續的查找,并且報頭循環回查找函數的開頭以進行下一次查找。 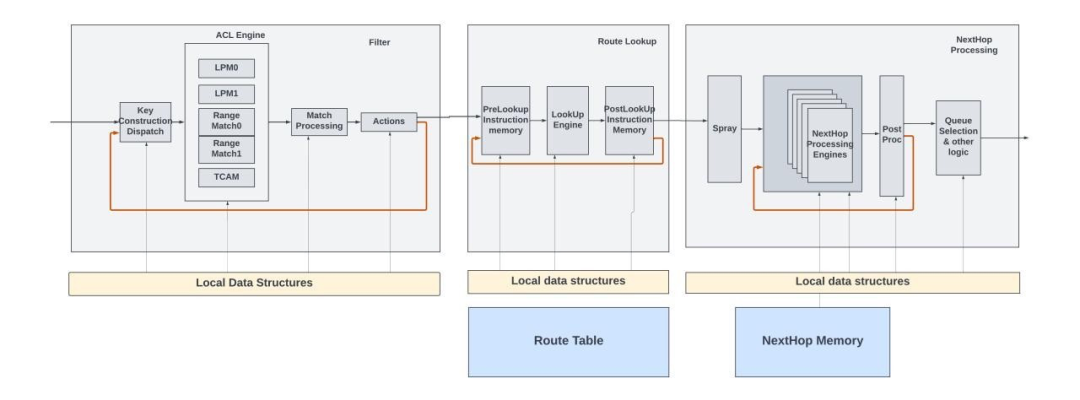
數據包如何在每個查找模塊內循環
需要注意的是,在數據包處理pipeline中,因為每個數據包都經過不同的pipeline并具有不同數量的查找、過濾器和下一跳操作,因此無法不會保持數據包的原有順序。網絡設備必須確保同一數據流中的數據包不會被打亂順序。粗略地判斷數據流的方式是以數據包進入的輸入端口/接口為準。而更為精細的判斷方法則是查看數據包的五元組,并通過計算哈希函數來確定數據流。pipeline末端的重排序引擎可以將數據包重新按照每個端口或每個數據流的順序排列好。 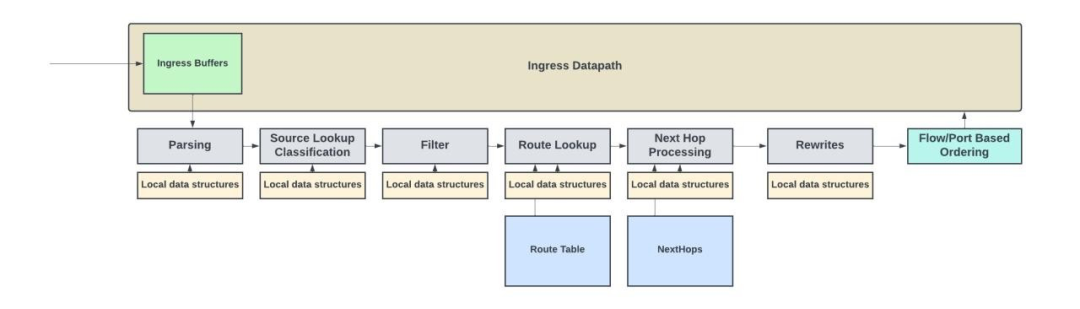
帶有重排序引擎的數據包處理pipeline
再循環
在某些封裝中,報頭字節可能會超過 128B。對于那些在初次傳遞中無法檢測到內部報頭的情況,數據包需經歷如下步驟:首先在剝離已解析的報頭字節,接著從入口內存中讀取額外的報頭字節,并將新報頭再次發回處理pipeline進行處理。在接下來的循環中,將重復處理步驟以處理內部報頭。
再循環應用的示例包括MPLS over UDP,其中需要處理兩個以上的堆棧,以及基于防火墻的隧道解封裝。 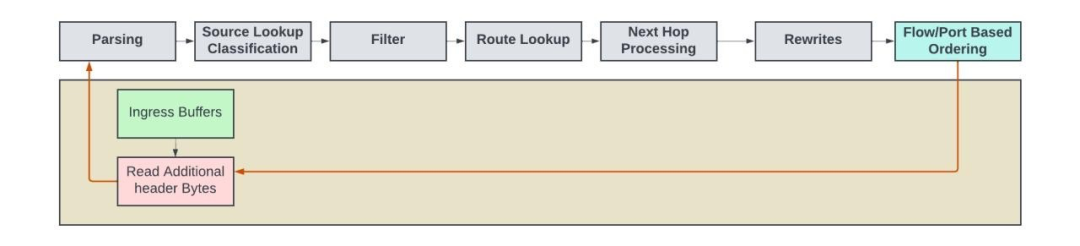
再循環的概念圖
吞吐量
網絡芯片所需的每秒數據包處理速率與能夠進入設備的最小數據包大小(通常是 64B 以太網幀)、數據包間隙 (IPG) 以及設備的總 WAN 吞吐量成正比。
Packets per second = (bits/second) / (bits /packet + IPG/packet)
假設一個3.2Tbps 的設備需要處理連續到來的 64B 數據包,若要跟上這種處理節奏,在1GHz的時鐘頻率下,每周期幾乎需要處理近5個數據包。由于每個pipeline最多只能每周期處理一個數據包,這意味著在這種情況下需要約5個數據包處理pipeline。就面積和功率而言,是相當昂貴的。

3.2Tbps 設備要滿足 64B 數據包的線路速率需要 5 個pipeline
在實際網絡流量中,平均數據包大小通常大于 64B。大多數流量通常使用最大傳輸單元 (MTU) 大小的數據包來最大化吞吐量。設計針對平均常用數據包大小優化的數據包處理引擎有助于實現更優的設計,有效利用芯片面積。那么,我們如何確定平均數據包大小呢?
一種方法是檢查網絡性能測試中使用的各種 IMIX 模式。
IMIX( Internet MIX)是網絡性能測試中使用的概念,用于更準確地模擬現實世界中的互聯網流量模式。IMIX不使用統一的數據包大小,而是采用多種數據包大小的組合來代表互聯網流量的多樣性。例如,IMIX 可能包含小型數據包(64 字節,常見于 ACK 或控制消息)、中型數據包(大約 576 字節,通常用于特定應用數據)和大型數據包(大約 1500 字節,),并且它們之間有一定的分布比例。
對于 IMIX 數據包大小分布并沒有一個普遍接受的標準。不同的組織可能會根據其特定需求和對網絡流量的觀察,定義自己的 IMIX 配置文件。谷歌和 Meta 在評估網絡設備時都有自己的 IMIX 模式。
假設數據包處理需要以線速處理平均約 345 B大小的數據包,并在1.1GHz的時鐘頻率下運行,那么只需一條pipeline即可滿足需求! 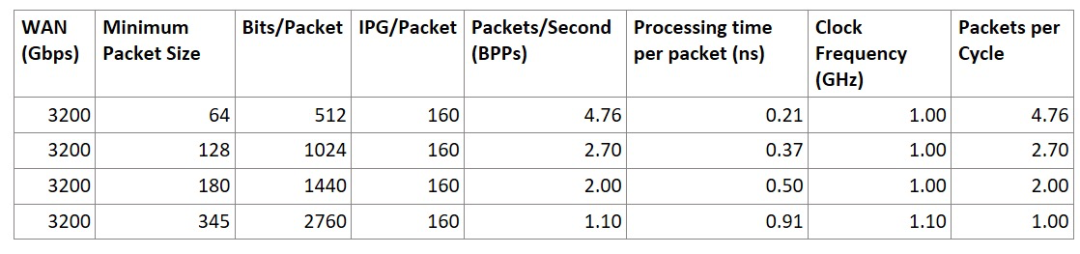
該表顯示了增加平均數據包大小以滿足線路速率時,如何減少pipeline數量
為了應對互聯網流量可能存在突發性的特點,以及可能出現瞬態場景,即平均數據包大小小于350B,且有許多連續的小數據包涌入,這就需要在數據包處理輸入端增設一個突發吸收緩沖區(即圖中所示的入口緩沖區)。一旦這個緩沖區開始填滿,硬件就可以執行優先級感知丟棄策略,即給予控制/保活數據包更高的優先級。丟棄策略的具體規定因供應商而異。
在上一代 Express Silicon (Express4) 中,為了實現3.2Tbps處理能力,并使得平均數據包大小達到約180B,決定增加兩條pipeline。如下圖所示,在實現這兩條pipeline時,它們可以共享本地數據結構、路由表和下一跳內存資源。 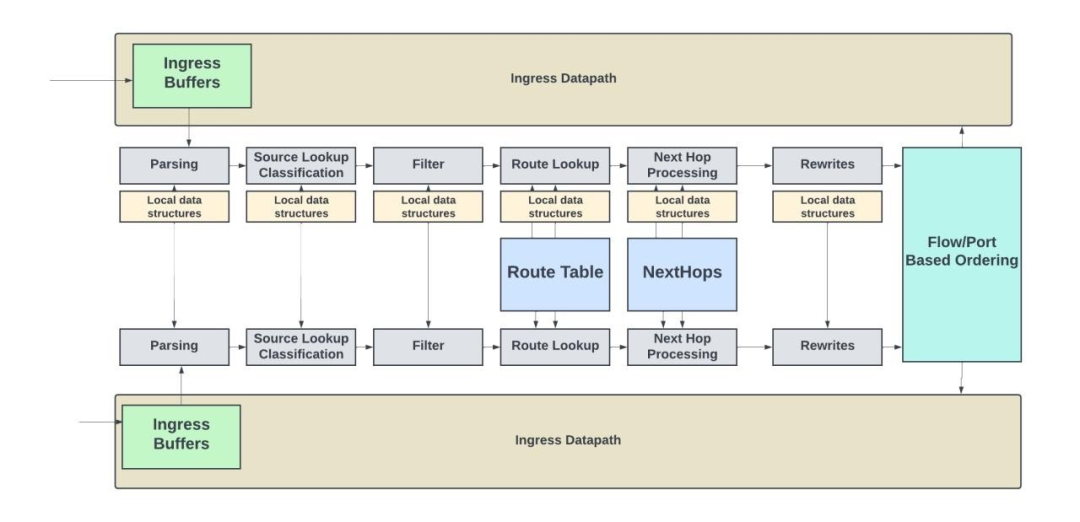 ? ?
? ?
總結
本文闡述了高端路由器中數據包處理引擎所使用的技術,以實現每秒數十億數據包的高性能處理,同時提供足夠的處理靈活性。從宏觀層面概述了數據包處理的基本原理,討論了其如何隨著時間演變,以及網絡芯片供應商在不斷增加廣域網帶寬時面臨的吞吐量擴展挑戰。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19407瀏覽量
231172 -
以太網
+關注
關注
40文章
5460瀏覽量
172718 -
路由器
+關注
關注
22文章
3744瀏覽量
114469 -
VLAN
+關注
關注
1文章
279瀏覽量
35763 -
網絡芯片
+關注
關注
0文章
30瀏覽量
12125
原文標題:高端網絡芯片如何處理數據包?
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

DPDK在AI驅動的高效數據包處理應用
請問在串口通信中數據包的幀頭和幀尾怎樣加入到數據包?
網絡數據包捕獲機制研究
基于Jpcap的數據包捕獲器的設計與實現
什么是數據包?
深度數據包檢測技術研究
基于數據包長度的網絡隱蔽通道







 工商網監
工商網監
評論