") IB Verbs和NVIDIA DOCA GPUNetIO性能測(cè)試
IB Verbs和NVIDIA DOCA GPUNetIO性能測(cè)試
NVIDIA DOCA GPUNetIO 是 NVIDIA DOCA SDK 中的一個(gè)庫(kù),專門(mén)為實(shí)時(shí)在線 GPU 數(shù)據(jù)包處理而設(shè)計(jì)。它結(jié)合了 GPUDirect RDMA 和 GPUDirect Async 等技術(shù),能夠創(chuàng)建以 GPU 為中心的應(yīng)用程序,其中 CUDA 內(nèi)核可以直接與網(wǎng)卡(NIC)通信,從而繞過(guò) CPU 發(fā)送和接收數(shù)據(jù)包,并將 CPU 排除在關(guān)鍵路徑之外。
此前,DOCA GPUNetIO 與 DOCA Ethernet 和 DOCA Flow 僅限于處理以太網(wǎng)傳輸層上的數(shù)據(jù)包傳輸。隨著 DOCA 2.7 的推出,現(xiàn)在有一組擴(kuò)展的 API 使 DOCA GPUNetIO 能夠從 GPU CUDA 內(nèi)核使用 RoCE 或 InfiniBand 傳輸層來(lái)直接支持 RDMA 通信。
本文探討了由支持 DOCA GPUNetIO 的 GPU CUDA 內(nèi)核控制的全新遠(yuǎn)程直接內(nèi)存訪問(wèn)(RDMA)功能,并與性能測(cè)試(perftest)微基準(zhǔn)測(cè)試進(jìn)行了性能比較。
請(qǐng)注意,RDMA 縮寫(xiě)描述的協(xié)議允許從一臺(tái)計(jì)算機(jī)的內(nèi)存到另一臺(tái)計(jì)算機(jī)的內(nèi)存進(jìn)行遠(yuǎn)程直接內(nèi)存訪問(wèn),而無(wú)需任何一臺(tái)計(jì)算機(jī)的操作系統(tǒng)介入。操作示例包括 RDMA 寫(xiě)入和 RDMA 讀取。它不能將與 GPUDirect RDMA 混淆,后者與 RDMA 協(xié)議無(wú)關(guān)。GPUDirect RDMA 是 NVIDIA 在 GPUDirect 技術(shù)系列中啟用的技術(shù)之一,使網(wǎng)卡能夠繞過(guò) CPU 內(nèi)存副本和操作系統(tǒng)例程,直接訪問(wèn) GPU 內(nèi)存發(fā)送或接收數(shù)據(jù)。任何使用以太網(wǎng)、InfiniBand 或 RoCE 的網(wǎng)絡(luò)框架都可以啟用 GPUDirect RDMA。
具有 GPUNetIO 的 RDMA GPU 數(shù)據(jù)路徑
RDMA 可以在兩臺(tái)主機(jī)的主內(nèi)存之間提供直接訪問(wèn),而無(wú)需操作系統(tǒng)、緩存或存儲(chǔ)的介入。這可實(shí)現(xiàn)高吞吐量、低延遲和低 CPU 利用率的數(shù)據(jù)傳輸。這是通過(guò)向遠(yuǎn)程主機(jī)(或?qū)Φ戎鳈C(jī))注冊(cè)并共享本地內(nèi)存區(qū)域來(lái)實(shí)現(xiàn)的,以便遠(yuǎn)程主機(jī)知道如何訪問(wèn)它。
兩個(gè)對(duì)等主機(jī)需要通過(guò) RDMA 交換數(shù)據(jù)的應(yīng)用程序通常遵循三個(gè)基本步驟:
步驟 1–本地配置:每個(gè)對(duì)等主機(jī)在本地創(chuàng)建 RDMA 隊(duì)列和內(nèi)存緩沖區(qū),以便與其他對(duì)等主機(jī)共享。
步驟 2–交換信息:使用帶外(OOB)機(jī)制(例如,Linux 套接字),對(duì)等主機(jī)交換有關(guān)要遠(yuǎn)程訪問(wèn)的 RDMA 隊(duì)列和內(nèi)存緩沖區(qū)的信息。
步驟 3–數(shù)據(jù)路徑:兩個(gè)對(duì)等主機(jī)執(zhí)行 RDMA 讀取、寫(xiě)入、發(fā)送和接收,以使用遠(yuǎn)程內(nèi)存地址來(lái)交換數(shù)據(jù)。
DOCA RDMA 庫(kù)支持按照上面列出的三個(gè)步驟通過(guò) InfiniBand 或 RoCE 實(shí)現(xiàn) RDMA 通信,所有這些步驟均由 CPU 執(zhí)行。通過(guò)引入全新的 GPUNetIO RDMA 功能,應(yīng)用程序可以使用在 GPU 上的 CUDA 內(nèi)核執(zhí)行這 3 個(gè)步驟從而代替 CPU 來(lái)管理 RDMA 應(yīng)用程序的數(shù)據(jù)路徑,而步驟 1 和 2 保持不變,因?yàn)樗鼈兣c GPU 數(shù)據(jù)路徑無(wú)關(guān)。
將 RDMA 數(shù)據(jù)路徑移到 GPU 上的好處與以太網(wǎng)用例中的好處相同。在數(shù)據(jù)處理發(fā)生在 GPU 上的網(wǎng)絡(luò)應(yīng)用程序中,將網(wǎng)絡(luò)通信從 CPU 卸載到 GPU,使其能夠成為應(yīng)用程序的主控制器,消除與 CPU 交互所需的額外延遲,以及了解數(shù)據(jù)何時(shí)準(zhǔn)備就緒及數(shù)據(jù)位于何處,這也釋放了 CPU 資源。此外,GPU 可以同時(shí)并行管理多個(gè) RDMA 隊(duì)列,例如,每個(gè) CUDA 塊都可以在不同的 RDMA 隊(duì)列上發(fā)布 RDMA 操作。
IB Verbs 和 DOCA GPUNetIO 性能測(cè)試
在 DOCA 2.7 中,引入了一個(gè)新的 DOCA GPUNetIO RDMA 客戶端——服務(wù)器代碼示例,以展示新 API 的使用并評(píng)估其正確性。本文分析了 GPUNetIO RDMA 功能與 IB Verbs RDMA 功能之間的性能比較,重現(xiàn)了眾所周知的 perftest 套件中的一個(gè)微基準(zhǔn)測(cè)試。
簡(jiǎn)而言之,perftest 是一組微基準(zhǔn)測(cè)試,用于使用基本的 RDMA 操作測(cè)量?jī)蓚€(gè)對(duì)等主機(jī)(服務(wù)器和客戶端)之間的 RDMA 帶寬(BW)和延遲。盡管網(wǎng)絡(luò)控制部分發(fā)生在 CPU 中,但可以通過(guò)使用 --use_cuda 標(biāo)志啟用 GPUDirect RDMA 來(lái)指定數(shù)據(jù)是否駐留在 GPU 內(nèi)存中。
一般來(lái)說(shuō),RDMA 寫(xiě)入單向帶寬基準(zhǔn)測(cè)試(即 ib_write_bw)在每個(gè) RDMA 隊(duì)列上發(fā)布一系列相同大小消息的寫(xiě)入請(qǐng)求,用于固定迭代次數(shù),并命令網(wǎng)卡執(zhí)行已發(fā)布的寫(xiě)入,這就是所謂的“按門(mén)鈴”程序。為了確保所有寫(xiě)入都已發(fā)出,在進(jìn)入下一次迭代之前,它會(huì)輪詢完成隊(duì)列,等待確認(rèn)每個(gè)寫(xiě)入都已正確執(zhí)行。然后,對(duì)于每個(gè)消息大小,都可以檢索發(fā)布和輪詢所花費(fèi)的總時(shí)間,并以 MB/s 為單位計(jì)算帶寬。
圖 1 顯示了 IB Verbs ib_write_bw perftest 主循環(huán)。在每次迭代中,CPU 都會(huì)發(fā)布一個(gè) RDMA 寫(xiě)入請(qǐng)求列表,命令網(wǎng)卡執(zhí)行這些請(qǐng)求(按門(mén)鈴),然后等待完成后再進(jìn)行下一次迭代。啟用 CUDA 標(biāo)志后,要寫(xiě)入的數(shù)據(jù)包將從 GPU 內(nèi)存本地獲取,而不是從 CPU 內(nèi)存。
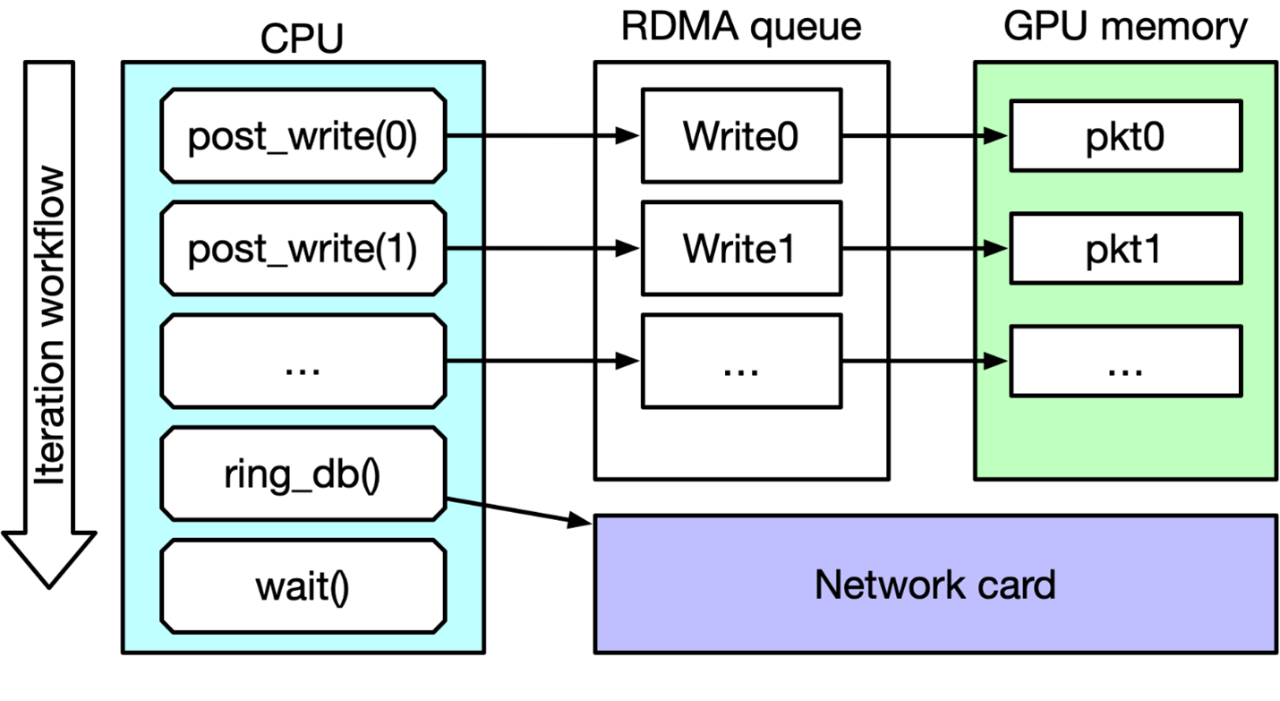
圖 1:IB Verbs ib_write_bw perftest 主循環(huán)
實(shí)驗(yàn)是使用 DOCA 庫(kù)重現(xiàn) ib_write_bw 微基準(zhǔn)測(cè)試,使用 DOCA RDMA 作為 CPU 上的控制路徑以建立客戶端-服務(wù)器連接,并使用 DOCA GPUNetIO RDMA 作為數(shù)據(jù)路徑,在 CUDA 內(nèi)核中發(fā)布寫(xiě)入。這種比較不是同類比較,因?yàn)?perftest 使用 GPUDirect RDMA 來(lái)傳輸數(shù)據(jù),但網(wǎng)絡(luò)通信由 CPU 控制,而 DOCA GPUNetIO 同時(shí)使用 GPUDirect RDMA 和 GPUDirect Async 來(lái)控制網(wǎng)絡(luò)通信和來(lái)自 GPU 的數(shù)據(jù)傳輸。目標(biāo)是證明 DOCA GPUNetIO RDMA 性能與被視為基準(zhǔn)的 IB Verbs perftest 相當(dāng)。
為了重現(xiàn) ib_write_bw 數(shù)據(jù)路徑并測(cè)量發(fā)布每種消息大小的 RDMA 寫(xiě)入操作所需的時(shí)間,CPU 會(huì)記錄一個(gè) CUDA 事件,啟動(dòng) rdma_write_bw CUDA 內(nèi)核,然后記錄第二個(gè) CUDA 事件。這應(yīng)該可以很好地近似 CUDA 內(nèi)核使用 DOCA GPUNetIO 功能發(fā)布 RDMA 寫(xiě)入所需的時(shí)間(以毫秒為單位),如下面的代碼段 1 所示。
Int msg_sizes[MAX_MSG] = {....};
for (int msg_idx = 0; msg_idx < MAX_MSG; msg_idx++) {
? ? ? ? do_warmup();
? ? ? ? cuEventRecord(start_event, stream);
? ? ? ? rdma_write_bw<<>>(msg_sizes[msg_idx], …);
cuEventRecord(end_event, stream);
cuEventSynchronize(end_event);
cuEventElapsedTime(&total_ms, start_event, end_event);
calculate_result(total_ms, msg_sizes[msg_idx], …)
}
在下面的代碼段 2 中,對(duì)于給定的迭代次數(shù),CUDA 內(nèi)核 rdma_write_bw 使用按照弱模式的 DOCA GPUNetIO 設(shè)備功能并行發(fā)布一系列 RDMA 寫(xiě)入,CUDA 塊中的每個(gè) CUDA 線程都會(huì)發(fā)布一個(gè)寫(xiě)操作。
__global__ void rdma_write_bw(struct doca_gpu_dev_rdma *rdma_gpu,
const int num_iter, const size_t msg_size,
const struct doca_gpu_buf_arr *server_local_buf_arr,
const struct doca_gpu_buf_arr *server_remote_buf_arr)
{
struct doca_gpu_buf *remote_buf;
struct doca_gpu_buf *local_buf;
uint32_t curr_position;
uint32_t mask_max_position;
doca_gpu_dev_buf_get_buf(server_local_buf_arr, threadIdx.x, &local_buf);
doca_gpu_dev_buf_get_buf(server_remote_buf_arr, threadIdx.x, &remote_buf);
for (int iter_idx = 0; iter_idx < num_iter; iter_idx++) {
? ? ? doca_gpu_dev_rdma_get_info(rdma_gpu, &curr_position, &mask_max_position);
? ? ? doca_gpu_dev_rdma_write_weak(rdma_gpu,
? ? ? ? ? ? ? ? ? remote_buf, 0,
? ? ? ? ? ? ? ? ? local_buf, 0,
? ? ? ? ? ? ? ? ? msg_size, 0,
? ? ? ? ? ? ? ? ? DOCA_GPU_RDMA_WRITE_FLAG_NONE,
? ? ? ? ? ? ? ? ? (curr_position + threadIdx.x) & mask_max_position);
? ? ? /* Wait all CUDA threads to post their RDMA Write */
? ? ? __syncthreads();
? ? ? if (threadIdx.x == 0) {
? ? ? ? ? /* Only 1 CUDA thread can commit the writes in the queue to execute them */
? ? ? ? ? doca_gpu_dev_rdma_commit_weak(rdma_gpu, blockDim.x);
? ? ? ? ? ? ? ?/* Only 1 CUDA thread can flush the RDMA queue waiting for the actual execution of the writes */
? ? ? doca_gpu_dev_rdma_flush(rdma_gpu);
? ? ? }
? ? ? __syncthreads();
? }
? return;
}
圖 2 描述了代碼段 2。在每次迭代時(shí),GPU CUDA 內(nèi)核都會(huì)并行發(fā)布一系列 RDMA 寫(xiě)入請(qǐng)求,CUDA 塊中的每個(gè) CUDA 線程一個(gè)。在同步所有 CUDA 線程后,只有線程 0 命令網(wǎng)卡執(zhí)行寫(xiě)入并等待完成,然后刷新隊(duì)列,最后再進(jìn)行下一次迭代。
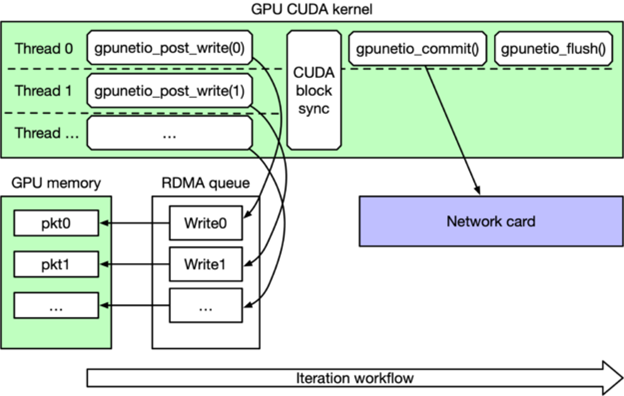
圖 2:DOCA GPUNetIO RDMA 寫(xiě)入性能測(cè)試主循環(huán)
為了比較性能,為 IB Verbs perftest 和 DOCA GPUNetIO perftest 設(shè)置了相同的參數(shù):1 個(gè) RDMA 隊(duì)列,2048 次迭代,每次迭代執(zhí)行 512 次 RDMA 寫(xiě)入,測(cè)試消息大小從 64 字節(jié)到 4096 字節(jié)。
RoCE 基準(zhǔn)測(cè)試已在具有不同 PCIe 拓?fù)涞膬蓚€(gè)系統(tǒng)上執(zhí)行:
系統(tǒng) 1:HPE ProLiant DL380 Gen11 系統(tǒng),配備 NVIDIA GPU L40S 和運(yùn)行在 NIC 模式的 BlueField-3 卡、Intel Xeon Silver 4410Y CPU。GPU 和網(wǎng)卡連接到同一 NUMA 節(jié)點(diǎn)上的兩個(gè)不同 PCIe 插槽(無(wú)專用 PCIe 交換機(jī))。
系統(tǒng) 2:Dell R750 系統(tǒng),配備 NVIDIA H100 GPU 和 ConnectX-7 網(wǎng)卡、Intel Xeon Silver 4314 CPU。GPU 和網(wǎng)卡連接到不同 NUMA 節(jié)點(diǎn)上的兩個(gè)不同 PCIe 插槽(GPUDirect 應(yīng)用程序的最壞情況)。
如下圖所示,兩種 perftest 在兩個(gè)系統(tǒng)上實(shí)現(xiàn)了完全可比較的峰值帶寬(圖 3 和圖 4),報(bào)告以 MB/s 為單位。
具體來(lái)說(shuō),在圖 3 中,DOCA GPUNetIO perftest 帶寬優(yōu)于圖 4 中報(bào)告的 DOCA GPUNetIO perftest 帶寬,因?yàn)橄到y(tǒng)上的拓?fù)洳煌@不僅影響從 GPU 內(nèi)存到網(wǎng)絡(luò)的數(shù)據(jù)移動(dòng)(GPUDirect RDMA),而且影響 GPU 和網(wǎng)卡之間的內(nèi)部通信控制 RDMA 通信(GPUDirect Async)。
由于代碼中不同邏輯的性質(zhì),時(shí)間和帶寬采用不同的方法來(lái)測(cè)量,IB Verbs perftest 使用系統(tǒng)時(shí)鐘,而 DOCA GPUNetIO perftest 則依賴于 CUDA 事件,后者可能具有不同的內(nèi)部時(shí)間測(cè)量開(kāi)銷。
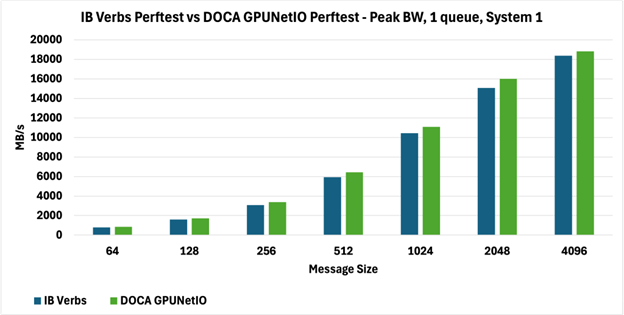
圖 3:Perftest 對(duì)系統(tǒng) 1 上 1 個(gè)隊(duì)列的峰值帶寬(MB/s)進(jìn)行 IB Verbs 與 DOCA GPUNetIO 的比較
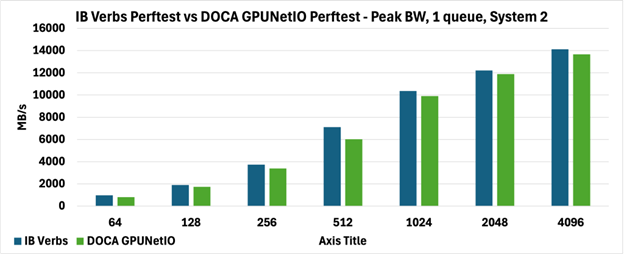
圖 4:Perftest 對(duì)系統(tǒng) 2 上 1 個(gè)隊(duì)列的峰值帶寬(MB/s)進(jìn)行 IB Verbs 與 DOCA GPUNetIO 的比較
請(qǐng)注意,像 perftest 這樣的應(yīng)用程序并不是展示 GPU 利用率優(yōu)勢(shì)的最佳工具,因?yàn)榭蓪?shí)現(xiàn)的并行化程度非常低。DOCA GPUNetIO perftest 進(jìn)行 RDMA 寫(xiě)入是以并行方式發(fā)布在隊(duì)列中的(512 次寫(xiě)入,每次寫(xiě)入由不同的 CUDA 線程執(zhí)行),但發(fā)布所需的時(shí)間非常短(約 4 微秒)。大部分 perftest 時(shí)間都花在網(wǎng)卡實(shí)際執(zhí)行 RDMA 寫(xiě)入、通過(guò)網(wǎng)絡(luò)發(fā)送數(shù)據(jù)和返回上。
這項(xiàng)實(shí)驗(yàn)可以被認(rèn)為是成功的,因?yàn)樗C明了使用 DOCA GPUNetIO RDMA API 與使用常規(guī) IB Verbs 相比不會(huì)引入任何相關(guān)開(kāi)銷,并且在運(yùn)行相同類型的工作負(fù)載和工作流程時(shí)可以滿足性能目標(biāo)。ISV 開(kāi)發(fā)者和最終用戶可以使用 DOCA GPUNetIO RDMA,獲得 GPUDirect 異步技術(shù)的優(yōu)勢(shì),將通信控制卸載到 GPU。
這種架構(gòu)選擇提供了以下優(yōu)勢(shì):
更具可擴(kuò)展性的應(yīng)用程序,能夠同時(shí)并行管理多個(gè) RDMA 隊(duì)列(通常每個(gè) CUDA 塊一個(gè)隊(duì)列)。
能夠利用 GPU 提供的高度并行性,使多個(gè) CUDA 線程并行處理不同的數(shù)據(jù),并以盡可能低的延遲在同一隊(duì)列上發(fā)布 RDMA 操作。
更低的 CPU 利用率,使解決方案獨(dú)立于平臺(tái)(不同的 CPU 架構(gòu)不會(huì)導(dǎo)致顯著的性能差異)。
更少的內(nèi)部總線事務(wù)(例如 PCIe),因?yàn)椴恍枰獙?GPU 上的工作與 CPU 活動(dòng)同步。CPU 不再負(fù)責(zé)發(fā)送或接收 GPU 必須處理的數(shù)據(jù)。
-
以太網(wǎng)
+關(guān)注
關(guān)注
40文章
5460瀏覽量
172709 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5076瀏覽量
103712 -
gpu
+關(guān)注
關(guān)注
28文章
4771瀏覽量
129348 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3053瀏覽量
74323 -
RDMA
+關(guān)注
關(guān)注
0文章
78瀏覽量
8981
原文標(biāo)題:使用 NVIDIA DOCA GPUNetIO 解鎖 GPU 加速的 RDMA
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NVIDIA DOCA 1.5長(zhǎng)期支持版本發(fā)布
使用 NVIDIA DOCA GPUNetIO 進(jìn)行內(nèi)聯(lián) GPU 數(shù)據(jù)包處理
NVIDIA DOCA 應(yīng)用代碼分享活動(dòng)開(kāi)啟注冊(cè)!
利用 NVIDIA DOCA 2.0 改變 IPsec 的部署
《揭秘 NVIDIA DPU & DOCA》 開(kāi)講啦!

《揭秘 NVIDIA DPU & DOCA》 第二講上線!

《揭秘 NVIDIA DPU & DOCA》 第三講上線!

《揭秘 NVIDIA DPU & DOCA》 第五講上線!

《揭秘 NVIDIA DPU & DOCA》 第六講上線!

《揭秘 NVIDIA DPU & DOCA》 第七講上線!

《揭秘 NVIDIA DPU & DOCA》 第八講上線!

使用 NVIDIA DOCA GPUNetIO 實(shí)現(xiàn)實(shí)時(shí)網(wǎng)絡(luò)處理功能
NVIDIA DOCA 2.5 長(zhǎng)期支持版本發(fā)布





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論