 AlphaZero完爆人類棋類游戲 刷新對人工智能的認知
AlphaZero完爆人類棋類游戲 刷新對人工智能的認知
或許“智能爆炸”不會發生,但永遠不要低估人工智能的發展。推出最強圍棋AI AlphaGo Zero不到50天,DeepMind又一次超越了他們自己,也刷新了世人對人工智能的認知。12月5日,包括David Silver、Demis Hassabis等人在內的DeepMind團隊發表論文,提出通用棋類AI AlphaZero,從零開始訓練,除了基本規則沒有任何其他知識,4小時擊敗最強國際象棋AI、2小時擊敗最強將棋AI,8小時擊敗李世石版AlphaGo,連最強圍棋AI AlphaGo Zero也不能幸免:訓練34小時的AlphaZero勝過了訓練72小時的AlphaGo Zero。
由于是通用棋類AI,因此去掉了代表圍棋的英文“Go”,沒有使用人類知識,從零開始訓練,所以用Zero,兩相結合得到“AlphaZero”,這個新AI強在哪里?
世界最強圍棋AI AlphaGo Zero帶給世人的震撼并沒有想象中那么久——不是因為大家都去看誰(沒)跟誰吃飯了,而是DeepMind再次迅速超越了他們自己,超越了我們剩下所有人的想象。
12月5日,距離發布AlphaGo Zero論文后不到兩個月,他們在arXiv上傳最新論文《用通用強化學習算法自我對弈,掌握國際象棋和將棋》(Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm),用看似平淡的標題,平淡地拋出一個炸彈。
其中,DeepMind團隊描述了一個通用棋類AI“AlphaZero”,在不同棋類游戲中,戰勝了所有對手,而這些對手都是各自領域的頂級AI:
戰勝最強國際象棋AI Stockfish:28勝,0負,72平;
戰勝最強將棋AI Elmo:90勝,2平,8負;
戰勝最強圍棋AI AlphaGo Zero:60勝,40負
其中,Stockfish是世界上最強的國際象棋引擎之一,它比最好的人類國際象棋大師還要強大得多。與大多數國際象棋引擎不同,Stockfish是開源的(GPL license)。用戶可以閱讀代碼,進行修改,回饋,甚至在自己的項目中使用它,而這也是它強大的一個原因。
將棋AI Elmo的開發者是日本人瀧澤城,在第27屆世界計算機將棋選手權賽中獲得優勝。Elmo的策略是在對戰中搜索落子在哪個位置勝率更高,判斷對戰形勢,進而調整策略。Elmo名字的由來是electric monkey(電動猴子,越來越強大之意),根據作者的說法也有elastic monkey(橡皮猴子,愈挫愈勇)之意。
而AlphaGo Zero更是不必介紹,相信“阿法元”之名已經傳遍中國大江南北。而AlphaZero在訓練34小時后,也勝過了訓練72小時的AlphaGo Zero。
AlphaZero橫空出世,網上已經炸開了鍋,Reddit網友紛紛評論:AlphaZero已經不是機器的棋了,是神仙棋,非常優美,富有策略性,更能深刻地謀劃(maneuver),完全是在調戲Stockfish。
看著AlphaZero贏,簡直太不可思議了!這根本就不是計算機,這壓根兒就是人啊!
Holy fu*ck,第9場比賽太特么瘋狂了!
DeepMind太神了!
我的神啊!它竟然只玩d4/c4。總體上來看,它似乎比我們訓練的要少得多。
這條消息太瘋狂了。
而知乎上,短短幾小時內也有很多評論:
知乎用戶fffasttime:專治各種不服的DeepMind又出師了,但這次的主攻的內容不再是圍棋了,而是所有的棋類游戲。……之前AlphaGo把圍棋界打得心態崩了,而現在AlphaZero贏的不光是人類棋手,還包括各路象棋的AI作者。
知乎用戶陸君慨:棋類的解決框架一直都是基于 minimax + heuristic。以前圍棋難是因為minimax在有著很大分支的游戲上無法產生足夠的深度,并且heuristic難以設計。Alphago Zero時候就已經證明了cnn很適合做heuristic,而mcts也可以解決深度問題。那為什么別人不做呢?
因為貧窮限制了我們的想象力。
有錢真的是可以為所欲為。
比AlphaGo Zero更強的AlphaZero來了!8小時解決一切棋類!
知乎用戶PENG Bo迅速就發表了感慨,我們取得了他的授權,轉載如下(知乎鏈接見文末):
讀過AlphaGo Zero論文的同學,可能都驚訝于它的方法的簡單。另一方面,深度神經網絡,是否能適用于國際象棋這樣的與圍棋存在諸多差異的棋類?MCTS(蒙特卡洛樹搜索)能比得上alpha-beta搜索嗎?許多研究者都曾對此表示懷疑。
但今天AlphaZero來了(https://arxiv.org/pdf/1712.01815.pdf),它破除了一切懷疑,通過使用與AlphaGo Zero一模一樣的方法(同樣是MCTS+深度網絡,實際還做了一些簡化),它從零開始訓練:
4小時就打敗了國際象棋的最強程序Stockfish!
2小時就打敗了日本將棋的最強程序Elmo!
8小時就打敗了與李世石對戰的AlphaGo v18!
在訓練后,它面對Stockfish取得100盤不敗的恐怖戰績,而且比之前的AlphaGo Zero也更為強大(根據論文后面的表格,訓練34小時的AlphaZero勝過訓練72小時的AlphaGo Zero)。
這令人震驚,因為此前大家都認為Stockfish已趨于完美,它的代碼中有無數人類精心構造的算法技巧。
然而,現在Stockfish就像一位武術大師,碰上了用槍的AlphaZero,被一槍斃命。
喜歡國象的同學注意了:AlphaZero不喜歡西西里防御。
訓練過程極其簡單粗暴。超參數,網絡架構都不需要調整。無腦上算力,就能解決一切問題。
Stockfish和Elmo,每秒種需要搜索高達幾千萬個局面。
AlphaZero每秒種僅需搜索幾萬個局面,就將他們碾壓。深度網絡真是狂拽炫酷。
當然,訓練AlphaZero所需的計算資源也是海量的。這次DeepMind直接說了,需要5000個TPU v1作為生成自對弈棋譜。
不過,隨著硬件的發展,這樣的計算資源會越來越普及。未來的AI會有多強大,確實值得思考。
個人一直認為,MCTS+深度網絡是非常強的組合,因為MCTS可為深度網絡補充邏輯性。我預測,這個組合未來會在更多場合顯示威力,例如有可能真正實現自動寫代碼,自動數學證明。
為什么說編程和數學,因為這兩個領域和下棋一樣,都有明確的規則和目標,有可模擬的環境。(在此之前,深度學習的調參黨和架構黨估計會先被干掉...... 目前很多灌水論文,電腦以后自己都可以寫出來。)
也許在5到20年內,我們會看到《Mastering Programming and Mathematics by General Reinforcement Learning》。然后許多人都要自謀出路了......
一個通用強化學習算法,橫跨多個高難度領域,實現超人性能
David Silver曾經說過,強化學習+深度學習=人工智能(RL+DL=AI)。而深度強化學習也是DeepMind一直以來致力探索的方向。AlphaZero論文也體現了這個思路。論文題目是《用通用強化學習自我對弈,掌握國際象棋和將棋》。可以看見,AlphaGo Zero的作者Julian Schrittwieser也在其中。
 |
對計算機國際象棋的研究和計算機科學一樣古老。巴貝奇、圖靈、香農和馮·諾依曼都設計過硬件、算法和理論來分析國際象棋,以及下國際象棋。象棋后來成為了一代人工智能研究者的挑戰性任務,在高性能的計算機的助力下,象棋程序達到了頂峰,超越了人類的水平。然而,這些系統高度適應它們的領域,如果沒有大量的人力投入,就不能歸納到其他問題。
人工智能的長期目標是創造出可以從最初的原則自我學習的程序。最近,AlphaGo Zero算法通過使用深度卷積神經網絡來表示圍棋知識,僅通過自我對弈的強化學習來訓練,在圍棋中實現了超越人類的表現。在本文中,除了游戲規則之外,我們還應用了一個類似的但是完全通用的算法,我們把這個算法稱為AlphaZero,除了游戲規則之外,沒有給它任何額外的領域知識,這個算法證明了一個通用的強化學習算法可以跨越多個具有挑戰性的領域實現超越人類的性能,并且是以“白板”(tabula rasa)的方式。
1997年,“深藍”在國際象棋上擊敗了人類世界冠軍,這是人工智能的一個里程碑。計算機國際象棋程序在自那以后的20多年里繼續穩步超越人類水平。這些程序使用人類象棋大師的知識和仔細調整的權重來評估落子位置,并結合高性能的alpha-beta搜索函數,利用大量的啟發式和領域特定的適應性來擴展巨大的搜索樹。我們描述了這些增強方法,重點關注2016年TCEC世界冠軍Stockfish;其他強大的國際象棋程序,包括深藍,使用的是非常相似的架構。
在計算復雜性方面,將棋比國際象棋更難:在更大的棋盤上進行比賽,任何被俘的對手棋子都會改變方向,隨后可能會掉到棋盤的任何位置。計算機將棋協會(CSA)的世界冠軍Elmo等最強大的將棋程序,直到最近才擊敗了人類冠軍。這些程序使用與計算機國際象棋程序類似的算法,再次基于高度優化的alpha-beta搜索引擎,并具有許多特定領域的適應性。
圍棋非常適合AlphaGo中使用的神經網絡架構,因為游戲規則是平移不變的(匹配卷積網絡的權重共享結構),是根據棋盤上落子點之間的相鄰點的自由度來定義的,并且是旋轉和反射對稱的(允許數據增加和合成)。此外,動作空間很簡單(可以在每個可能的位置放置一個棋子),而且游戲結果僅限于二元輸贏,這兩者都可能有助于神經網絡的訓練。
國際象棋和將棋可能不太適合AlphaGo的神經網絡架構。這些規則是依賴于位置的(例如棋子可以從第二級向前移動兩步,在第八級晉級)和不對稱的(例如棋子只向前移動,而王翼和后翼易位則不同)。規則包括遠程互動(例如,女王可能在一步之內穿過棋盤,或者從棋盤的遠側將死國王)。國際象棋的行動空間包括棋盤上所有棋手的所有符合規則的目的地;將棋也可以將被吃掉的棋子放回棋盤上。國際象棋和將棋都可能造成勝負之外的平局;實際上,人們認為國際象棋的最佳解決方案就是平局。
AlphaZero:更通用的AlphaGo Zero
AlphaZero算法是AlphaGo Zero算法更通用的版本。它用深度神經網絡和白板(tabula rasa)強化學習算法,替代傳統游戲程序中所使用的手工編碼知識和領域特定增強。
AlphaZero不使用手工編碼評估函數和移動排序啟發式算法,而是利用參數為θ的深度神經網絡(p,v)=fθ(s)。這個神經網絡把棋盤的位置作為輸入,輸出一個落子移動概率矢量p,其中每個動作a的分量為pa = Pr(a | s),標量值v根據位置s估計預期結果z,v ≈E [L| S]。AlphaZero完全從自我對弈中學習這些移動概率和價值估計,然后用學到的東西來指導其搜索。
AlphaZero使用通用的蒙特卡洛樹搜索(MCTS)算法。每個搜索都包含一系列自我對弈模擬,模擬時會從根節點到葉節點將一棵樹遍歷。每次模擬都是通過在每個狀態s下,根據當前的神經網絡fθ,選擇一步棋的走法移動a,這一步具有低訪問次數、高移動概率和高的價值(這些值是從s中選擇a的模擬葉節點狀態上做了平均的)。搜索返回一個向量π,表示移動的概率分布。
AlphaZero中的深度神經網絡參數θ通過自我對弈強化學習(self-play reinforcement learning)來訓練,從隨機初始化參數θ開始。游戲中,MCTS輪流為雙方選擇下哪步棋,at?πt。游戲結束時,根據游戲規則,按照最終的位置sT進行評分,計算結果z:z為-1為輸,0為平局,+1為贏。在反復自我對弈過程中,不斷更新神經網絡的參數θ,讓預測結果vt和游戲結果z之間的誤差最小化,同時使策略向量pt與搜索概率πt的相似度最大化。具體說,參數θ通過在損失函數l上做梯度下降進行調整,這個損失函數l是均方誤差和交叉熵損失之和。
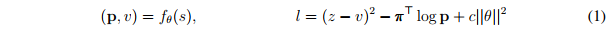
其中,c是控制L2權重正則化水平的參數。更新的參數將被用于之后的自我對弈當中。
AlphaZero與AlphaGo Zero的4大不同
AlphaZero算法與原始的AlphaGo Zero算法有以下幾大不同:
1、AlphaGo Zero是在假設結果為贏/輸二元的情況下,對獲勝概率進行估計和優化。而AlphaZero會將平局或其他潛在結果也納入考慮,對結果進行估計和優化。
2、AlphaGo和AlphaGo Zero會轉變棋盤位置進行數據增強,而AlphaZero不會。根據圍棋的規則,棋盤發生旋轉和反轉結果都不會發生變化。對此,AlphaGo和AlphaGo Zero使用兩種方式應對。首先,為每個位置生成8個對稱圖像來增強訓練數據。其次,在MCTS期間,棋盤位置在被神經網絡評估前,會使用隨機選擇的旋轉或反轉進行轉換,以便MonteCarlo評估在不同的偏差上進行平均。而在國際象棋和將棋中,棋盤是不對稱的,一般來說對稱也是不可能的。因此,AlphaZero不會增強訓練數據,也不會在MCTS期間轉換棋盤位置。
3、在AlphaGo Zero中,自我對弈是由以前所有迭代中最好的玩家生成的。而這個“最好的玩家”是這樣選擇出來的:每次訓練結束后,都會比較新玩家與最佳玩家;如果新玩家以55%的優勢獲勝,那么它將成為新的最佳玩家,自我對弈也將由這個新玩家產生的。AlphaZero只維護單一的一個神經網絡,這個神經網絡不斷更新,而不是等待迭代完成。自我對弈是通過使用這個神經網絡的最新參數生成的,省略了評估步驟和選擇最佳玩家的過程。
4、使用的超參數不同:AlphaGo Zero通過貝葉斯優化調整搜索的超參數;AlphaZero中,所有對弈都重復使用相同的超參數,因此無需進行針對特定某種游戲的調整。唯一的例外是為保證探索而添加到先驗策略中的噪音;這與棋局類型典型移動數量成比例。
奢華的計算資源:5000個第一代TPU,64個第二代TPU,碾壓其他棋類AI
像AlphaGo Zero一樣,棋盤狀態僅由基于每個游戲的基本規則的空間平面編碼。下棋的行動則是由空間平面或平面矢量編碼,也是僅基于每種游戲的基本規則。
作者將AlphaZero應用在國際象棋、將棋和圍棋中,都使用同樣的算法設置、網絡架構和超參數。他們為每一種棋都單獨訓練了一個AlphaZero。訓練進行了700,000步(minibatch大小為4096),從隨機初始化的參數開始,使用5000個第一代TPU生成自我對弈,使用64個第二代TPU訓練神經網絡。
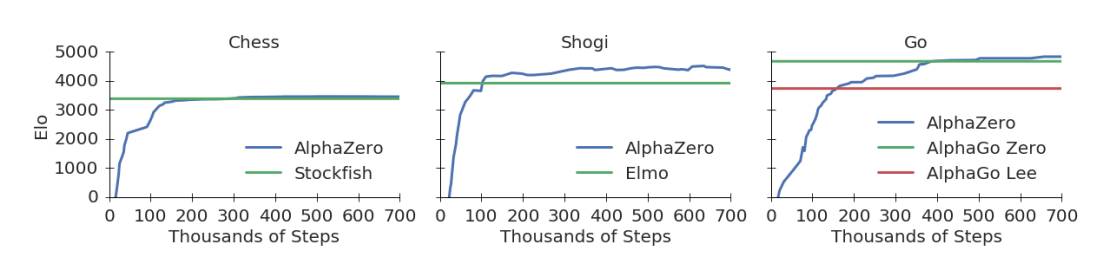
下面的圖1展示了AlphaZero在自我對弈強化學習中的性能。下國際象棋,AlphaZero僅用了4小時(300k步)就超越了Stockfish;下將棋,AlphaZero僅用了不到2小時(110k步)就超越了Elmo;下圍棋,AlphaZero不到8小時(165k步)就超越了李世石版的AlphaGo。
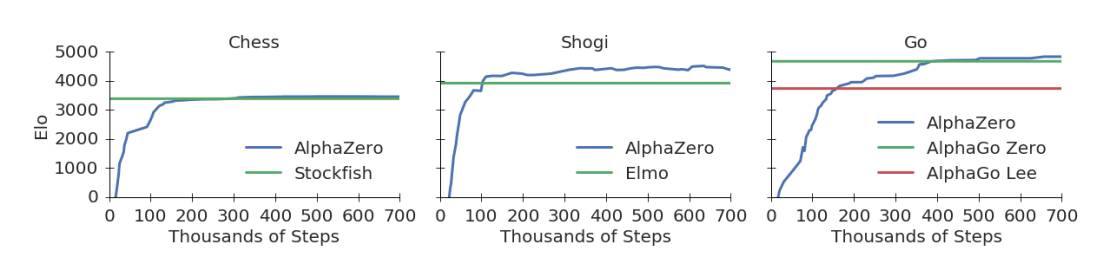
圖1:訓練AlphaZero 70萬步。Elo 等級分是根據不同玩家之間的比賽評估計算得出的,每一步棋有1秒的思考時間。a. AlphaZero在國際象棋上的表現,與2016 TCEC世界冠軍程序Stockfish對局;b. AlphaZero在將棋上的表現,與2017 CSA世界冠軍程序Elmo對局;c. AlphaZero在圍棋上的表現,與AlphaGo Lee和AlphaGo Zero(20 block / 3 天)對戰。
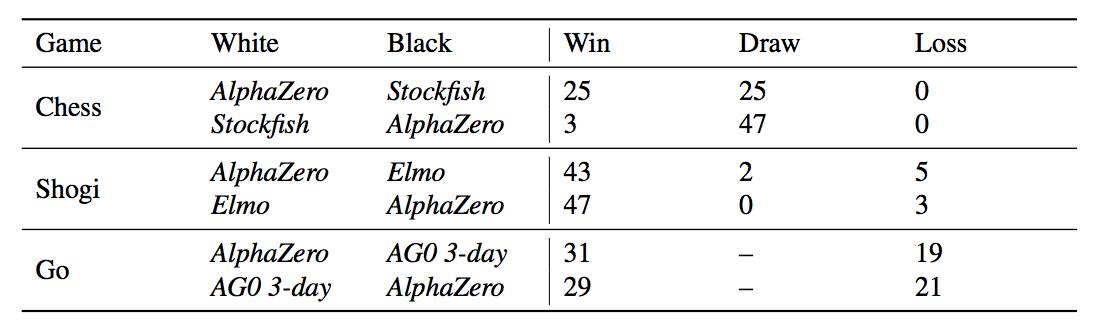
表1:AlphaZero視角下,在比賽中贏,平局或輸的局數。經過3天的訓練,AlphaZero分別與Stockfish,Elmo以及之前發布的AlphaGo Zero在國際象棋、將棋和圍棋分別進行100場比賽。每個AI每步棋都有1分鐘的思考時間。
他們還使用完全訓練好的AlphaZero與Stockfish、Elmo和AlphaGo Zero(訓練了3天)分別在國際象棋、將棋和圍棋中對比,對局100回,每下一步的時長控制在1分鐘。AlphaZero和前一版AlphaGo Zero使用一臺帶有4個TPU的機器訓練。Stockfish和Elmo都使用最強版本,使用64線1GB hash的機器。AlphaZero擊敗了所有選手,與Stockfish對戰全勝,與Elmo對戰輸了8局。
此外,他們還比較了Stockfish和Elmo使用的state-of-the-art alpha-beta搜索引擎,分析了AlphaZero的MCTS搜索的相對性能。AlphaZero在國際象棋中每秒搜索8萬個局面(position),在將棋中搜索到4萬個。相比之下,Stockfish每秒搜索7000萬個,Elmo每秒能搜索3500萬個局面。AlphaZero通過使用深度神經網絡,更有選擇性地聚焦在最有希望的變化上來補償較低數量的評估,就像香農最初提出的那樣,是一種更“人性化”的搜索方法。圖2顯示了每個玩家相對于思考時間的可擴展性,通過Elom量表衡量,相對于Stockfish或者Elmo 40ms的思考時間。AlphaZero的MCTS的思維時間比Stockfish或Elmo更有效,這對人們普遍持有的觀點,也即認為alpha-beta搜索在這些領域本質上具有優越性,提出了質疑。
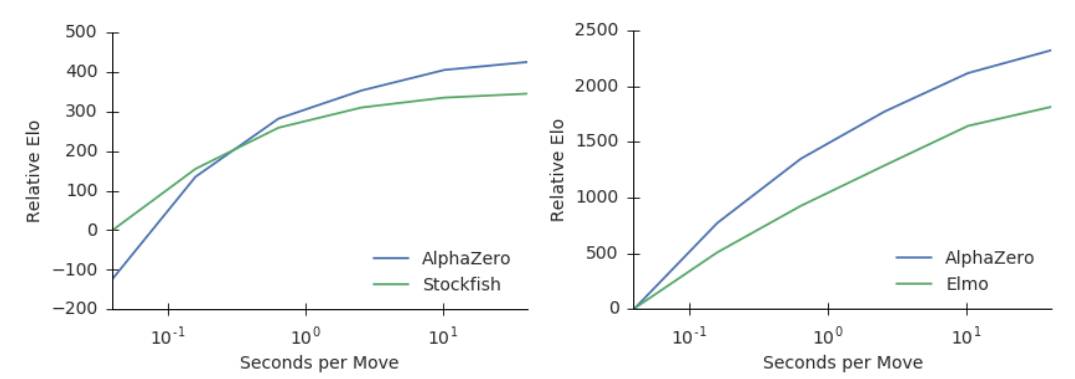
圖2:用每步棋的思考時間來衡量AlphaZero的可擴展性,以Elo作為衡量標準。a. 在國際象棋中,AlphaZero和Stockfish的表現,橫軸表示每步棋的思考時間。b. 在將棋中,AlphaZero和Elmo的表現,橫軸表示每步棋的思考時間。
分析10萬+人類開局,AlphaZero確實掌握了國際象棋,alpha-beta搜索并非不可超越
最后,我們分析了AlphaZero發現的國際象棋知識。表2分析了人類最常用的開局方式(在人類國際象棋游戲在線數據庫中玩過超過10萬次的opening)。在自我訓練期間,這些開局方式被AlphaZero獨立地發現和對弈。以每個人類開局方式為開始,AlphaZero徹底擊敗Stockfish,表明它確實掌握了廣泛的國際象棋知識。

表2:對12種最受歡迎的人類的開局(在一個在線數據庫的出現次數超過10萬次)的分析。每個開局都用ECO代碼和通用名稱標記。這張圖顯示了自我對弈的比例,其中AlphaZero都是先手。
在過去的幾十年里,國際象棋代表了人工智能研究的頂峰。State-of-the-art的程序是建立在強大的engine的基礎上的,這些engine可以搜索數以百萬計的位置,利用人工的特定領域的專業知識和復雜的領域適應性。
AlphaZero是一種通用的強化學習算法,最初是為了圍棋而設計的,它在幾小時內取得了優異的成績,搜索次數減少了1000倍,而且除了國際象棋的規則外,不需要任何領域知識。此外,同樣的算法在沒有修改的情況下,也適用于更有挑戰性的游戲,在幾小時內再次超越了當前最先進的水平。
-
AI
+關注
關注
87文章
31536瀏覽量
270353 -
AlphaGo
+關注
關注
3文章
79瀏覽量
27840
原文標題:【重磅】AlphaZero煉成最強通用棋類AI,DeepMind強化學習算法8小時完爆人類棋類游戲
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論