 自然語言處理技術入門之基于關鍵詞生成文本的技術實現過程
自然語言處理技術入門之基于關鍵詞生成文本的技術實現過程
文章節選自《自然語言處理技術入門與實戰》
在自然語言處理中,另外一個重要的應用領域,就是文本的自動撰寫。關鍵詞、關鍵短語、自動摘要提取都屬于這個領域中的一種應用。不過這些應用,都是由多到少的生成。這里我們介紹其另外一種應用:由少到多的生成,包括句子的復寫,由關鍵詞、主題生成文章或者段落等。
基于關鍵詞的文本自動生成模型
本章第一節就介紹基于關鍵詞生成一段文本的一些處理技術。其主要是應用關鍵詞提取、同義詞識別等技術來實現的。下面就對實現過程進行說明和介紹。
場景
在進行搜索引擎廣告投放的時候,我們需要給廣告撰寫一句話描述。一般情況下模型的輸入就是一些關鍵詞。比如我們要投放的廣告為鮮花廣告,假設廣告的關鍵詞為:“鮮花”、“便宜”。對于這個輸入我們希望產生一定數量的候選一句話廣告描述。
對于這種場景,也可能輸入的是一句話,比如之前人工撰寫了一個例子:“這個周末,小白鮮花只要99元,并且還包郵哦,還包郵哦!”。需要根據這句話復寫出一定數量在表達上不同,但是意思相近的語句。這里我們就介紹一種基于關鍵詞的文本(一句話)自動生成模型。
原理
模型處理流程如圖1所示。
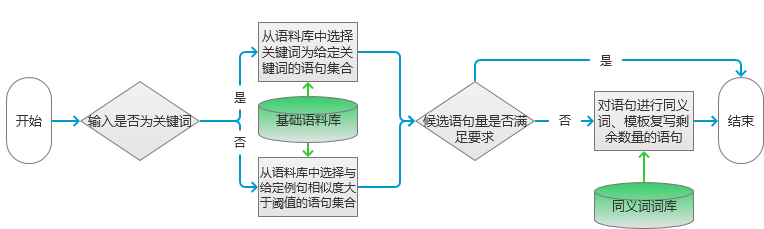
圖1
首先根據輸入的數據類型不同,進行不同的處理。如果輸入的是關鍵詞,則在語料庫中選擇和輸入關鍵詞相同的語句。如果輸入的是一個句子,那么就在語料庫中選擇和輸入語句相似度大于指定閾值的句子。
對于語料庫的中句子的關鍵詞提取的算法,則使用之前章節介紹的方法進行。對于具體的算法選擇可以根據自己的語料庫的形式自由選擇。
圖2
語句相似度計算,這里按照圖2左邊虛線框中的流程進行計算:
首先對待計算的兩個語句進行分詞處理,對于分詞后的語句判斷其是否滿足模板變換,如果滿足則直接將語句放入候選集,并且設置相似度為0。如果不滿足則進入到c)步進行計算。
判斷兩個語句是否滿足模板變換的流程圖,如圖2中右邊虛線框所標記的流程所示:(1)首先判斷分詞后,兩個句子的詞是不是完全一樣,而只是位置不同,如果是則滿足模板變換的條件。(2)如果詞不完全相同,就看看對不同的詞之間是否可以進行同義詞變換,如果能夠進行同義詞變換,并且變換后的語句兩個句子去公共詞的集合,該集合若為某一句話的全部詞集合,則也滿足模板變換條件。(3)如果上述兩個步驟都不滿足,則兩個句子之間不滿足模板變換。
對兩個句子剩余的詞分別兩兩計算其詞距離。假如兩個句子分別剩余的詞為,句1:“鮮花”、“多少錢”、“包郵”。句2:“鮮花”、“便宜”、“免運費”。那么其距離矩陣如下表所示:
得到相似矩陣以后,就把兩個句子中相似的詞替換為一個,假設我們這里用“包郵”替換掉“免運費”。那么兩個句子的詞向量就變為:句1:<鮮花、多少錢、包郵>,句2:<鮮花、便宜、包郵>。
對于兩個句子分別構建bi-gram統計向量,則有:(1)句1:< begin,鮮花>、<鮮花,多少錢>、<多少錢,包郵>、<包郵,end>。(2)句2:< begin,鮮花>、<鮮花,便宜>、<便宜,包郵>、<包郵,end>。
這兩個句子的相似度由如下公式計算:

所以上面的例子的相似度為:1.0-2.0*2/8=0.5。
完成候選語句的提取之后,就要根據候選語句的數量來判斷后續操作了。如果篩選的候選語句大于等于要求的數量,則按照句子相似度由低到高選取指定數量的句子。否則要進行句子的復寫。這里采用同義詞替換和根據指定模板進行改寫的方案。
實現
實現候選語句計算的代碼如下:
Map
if (type == 0) {//輸入為關鍵詞
result = getKeyWordsSentence(keyWordsList);
}else {
result = getWordSimSentence(sentence);
}
//得到候選集數量大于等于要求的數量則對結果進行裁剪
if (result.size() >= number) {
result = sub(result, number);
}else {
//得到候選集數量小于要求的數量則對結果進行添加
result = add(result, number);
}
首先根據輸入的內容形式選擇不同的生成模式進行語句生成。這一步的關鍵在于對語料庫的處理,對于相似關鍵詞和相似語句的篩選。對于關鍵詞的篩選,我們采用布隆算法進行,當然也可以采用索引查找的方式進行。對于候選語句,我們首先用關鍵詞對于語料庫進行一個初步的篩選。確定可能性比較大的語句作為后續計算的語句。
對于得到的候選結果,我們都以map的形式保存,其中key為后續語句,value為其與目標的相似度。之后按照相似度從低到高進行篩選。至于map的排序我們在之前的章節已經介紹了,這里就不再重復了。
實現語句相似篩選計算的代碼如下。
for (String sen : sentenceList) {
//對待識別語句進行分詞處理
List
List
//首先判斷兩個語句是不是滿足目標變換
boolean isPatternSim = isPatternSimSentence(wordsList1, wordsList2);
if (!isPatternSim) {//不滿足目標變換
//首先計算兩個語句的bi-gram相似度
double tmp = getBigramSim(wordsList1, wordsList2);
//這里的篩選條件是相似度小于閾值,因為bi-gram的相似度越小,代表兩者越相似
if (threshold > tmp) {
result.put(sen,tmp);
}
}else {
result.put(sen,0.0);
}
}
首先對待識別的兩個語句進行分詞,并對分詞后的結果進行模板轉換的識別,如果滿足模板轉換的條件,則將語句作為候選語句,并且賦值一個最小的概率。如果不滿足則計算兩者的bi-gram的相似度。再根據閾值進行篩選。
這里使用的bi-gram是有改進的,而常規的bi-gram是不需要做比例計算的。這里進行這個計算是為了避免不同長度的字符的影響。對于相似度的度量也可以根據自己的實際情況選擇合適的度量方式進行。
拓展
本節處理的場景是:由文本到文本的生成。這個場景一般主要涉及:文本摘要、句子壓縮、文本復寫、句子融合等文本處理技術。其中本節涉及文本摘要和句子復寫兩個方面的技術。文本摘要如前所述主要涉及:關鍵詞提取、短語提取、句子提取等。句子復寫則根據實現手段的不同,大致可以分為如下幾種。
基于同義詞的改寫方法。這也是本節使用的方式,這種方法是詞匯級別的,能夠在很大程度上保證替換后的文本與原文語義一致。缺點就是會造成句子的通順度有所降低,當然可以結合隱馬爾科夫模型對于句子搭配進行校正提升整體效果。
基于模板的改寫方法。這也是本節使用的方式。該方法的基本思想是,從大量收集的語料中統計歸納出固定的模板,系統根據輸入句子與模板的匹配情況,決定如何生成不同的表達形式。假設存在如下的模板。
rzv n, a a ——> a a, rzv n
那么對于(輸入):這/rzv, 鮮花/n, 真/a, 便宜/a就可以轉換為(輸出):真/a, 便宜/a, 這/rzv, 鮮花/n該方法的特點是易于實現,而且處理速度快,但問題是模板的通用性難以把握,如果模板設計得過于死板,則難以處理復雜的句子結構,而且,能夠處理的語言現象將受到一定的約束。如果模板設計得過于靈活,往往產生錯誤的匹配。
基于統計模型和語義分析生成模型的改寫方法。這類方法就是根據語料庫中的數據進行統計,獲得大量的轉換概率分布,然后對于輸入的語料根據已知的先驗知識進行替換。這類方法的句子是在分析結果的基礎上進行生成的,從某種意義上說,生成是在分析的指導下實現的,因此,改寫生成的句子有可能具有良好的句子結構。但是其所依賴的語料庫是非常大的,這樣就需要人工標注很多數據。對于這些問題,新的深度學習技術可以解決部分的問題。同時結合知識圖譜的深度學習,能夠更好地利用人的知識,最大限度地減少對訓練樣本的數據需求。
RNN模型實現文本自動生成
6.1.2節介紹了基于短文本輸入獲得長文本的一些處理技術。這里主要使用的是RNN網絡,利用其對序列數據處理能力,來實現文本序列數據的自動填充。下面就對其實現細節做一個說明和介紹。
場景
在廣告投放的過程中,我們可能會遇到這種場景:由一句話生成一段描述文本,文本長度在200~300字之間。輸入也可能是一些主題的關鍵詞。
這個時候我們就需要一種根據少量文本輸入產生大量文本的算法了。這里介紹一種算法:RNN算法。在5.3節我們已經介紹了這個算法,用該算法實現由拼音到漢字的轉換。其實這兩個場景的模式是一樣的,都是由給定的文本信息,生成另外一些文本信息。區別是前者是生成當前元素對應的漢字,而這里是生成當前元素對應的下一個漢字。
原理
同5.3節一樣,我們這里使用的還是Simple RNN模型。所以整個計算流程圖如圖3所示。

圖3
在特征選擇的過程中,我們需要更多地考慮上下兩段之間的銜接關系、一段文字的長度、段落中感情變化、措辭變換等描述符提取。這樣能更好地實現文章自然的轉承啟合。
在生成的文章中,對于形容詞、副詞的使用可以給予更高的比重,因為形容詞、副詞一般不會影響文章的結構,以及意思的表達,但同時又能增加文章的吸引力。比如最好的,最漂亮的,最便宜的等,基本都是百搭的詞,對于不同的名詞或者動名詞都可以進行組合,同時讀者看到以后,一般都有欲望去深度了解。
對于和主題相關的詞,可以在多處使用,如果能替換為和主題相關的詞都盡量替換為和主題相關的詞。因為這個不僅能提升文章的連貫性,還能增加主題的曝光率。
上面這些是對于廣告場景提出的一些經驗之談,其他場景的模式或許不太適用,不過可以根據自己的場景確定具體的優化策略。
具體的計算流程和5.3節基本一致,在這里就不再贅述了。
代碼
實現特征訓練計算的代碼如下:
public double train(List
alreadyTrain = true;
double minError = Double.MAX_VALUE;
for (int i = 0; i < totalTrain; i++) {
//定義更新數組
double[][] weightLayer0_update = new double[weightLayer0.length][weightLayer0[0].length];
double[][] weightLayer1_update = new double[weightLayer1.length][weightLayer1[0].length];
double[][] weightLayerh_update = new double[weightLayerh.length][weightLayerh[0].length];
List
List
double[] hiddenLayerInitial = new double[hiddenLayers];
//對于初始的隱含層變量賦值為0
Arrays.fill(hiddenLayerInitial, 0.0);
hiddenLayerInput.add(hiddenLayerInitial);
double overallError = 0.0;
//前向網絡計算預測誤差
overallError = propagateNetWork(x, y, hiddenLayerInput,
outputLayerDelta, overallError);
if (overallError < minError) {
minError = overallError;
}else {
continue;
}
first2HiddenLayer = Arrays.copyOf(hiddenLayerInput.get(hiddenLayerInput.size()-1), hiddenLayerInput.get(hiddenLayerInput.size()-1).length);
double[] hidden2InputDelta = new double[weightLayerh_update.length];
//后向網絡調整權值矩陣
hidden2InputDelta = backwardNetWork(x, hiddenLayerInput,
outputLayerDelta, hidden2InputDelta,weightLayer0_update, weightLayer1_update, weightLayerh_update);
weightLayer0 = matrixAdd(weightLayer0, matrixPlus(weightLayer0_update, alpha));
weightLayer1 = matrixAdd(weightLayer1, matrixPlus(weightLayer1_update, alpha));
weightLayerh = matrixAdd(weightLayerh, matrixPlus(weightLayerh_update, alpha));
}
return -1.0;
}
首先對待調整的變量進行初始化,在完成這一步之后,就開始運用前向網絡對輸入值進行預測,完成預測之后,則運用后向網絡根據預測誤差對各個權值向量進行調整。
這個過程需要注意的是,每次權值的更新不是全量更新,而是根據學習速率alpha來進行更新的。其他的步驟基本和之前描述的一樣。
實現預測計算的代碼如圖下:
public double[] predict(double[] x) {
if (!alreadyTrain) {
new IllegalAccessError("model has not been trained, so can not to be predicted!!!");
}
double[] x2FirstLayer = matrixDot(x, weightLayer0);
double[] firstLayer2Hidden = matrixDot(first2HiddenLayer, weightLayerh);
if (x2FirstLayer.length != firstLayer2Hidden.length) {
new IllegalArgumentException("the x2FirstLayer length is not equal with firstLayer2Hidden length!");
}
for (int i = 0; i < x2FirstLayer.length; i++) {
firstLayer2Hidden[i] += x2FirstLayer[i];
}
firstLayer2Hidden = sigmoid(firstLayer2Hidden);
double[] hiddenLayer2Out = matrixDot(firstLayer2Hidden, weightLayer1);
hiddenLayer2Out = sigmoid(hiddenLayer2Out);
return hiddenLayer2Out;
}
在預測之前首先要確定模型是不是已經訓練完成,如果沒有訓練完成,則要先進行訓練得到預測模型。當然這是一個跟具體業務邏輯有關的校驗,這主要是針對預測和訓練分開的情況,如果訓練和預測是在一個流程內的,則也可以不用校驗。
在得到訓練模型之后,就根據前向網絡的流程逐步計算,最終得到預測值。因為我們這里是一個分類問題,所以最終是選擇具有最大概率的字作為最終的輸出。
拓展
文本的生成,按照輸入方式不同,可以分為如下幾種:
文本到文本的生成。即輸入的是文本,輸出的也是文本。
圖像到文本。即輸入的是圖像,輸出的是文本。
數據到文本。即輸入的是數據,輸出的是文本。
其他。即輸入的形式為非上面三者,但是輸出的也是文本。因為這類的輸入比較難歸納,所以就歸為其他了。
其中第2、第3種最近發展得非常快,特別是隨著深度學習、知識圖譜等前沿技術的發展。基于圖像生成文本描述的試驗成果在不斷被刷新。基于GAN(對抗神經網絡)的圖像文本生成技術已經實現了非常大的圖譜,不僅能夠根據圖片生成非常好的描述,還能根據文本輸入生成對應的圖片。
由數據生成文本,目前主要應用在新聞撰寫領域。中文和英文的都有很大的進展,英文的以美聯社為代表,中文的則以騰訊公司為代表。當然這兩家都不是純粹地以數據為輸入,而是綜合了上面4種情況的新聞撰寫。
從技術上來說,現在主流的實現方式有兩種:一種是基于符號的,以知識圖譜為代表,這類方法更多地使用人的先驗知識,對于文本的處理更多地包含語義的成分。另一種是基于統計(聯結)的,即根據大量文本學習出不同文本之間的組合規律,進而根據輸入推測出可能的組合方式作為輸出。隨著深度學習和知識圖譜的結合,這兩者有明顯的融合現象,這應該是實現未來技術突破的一個重要節點。
-
自然語言
+關注
關注
1文章
291瀏覽量
13400
原文標題:如何使用 RNN 模型實現文本自動生成 | 贈書
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論