 對2017年深度學習所取得的成就進行盤點
對2017年深度學習所取得的成就進行盤點
機器學習將成為基本技能,學習機器學習永遠不會遲編者按:人工智能正在日益滲透到所有的技術領域。而機器學習(ML)是目前最活躍的分支。最近幾年,ML取得了許多重要進展。其中一些因為事件跟大眾關系密切而引人矚目,而有的雖然低調但意義重大。Statsbot一直在持續評估深度學習的各項成就。值此年終之際,他們的團隊決定對過去一年深度學習所取得的成就進行盤點。
1. 文字
1.1. Google自然機器翻譯
將近1年前,Google發布了新一代的Google Translate。這家公司還介紹了其網絡架構遞歸神經網絡(RNN)的細節情況。
其關鍵成果是:將跟人類翻譯準確率的差距縮小了55%—85%(由人按照6個等級進行評估)。如果沒有像Google手里的那么大規模的數據集的話,是很難用這一模型再生出好結果的。

1.2. 談判。能否成交?
你大概已經聽說過Facebook把它的聊天機器人關閉這則愚蠢的新聞了,因為那機器人失去了控制并且發明了自己的語言。Facebook做這個聊天機器人的目的是為了協商談判,跟另一個代理進行文字上的談判,以期達成交易:比如怎么分攤物品(書、帽等)。每一個代理在談判時都有自己的目標,但是對方并不知道自己的目標。不能達成交易就不能推出談判。
出于訓練的目的,他們收集了人類談判協商的數據集然后做一個有監督的遞歸渦輪里面對它進行訓練。接著,他們用強化學習訓練代理,讓它自己跟自己講話,條件限制是語言跟人類類似。
機器人學會了一條真正的談判策略——假裝對交易的某個方面展現出興趣,然后隨后放棄這方面的訴求從而讓自己的真正目標受益。這是創建此類交互式機器人的第一次嘗試,結果還是相當成功的。
當然,說這個機器人發明了自己的語言完全就是牽強附會了。在訓練(跟同一個代理進行協商談判)的時候,他們取消了對文字與人類相似性的限制,然后算法就修改了交互的語言。沒什么特別。
過去幾年,遞歸網絡的發展一直都很活躍,并且應用到了很多的任務和應用中。RNN的架構已經變得復雜許多,但在一些領域,簡單的前向網絡——DSSM也能取得類似的結果。比方說,此前Google用LSTM在郵件功能Smart Reply上也已經達到了相同的質量。此外,Yandex還基于此類網絡推出了一個新的搜索引擎。
2. 語音
2.1. WaveNet:裸音頻的生成式模型
DeepMind的員工在文章中介紹了音頻的生成。簡單來說,研究人員在之前圖像生成(PixelRNN和PixelCNN)的基礎上做出了一個自回歸的完全卷積WaveNet模型。
該網絡經過了端到端的訓練:文本作為輸入,音頻做出輸出。研究取得了出色的結果,因為跟人類的差異減少了50%。
這種網絡的主要劣勢是生產力低,由于自回歸的關系,聲音是串行生產的,所以一秒鐘的音頻要1到2分鐘才能生成。
我們來看看……哦對不起,是聽聽這個例子。
如果你撤銷網絡對輸入文字的依賴,只留下對之前生成音素的依賴,則網絡就能生成類似人類語言的音素,但這樣的音頻是沒有意義的。
聽聽這個生成語音的例子。
同一個模型不僅可以應用到語音上,而且也可以應用在創作音樂等事情上。想象一下用這個模型(用某個鋼琴游戲的數據集訓練,也是沒有依賴輸入數據的)生成音頻。
2.2. 理解唇語
唇語理解是另一個深度學習超越人類的成就和勝利。
Google Deepmind跟牛津大學合作在《唇語自然理解》這篇文章中介紹了他們的模型(通過電視數據集訓練)是如何超越職業唇語解讀師的。
這個數據集總共有包含100000個句子的音視頻。模型:音頻用LSTM,視頻用CNN+LSTM。這兩個狀態向量提供給最后的LSTM,然后再生成結果(字符)。
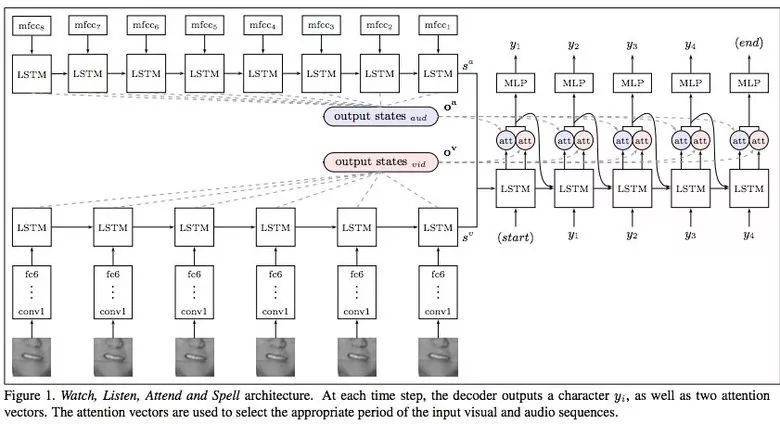
訓練過程中用到了不同類型的輸入數據:音頻、視頻以及音視頻。換句話說,這是一種“多渠道”模型。
2.3. 合成奧巴馬:從音頻中合成嘴唇動作
華盛頓大學干了一件嚴肅的工作,他們生成了奧巴馬總統的唇語動作。之所以要選擇他是因為他講話的網上視頻很多(17小時的高清視頻)。
光靠網絡他們是沒有辦法取得進展的,因為人工的東西太多。因此,文章作者構思了一些支撐物(或者花招,你要是喜歡這么說的話)來改進紋理和時間控制。
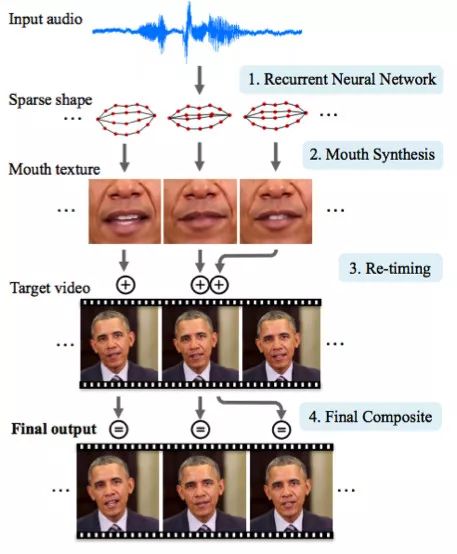
你可以看到,結果是很驚艷的。很快,你就沒法相信這位總統的視頻了。
3. 計算機視覺
3.1. OCR:Google Maps和StreetView(街景)
Google Brain Team在博客和文章中報告了他們是如何引入一種新的OCR(光學字符識別)引擎給Maps,然后用來識別街道名牌和商店標志。
在技術開發的過程中,該公司編譯了一種新的FSNS(法國街道名牌),里面包含有很多復雜的情況。
為了識別每一塊名牌,該網絡利用了名牌多至4張的照片。特征由CNN來析取,在空間注意(考慮了像素坐標)的幫助下進行擴充,然后再把結果送給LSTM。
同樣的方法被應用到識別廣告牌上的商店名上面(里面會有大量的“噪聲”數據,網絡本身必須“關注”合適的位置)。這一算法應用到了800億張圖片上。
3.2. 視覺推理
有一種任務類型叫做視覺推理,神經網絡被要求根據一張照片來回答問題。比方說:“圖中橡皮材料的物品跟黃色金屬圓柱體的數量是不是一樣的?”這個問題可不是小問題,直到最近,解決的準確率也只有68.5%。

不過Deepind團隊再次取得了突破:在CLEVR數據集上他們達到了95.5%的準確率,甚至超過了人類。
這個網絡的架構非常有趣:
把預訓練好的LSTM用到文本問題上,我們就得到了問題的嵌入。
利用CNN(只有4層)到圖片上,就得到了特征地圖(歸納圖片特點的特征)
接下來,我們對特征地圖的左邊片段進行兩兩配對(下圖的黃色、藍色、紅色),給每一個增加坐標與文本嵌入。
我們通過另一個網絡來跑所有這些三元組然后匯總起來。
結果呈現再到一個前向反饋網絡里面跑,然后提供softmax答案。

3.3. Pix2Code應用
Uizard公司創建了一個有趣的神經網絡應用:根據界面設計器的截屏生成布局代碼:
這是極其有用的一種神經網絡應用,可以幫助軟件開發變得容易一些。作者聲稱他們取得了77%的準確率。然而,這仍然在研究中,還沒有討論過真正的使用情況。
他們還沒有開源代碼或者數據集,但是承諾會上傳。
3.4. SketchRNN:教機器畫畫
你大概已經看過Google的Quick, Draw!了,其目標是在20秒之內畫出各種對象的草圖。這家公司收集了這個數據集以便來教神經網絡畫畫,就像Google在他們的博客和文章中所說那樣。
這份數據集包含了7萬張素描,Google現在已經開放給公眾了。素描不是圖片,而是畫畫詳細的向量表示(用戶按下“鉛筆”畫畫,畫完時釋放所記錄的東西)。
研究人員已經把RNN作為編碼/解碼機制來訓練該序列到序列的變自編碼器(Sequence-to-Sequence Variational Autoencoder)。

最終,作為自編碼器應有之義,該模型將得到一個歸納原始圖片特點的特征向量。
鑒于該解碼器可以從這一向量析取出一幅圖畫,你可以改變它并且得到新的素描。
甚至進行向量運算來創作一只貓豬:
3.5. GAN(生成對抗網絡)
生成對抗網絡(GAN)是深度學習最熱門的話題之一。很多時候,這個想法都是用于圖像方面,所以我會用圖像來解釋這一概念。
其想法體現在兩個網絡——生成器與鑒別器的博弈上。第一個網絡創作圖像,然后對二個網絡試圖理解該圖像是真實的還是生成的。
用圖示來解釋大概是這樣的:
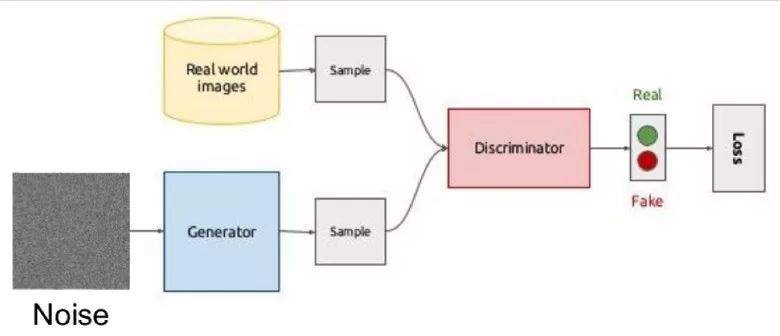
在訓練期間,生成器通過隨機向量(噪聲)生成一幅圖像然后交給鑒別器的輸入,由后者說出這是真的還是假的。鑒別器還會接收來自數據集的真實圖像。
訓練這樣的結構是很難的,因為找到兩個網絡的平衡點很難。通常情況下鑒別器會獲勝,然后訓練就停滯不前了。然而,該系統的優勢在于我們可以解決對我們來說很難設置損失函數的問題(比方說改進圖片質量)——這種問題交給鑒別器最合適。
GAN訓練結果的典型例子是宿舍或者人的圖片
此前,我們討論過將原始數據編碼為特征表示的自編碼(Sketch-RNN)。同樣的事情也發生在生成器上。
利用向量生成圖像的想法在這個以人臉為例的項目http://carpedm20.github.io/faces/中得到了清晰展示。你可以改變向量來看看人臉是如何變化的。
相同的算法也可用于潛在空間:“一個戴眼鏡的人”減去“一個人”加上一個“女人”相當于“一個戴眼鏡的女人”。
3.6. 用GAN改變臉部年齡
如果在訓練過程中你把控制參數交給潛在向量,那么在生成潛在向量時,你就可以更改它從而在在圖片中管理必要的圖像。這種方法被稱為有條件GAN。
《用有條件生成對抗網絡進行面部老化》這篇文章的作者就是這么干的。在用IMDB數據集中已知年齡的演員對引擎進行過訓練之后,研究人員就有機會來改變此人的面部年齡。
3.7. 專業照片
Google已經為GAN找到了另一種有趣的應用——選擇和改善照片。他們用專業照片數據集來訓練GAN:生成器試圖改進糟糕的照片(經過專業拍攝然后用特殊過濾器劣化),而鑒別器則要區分“改進過”的照片與真正的專業照片。
經過訓練的算法會篩查Google Street View的全景照片,選出其中最好的作品,并會收到一些專業和半專業品質的照片(經過攝影師評級)。
3.8. 通過文字描述合成圖像
GAN的一個令人印象深刻的例子是用文字生成圖像。
這項研究的作者提出不僅把文字嵌入到生成器(有條件GAN)的輸入,同時也嵌入到鑒別器的輸入,這樣就可以驗證文字與圖像的相關性。為了確保鑒別器學會運行他的函數,除了訓練以外,他們還給真實圖像添加了不正確的文字。

3.9. Pix2pix應用
2016年引人矚目的文章之一是Berkeley AI Research (BAIR)的《用有條件對抗網絡進行圖像到圖像的翻譯》。研究人員解決了圖像到圖像生成的問題,比方說在要求它用一幅衛星圖像創造一幅地圖時,或者根據素描做出物體的真實紋理。

這里還有一個有條件GAN成功表現的例子。這種情況下,條件擴大到整張圖片。在圖像分割中很流行的UNet被用作生成器的架構,一個新的PatchGAN分類器用作鑒別器來對抗模糊圖像(圖片被分成N塊,每一塊都分別進行真偽的預測)。
Christopher Hesse創作了可怕的貓形象,引起了用戶極大的興趣。

你可以在這里找到源代碼。
3.10. CycleGAN圖像處理工具
要想應用Pix2Pix,你需要一個包含來自不同領域圖片匹配對的數據集。比方說在卡片的情況下,收集此類數據集并不是問題。然而,如果你希望做點更復雜的東西,比如對對象進行“變形”或者風格化,一般而言就找不到對象匹配対了。
因此,Pix2Pix的作者決定完善自己的想法,他們想出了CycleGAN,在沒有特定配對的情況來對不同領域的圖像進行轉換——《不配對的圖像到圖像翻譯》
其想法是教兩對生成器—鑒別器將圖像從一個領域轉換為另一個領域,然后再反過來,由于我們需要一種循環的一致性——經過一系列的生成器應用之后,我們應該得到類似原先L1層損失的圖像。為了確保生成器不會將一個領域的圖像轉換成另一個跟原先圖像毫無關系的領域的圖像,需要有一個循環損失。

這種辦法讓你可以學習馬—>斑馬的映射。
此類轉換不太穩定,往往會創造出不成功的選項:
源碼可以到這里找。
3.11. 腫瘤分子學的進展
機器學習現在已經走進了醫療業。除了識別超聲波、MRI以及進行診斷以外,它還可以用來發現對抗癌癥的藥物。
我們已經報道過這一研究的細節。簡單來說,在對抗自編碼器(AAE)的幫助下,你可以學習分子的潛在表征然后用它來尋找新的分子。通過這種方式已經找到了69種分子,其中一半是用于對抗癌癥的,其他的也有著重大潛能。
3.12. 對抗攻擊
對抗攻擊方面的話題探討得很熱烈。什么是對抗攻擊?比方說,基于ImageNet訓練的標準網絡,在添加特殊噪聲給已分類的圖片之后完全是不穩定的。在下面這個例子中,我們看到給人類眼睛加入噪聲的圖片基本上是不變的,但是模型完全發瘋了,預測成了完全不同的類別。
Fast Gradient Sign Method(FGSM,快速梯度符號方法)就實現了穩定性:在利用了該模型的參數之后,你可以朝著想要的類別前進一到幾個梯度步然后改變原始圖片。
Kaggle的任務之一與此有關:參與者被鼓勵去建立通用的攻防體系,最終會相互對抗以確定最好的。
為什么我們要研究這些攻擊?首先,如果我們希望保護自己的產品的話,我們可以添加噪聲給captcha來防止spammer(垃圾群發者)的自動識別。其次,算法正日益滲透到我們的生活當中——比如面部識別系統和自動駕駛汽車就是例子。這種情況下,攻擊者會利用這些算法的缺陷。
這里就有一個例子,通過特殊玻璃你可以欺騙面部識別系統,然后“把自己扮成另一個人而獲得通過”。因此,在訓練模型的時候我們需要考慮可能的攻擊。
此類對標識的操縱也妨礙了對其的正確識別。
這里有來自競賽組織者的一組文章。
已經寫好的用于攻擊的庫:cleverhans和foolbox。
4. 強化學習
強化學習(RL)也是機器學習最有趣發展最活躍的分支之一。
這種辦法的精髓是在一個通過體驗給予獎勵的環境中學習代理的成功行為——就像人一生的學習一樣。
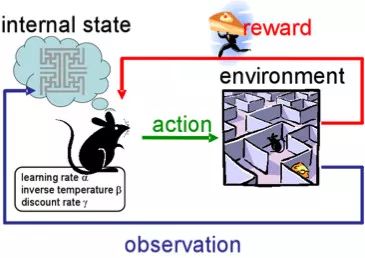
RL在游戲、機器人以及系統管理(比如交通)中使用活躍。
當然,每個人都聽說過Alphago在與人類最好圍棋選手的比賽中取得的勝利。研究人員在訓練中使用了RL:機器人個你自己下棋來改進策略。
4.1. 不受控輔助任務的強化訓練
前幾年DeepMind已經學會了用DQN來玩大型電玩,表現已經超過了人類。目前,他們正在教算法玩類似Doom這樣更復雜的游戲。
大量關注被放到了學習加速上面,因為代理跟環境的交互經驗需要現代GPU很多小時的訓練。
4.2. 學習機器人
在OpenAi,他們一直在積極研究人類在虛擬環境下對代理的訓練,這要比在現實生活中進行實驗更安全。
他們的團隊在其中一項研究中顯示出一次性的學習是有可能的:一個人在VR中演示如何執行特定任務,結果表明,一次演示就足以供算法學會然后在真實條件下再現。

如果教會人也這么簡單就好了。
4.3. 基于人類偏好的學習
這里是OpenAi和DeepMind聯合對該主題展開的工作。基本上就是代理有個任務,算法提供了兩種可能的解決方案給人然后指出哪一個更好。這個過程會不斷反復,然后獲取人類900的字位反饋(二進制標記)的算法就學會了如何解決這個問題。
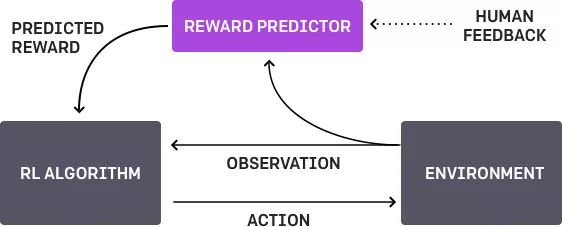
像以往一樣,人類必須小心,要考慮清楚他教給機器的是什么。比方說,鑒別器確定算法真的想要拿那個東西,但其實他只是模仿了這個動作。
4.4. 復雜環境下的運動
這是另一項來自DeepMind的研究。為了教機器人復雜的行為(走路、跳躍等),甚至做類似人的動作,你得大量參與到損失函數的選擇上,這會鼓勵想要的行為。然而,算法學習通過簡單獎勵學習復雜行為會更好一些。
研究人員設法實現了這一點:他們通過搭建一個有障礙的復雜環境并且提供一個簡單的回報機制用于運動中的處理來教代理(軀體模擬器)執行復雜動作。
你可以觀看這段視頻,結果令人印象深刻。然而,用疊加聲音觀看會有趣得多!
最后,我再提供一個最近發布的算法鏈接,這是OpenAI開發用于學習RL的。現在你可以使用比標準的DQN更先進的解決方案了。
5. 其他
5.1. 冷卻數據中心
2017年7月,Google報告稱它利用了DeepMind在機器學習方面的成果來減少數據中心的能耗。
基于數據中心數千個傳感器的信息,Google開發者訓練了一個神經網絡,一方面預測數據中心的PUE(能源使用效率),同時進行更高效的數據中心管理。這是ML實際應用的一個令人印象深刻的重要例子。

5.2. 適用所有任務的模型
就像你知道的那樣,訓練過的模型是非常專門化的,每一個任務都必須針對特殊模型訓練,很難從一個任務轉化到執行另一個任務。不過Google Brain在模型的普適性方面邁出了一小步,《學習一切的單一模型》
研究人員已經訓練了一個模型來執行8種不同領域(文本、語音、圖像)的任務。比方說,翻譯不同的語言,文本解析,以及圖像與聲音識別。

為了實現這一點,他們開發了一個復雜的網絡架構,里面有不同的塊處理不同的輸入數據然后產生出結果。用于編碼/解碼的這些塊分成了3種類型:卷積、注意力以及門控專家混合(MoE)。
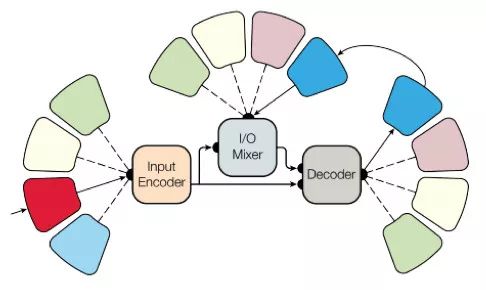
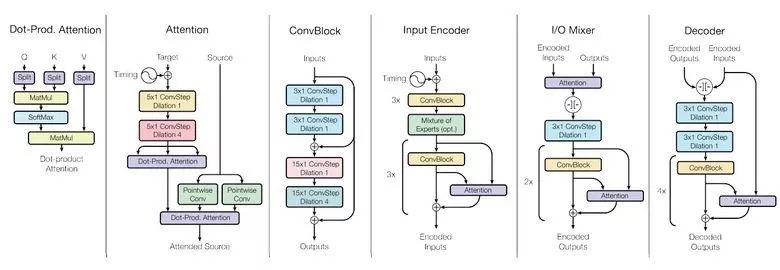
學習的主要結果:
得到了幾乎完美的模型(作者并未對超參數進行調優)。
不同領域間的知識發生了轉化,也就是說,對于需要大量數據的任務,表現幾乎是一樣的。而且在小問題上表現更好(比方說解析)。
不同任務需要的塊并不會相互干擾甚至有時候還有所幫助,比如,MoE——對Imagenet任務就有幫助。
順便說一下,這個模型放到了tensor2tensor里面。
5.3. 一小時弄懂Imagenet
Facebook的員工在一篇文章中告訴我們,他們的工程師是如何在僅僅一個小時之內教會Resnet-50模型弄懂Imagenet的。要說清楚的是,他們用來256個GPU(Tesla P100)。
他們利用了Gloo和Caffe2進行分布式學習。為了讓這個過程高效,采用大批量(8192個要素)的學習策略是必要的:梯度平均、熱身階段、特殊學習率等。
因此,從8個GPU擴展到256個GPU時,實現90%的效率是有可能的。不想沒有這種集群的普通人,現在Facebook的研究人員實驗甚至可以更快。
6. 新聞
6.1. 無人車
無人車的研發正熱火朝天,各種車都在積極地進行測試。最近幾年,我們留意到了英特爾收購了Mobileye,Uber與Google之間發生的前員工竊取技術的丑聞,以及采用自動導航導致的第一起死亡事件等等。
我想強調一件事情:Google Waymo正在推出一個beta計劃。Google是該領域的先驅,它認為自己的技術是非常好的,因為它的車已經行駛了300多萬英里。
最近無人車還被允許在美國全境行駛了。
6.2. 醫療保健
就像我說過那樣,現代ML正開始引入到醫療行業當中。比方說,Google跟一個醫療中心合作來幫助后者進行診斷。
Deepmind甚至還設立了一個獨立的部門。
今年Kaggle推出了Data Science Bowl計劃,這是一項預測一年肺癌情況的競賽,選手們的依據是一堆詳細的圖片,獎金池高達100萬美元。
6.3 投資
目前,ML方面的投資非常大,就像之前在大數據方面的投資一樣。
中國在AI方面的投入高達1500億美元,意在成為這個行業的領袖。
公司方面,百度研究院雇用了1300人,相比之下FAIR的是80人。在最近的KDD上,阿里的員工介紹了他們的參數服務器鯤鵬(KunPeng),上面跑的樣本達1000億,有1萬億個參數,這些都是“普通任務”。
你可以得出自己的結論,學習機器學習永遠不會遲。無路如何,隨著時間轉移,所有開發者都會使用機器學習,使得后者變成普通技能之一,就像今天對數據庫的使用能力一樣。
-
翻譯
+關注
關注
0文章
47瀏覽量
10829 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46127 -
無人車
+關注
關注
1文章
304瀏覽量
36567 -
深度學習
+關注
關注
73文章
5515瀏覽量
121551
原文標題:深度 | 2017 年,深度學習領域有哪些成就?
文章出處:【微信號:melux_net,微信公眾號:人工智能大趨勢】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
2017全國深度學習技術應用大會
【盤點】2017元器件交期年終盤點,2018年最新預測!
Nanopi深度學習之路(1)深度學習框架分析
什么是深度學習?使用FPGA進行深度學習的好處?
2017年18款雙攝機型盤點 誰在受益?
對2017年NLP領域中深度學習技術應用的總結
深度學習領域Facebook等巨頭在2017都做了什么
深度神經網絡加速和壓縮方面所取得的進展報告
你知道機器深度學習 那你知道全新的進化算法嗎





 工商網監
工商網監
評論