") 基于注意力機(jī)制的用戶行為建模框架及其在推薦領(lǐng)域的應(yīng)用
基于注意力機(jī)制的用戶行為建模框架及其在推薦領(lǐng)域的應(yīng)用
本文提出一種基于注意力機(jī)制的用戶異構(gòu)行為序列的建模框架,并將其應(yīng)用到推薦場(chǎng)景中。我們將不同種類的用戶行為序列進(jìn)行分組編碼,并映射到不同子空間中。我們利用self-attention對(duì)行為間的互相影響進(jìn)行建模。最終我們得到用戶的行為表征,下游任務(wù)就可以使用基本的注意力模型進(jìn)行有更具指向性的決策。我們嘗試用同一種模型同時(shí)預(yù)測(cè)多種類型的用戶行為,使其達(dá)到多個(gè)單獨(dú)模型預(yù)測(cè)單類型行為的效果。另外,由于我們的方法中沒有使用RNN,CNN等方法,因此在提高效果的同時(shí),該方法能夠有更快的訓(xùn)練速度。
研究背景
一個(gè)人是由其所表現(xiàn)出的行為所定義。而對(duì)用戶精準(zhǔn)、深入的研究也往往是很多商業(yè)問題的核心。從長(zhǎng)期來(lái)看,隨著人們可被記錄的行為種類越來(lái)越多,平臺(tái)方需要有能力通過融合各類不同的用戶行為,更好的去理解用戶,從而提供更好的個(gè)性化服務(wù)。
對(duì)于阿里巴巴來(lái)說,以消費(fèi)者運(yùn)營(yíng)為核心理念的全域營(yíng)銷正是一個(gè)結(jié)合用戶全生態(tài)行為數(shù)據(jù)來(lái)幫助品牌實(shí)現(xiàn)新營(yíng)銷的數(shù)據(jù)&技術(shù)驅(qū)動(dòng)的解決方案。因此,對(duì)用戶行為的研究就成為了一個(gè)非常核心的問題。其中,很大的挑戰(zhàn)來(lái)自于能否對(duì)用戶的異構(gòu)行為數(shù)據(jù)進(jìn)行更精細(xì)的處理。
在這樣的背景下,本文提出一個(gè)通用的用戶表征框架,試圖融合不同類型的用戶行為序列,并以此框架在推薦任務(wù)中進(jìn)行了效果驗(yàn)證。另外,我們還通過多任務(wù)學(xué)習(xí)的方式,期望能夠利用該用戶表征實(shí)現(xiàn)不同的下游任務(wù)。
相關(guān)工作
異構(gòu)行為建模:通常通過手動(dòng)特征工程來(lái)表示用戶特征。這些手工特征以聚合類特征或無(wú)時(shí)序的id特征集合為主。
單行為序列建模:用戶序列的建模通常會(huì)用RNN(LSTM/GRU)或者CNN + Pooling的方式。RNN難以并行,訓(xùn)練和預(yù)測(cè)時(shí)間較長(zhǎng),且LSTM中的Internal Memory無(wú)法記住特定的行為記錄。CNN也無(wú)法保留特定行為特征,且需要較深的層次來(lái)建立任意行為間的影響。
異構(gòu)數(shù)據(jù)表征學(xué)習(xí):參考知識(shí)圖譜和Multi-modal的表征研究工作,但通常都有非常明顯的映射監(jiān)督。而在我們的任務(wù)中,異構(gòu)的行為之間并沒有像image caption這種任務(wù)那樣明顯的映射關(guān)系。
本文的主要貢獻(xiàn)如下:
嘗試設(shè)計(jì)和實(shí)現(xiàn)了一種能夠融合用戶多種時(shí)序行為數(shù)據(jù)的方法,較為創(chuàng)新的想法在于提出了一種同時(shí)考慮異構(gòu)行為和時(shí)序的解決方案,并給出較為簡(jiǎn)潔的實(shí)現(xiàn)方式。
使用類似Google的self-attention機(jī)制去除CNN、LSTM的限制,讓網(wǎng)絡(luò)訓(xùn)練和預(yù)測(cè)速度變快的同時(shí),效果還可以略有提升。
此框架便于擴(kuò)展。可以允許更多不同類型的行為數(shù)據(jù)接入,同時(shí)提供多任務(wù)學(xué)習(xí)的機(jī)會(huì),來(lái)彌補(bǔ)行為稀疏性。
ATRank方案介紹
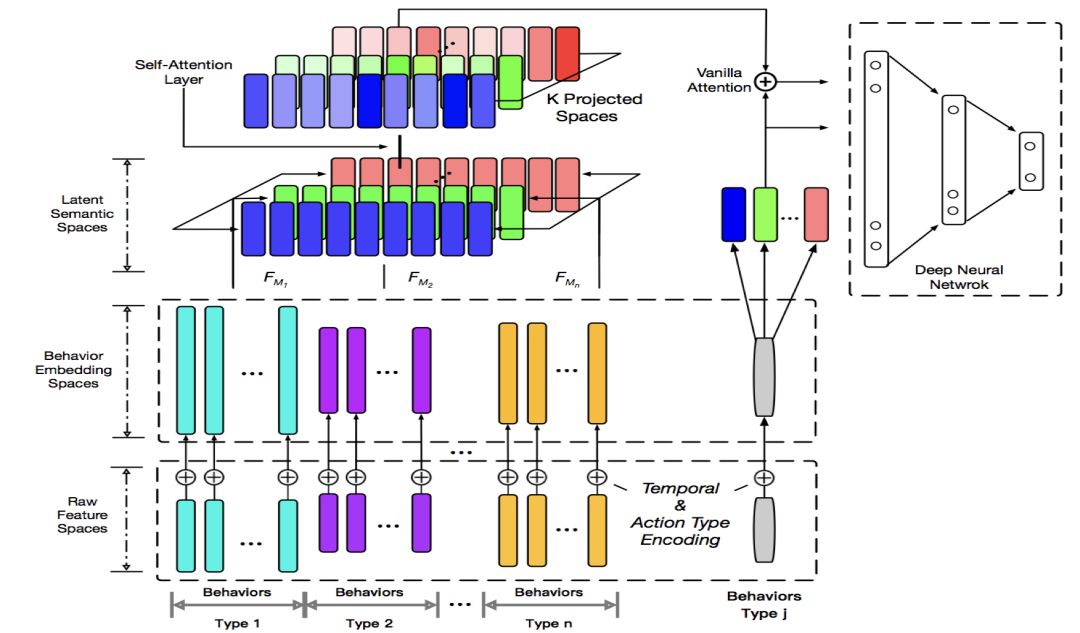
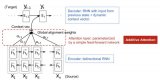
整個(gè)用戶表征的框架包括原始特征層,語(yǔ)義映射層,Self-Attention層和目標(biāo)網(wǎng)絡(luò)。
語(yǔ)義映射層能讓不同的行為可以在不同的語(yǔ)義空間下進(jìn)行比較和相互作用。Self-Attention層讓單個(gè)的行為本身變成考慮到其他行為影響的記錄。目標(biāo)網(wǎng)絡(luò)則通過Vanilla Attention可以準(zhǔn)確的找到相關(guān)的用戶行為進(jìn)行預(yù)測(cè)任務(wù)。通過Time Encoding + Self Attention的思路,我們的實(shí)驗(yàn)表明其的確可以替代CNN/RNN來(lái)描述序列信息,能使模型的訓(xùn)練和預(yù)測(cè)速度更快。
1. 行為分組
某個(gè)用戶的行為序列可以用一個(gè)三元組來(lái)描述(動(dòng)作類型,目標(biāo),時(shí)間)。我們先將用戶不同的行為按照目標(biāo)實(shí)體進(jìn)行分組,如圖中最下方不同顏色group。例如商品行為,優(yōu)惠券行為,關(guān)鍵字行為等等。動(dòng)作類型可以是點(diǎn)擊/收藏/加購(gòu)、領(lǐng)取/使用等等。
每個(gè)實(shí)體都有自己不同的屬性,包括實(shí)值特征和離散id類特征。動(dòng)作類型是id類,我們也將時(shí)間離散化。三部分相加得到下一層的向量組。
即,某行為的編碼 = 自定義目標(biāo)編碼 + lookup(離散化時(shí)間) + lookup(動(dòng)作類型)。
由于實(shí)體的信息量不同,因此每一組行為編碼的向量長(zhǎng)度不一,其實(shí)也代表行為所含的信息量有所不同。另外,不同行為之間可能會(huì)共享一些參數(shù),例如店鋪id,類目id這類特征的lookup table,這樣做能減少一定的稀疏性,同時(shí)降低參數(shù)總量。
分組的主要目的除了說明起來(lái)比較方便,還與實(shí)現(xiàn)有關(guān)。因?yàn)樽冮L(zhǎng)、異構(gòu)的處理很難高效的在不分組的情況下實(shí)現(xiàn)。并且在后面還可以看到我們的方法實(shí)際上并不強(qiáng)制依賴于行為按時(shí)間排序。
2. 語(yǔ)義空間映射
這一層通過將異構(gòu)行為線性映射到多個(gè)語(yǔ)義空間,來(lái)實(shí)現(xiàn)異構(gòu)行為之間的同語(yǔ)義交流。例如框架圖中想表達(dá)的空間是紅綠藍(lán)(RGB)構(gòu)成的原子語(yǔ)義空間,下面的復(fù)合色彩(不同類型的用戶行為)會(huì)投影到各個(gè)原子語(yǔ)義空間。在相同語(yǔ)義空間下,這些異構(gòu)行為的相同語(yǔ)義成分才有了可比性。
類似的思路其實(shí)也在knowledge graph representation里也有出現(xiàn)。而在NLP領(lǐng)域,今年也有一些研究表明多語(yǔ)義空間的attention機(jī)制可以提升效果。個(gè)人認(rèn)為的一點(diǎn)解釋是說,如果不分多語(yǔ)義空間,會(huì)發(fā)生所謂語(yǔ)義中和的問題。簡(jiǎn)單的理解是,兩個(gè)不同種類的行為a,b可能只在某種領(lǐng)域上有相關(guān)性,然而當(dāng)attention score是一個(gè)全局的標(biāo)量時(shí), a,b在不那么相關(guān)的領(lǐng)域上會(huì)增大互相影響,而在高度相關(guān)的領(lǐng)域上這種影響則會(huì)減弱。
盡管從實(shí)現(xiàn)的角度上來(lái)說,這一層就是所有行為編碼向一個(gè)統(tǒng)一的空間進(jìn)行映射,映射方法線性非線性都可以,但實(shí)際上,對(duì)于后面的網(wǎng)絡(luò)層來(lái)說,我們可以看作是將一個(gè)大的空間劃分為多語(yǔ)義空間,并在每個(gè)子空間里進(jìn)行self-attention操作。因此從解釋上來(lái)說,我們簡(jiǎn)單的把這個(gè)映射直接描述成對(duì)多個(gè)子語(yǔ)義空間進(jìn)行投影。
3. Self Attention層
Self Attention層的目的實(shí)際上是想將用戶的每一個(gè)行為從一個(gè)客觀的表征,做成一個(gè)用戶記憶中的表征。客觀的表征是指,比如A,B做了同樣一件事,這個(gè)行為本身的表征可能是相同的。但這個(gè)行為在A,B的記憶中,可能強(qiáng)度、清晰度是完全不一樣的,這是因?yàn)锳,B的其他行為不同。實(shí)際上,觀察softmax函數(shù)可知,某種相似行為做的越多,他們的表征就越會(huì)被平均。而帶來(lái)不一樣體驗(yàn)的行為則會(huì)更容易保留自己的信息。因此self attention實(shí)際上模擬了一個(gè)行為被其他行為影響后的表征。
另外,Self Attention可以有多層。可以看到,一層Self-Attention對(duì)應(yīng)著一階的行為影響。多層則會(huì)考慮多階的行為影響。這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)借鑒的是google的self-attention框架。
具體計(jì)算方式如下:
記S是整個(gè)語(yǔ)義層拼接后的輸出,Sk是第k個(gè)語(yǔ)義空間上的投影,則經(jīng)過self-attention后第k個(gè)語(yǔ)義空間的表征計(jì)算公式為:
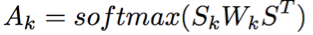
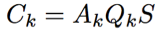
這里的attention function可以看做是一種bilinear的attention函數(shù)。最后的輸出則是這些空間向量拼接后再加入一個(gè)前饋網(wǎng)絡(luò)。
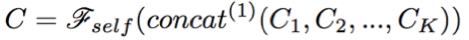
4. 目標(biāo)網(wǎng)絡(luò)
目標(biāo)網(wǎng)絡(luò)會(huì)隨著下游任務(wù)的不同而定制。本文所涉及的任務(wù)是用戶行為預(yù)測(cè)及推薦場(chǎng)景的點(diǎn)擊預(yù)測(cè)的任務(wù),采用的是point-wise的方式進(jìn)行訓(xùn)練和預(yù)測(cè)。
框架圖中灰色的bar代表待預(yù)測(cè)的任意種類的行為。我們將該行為也通過embedding、projection等轉(zhuǎn)換,然后和用戶表征產(chǎn)出的行為向量做vanilla attention。最后Attention向量和目標(biāo)向量將被送入一個(gè)Ranking Network。其他場(chǎng)景強(qiáng)相關(guān)的特征可以放在這里。這個(gè)網(wǎng)絡(luò)可以是任意的,可以是wide & deep,deep FM,pnn都行。我們?cè)谡撐牡膶?shí)驗(yàn)中就是簡(jiǎn)單的dnn。
離線實(shí)驗(yàn)
為了比較框架在單行為預(yù)測(cè)時(shí)的效果,我們?cè)赼mazon購(gòu)買行為的公開數(shù)據(jù)集上的實(shí)驗(yàn)。
訓(xùn)練收斂結(jié)果如下圖:
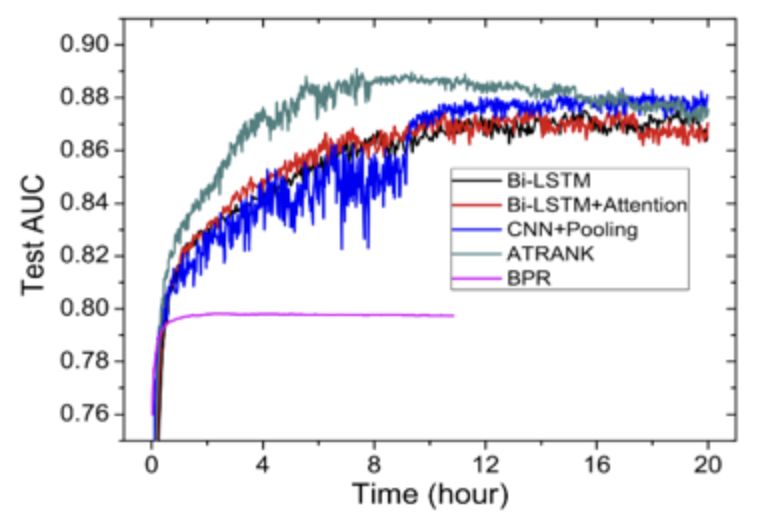
用戶平均AUC如下圖:
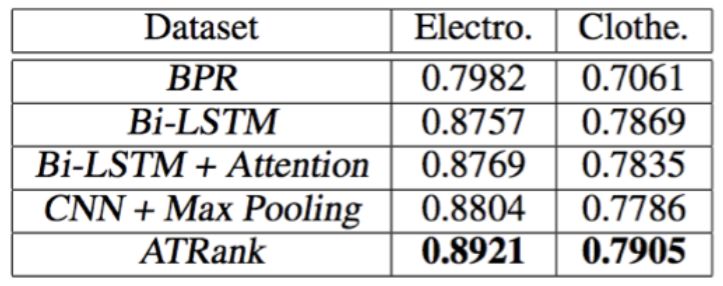
實(shí)驗(yàn)結(jié)論:在行為預(yù)測(cè)或推薦任務(wù)中,self-attention + time encoding也能較好的替代cnn+pooling或lstm的編碼方式。訓(xùn)練時(shí)間上能較cnn/lstm快4倍。效果上也能比其他方法略好一些。
Case Study
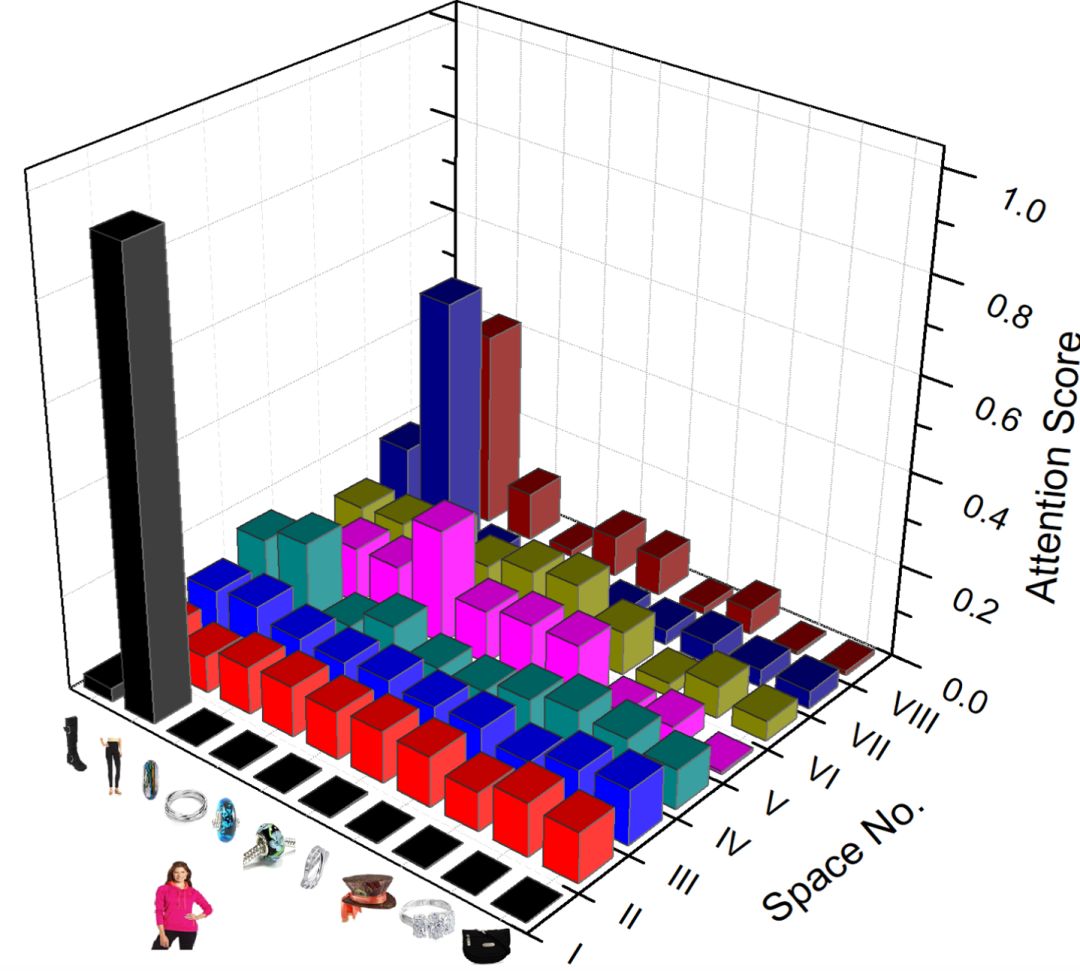
為了深究Self-Attention在多空間內(nèi)的意義,我們?cè)赼mazon dataset上做了一個(gè)簡(jiǎn)單的case study。如下圖:
從圖中我們可以看到,不同的空間所關(guān)注的重點(diǎn)很不一樣。例如空間I, II, III, VIII中每一行的attention分的趨勢(shì)類似。這可能是主要體現(xiàn)不同行為總體的影響。另一些空間,例如VII,高分attention趨向于形成稠密的正方形,我們可以看到這其實(shí)是因?yàn)檫@些商品屬于同樣的類目。
下圖則是vanilla attention在不同語(yǔ)義空間下的得分情況。
多任務(wù)學(xué)習(xí)
論文中,我們離線收集了阿里電商用戶對(duì)商品的購(gòu)買點(diǎn)擊收藏加購(gòu)、優(yōu)惠券領(lǐng)取、關(guān)鍵字搜索三種行為進(jìn)行訓(xùn)練,同樣的也對(duì)這三種不同的行為同時(shí)進(jìn)行預(yù)測(cè)。其中,用戶商品行為記錄是全網(wǎng)的,但最終要預(yù)測(cè)的商品點(diǎn)擊行為是店鋪內(nèi)某推薦場(chǎng)景的真實(shí)曝光、點(diǎn)擊記錄。優(yōu)惠券、關(guān)鍵字的訓(xùn)練和預(yù)測(cè)都是全網(wǎng)行為。
我們分別構(gòu)造了7種訓(xùn)練模式進(jìn)行對(duì)比。分別是單行為樣本預(yù)測(cè)同類行為(3種),全行為多模型預(yù)測(cè)單行為(3種),全行為單模型預(yù)測(cè)全行為(1種)。在最后一種實(shí)驗(yàn)設(shè)置下,我們將三種預(yù)測(cè)任務(wù)各自切成mini-batch,然后統(tǒng)一進(jìn)行shuffle并訓(xùn)練。
實(shí)驗(yàn)結(jié)果如下表:
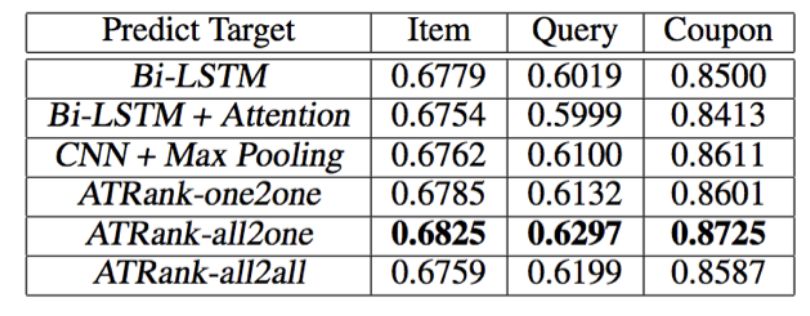
all2one是三個(gè)模型分別預(yù)測(cè)三個(gè)任務(wù),all2all是單模型預(yù)測(cè)三個(gè)任務(wù),即三個(gè)任務(wù)共享所有參數(shù),而沒有各自獨(dú)占的部分。因此all2all與all2one相比稍低可以理解。我們訓(xùn)練多任務(wù)all2all時(shí),將三種不同的預(yù)測(cè)任務(wù)各自batch后進(jìn)行充分隨機(jī)的shuffle。文中的多任務(wù)訓(xùn)練方式還是有很多可以提升的地方,前沿也出現(xiàn)了一些很好的可借鑒的方法,是我們目前正在嘗試的方向之一。
實(shí)驗(yàn)表明,我們的框架可以通過融入更多的行為數(shù)據(jù)來(lái)達(dá)到更好的推薦/行為預(yù)測(cè)的效果。
總結(jié)
本文提出一個(gè)通用的用戶表征框架,來(lái)融合不同類型的用戶行為序列,并在推薦任務(wù)中得到驗(yàn)證。
未來(lái),我們希望能結(jié)合更多實(shí)際的商業(yè)場(chǎng)景和更豐富的數(shù)據(jù)沉淀出靈活、可擴(kuò)展的用戶表征體系,從而更好的理解用戶,提供更優(yōu)質(zhì)的個(gè)性化服務(wù),輸出更全面的數(shù)據(jù)能力。
-
行為識(shí)別
+關(guān)注
關(guān)注
0文章
13瀏覽量
2527
原文標(biāo)題:【AAAI oral】阿里北大提出新attention建模框架,一個(gè)模型預(yù)測(cè)多種行為
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
DeepMind為視覺問題回答提出了一種新的硬注意力機(jī)制
淺談自然語(yǔ)言處理中的注意力機(jī)制
深度分析NLP中的注意力機(jī)制
注意力機(jī)制的誕生、方法及幾種常見模型
基于注意力機(jī)制的深度興趣網(wǎng)絡(luò)點(diǎn)擊率模型

基于注意力機(jī)制的深度學(xué)習(xí)模型AT-DPCNN

基于多層CNN和注意力機(jī)制的文本摘要模型

結(jié)合注意力機(jī)制的跨域服裝檢索方法
基于情感評(píng)分的分層注意力網(wǎng)絡(luò)框架
基于注意力機(jī)制等的社交網(wǎng)絡(luò)熱度預(yù)測(cè)模型
計(jì)算機(jī)視覺中的注意力機(jī)制

PyTorch教程11.4之Bahdanau注意力機(jī)制





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論