") 8種用Python實(shí)現(xiàn)線性回歸的方法對(duì)比分析_哪個(gè)方法更好?
8種用Python實(shí)現(xiàn)線性回歸的方法對(duì)比分析_哪個(gè)方法更好?
說(shuō)到如何用Python執(zhí)行線性回歸,大部分人會(huì)立刻想到用sklearn的linear_model,但事實(shí)是,Python至少有8種執(zhí)行線性回歸的方法,sklearn并不是最高效的。
今天,讓我們來(lái)談?wù)劸€性回歸。沒(méi)錯(cuò),作為數(shù)據(jù)科學(xué)界元老級(jí)的模型,線性回歸幾乎是所有數(shù)據(jù)科學(xué)家的入門必修課。拋開(kāi)涉及大量數(shù)統(tǒng)的模型分析和檢驗(yàn)不說(shuō),你真的就能熟練應(yīng)用線性回歸了么?未必!
在這篇文章中,文摘菌將介紹8種用Python實(shí)現(xiàn)線性回歸的方法。了解了這8種方法,就能夠根據(jù)不同需求,靈活選取最為高效的方法實(shí)現(xiàn)線性回歸。
“寶刀不老”的線性回歸
時(shí)至今日,深度學(xué)習(xí)早已成為數(shù)據(jù)科學(xué)的新寵。即便往前推10年,SVM、boosting等算法也能在準(zhǔn)確率上完爆線性回歸。
為什么我們還需要線性回歸呢?
一方面,線性回歸所能夠模擬的關(guān)系其實(shí)遠(yuǎn)不止線性關(guān)系。線性回歸中的“線性”指的是系數(shù)的線性,而通過(guò)對(duì)特征的非線性變換,以及廣義線性模型的推廣,輸出和特征之間的函數(shù)關(guān)系可以是高度非線性的。另一方面,也是更為重要的一點(diǎn),線性模型的易解釋性使得它在物理學(xué)、經(jīng)濟(jì)學(xué)、商學(xué)等領(lǐng)域中占據(jù)了難以取代的地位。
那么,如何用Python來(lái)實(shí)現(xiàn)線性回歸呢?
由于機(jī)器學(xué)習(xí)庫(kù)scikit-learn的廣泛流行,常用的方法是從該庫(kù)中調(diào)用linear_model來(lái)擬合數(shù)據(jù)。雖然這可以提供機(jī)器學(xué)習(xí)的其他流水線特征(例如:數(shù)據(jù)歸一化,模型系數(shù)正則化,將線性模型傳遞到另一個(gè)下游模型)的其他優(yōu)點(diǎn),但是當(dāng)一個(gè)數(shù)據(jù)分析師需要快速而簡(jiǎn)便地確定回歸系數(shù)(和一些基本相關(guān)統(tǒng)計(jì)量)時(shí),這通常不是最快速簡(jiǎn)便的方法。
下面,我將介紹一些更快更簡(jiǎn)潔的方法,但是它們所提供信息量和建模的靈活性不盡相同。
各種線性回歸方法的完整源碼都可以在文末的GitHub鏈接中找到。他們大多數(shù)都依賴于SciPy包。
SciPy是基于Python的Numpy擴(kuò)展構(gòu)建的數(shù)學(xué)算法和函數(shù)的集合。通過(guò)為用戶提供便于操作和可視化數(shù)據(jù)的高級(jí)命令和類,為交互式Python會(huì)話增加了強(qiáng)大的功能。
8種方法實(shí)現(xiàn)線性回歸
方法一:Scipy.polyfit( ) or numpy.polyfit( )

這是一個(gè)最基本的最小二乘多項(xiàng)式擬合函數(shù)(least squares polynomial fit function),接受數(shù)據(jù)集和任何維度的多項(xiàng)式函數(shù)(由用戶指定),并返回一組使平方誤差最小的系數(shù)。這里給出函數(shù)的詳細(xì)描述。對(duì)于簡(jiǎn)單的線性回歸來(lái)說(shuō),可以選擇1維函數(shù)。但是如果你想擬合更高維的模型,則可以從線性特征數(shù)據(jù)中構(gòu)建多項(xiàng)式特征并擬合模型。
方法二:Stats.linregress( )

這是一個(gè)高度專業(yè)化的線性回歸函數(shù),可以在SciPy的統(tǒng)計(jì)模塊中找到。然而因?yàn)樗鼉H被用來(lái)優(yōu)化計(jì)算兩組測(cè)量數(shù)據(jù)的最小二乘回歸,所以其靈活性相當(dāng)受限。因此,不能使用它進(jìn)行廣義線性模型和多元回歸擬合。但是,由于其特殊性,它是簡(jiǎn)單線性回歸中最快速的方法之一。除了擬合的系數(shù)和截距項(xiàng)之外,它還返回基本統(tǒng)計(jì)量,如R2系數(shù)和標(biāo)準(zhǔn)差。
方法三:Optimize.curve_fit( )

這與Polyfit方法是一致的,但本質(zhì)上更具一般性。這個(gè)強(qiáng)大的函數(shù)來(lái)自scipy.optimize模塊,可以通過(guò)最小二乘最小化將任意的用戶自定義函數(shù)擬合到數(shù)據(jù)集上。
對(duì)于簡(jiǎn)單的線性回歸來(lái)說(shuō),可以只寫一個(gè)線性的mx + c函數(shù)并調(diào)用這個(gè)估計(jì)函數(shù)。不言而喻,它也適用于多元回歸,并返回最小二乘度量最小的函數(shù)參數(shù)數(shù)組以及協(xié)方差矩陣。
方法四:numpy.linalg.lstsq

這是通過(guò)矩陣分解計(jì)算線性方程組的最小二乘解的基本方法。來(lái)自numpy包的簡(jiǎn)便線性代數(shù)模塊。在該方法中,通過(guò)計(jì)算歐幾里德2-范數(shù)||b-ax||2最小化的向量x來(lái)求解等式ax = b。
該方程可能有無(wú)數(shù)解、唯一解或無(wú)解。如果a是方陣且滿秩,則x(四舍五入)是方程的“精確”解。
你可以使用這個(gè)方法做一元或多元線性回歸來(lái)得到計(jì)算的系數(shù)和殘差。一個(gè)小訣竅是,在調(diào)用函數(shù)之前必須在x數(shù)據(jù)后加一列1來(lái)計(jì)算截距項(xiàng)。這被證明是更快速地解決線性回歸問(wèn)題的方法之一。
方法五:Statsmodels.OLS ( )
Statsmodels是一個(gè)小型的Python包,它為許多不同的統(tǒng)計(jì)模型估計(jì)提供了類和函數(shù),還提供了用于統(tǒng)計(jì)測(cè)試和統(tǒng)計(jì)數(shù)據(jù)探索的類和函數(shù)。每個(gè)估計(jì)對(duì)應(yīng)一個(gè)泛結(jié)果列表。可根據(jù)現(xiàn)有的統(tǒng)計(jì)包進(jìn)行測(cè)試,從而確保統(tǒng)計(jì)結(jié)果的正確性。
對(duì)于線性回歸,可以使用該包中的OLS或一般最小二乘函數(shù)來(lái)獲得估計(jì)過(guò)程中的完整的統(tǒng)計(jì)信息。
一個(gè)需要牢記的小技巧是,必須手動(dòng)給數(shù)據(jù)x添加一個(gè)常數(shù)來(lái)計(jì)算截距,否則默認(rèn)情況下只會(huì)得到系數(shù)。以下是OLS模型的完整匯總結(jié)果的截圖。結(jié)果中與R或Julia等統(tǒng)計(jì)語(yǔ)言一樣具有豐富的內(nèi)容。
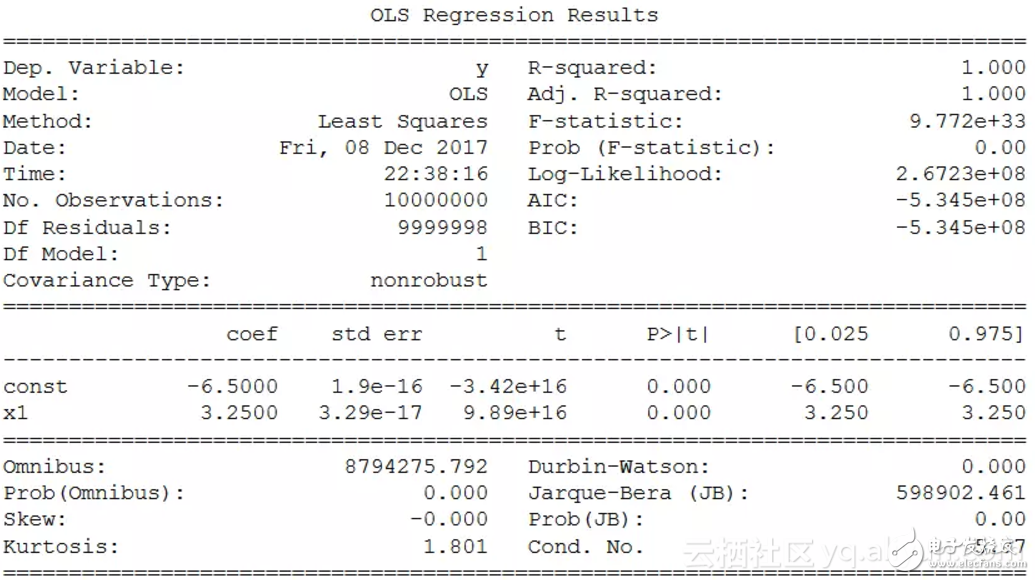
方法六和七:使用矩陣的逆求解析解
對(duì)于條件良好的線性回歸問(wèn)題(其中,至少滿足數(shù)據(jù)點(diǎn)個(gè)數(shù)>特征數(shù)量),系數(shù)求解等價(jià)于存在一個(gè)簡(jiǎn)單的閉式矩陣解,使得最小二乘最小化。由下式給出:
這里有兩個(gè)選擇:
(a)使用簡(jiǎn)單的乘法求矩陣的逆
(b)首先計(jì)算x的Moore-Penrose廣義偽逆矩陣,然后與y取點(diǎn)積。由于第二個(gè)過(guò)程涉及奇異值分解(SVD),所以它比較慢,但是它可以很好地適用于沒(méi)有良好條件的數(shù)據(jù)集。
方法八:sklearn.linear_model.LinearRegression( )
這是大多數(shù)機(jī)器學(xué)習(xí)工程師和數(shù)據(jù)科學(xué)家使用的典型方法。當(dāng)然,對(duì)于現(xiàn)實(shí)世界中的問(wèn)題,它可能被交叉驗(yàn)證和正則化的算法如Lasso回歸和Ridge回歸所取代,而不被過(guò)多使用,但是這些高級(jí)函數(shù)的核心正是這個(gè)模型本身。
八種方法效率比拼
作為一名數(shù)據(jù)科學(xué)家,應(yīng)該一直尋找準(zhǔn)確且快速的方法或函數(shù)來(lái)完成數(shù)據(jù)建模工作。如果模型本來(lái)就很慢,那么會(huì)對(duì)大數(shù)據(jù)集造成執(zhí)行瓶頸。
一個(gè)可以用來(lái)確定可擴(kuò)展性的好辦法是不斷增加數(shù)據(jù)集的大小,執(zhí)行模型并取所有的運(yùn)行時(shí)間繪制成趨勢(shì)圖。
下面是源代碼及其運(yùn)行結(jié)果( https://github.com/tirthajyoti/PythonMachineLearning/blob/master/Linear_... )。
由于其簡(jiǎn)單,即使多達(dá)1000萬(wàn)個(gè)數(shù)據(jù)點(diǎn),stats.linregress和簡(jiǎn)單的矩陣求逆還是最快速的方法。
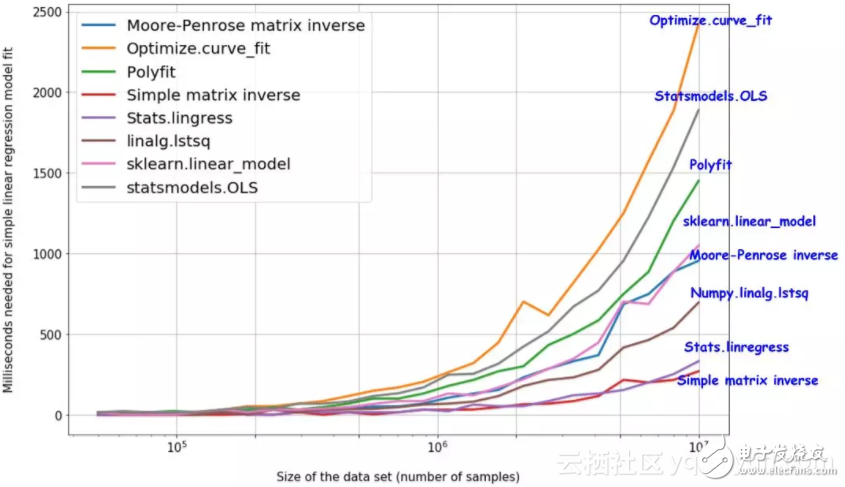
簡(jiǎn)單矩陣逆求解的方案更快
作為數(shù)據(jù)科學(xué)家,我們必須一直探索多種解決方案來(lái)對(duì)相同的任務(wù)進(jìn)行分析和建模,并為特定問(wèn)題選擇最佳方案。
在本文中,我們討論了8種簡(jiǎn)單線性回歸的方法。大多數(shù)都可以擴(kuò)展到更一般化的多元和多項(xiàng)式回歸建模中。
本文的目標(biāo)主要是討論這些方法的相對(duì)運(yùn)行速度和計(jì)算復(fù)雜度。我們?cè)谝粋€(gè)數(shù)據(jù)量持續(xù)增加的合成數(shù)據(jù)集(最多達(dá)1000萬(wàn)個(gè)樣本)上進(jìn)行測(cè)試,并給出每種方法的運(yùn)算時(shí)間。
令人驚訝的是,與廣泛被使用的scikit-learnlinear_model相比,簡(jiǎn)單矩陣的逆求解的方案反而更加快速。
-
python
+關(guān)注
關(guān)注
56文章
4807瀏覽量
85039 -
線性回歸
+關(guān)注
關(guān)注
0文章
41瀏覽量
4316
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
幀同步通常采用的方法有逐位調(diào)整法和置位調(diào)整法,對(duì)比分析哪個(gè)好?
單片線性電路和PWM放大器對(duì)比分析哪個(gè)好?
幾款主流的Python開(kāi)發(fā)板對(duì)比分析哪個(gè)好?
STM32和Arduino對(duì)比分析哪個(gè)好?
無(wú)功電流檢測(cè)方法對(duì)比分析
SPWM調(diào)制方法對(duì)比分析
8 種進(jìn)行簡(jiǎn)單線性回歸的方法分析與討論






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論