") 連接視覺語言大模型與端到端自動(dòng)駕駛
連接視覺語言大模型與端到端自動(dòng)駕駛
連接視覺語言大模型與端到端自動(dòng)駕駛
端到端自動(dòng)駕駛在大規(guī)模駕駛數(shù)據(jù)上訓(xùn)練,展現(xiàn)出很強(qiáng)的決策規(guī)劃能力,但是面對復(fù)雜罕見的駕駛場景,依然存在局限性,這是因?yàn)槎说蕉四P腿狈ΤWR知識和邏輯思維。而視覺語言多模態(tài)大模型(LargeVision-Language Models,LVLM),例如GPT-4O,已經(jīng)展現(xiàn)出極強(qiáng)的視覺理解能力和分析能力,可以很好的與端到端模型互為補(bǔ)充,充當(dāng)駕駛決策的“大腦”。
基于這個(gè)思路,我們提出了一種連接視覺語言多模態(tài)大模型和端到端模型的智駕系統(tǒng) Senna,針對端到端模型魯棒性差,泛化性弱問題,行業(yè)首創(chuàng)“大模型高維駕駛決策-端到端低維軌跡規(guī)劃”的新駕駛范式,打造“大模型 +端到端”的下一代架構(gòu),實(shí)現(xiàn)安全,高效,擬人的智能駕駛。經(jīng)多個(gè)數(shù)據(jù)集上的大量實(shí)驗(yàn)證明Senna 具有業(yè)界最優(yōu)的多模態(tài)+端到端規(guī)劃性能,展現(xiàn)出強(qiáng)大的跨場景泛化性和可遷移能力。
概述
端到端自動(dòng)駕駛在大規(guī)模駕駛數(shù)據(jù)上訓(xùn)練,展現(xiàn)出很強(qiáng)的決策規(guī)劃能力,但是面對復(fù)雜罕見的駕駛場景,依然存在局限性,這是因?yàn)槎说蕉四P腿狈ΤWR知識和邏輯思維。而視覺語言多模態(tài)大模型(Large Vision-Language Models,LVLM),例如GPT-4O,已經(jīng)展現(xiàn)出極強(qiáng)的視覺理解能力和分析能力,可以很好的與端到端模型互為補(bǔ)充,充當(dāng)駕駛決策的“大腦”。基于這個(gè)思路,我們提出了一種連接視覺語言多模態(tài)大模型和端到端模型的智駕系統(tǒng)Senna,針對端到端模型魯棒性差,泛化性弱問題,行業(yè)首創(chuàng)“大模型高維駕駛決策-端到端低維軌跡規(guī)劃”的新駕駛范式,打造“大模型+端到端”的下一代架構(gòu),實(shí)現(xiàn)安全,高效,擬人的智能駕駛。經(jīng)多個(gè)數(shù)據(jù)集上的大量實(shí)驗(yàn)證明,Senna具有業(yè)界最優(yōu)的多模態(tài)+端到端規(guī)劃性能,展現(xiàn)出強(qiáng)大的跨場景泛化性和可遷移能力。
Senna解決的研究問題
此前基于大模型的自動(dòng)駕駛方案,往往將大模型直接作為端到端模型,即直接用大模型預(yù)測規(guī)劃軌跡或者控制信號,但是大模型并不擅長預(yù)測精準(zhǔn)的數(shù)值,因此這種方案并不一定是最優(yōu)解。此前神經(jīng)學(xué)的研究表明,人腦在做細(xì)致決策時(shí),層次化的高維決策模塊和低維執(zhí)行模塊組成的系統(tǒng)起到了關(guān)鍵的作用。例如,當(dāng)想要左轉(zhuǎn)的駕駛員看到紅綠燈由紅變綠,大腦中首先會(huì)思考,現(xiàn)在紅綠燈變綠了,因此我可以加速啟動(dòng)通過路口。然后再通過“打轉(zhuǎn)向燈”,“踩油門”等一系列動(dòng)作完成通過路口這個(gè)目標(biāo)。基于上述觀察,Senna主要嘗試探索和解決三個(gè)問題:
(1)如何有效地結(jié)合多模態(tài)大模型和端到端自動(dòng)駕駛模型?

Senna采用解耦的行為決策-軌跡規(guī)劃思路,多模態(tài)大模型在大規(guī)模駕駛數(shù)據(jù)上微調(diào),以提升其對駕駛場景的理解能力,并采用自然語言輸出高維決策指令,然后端到端模型基于大模型提供的決策指令,生成具體的規(guī)劃軌跡。一方面,使用大模型預(yù)測語言化的決策指令,可以最大利用其在語言任務(wù)上預(yù)訓(xùn)練的知識和常識,生成合理的決策,并且避免預(yù)測精確數(shù)字效果欠佳的缺陷;另一方面,端到端模型更擅長精確的軌跡預(yù)測,將高維決策的任務(wù)解耦,可以降低端到端模型學(xué)習(xí)的難度,提升其軌跡規(guī)劃的精確度。
(2)如何設(shè)計(jì)一個(gè)面向駕駛?cè)蝿?wù)的多模態(tài)大模型?
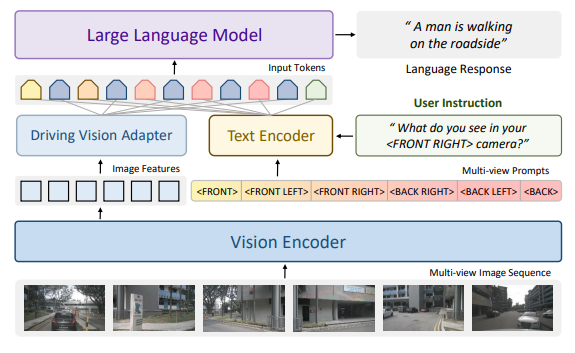
駕駛依賴于準(zhǔn)確的空間感知,目前常見的多模態(tài)大模型沒有針對多圖輸入進(jìn)行專門優(yōu)化,此前針對駕駛?cè)蝿?wù)的大模型或者僅支持前視輸入,缺乏完整的空間感知,存在安全隱患;或者支持多圖輸入,但是并沒有進(jìn)行細(xì)致的設(shè)計(jì),或針對其有效性進(jìn)行驗(yàn)證。
為了解決這些問題,我們提出了Senna,Senna包含兩個(gè)模塊,一個(gè)駕駛多模態(tài)大模型 (Senna-VLM) 和一個(gè)端到端模型(Senna-E2E),相比于通用的多模態(tài)大模型,Senna-VLM針對駕駛?cè)蝿?wù)做出如下設(shè)計(jì):首先,針對駕駛的大模型需要支持多圖從而可以輸入環(huán)視和多幀的信息,這對于準(zhǔn)確的駕駛場景理解和安全非常重要。最初,我們嘗試簡單基于LLaVA-1.5模型加入環(huán)視多圖輸入,但是效果并不符合預(yù)期。在LLaVA中,一張圖像需要占用576個(gè)token,6張圖則需要占用3456個(gè)token,這幾乎要接近最大輸入長度,導(dǎo)致圖像信息占用的token數(shù)量過多。因此Senna-VLM對圖像編碼器輸出的圖像token做進(jìn)一步特征壓縮,并設(shè)計(jì)了針對環(huán)視多圖的prompt,使得Senna可以區(qū)分不同視角的圖像特征并建立空間理解能力。
(3)如何有效地訓(xùn)練面向駕駛?cè)蝿?wù)的多模態(tài)大模型?
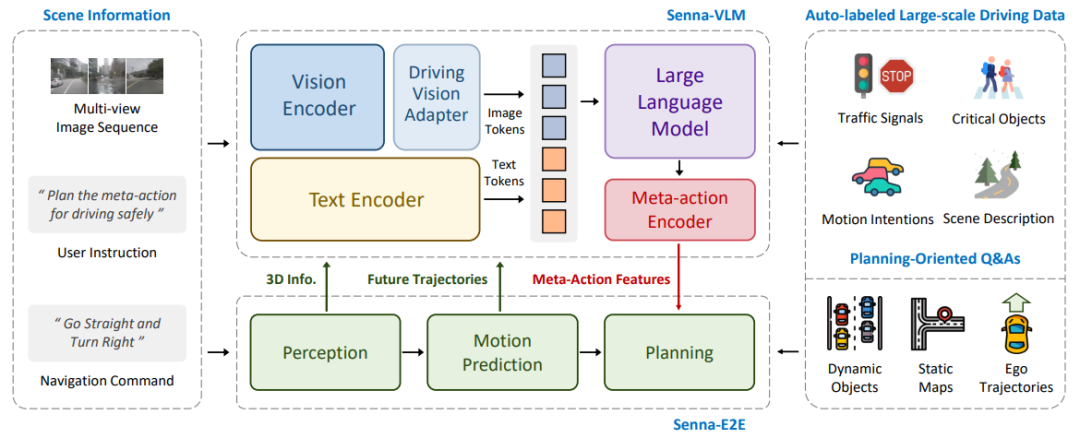
在有了適合駕駛?cè)蝿?wù)的模型設(shè)計(jì)后,有效地訓(xùn)練LVLM是最后一步。這部分包括兩方面的內(nèi)容,數(shù)據(jù)和訓(xùn)練策略。在數(shù)據(jù)方面,此前工作提出了一些策略,但是很多并不是針對規(guī)劃服務(wù),例如檢測和grouding。另外,很多數(shù)據(jù)依賴于人工標(biāo)注,這限制了數(shù)據(jù)的大規(guī)模生產(chǎn)。在本文中,我們首次驗(yàn)證了不同類型的問答數(shù)據(jù)在駕駛規(guī)劃中的重要性。具體來說,我們引入了一系列面向規(guī)劃的問答數(shù)據(jù),旨在增強(qiáng)Senna對駕駛場景中與規(guī)劃相關(guān)的線索的理解,最終實(shí)現(xiàn)更準(zhǔn)確的規(guī)劃。這些問答數(shù)據(jù)包括駕駛場景描述、交通參與者的運(yùn)動(dòng)意圖預(yù)測、交通信號檢測、高維決策規(guī)劃等。我們的數(shù)據(jù)策略可以完全通過自動(dòng)化流程實(shí)現(xiàn)大規(guī)模生產(chǎn)。至于訓(xùn)練策略,大多數(shù)現(xiàn)有方法采用通用數(shù)據(jù)預(yù)訓(xùn)練,然后針對駕駛?cè)蝿?wù)微調(diào)。然而,我們的實(shí)驗(yàn)結(jié)果表明,這可能不是最佳選擇。我們?yōu)?Senna-VLM 提出了一種三階段訓(xùn)練策略,包括混合數(shù)據(jù)預(yù)訓(xùn)練、駕駛通用微調(diào)和駕駛決策微調(diào)。實(shí)驗(yàn)結(jié)果表明,我們提出的三階段訓(xùn)練策略可以實(shí)現(xiàn)最佳的規(guī)劃性能。
Senna的關(guān)鍵創(chuàng)新
在模型層面,Senna提出層次化的規(guī)劃策略,可以充分利用大模型的常識知識和邏輯推理能力,生成準(zhǔn)確的決策指令,并通過端到端模型生成具體的軌跡。另外,Senna設(shè)計(jì)了針對環(huán)視和多圖的策略,通過圖像token壓縮和精心設(shè)計(jì)的環(huán)視prompt,有效提高了多模態(tài)大模型對駕駛場景的理解。
在數(shù)據(jù)方面,我們設(shè)計(jì)了多種可以大規(guī)模自動(dòng)標(biāo)注的面向規(guī)劃的駕駛問答數(shù)據(jù),包括場景描述、交通參與者行為預(yù)測、交通信號識別以及自車決策等。這些問答數(shù)據(jù)對于Senna生成準(zhǔn)確的決策起到了關(guān)鍵作用。
在訓(xùn)練層面,我們提出三階段的大模型訓(xùn)練策略,不僅提升了Senna在駕駛場景的表現(xiàn),且有效保留了其常識知識而不至于出現(xiàn)模式坍塌的問題。
Senna的實(shí)驗(yàn)及應(yīng)用效果
基于多個(gè)數(shù)據(jù)集上的大量實(shí)驗(yàn)表明Senna 實(shí)現(xiàn)了state-of-the-art的規(guī)劃性能。實(shí)驗(yàn)結(jié)果的亮點(diǎn)在于,通過使用在大規(guī)模數(shù)據(jù)集上預(yù)訓(xùn)練的權(quán)重并進(jìn)行微調(diào),Senna 實(shí)現(xiàn)了顯著的性能提升,與沒有預(yù)訓(xùn)練的模型相比,平均規(guī)劃誤差大幅降低了27.12% ,碰撞率降低了33.33%,這些結(jié)果驗(yàn)證了 Senna 提出的結(jié)構(gòu)化的決策規(guī)劃策略、模型結(jié)構(gòu)設(shè)計(jì)和訓(xùn)練策略的有效性。Senna強(qiáng)大的跨場景泛化性和可遷移能力,展現(xiàn)出成為下一代通用智駕大模型的潛力。
未來探索方向
Senna初步探索并驗(yàn)證了基于語言化的決策將大模型和端到端模型結(jié)合的可行性。下一步,我們將利用更精細(xì)的語言決策,并基于決策信息以可控的方式實(shí)現(xiàn)個(gè)性化的軌跡規(guī)劃,并在可解釋性、閉環(huán)驗(yàn)證等方面進(jìn)一步探索優(yōu)化。相信Senna將會(huì)激發(fā)行業(yè)在該領(lǐng)域的進(jìn)一步研究和突破。
-
智能駕駛
+關(guān)注
關(guān)注
3文章
2589瀏覽量
48919 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
785文章
13930瀏覽量
167002 -
大模型
+關(guān)注
關(guān)注
2文章
2545瀏覽量
3163
原文標(biāo)題:下一代“多模態(tài)大模型+端到端”架構(gòu)Senna:開創(chuàng)智駕決策規(guī)劃全新范式
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
自動(dòng)駕駛真的會(huì)來嗎?
自動(dòng)駕駛系統(tǒng)要完成哪些計(jì)算機(jī)視覺任務(wù)?
基于視覺的slam自動(dòng)駕駛
如何基于深度神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)一個(gè)端到端的自動(dòng)駕駛模型?
端到端的自動(dòng)駕駛研發(fā)系統(tǒng)介紹
基于端到端的自動(dòng)駕駛系統(tǒng)只能做demo嗎
端到端自動(dòng)駕駛到底是什么?
理想汽車自動(dòng)駕駛端到端模型實(shí)現(xiàn)

佐思汽研發(fā)布《2024年端到端自動(dòng)駕駛研究報(bào)告》

理想汽車加速自動(dòng)駕駛布局,成立“端到端”實(shí)體組織
實(shí)現(xiàn)自動(dòng)駕駛,唯有端到端?

Mobileye端到端自動(dòng)駕駛解決方案的深度解析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論