 算力調度的基礎知識
算力調度的基礎知識
編者按
“算力調度”的概念,這幾年越來越多的被提及。剛聽到這個概念的時候,我腦海里一直拐不過彎。作為底層芯片出身的我,一直認為:算力是硬件的服務器和集群,他在某個地方,就是固定的;根本就不存在算力的調度,調度的應該是上層的業務軟件。
經過跟行業眾多朋友的交流和思考后,我逐漸能夠理解“算力調度”所表達的意思。從業務的視角,客戶關心的是業務本身,需要算力隨時隨地可用,而不需要關注承載業務的具體的硬件在哪里。當然,要實現不需要關注硬件,有許多工作要做,這就是“算力調度”要完成的事情,也就是說:“算力調度,不僅僅是調度”。
本篇文章,我們簡單聊一聊算力調度,僅供探討,歡迎私信交流。
1 計算任務的特征
1.1 計算任務的時間和空間特征
計算任務(Workload,也譯作工作任務、工作負載等),是一個或一組相關的、運行中的應用程序。
站在軟件運行的角度,根據運行時間的長短,我們可以把計算任務簡單的分為兩類,短期型任務和常駐型任務:
短期型任務指的是,任務開始執行,會在一定的時間內運行完成,結束后會釋放計算資源。
常駐型任務指的是,沒有外部強制關閉的話,任務會一直處于執行狀態,不會結束。
從微觀的看,某個特定的處理器,在其上運行的程序(線程)是分時調度的。這樣,線程的資源占用不會大于1個CPU核。
但相對宏觀的某個計算任務(一個進程或一組相關的進程),其占用的處理器資源既可以少于1個CPU核,也可以是多個CPU核,甚至多個CPU芯片、多臺服務器的集群,直到成千上萬臺服務器的大集群。最典型的例子就是AI大模型訓練,需要上千臺服務器上萬張GPU卡的計算集群來運行大模型訓練的計算任務,并且一次計算任務運行會持續數十天。
串行和并行,會影響計算任務的時間和空間。串行,是以時間換空間;反過來,并行則是以空間換時間。
當計算資源有限而計算任務尺寸較大時,可以把計算任務拆分成許多小計算任務,然后這些小計算任務串行運行。雖然計算的時間會增大,但可以在較小規模的計算資源上完成計算。
反過來,當計算任務的運行時間非常長,我們也可以把任務拆分成短任務,這些短任務并行運行在不同的計算資源上,從而減少計算的時間。這也就是我們經常說的并行加速。
1.2 計算的兩種形態

根據軟件任務的尺寸和硬件服務器尺寸的匹配程度,可以簡單的把計算分為兩種類型:
第一種,一臺硬件服務器處理很多件計算任務。
像云計算,通過虛擬化或容器的方式,可以把單臺服務器分割成多份,每一個虛機或容器,就運行“一個計算任務”,一臺服務器可以同時支持多個計算任務運行。
目前,AI推理的計算任務,通常也可以在一臺服務器尺寸范圍內完成。也因此,AI推理計算任務通常是基于云虛機或容器的方式來運行。
第二種,很多臺硬件服務器處理一件計算任務。
如超級計算(HPC),超算的計算節點可以看做是一臺計算機,然后超算實際上是這些計算節點組成的計算集群。超算的計算任務都比較大,通過并行占用所有計算資源的方式,達到快速計算的目的。
AI模型的訓練的計算任務,尺寸非常大,所以把模型進行拆分,拆分成若干小的計算任務,并且這些小的計算任務之間的聯系更加緊密,是一種緊耦合的關系。也因此,AI模型的訓練,通常是千卡萬卡,甚至更多GPU卡的高性能集群計算,各個需要計算節點之間需要高速(網絡)互聯通信。AI訓練的計算架構,更接近HPC。
1.3 分布式解構
隨著系統越來越大,單機計算已經非常的少見,集群計算已經成為主流。云計算模式,雖然某個具體的計算任務是放在一臺計算服務器上去運行,而實際的情況很可能是——這個計算任務是某個巨服務解構拆分出的其中一個微服務。每個微服務聚焦做一個相對簡單的事情,從而使得單個微服務可以在單機上以虛機或容器的方式運行。
那這樣的話,計算豈不可以統一到一種形態?即單個計算任務需要多臺計算服務器來承載其運行。這里的關鍵,是在于大計算任務解構拆分的不同小計算任務之間的交互耦合度。這樣,根據交互耦合度和網絡硬件實現,我們分為如下幾個情況(耦合性依次降低):
IB高性能網絡+內存一致性硬件加速。計算任務之間完全緊耦合,通常采用超級計算(HPC)模式。超算的各個節點之間主流是通過IB網絡連接,但會在其上構建高效的內存一致性協議加速處理,從而使得整個超算連成一臺計算機。
IB高性能網絡。計算任務之間,聯系緊密,數據量大,延遲敏感。計算機集群,通過IB網絡連接。本質上仍然是多臺計算機組成的計算集群,計算任務間靠點對點通信交互數據。典型案例如AI大模型訓練。
RoCEv2高性能網絡。計算任務之間延遲敏感,但聯系緊密程度再低一些,通常可以選用RoCEv2的方式。RoCEv2在高性能、兼容性和低成本方面達成一個均衡。典型案例如EBS高性能塊存儲和分布式文件存儲。
標準Ethernet網絡。計算任務之間完全解耦,則通常采用標準以太網的方式。傳統的云計算下,微服務解構的互聯網業務通常采取此網絡方式。
2 理想化的算力調度
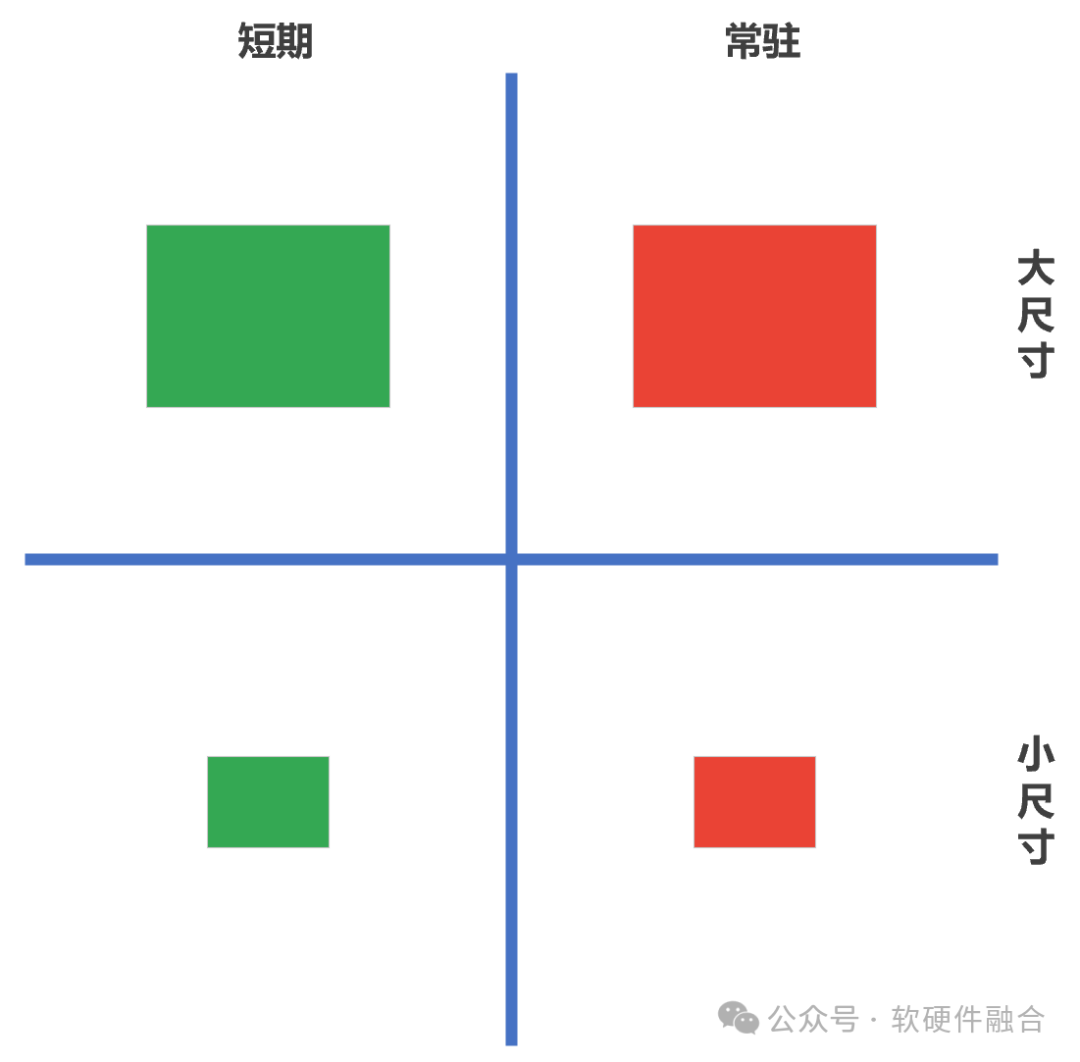
依據計算任務的時間和空間特性,相對應的算力調度方式也就分為四類:
短期的小尺寸計算任務。這是通常大家理解的算力調度,也是算力調度最簡單的情況。
短期的大尺寸計算任務。超算或AI大模型訓練的計算模式。
常駐的小尺寸計算任務。云計算常見的業務組織方式,是常駐的小尺寸計算任務。
長期的大尺寸計算任務。實際的互聯網型業務系統。
這里,我們從計算的角度,談一下計算方式的統一:
一個是,計算任務的解構(計算任務的彈性)。大尺寸的計算任務,可以拆分成若干個小尺寸的計算任務。從而使得計算任務能夠匹配單個裸機的計算主機(裸機、虛擬機、容器等);
另一個,計算資源的池化(虛擬化)和再組合(計算主機的彈性)。計算主機可以從1/N個處理器核、擴展到多個處理器核,甚至擴展到M個計算節點。因為計算主機的彈性,從而使得計算主機既可以適配小尺寸的計算任務,也可以適配大尺寸的計算任務。
兩者相向而行,并且均具有一定的(尺寸)彈性,從而能夠盡可能的適配對方。
3 實際算力調度中的問題
3.1 問題一:靜態調度和動態調度
靜態調度:計算任務在初始運行時,分配計算資源時候的調度。一般來說,短期型的計算任務,通常只有靜態調度,也即僅調度一次,運行結束后就立刻釋放計算資源。
動態調度:計算任務在運行的過程中,受計算資源的各類情況變化的影響,計算任務需要(重新)調度到其他計算資源,也即我們通常理解的業務遷移。常駐型的計算任務通常會遇到這樣的情況。
這里舉一個動態調度的案例——跨云邊端的高階自動駕駛汽車:
初始的時候,車輛由駕駛員駕駛。此刻,其他乘車人員,可以在車上玩游戲、看電影、聽音樂、刷短視頻等等。這些計算任務都運行在車輛終端本地。
當開啟自動駕駛時,本地算力不夠。游戲、電影、音樂、短視頻等計算任務,由于優先級較低,統一調度到邊緣側甚至云側。而自動駕駛的計算任務,由于尺寸較大,通常也是由解構的若干微服務組成。其中優先級較高的少量微服務,運行在車輛終端本地;而優先級較低的大部分微服務,也和游戲等其他計算任務一樣,運行在邊緣側甚至云側。
解除自動駕駛后,自動駕駛相關微服務(計算任務)退出,并且釋放本地和邊緣、云端的算力資源。而游戲等其他計算任務再從邊緣、云端,重新調度(遷移)到車輛終端本地。
3.2 問題二:任務的狀態
無狀態計算任務
如果是無狀態的計算任務,的確可以隨便調度。
但一個計算任務至少有兩個狀態,一個是計算任務的輸入,一個是計算任務的輸出。因此,任務調度會受輸入源和輸出目的的約束——不管調度到哪里,都需要能訪問源數據和寫入結果數據。
有狀態計算任務
如果是有狀態的計算任務,那么在運行的過程中,一方面是盡可能提高運行平臺的高可用性,盡量減少調度;另一方面則當不得不調度的時候,運行現場需要和計算任務一起調度。
3.3 任務間的關聯性
大任務拆分成小任務(巨服務微服務化),這些小任務間必然需要相互訪問。那么在調度的時候,就需要考慮這一層約束:凡是有關聯的計算任務,只能在一個集群(可網絡訪問)內調度。如果是跨集群,或者跨數據中心和云邊端的計算任務,則需要考慮網絡打通、訪問延遲、訪問權限等方面的問題。事情遠不是理想化的算力調度那么簡單!
因此,算力調度,此刻應該有兩層:
第一層,是全局算力調度。為這個大任務,或者用戶的若干大任務分配一個獨立的計算集群,可以是跨數據中心、跨云邊端的算力資源所組成的“虛擬”的集群。
另一層,則是用戶在自己的集群內部,進行業務層次的算力再調度。
3.4 任務的計算平臺要求
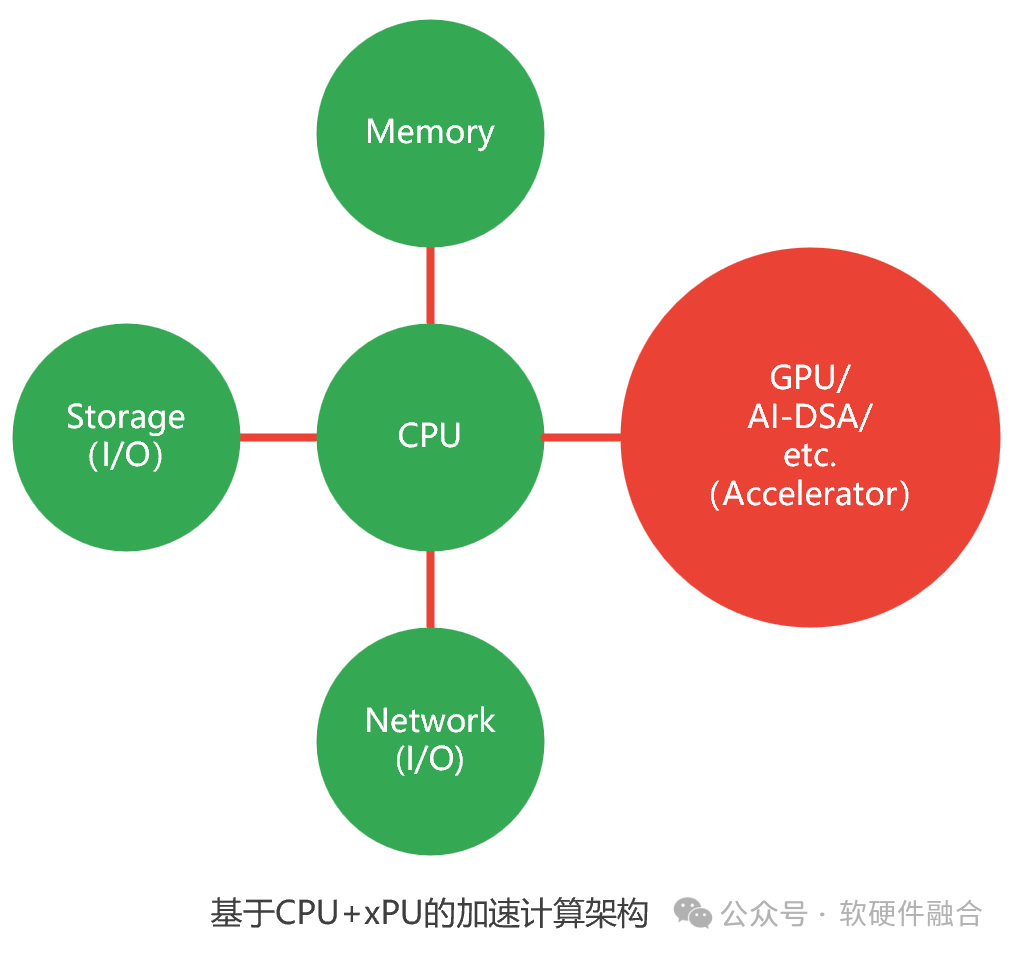
計算平臺由如下部分組成:
CPU處理器。CPU是圖靈完備的,可以自運行。
內存。計算數據暫存和數據共享的區域。
存儲I/O。本地的存儲通過片間總線,如PCIe;遠程的存儲需要通過網絡。
網絡I/O。網絡主要用于外部通信。在集群計算和計算存儲分離的場景下,網絡的功能主主要是三個:
訪問內網,東西向網絡,作為集群內部不同節點間的網絡通信,目前主要是IB;
訪問遠程存儲,目前主要使用RoCEv2;
訪問外網,南北向網絡,作為集群外部的訪問端口,目前主要是Ethernet。
一個或多個加速處理器:
從整個架構看,加速處理器是和CPU功能類似的計算部件。
其他加速處理器是非圖靈完備的,均需要組成CPU+xPU的異構計算架構。從CPU軟件視角看,加速處理器是跟網絡和存儲I/O類似的部件。
加速處理器,目前常用可以分為兩類:GPU,通用的并行計算加速平臺。DSA。領域專用加速器,DSA是完全專用(ASIC)向通用可編程性的微調。
因此,計算任務,在不同計算平臺調度的時候,需要考慮平臺的差異性:
CPU架構的差異性。CPU是x86、ARM還是其他架構;
網絡和存儲接口是否一致;
加速處理器的類型和架構是否一致。
目前,算力多樣性已經成為困擾算力調度最大的問題。如何在多元異構算力平臺上,實現統一調度,是目前算力中心發展要解決的重要問題之一。
4 宏觀視角:多租戶多系統的算力調度
計算的形態,從單機計算,走到了集群計算;并且,還在逐漸走進跨集群、跨數據中心、跨云邊端的協同計算,甚至融合計算。宏觀的看,一個計算系統,必然是數以萬計的租戶所擁有的數以百萬計的大計算任務(業務系統)共存。這里的每個大計算任務,又會拆分成數十個甚至上百個小計算任務(微服務)。也因此,宏觀的計算是:數以萬計租戶的數以億計的計算任務,并行不悖的交叉混合運行在數十個甚至上百個云算力中心、數以千計的邊緣數據中心,以及數以百萬計的終端計算節點上。 從算力的視角,全局存在一個統一的調度系統,所有的計算任務都是統一的調度的。調度系統能完全考慮并滿足所有計算任務的各種特性要求。 從業務的視角,調度通常是兩層:
業務從全局調度系統獲取自己的資源(第一層調度),組成自己的“虛擬”集群;
然后,業務的計算任務,在這“虛擬”集群里再進行調度。
全局調度為計算實例分配好資源之后,仍然可以動態調度(遷移),以保證計算實例的高可用。
業務從全局調度系統獲取資源也是動態的,可增加,可減少。
5 算力調度的分層
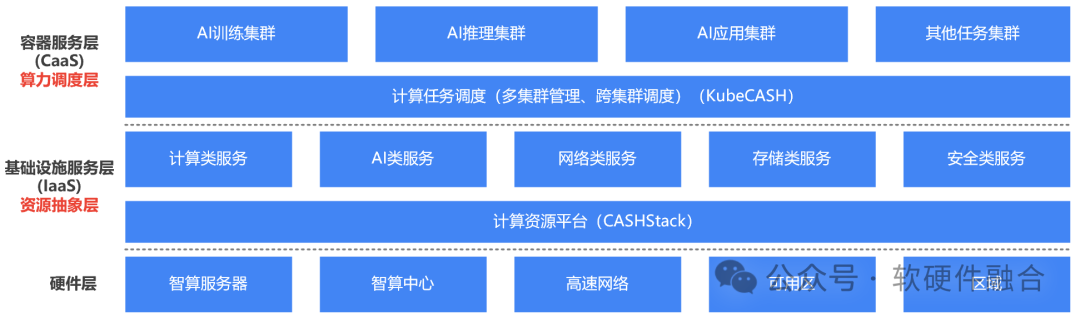
以容器和K8S容器管理為中心的云原生體系,越來越成熟,行業里出現了一個聲音:“是不是傳統IaaS虛擬化層就沒有存在的必要了?” 我們的觀點是:企業云場景,虛擬化的確沒有必要(企業云規模小,沒有必要那么復雜);但超大規模多租戶的算力中心場景,IaaS層仍然非常有必要,也仍然非常有價值。 這樣,在硬件之上,業務之下,存在兩層抽象層:
第一層,資源抽象層。通過計算機虛擬化,對資源進行抽象和封裝,以及資源的池化和彈性切分。目前,業界一些先進的解決方案,可以通過DPU的加持,實現虛擬化的零損耗,以及裸機和虛擬機的統一,既有裸機的性能又有虛機的高可用和彈性。因此,裸機和虛擬主機的相關劣勢已經“不復存在”。此外,通過虛擬化,可以實現接口的抽象統一,從而減少多元異構算力帶來架構/接口兼容性的問題。
第二層,算力調度層。容器化及云原生的核心優勢,是以應用為中心:一次打包,到處運行。因此,通常是以容器為載體,以容器為基礎調度粒度,從而實現算力的高效調度。
-
計算
+關注
關注
2文章
451瀏覽量
38865 -
調度
+關注
關注
0文章
53瀏覽量
10792 -
算力
+關注
關注
1文章
1012瀏覽量
14954
原文標題:聊一聊算力調度
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

算智算中心的算力如何衡量?

超算智算融合 南京信易達發布全新“智能算力融合平臺”

算力基礎篇:從零開始了解算力

大模型時代的算力需求
中科曙光入選2024算力服務產業圖譜及算力服務產品名錄
神州鯤泰亮相北京數字安全大會,以智能算力構筑數據安全的堅實底座

算力系列基礎篇——算力101:從零開始了解算力






 工商網監
工商網監
評論