") 人工智能、區(qū)塊鏈、算法...這30個(gè)大數(shù)據(jù)熱詞你知道嗎
人工智能、區(qū)塊鏈、算法...這30個(gè)大數(shù)據(jù)熱詞你知道嗎
前言
本文為您挑選了30個(gè)和大數(shù)據(jù)相關(guān)的網(wǎng)絡(luò)熱詞,看看你了解多少?
2017年,我國大數(shù)據(jù)產(chǎn)業(yè)保持高速發(fā)展態(tài)勢(shì),各級(jí)政府和企業(yè)大力推進(jìn),技術(shù)創(chuàng)新取得明顯突破,大數(shù)據(jù)應(yīng)用推進(jìn)勢(shì)頭良好,產(chǎn)業(yè)體系初具雛形,支撐能力日益增強(qiáng)。展望2018年,大數(shù)據(jù)產(chǎn)業(yè)發(fā)展將迎來“黃金期”,在滿城盡談大數(shù)據(jù)的時(shí)代,與時(shí)俱進(jìn)地了解一些大數(shù)據(jù)知識(shí)對(duì)生活和工作都大有裨益。本文為您挑選了30個(gè)和大數(shù)據(jù)相關(guān)的網(wǎng)絡(luò)熱詞,看看你了解多少?
一.人工智能
人工智能(Artificial Intelligence),英文縮寫為AI。它是研究、開發(fā)用于模擬、延伸和擴(kuò)展人的智能的理論、方法、技術(shù)及應(yīng)用系統(tǒng)的一門新的技術(shù)科學(xué)。
人工智能是計(jì)算機(jī)科學(xué)的一個(gè)分支,它企圖了解智能的實(shí)質(zhì),并生產(chǎn)出一種新的能以人類智能相似的方式做出反應(yīng)的智能機(jī)器,該領(lǐng)域的研究包括機(jī)器人、語言識(shí)別、圖像識(shí)別、自然語言處理和專家系統(tǒng)等。人工智能從誕生以來,理論和技術(shù)日益成熟,應(yīng)用領(lǐng)域也不斷擴(kuò)大,可以設(shè)想,未來人工智能帶來的科技產(chǎn)品,將會(huì)是人類智慧的“容器”。人工智能可以對(duì)人的意識(shí)、思維的信息過程的模擬。人工智能不是人的智能,但能像人那樣思考、也可能超過人的智能。
人工智能是一門極富挑戰(zhàn)性的科學(xué),從事這項(xiàng)工作的人必須懂得計(jì)算機(jī)知識(shí),心理學(xué)和哲學(xué)。人工智能是包括十分廣泛的科學(xué),它由不同的領(lǐng)域組成,如機(jī)器學(xué)習(xí),計(jì)算機(jī)視覺等等,總的說來,人工智能研究的一個(gè)主要目標(biāo)是使機(jī)器能夠勝任一些通常需要人類智能才能完成的復(fù)雜工作。但不同的時(shí)代、不同的人對(duì)這種“復(fù)雜工作”的理解是不同的。2017年12月,人工智能入選“2017年度中國媒體十大流行語”。
二.區(qū)塊鏈

狹義來講,區(qū)塊鏈?zhǔn)且环N按照時(shí)間順序?qū)?shù)據(jù)區(qū)塊以順序相連的方式組合成的一 種鏈?zhǔn)綌?shù)據(jù)結(jié)構(gòu), 并以密碼學(xué)方式保證的不可篡改和不可偽造的分布式賬本。廣義來講,區(qū)塊鏈技術(shù)是利用塊鏈?zhǔn)綌?shù)據(jù)結(jié)構(gòu)來驗(yàn)證與存儲(chǔ)數(shù)據(jù)、利用分布式節(jié)點(diǎn)共識(shí)算法來生成和更新數(shù)據(jù)、利用密碼學(xué)的方式保證數(shù)據(jù)傳輸和訪問的安全、利用由自動(dòng)化腳本代碼組成的智能合約來編程和操作數(shù)據(jù)的一種全新的分布式基礎(chǔ)架構(gòu)與計(jì)算范式。
三.圖靈測(cè)試
圖靈測(cè)試(The Turing test)由艾倫·麥席森·圖靈發(fā)明,指測(cè)試者與被測(cè)試者(一個(gè)人和一臺(tái)機(jī)器)隔開的情況下,通過一些裝置(如鍵盤)向被測(cè)試者隨意提問。
進(jìn)行多次測(cè)試后,如果有超過30%的測(cè)試者不能確定出被測(cè)試者是人還是機(jī)器,那么這臺(tái)機(jī)器就通過了測(cè)試,并被認(rèn)為具有人類智能。圖靈測(cè)試一詞來源于計(jì)算機(jī)科學(xué)和密碼學(xué)的先驅(qū)阿蘭·麥席森·圖靈寫于1950年的一篇論文《計(jì)算機(jī)器與智能》,其中30%是圖靈對(duì)2000年時(shí)的機(jī)器思考能力的一個(gè)預(yù)測(cè),目前我們已遠(yuǎn)遠(yuǎn)落后于這個(gè)預(yù)測(cè)。
四.回歸分析regression analysis
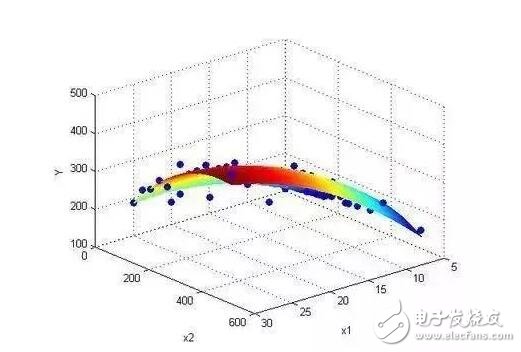
回歸分析(regression analysis)是確定兩種或兩種以上變量間相互依賴的定量關(guān)系的一種統(tǒng)計(jì)分析方法。運(yùn)用十分廣泛,回歸分析按照涉及的變量的多少,分為一元回歸和多元回歸分析;按照因變量的多少,可分為簡(jiǎn)單回歸分析和多重回歸分析;按照自變量和因變量之間的關(guān)系類型,可分為線性回歸分析和非線性回歸分析。如果在回歸分析中,只包括一個(gè)自變量和一個(gè)因變量,且二者的關(guān)系可用一條直線近似表示,這種回歸分析稱為一元線性回歸分析。如果回歸分析中包括兩個(gè)或兩個(gè)以上的自變量,且自變量之間存在線性相關(guān),則稱為多重線性回歸分析。
五.MapReduce
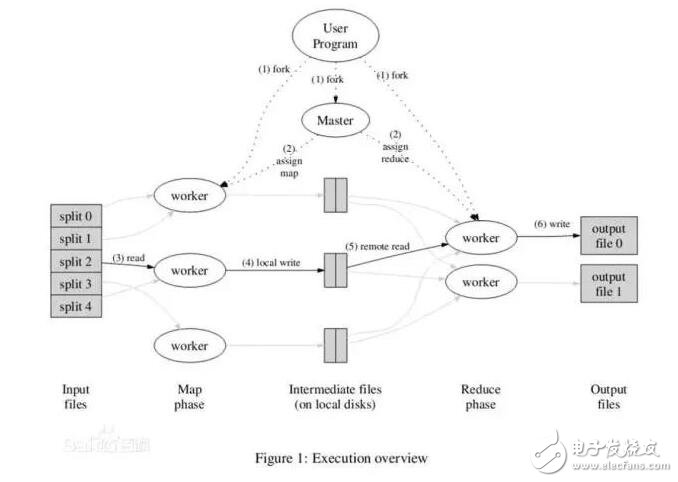
MapReduce是一種編程模型,用于大規(guī)模數(shù)據(jù)集(大于1TB)的并行運(yùn)算。概念"Map(映射)"和"Reduce(歸約)",是它們的主要思想,都是從函數(shù)式編程語言里借來的,還有從矢量編程語言里借來的特性。它極大地方便了編程人員在不會(huì)分布式并行編程的情況下,將自己的程序運(yùn)行在分布式系統(tǒng)上。 當(dāng)前的軟件實(shí)現(xiàn)是指定一個(gè)Map(映射)函數(shù),用來把一組鍵值對(duì)映射成一組新的鍵值對(duì),指定并發(fā)的Reduce(歸約)函數(shù),用來保證所有映射的鍵值對(duì)中的每一個(gè)共享相同的鍵組。
六.貪心算法
貪心算法(又稱貪婪算法)是指,在對(duì)問題求解時(shí),總是做出在當(dāng)前看來是最好的選擇。也就是說,不從整體最優(yōu)上加以考慮,他所做出的是在某種意義上的局部最優(yōu)解。
貪心算法不是對(duì)所有問題都能得到整體最優(yōu)解,關(guān)鍵是貪心策略的選擇,選擇的貪心策略必須具備無后效性,即某個(gè)狀態(tài)以前的過程不會(huì)影響以后的狀態(tài),只與當(dāng)前狀態(tài)有關(guān)。
貪心算法的基本思路是從問題的某一個(gè)初始解出發(fā)一步一步地進(jìn)行,根據(jù)某個(gè)優(yōu)化測(cè)度,每一步都要確保能獲得局部最優(yōu)解。每一步只考慮一個(gè)數(shù)據(jù),他的選取應(yīng)該滿足局部?jī)?yōu)化的條件。若下一個(gè)數(shù)據(jù)和部分最優(yōu)解連在一起不再是可行解時(shí),就不把該數(shù)據(jù)添加到部分解中,直到把所有數(shù)據(jù)枚舉完,或者不能再添加算法停止 。
七.數(shù)據(jù)挖掘
數(shù)據(jù)挖掘(英語:Data mining),又譯為資料探勘、數(shù)據(jù)采礦。它是數(shù)據(jù)庫知識(shí)發(fā)現(xiàn)(英語:Knowledge-Discovery in Databases,簡(jiǎn)稱:KDD)中的一個(gè)步驟。數(shù)據(jù)挖掘一般是指從大量的數(shù)據(jù)中通過算法搜索隱藏于其中信息的過程。數(shù)據(jù)挖掘通常與計(jì)算機(jī)科學(xué)有關(guān),并通過統(tǒng)計(jì)、在線分析處理、情報(bào)檢索、機(jī)器學(xué)習(xí)、專家系統(tǒng)(依靠過去的經(jīng)驗(yàn)法則)和模式識(shí)別等諸多方法來實(shí)現(xiàn)上述目標(biāo)。
八.數(shù)據(jù)可視化
數(shù)據(jù)可視化,是關(guān)于數(shù)據(jù)視覺表現(xiàn)形式的科學(xué)技術(shù)研究。其中,這種數(shù)據(jù)的視覺表現(xiàn)形式被定義為,一種以某種概要形式抽提出來的信息,包括相應(yīng)信息單位的各種屬性和變量。
它是一個(gè)處于不斷演變之中的概念,其邊界在不斷地?cái)U(kuò)大。主要指的是技術(shù)上較為高級(jí)的技術(shù)方法,而這些技術(shù)方法允許利用圖形、圖像處理、計(jì)算機(jī)視覺以及用戶界面,通過表達(dá)、建模以及對(duì)立體、表面、屬性以及動(dòng)畫的顯示,對(duì)數(shù)據(jù)加以可視化解釋。與立體建模之類的特殊技術(shù)方法相比,數(shù)據(jù)可視化所涵蓋的技術(shù)方法要廣泛得多。
九.分布式計(jì)算Distributed computing
在計(jì)算機(jī)科學(xué)中,分布式計(jì)算(英語:Distributed computing,又譯為分散式計(jì)算)這個(gè)研究領(lǐng)域,主要研究分散系統(tǒng)(Distributed system)如何進(jìn)行計(jì)算。分散系統(tǒng)是一組電子計(jì)算機(jī)(computer),通過計(jì)算機(jī)網(wǎng)絡(luò)相互鏈接與通信后形成的系統(tǒng)。把需要進(jìn)行大量計(jì)算的工程數(shù)據(jù)分區(qū)成小塊,由多臺(tái)計(jì)算機(jī)分別計(jì)算,在上傳運(yùn)算結(jié)果后,將結(jié)果統(tǒng)一合并得出數(shù)據(jù)結(jié)論的科學(xué)。
十.分布式架構(gòu)
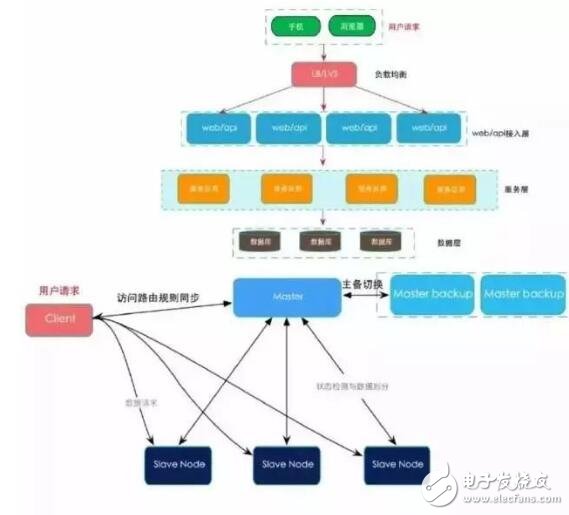
分布式架構(gòu)是 分布式計(jì)算技術(shù)的應(yīng)用和工具,目前成熟的技術(shù)包括J2EE, CORBA和.NET(DCOM),這些技術(shù)牽扯的內(nèi)容非常廣,相關(guān)的書籍也非常多,本文不介紹這些技術(shù)的內(nèi)容,也沒有涉及這些技術(shù)的細(xì)節(jié),只是從各種分布式系統(tǒng)平臺(tái)產(chǎn)生的背景和在軟件開發(fā)中應(yīng)用的情況來探討它們的主要異同。
十一.Hadoop
Hadoop是一個(gè)由Apache基金會(huì)所開發(fā)的分布式系統(tǒng)基礎(chǔ)架構(gòu)。
用戶可以在不了解分布式底層細(xì)節(jié)的情況下,開發(fā)分布式程序。充分利用集群的威力進(jìn)行高速運(yùn)算和存儲(chǔ)。
Hadoop實(shí)現(xiàn)了一個(gè)分布式文件系統(tǒng)(Hadoop Distributed File System),簡(jiǎn)稱HDFS。HDFS有高容錯(cuò)性的特點(diǎn),并且設(shè)計(jì)用來部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)來訪問應(yīng)用程序的數(shù)據(jù),適合那些有著超大數(shù)據(jù)集(large data set)的應(yīng)用程序。HDFS放寬了(relax)POSIX的要求,可以以流的形式訪問(streaming access)文件系統(tǒng)中的數(shù)據(jù)。
Hadoop的框架最核心的設(shè)計(jì)就是:HDFS和MapReduce。HDFS為海量的數(shù)據(jù)提供了存儲(chǔ),則MapReduce為海量的數(shù)據(jù)提供了計(jì)算。
十二.BI商業(yè)智能
BI(Business Intelligence)即商務(wù)智能,它是一套完整的解決方案,用來將企業(yè)中現(xiàn)有的數(shù)據(jù)進(jìn)行有效的整合,快速準(zhǔn)確的提供報(bào)表并提出決策依據(jù),幫助企業(yè)做出明智的業(yè)務(wù)經(jīng)營決策。
商業(yè)智能的概念最早在1996年提出。當(dāng)時(shí)將商業(yè)智能定義為一類由數(shù)據(jù)倉庫(或數(shù)據(jù)集市)、查詢報(bào)表、數(shù)據(jù)分析、數(shù)據(jù)挖掘、數(shù)據(jù)備份和恢復(fù)等部分組成的、以幫助企業(yè)決策為目的技術(shù)及其應(yīng)用。而這些數(shù)據(jù)可能來自企業(yè)的CRM、SCM等業(yè)務(wù)系統(tǒng)。
商業(yè)智能能夠輔助的業(yè)務(wù)經(jīng)營決策,既可以是操作層的,也可以是戰(zhàn)術(shù)層和戰(zhàn)略層的決策。為了將數(shù)據(jù)轉(zhuǎn)化為知識(shí),需要利用數(shù)據(jù)倉庫、聯(lián)機(jī)分析處理(OLAP)工具和數(shù)據(jù)挖掘等技術(shù)。因此,從技術(shù)層面上講,商業(yè)智能不是什么新技術(shù),它只是數(shù)據(jù)倉庫、OLAP和數(shù)據(jù)挖掘等技術(shù)的綜合運(yùn)用。
十三.非關(guān)系型數(shù)據(jù)庫NoSQL
非關(guān)系型數(shù)據(jù)庫,又被稱為NoSQL(Not Only SQL ),意為不僅僅是SQL( Stmuctured QueryLanguage,結(jié)構(gòu)化查詢語言),據(jù)維基百科介紹,NoSQL最早出現(xiàn)于1998 年,是由Carlo Storzzi最早開發(fā)的個(gè)輕量、開源、不兼容SQL 功能的關(guān)系型數(shù)據(jù)庫,2009 年,在一次分布式開源數(shù)據(jù)庫的討論會(huì)上,再次提出了NOSQL 的概念,此時(shí)NOSQL主要是指I非關(guān)系型、分布式、不提供ACID (數(shù)據(jù)庫事務(wù)處理的四個(gè)本要素)的數(shù)據(jù)庫設(shè)計(jì)模式。同年,在業(yè)特蘭大舉行的“NO:SQL(east)”討論會(huì)上,對(duì)NOSQL 最普遍的定義是“非關(guān)聯(lián)型的”,強(qiáng)調(diào)Key-Value 存儲(chǔ)和文檔數(shù)據(jù)庫的優(yōu)點(diǎn),而不是單純地反對(duì)RDBMS,至此,NoSQL 開始正式出現(xiàn)在世人面前。
十四.結(jié)構(gòu)化數(shù)據(jù)
結(jié)構(gòu)化數(shù)據(jù),簡(jiǎn)單來說就是數(shù)據(jù)庫。結(jié)合到典型場(chǎng)景中更容易理解,比如企業(yè)ERP、財(cái)務(wù)系統(tǒng);醫(yī)療HIS數(shù)據(jù)庫;教育一卡通;政府行政審批;其他核心數(shù)據(jù)庫等。
基本包括高速存儲(chǔ)應(yīng)用需求、數(shù)據(jù)備份需求、數(shù)據(jù)共享需求以及數(shù)據(jù)容災(zāi)需求。
十五.半結(jié)構(gòu)化數(shù)據(jù)
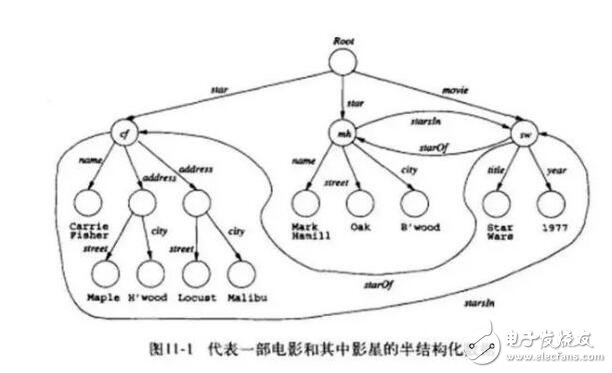
和普通純文本相比,半結(jié)構(gòu)化數(shù)據(jù)具有一定的結(jié)構(gòu)性,但和具有嚴(yán)格理論模型的關(guān)系數(shù)據(jù)庫的數(shù)據(jù)相比。OEM(Object exchange Model)是一種典型的半結(jié)構(gòu)化數(shù)據(jù)模型。
在做一個(gè)信息系統(tǒng)設(shè)計(jì)時(shí)肯定會(huì)涉及到數(shù)據(jù)的存儲(chǔ),一般我們都會(huì)將系統(tǒng)信息保存在某個(gè)指定的關(guān)系數(shù)據(jù)庫中。我們會(huì)將數(shù)據(jù)按業(yè)務(wù)分類,并設(shè)計(jì)相應(yīng)的表,然后將對(duì)應(yīng)的信息保存到相應(yīng)的表中。比如我們做一個(gè)業(yè)務(wù)系統(tǒng),要保存員工基本信息:工號(hào)、姓名、性別、出生日期等等;我們就會(huì)建立一個(gè)對(duì)應(yīng)的staff表。
十六.非結(jié)構(gòu)化數(shù)據(jù)
非結(jié)構(gòu)化數(shù)據(jù)庫是指其字段長(zhǎng)度可變,并且每個(gè)字段的記錄又可以由可重復(fù)或不可重復(fù)的子字段構(gòu)成的數(shù)據(jù)庫,用它不僅可以處理結(jié)構(gòu)化數(shù)據(jù)(如數(shù)字、符號(hào)等信息)而且更適合處理非結(jié)構(gòu)化數(shù)據(jù)(全文文本、圖象、聲音、影視、超媒體等信息)。
十七.數(shù)據(jù)清洗
數(shù)據(jù)清洗從名字上也看的出就是把“臟”的“洗掉”,指發(fā)現(xiàn)并糾正數(shù)據(jù)文件中可識(shí)別的錯(cuò)誤的最后一道程序,包括檢查數(shù)據(jù)一致性,處理無效值和缺失值等。因?yàn)閿?shù)據(jù)倉庫中的數(shù)據(jù)是面向某一主題的數(shù)據(jù)的集合,這些數(shù)據(jù)從多個(gè)業(yè)務(wù)系統(tǒng)中抽取而來而且包含歷史數(shù)據(jù),這樣就避免不了有的數(shù)據(jù)是錯(cuò)誤數(shù)據(jù)、有的數(shù)據(jù)相互之間有沖突,這些錯(cuò)誤的或有沖突的數(shù)據(jù)顯然是我們不想要的,稱為“臟數(shù)據(jù)”。我們要按照一定的規(guī)則把“臟數(shù)據(jù)”“洗掉”,這就是數(shù)據(jù)清洗。而數(shù)據(jù)清洗的任務(wù)是過濾那些不符合要求的數(shù)據(jù),將過濾的結(jié)果交給業(yè)務(wù)主管部門,確認(rèn)是否過濾掉還是由業(yè)務(wù)單位修正之后再進(jìn)行抽取。不符合要求的數(shù)據(jù)主要是有不完整的數(shù)據(jù)、錯(cuò)誤的數(shù)據(jù)、重復(fù)的數(shù)據(jù)三大類。數(shù)據(jù)清洗是與問卷審核不同,錄入后的數(shù)據(jù)清理一般是由計(jì)算機(jī)而不是人工完成。
十八.算法
算法(Algorithm)是指解題方案的準(zhǔn)確而完整的描述,是一系列解決問題的清晰指令,算法代表著用系統(tǒng)的方法描述解決問題的策略機(jī)制。也就是說,能夠?qū)σ欢ㄒ?guī)范的輸入,在有限時(shí)間內(nèi)獲得所要求的輸出。如果一個(gè)算法有缺陷,或不適合于某個(gè)問題,執(zhí)行這個(gè)算法將不會(huì)解決這個(gè)問題。不同的算法可能用不同的時(shí)間、空間或效率來完成同樣的任務(wù)。一個(gè)算法的優(yōu)劣可以用空間復(fù)雜度與時(shí)間復(fù)雜度來衡量。
深度學(xué)習(xí)的概念源于人工神經(jīng)網(wǎng)絡(luò)的研究。含多隱層的多層感知器就是一種深度學(xué)習(xí)結(jié)構(gòu)。深度學(xué)習(xí)通過組合低層特征形成更加抽象的高層表示屬性類別或特征,以發(fā)現(xiàn)數(shù)據(jù)的分布式特征表示。
深度學(xué)習(xí)的概念由Hinton等人于2006年提出。基于深信度網(wǎng)(DBN)提出非監(jiān)督貪心逐層訓(xùn)練算法,為解決深層結(jié)構(gòu)相關(guān)的優(yōu)化難題帶來希望,隨后提出多層自動(dòng)編碼器深層結(jié)構(gòu)。此外Lecun等人提出的卷積神經(jīng)網(wǎng)絡(luò)是第一個(gè)真正多層結(jié)構(gòu)學(xué)習(xí)算法,它利用空間相對(duì)關(guān)系減少參數(shù)數(shù)目以提高訓(xùn)練性能。
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)研究中的一個(gè)新的領(lǐng)域,其動(dòng)機(jī)在于建立、模擬人腦進(jìn)行分析學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò),它模仿人腦的機(jī)制來解釋數(shù)據(jù),例如圖像,聲音和文本。
二十.人工神經(jīng)網(wǎng)絡(luò)
人工神經(jīng)網(wǎng)絡(luò)(Artificial Neural Networks,簡(jiǎn)寫為ANNs)也簡(jiǎn)稱為神經(jīng)網(wǎng)絡(luò)(NNs)或稱作連接模型(Connection Model),它是一種模仿動(dòng)物神經(jīng)網(wǎng)絡(luò)行為特征,進(jìn)行分布式并行信息處理的算法數(shù)學(xué)模型。這種網(wǎng)絡(luò)依靠系統(tǒng)的復(fù)雜程度,通過調(diào)整內(nèi)部大量節(jié)點(diǎn)之間相互連接的關(guān)系,從而達(dá)到處理信息的目的。
二十一.數(shù)據(jù)聚類
數(shù)據(jù)聚類 (英語 : Cluster analysis) 是對(duì)于靜態(tài)數(shù)據(jù)分析的一門技術(shù),在許多領(lǐng)域受到廣泛應(yīng)用,包括機(jī)器學(xué)習(xí),數(shù)據(jù)挖掘,模式識(shí)別,圖像分析以及生物信息。聚類是把相似的對(duì)象通過靜態(tài)分類的方法分成不同的組別或者更多的子集(subset),這樣讓在同一個(gè)子集中的成員對(duì)象都有相似的一些屬性,常見的包括在坐標(biāo)系中更加短的空間距離等。
二十二.隨機(jī)森林
在機(jī)器學(xué)習(xí)中,隨機(jī)森林是一個(gè)包含多個(gè)決策樹的分類器, 并且其輸出的類別是由個(gè)別樹輸出的類別的眾數(shù)而定。 Leo Breiman和Adele Cutler發(fā)展出推論出隨機(jī)森林的算法。 而 “Random Forests” 是他們的商標(biāo)。 這個(gè)術(shù)語是1995年由貝爾實(shí)驗(yàn)室的Tin Kam Ho所提出的隨機(jī)決策森林(random decision forests)而來的。這個(gè)方法則是結(jié)合 Breimans 的 “Bootstrap aggregating” 想法和 Ho 的”random subspace method”” 以建造決策樹的集合。
二十三.分治法
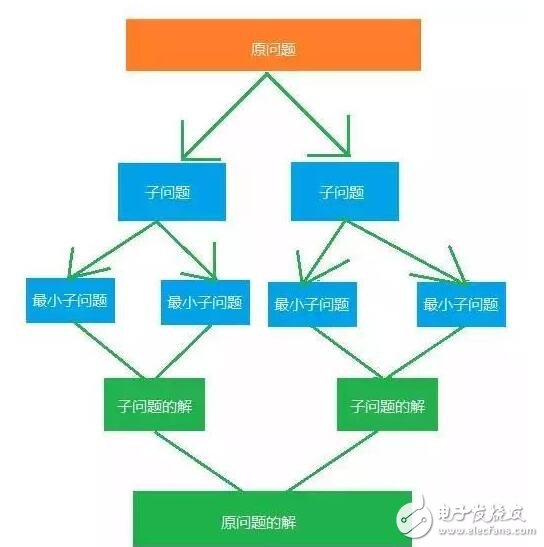
在計(jì)算機(jī)科學(xué)中,分治法是一種很重要的算法。字面上的解釋是“分而治之”,就是把一個(gè)復(fù)雜的問題分成兩個(gè)或更多的相同或相似的子問題,再把子問題分成更小的子問題……直到最后子問題可以簡(jiǎn)單的直接求解,原問題的解即子問題的解的合并。這個(gè)技巧是很多高效算法的基礎(chǔ),如排序算法(快速排序,歸并排序),傅立葉變換(快速傅立葉變換)。
二十四.支持向量機(jī)
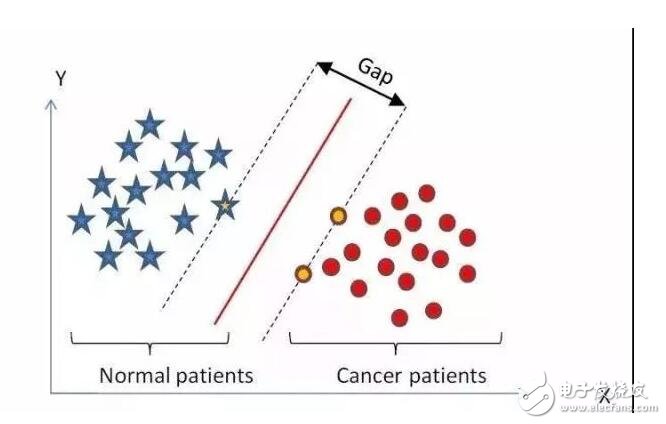
在機(jī)器學(xué)習(xí)領(lǐng)域,支持向量機(jī)SVM(Support Vector Machine)是一個(gè)有監(jiān)督的學(xué)習(xí)模型,通常用來進(jìn)行模式識(shí)別、分類、以及回歸分析。
SVM的主要思想可以概括為兩點(diǎn):⑴它是針對(duì)線性可分情況進(jìn)行分析,對(duì)于線性不可分的情況,通過使用非線性映射算法將低維輸入空間線性不可分的樣本轉(zhuǎn)化為高維特征空間使其線性可分,從而 使得高維特征空間采用線性算法對(duì)樣本的非線性特征進(jìn)行線性分析成為可能。
二十五.熵
熵(entropy)指的是體系的混亂的程度,它在控制論、概率論、數(shù)論、天體物理、生命科學(xué)等領(lǐng)域都有重要應(yīng)用,在不同的學(xué)科中也有引申出的更為具體的定義,是各領(lǐng)域十分重要的參量。熵的概念由魯?shù)婪颉た藙谛匏梗≧udolf Clausius)于1850年提出,并應(yīng)用在熱力學(xué)中。1948年,克勞德·艾爾伍德·香農(nóng)(Claude Elwood Shannon)第一次將熵的概念引入信息論中。
二十六.辛普森悖論
辛普森悖論亦有人譯為辛普森詭論,為英國統(tǒng)計(jì)學(xué)家E.H.辛普森(E.H.Simpson)于1951年提出的悖論,即在某個(gè)條件下的兩組數(shù)據(jù),分別討論時(shí)都會(huì)滿足某種性質(zhì),可是一旦合并考慮,卻可能導(dǎo)致相反的結(jié)論。
當(dāng)人們嘗試探究?jī)煞N變量是否具有相關(guān)性的時(shí)候,比如新生錄取率與性別,報(bào)酬與性別等,會(huì)分別對(duì)之進(jìn)行分組研究。辛普森悖論是在這種研究中,在某些前提下有時(shí)會(huì)產(chǎn)生的一種現(xiàn)象。即在分組比較中都占優(yōu)勢(shì)的一方,會(huì)在總評(píng)中反而是失勢(shì)的一方。該現(xiàn)象于20世紀(jì)初就有人討論,但一直到1951年E.H.辛普森在他發(fā)表的論文中,該現(xiàn)象才算正式被描述解釋。后來就以他的名字命名該悖論。
為了避免辛普森悖論的出現(xiàn),就需要斟酌各分組的權(quán)重,并乘以一定的系數(shù)去消除以分組數(shù)據(jù)基數(shù)差異而造成的影響。同時(shí)必需了解清楚情況,是否存在潛在因素,綜合考慮。
二十七.樸素貝葉斯模型
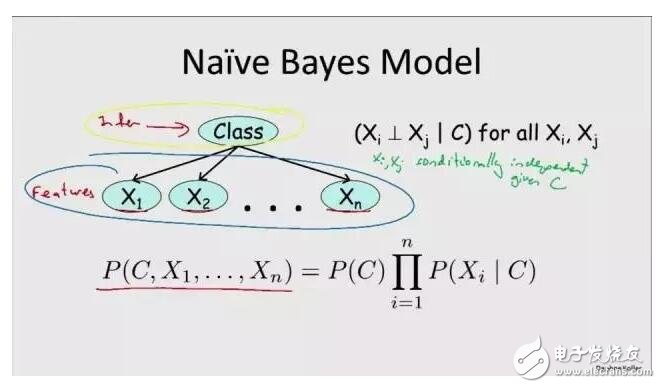
貝葉斯分類是一系列分類算法的總稱,這類算法均以貝葉斯定理為基礎(chǔ),故統(tǒng)稱為貝葉斯分類。樸素貝葉斯算法(Naive Bayesian) 是其中應(yīng)用最為廣泛的分類算法之一。
樸素貝葉斯分類器基于一個(gè)簡(jiǎn)單的假定:給定目標(biāo)值時(shí)屬性之間相互條件獨(dú)立。
通過以上定理和“樸素”的假定,我們知道:P( Category | Document) = P ( Document | Category ) * P( Category) / P(Document)。
二十八.數(shù)據(jù)科學(xué)家
數(shù)據(jù)科學(xué)家是指能采用科學(xué)方法、運(yùn)用數(shù)據(jù)挖掘工具對(duì)復(fù)雜多量的數(shù)字、符號(hào)、文字、網(wǎng)址、音頻或視頻等信息進(jìn)行數(shù)字化重現(xiàn)與認(rèn)識(shí),并能尋找新的數(shù)據(jù)洞察的工程師或?qū)<?不同于統(tǒng)計(jì)學(xué)家或分析師)。一個(gè)優(yōu)秀的數(shù)據(jù)科學(xué)家需要具備的素質(zhì)有:懂?dāng)?shù)據(jù)采集、懂?dāng)?shù)學(xué)算法、懂?dāng)?shù)學(xué)軟件、懂?dāng)?shù)據(jù)分析、懂預(yù)測(cè)分析、懂市場(chǎng)應(yīng)用、懂決策分析等。
二十九.并行處理
并行處理是計(jì)算機(jī)系統(tǒng)中能同時(shí)執(zhí)行兩個(gè)或更多個(gè)處理機(jī)的一種計(jì)算方法。處理機(jī)可同時(shí)工作于同一程序的不同方面。并行處理的主要目的是節(jié)省大型和復(fù)雜問題的解決時(shí)間。為使用并行處理,首先需要對(duì)程序進(jìn)行并行化處理,也就是說將工作各部分分配到不同處理機(jī)中。而主要問題是并行是一個(gè)相互依靠性問題,而不能自動(dòng)實(shí)現(xiàn)。此外,并行也不能保證加速。但是一個(gè)在 n 個(gè)處理機(jī)上執(zhí)行的程序速度可能會(huì)是在單一處理機(jī)上執(zhí)行的速度的 n 倍。
三十.云計(jì)算
云計(jì)算(cloud computing)是基于互聯(lián)網(wǎng)的相關(guān)服務(wù)的增加、使用和交付模式,通常涉及通過互聯(lián)網(wǎng)來提供動(dòng)態(tài)易擴(kuò)展且經(jīng)常是虛擬化的資源。云是網(wǎng)絡(luò)、互聯(lián)網(wǎng)的一種比喻說法。過去在圖中往往用云來表示電信網(wǎng),后來也用來表示互聯(lián)網(wǎng)和底層基礎(chǔ)設(shè)施的抽象。因此,云計(jì)算甚至可以讓你體驗(yàn)每秒10萬億次的運(yùn)算能力,擁有這么強(qiáng)大的計(jì)算能力可以模擬核爆炸、預(yù)測(cè)氣候變化和市場(chǎng)發(fā)展趨勢(shì)。用戶通過電腦、筆記本、手機(jī)等方式接入數(shù)據(jù)中心,按自己的需求進(jìn)行運(yùn)算。
-
算法
+關(guān)注
關(guān)注
23文章
4630瀏覽量
93356 -
人工智能
+關(guān)注
關(guān)注
1796文章
47676瀏覽量
240297 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8908瀏覽量
137798 -
區(qū)塊鏈
+關(guān)注
關(guān)注
111文章
15563瀏覽量
106702
原文標(biāo)題:人工智能、區(qū)塊鏈、算法...這30個(gè)大數(shù)據(jù)熱詞你知道嗎?
文章出處:【微信號(hào):tyutcsplab,微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
嵌入式和人工智能究竟是什么關(guān)系?
人工智能云計(jì)算大數(shù)據(jù)三者關(guān)系
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第6章人AI與能源科學(xué)讀后感
AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第4章-AI與生命科學(xué)讀后感
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第一章人工智能驅(qū)動(dòng)的科學(xué)創(chuàng)新學(xué)習(xí)心得
risc-v在人工智能圖像處理應(yīng)用前景分析
人工智能ai4s試讀申請(qǐng)
名單公布!【書籍評(píng)測(cè)活動(dòng)NO.44】AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新
報(bào)名開啟!深圳(國際)通用人工智能大會(huì)將啟幕,國內(nèi)外大咖齊聚話AI
FPGA在人工智能中的應(yīng)用有哪些?
基于多物理參數(shù)數(shù)據(jù)融合和先進(jìn)人工智能算法的鋰電池熱失控監(jiān)測(cè)傳感器

科達(dá)嘉電感器在大數(shù)據(jù)與人工智能領(lǐng)域被廣泛應(yīng)用
為何電感器對(duì)于大數(shù)據(jù)及人工智能產(chǎn)業(yè)發(fā)展至關(guān)重要






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論