 堆和堆的應用:堆排序和優先隊列
堆和堆的應用:堆排序和優先隊列
1.堆
堆(Heap))是一種重要的數據結構,是實現優先隊列(Priority Queues)首選的數據結構。由于堆有很多種變體,包括二項式堆、斐波那契堆等,但是這里只考慮最常見的就是二叉堆(以下簡稱堆)。
堆是一棵滿足一定性質的二叉樹,具體的講堆具有如下性質:父節點的鍵值總是不大于它的孩子節點的鍵值(小頂堆), 堆可以分為小頂堆和大頂堆,這里以小頂堆為例,其主要包含的操作有:
insert()
extractMin
peek(findMin)
delete(i)
由于堆是一棵形態規則的二叉樹,因此堆的父節點和孩子節點存在如下關系:
設父節點的編號為i, 則其左孩子節點的編號為2*i+1, 右孩子節點的編號為2*i+2設孩子節點的編號為i, 則其父節點的編號為(i-1)/2
由于二叉樹良好的形態已經包含了父節點和孩子節點的關系信息,因此就可以不使用鏈表而簡單的使用數組來存儲堆。
要實現堆的基本操作,涉及到的兩個關鍵的函數
siftUp(i, x): 將位置i的元素x向上調整,以滿足堆得性質,常常是用于insert后,用于調整堆;
siftDown(i, x):同理,常常是用于delete(i)后,用于調整堆;
具體的操作如下:
privatevoidsiftUp(inti){
intkey = nums[i];
for(;i > 0;){
intp = (i - 1) >>> 1;
if(nums[p] <= key)
break;
nums[i] = nums[p];
i = p;
}
nums[i] = key;
}
privatevoidsiftDown(inti){
intkey = nums[i];
for(;i < nums.length / 2;){
intchild = (i << 1) + 1;
if(child + 1 < nums.length && nums[child] > nums[child+1])
child++;
if(key <= nums[child])
break;
nums[i] = nums[child];
i = child;
}
nums[i] = key;
}
可以看到siftUp和siftDown不停的在父節點和子節點之間比較、交換;在不超過logn的時間復雜度就可以完成一次操作。
有了這兩個基本的函數,就可以實現上述提及的堆的基本操作。
首先是如何建堆,實現建堆操作有兩個思路:
一個是不斷地insert(insert后調用的是siftUp)
另一個將原始數組當成一個需要調整的堆,然后自底向上地在每個位置i調用siftDown(i),完成后我們就可以得到一個滿足堆性質的堆。這里考慮后一種思路:
通常堆的insert操作是將元素插入到堆尾,由于新元素的插入可能違反堆的性質,因此需要調用siftUp操作自底向上調整堆;堆移除堆頂元素操作是將堆頂元素刪除,然后將堆最后一個元素放置在堆頂,接著執行siftDown操作,同理替換堆頂元素也是相同的操作。
建堆
// 建立小頂堆
privatevoidbuildMinHeap(int[]nums){
intsize = nums.length;
for(intj = size / 2 - 1;j >= 0;j--)
siftDown(nums,j,size);
}
那么建堆操作的時間復雜度是多少呢?答案是O(n)。雖然siftDown的操作時間是logn,但是由于高度在遞減的同時,每一層的節點數量也在成倍減少,最后通過數列錯位相減可以得到時間復雜度是O(n)。
extractMin由于堆的固有性質,堆的根便是最小的元素,因此peek操作就是返回根nums[0]元素即可;若要將nums[0]刪除,可以將末尾的元素nums[n-1]覆蓋nums[0],然后將堆得size = size-1,調用siftDown(0)調整堆。時間復雜度為logn。
peek同上
delete(i)
刪除堆中位置為i的節點,涉及到兩個函數siftUp和siftDown,時間復雜度為logn,具體步驟是,
將元素last覆蓋元素i,然后siftDown
檢查是否需要siftUp
注意到堆的刪除操作,如果是刪除堆的根節點,則不用考慮執行siftUp的操作;若刪除的是堆的非根節點,則要視情況決定是siftDown還是siftUp操作,兩個操作是互斥的。
publicintdelete(inti){
intkey = nums[i];
//將last元素移動過來,先siftDown; 再視情況考慮是否siftUp
intlast = nums[i] = nums[size-1];
size--;
siftDown(i);
//check #i的node的鍵值是否確實發生改變(是否siftDown操作生效),若發生改變,則ok,否則為確保堆性質,則需要siftUp
if(i < size && nums[i] == last){
System.out.println("delete siftUp");
siftUp(i);
}
returnkey;
}
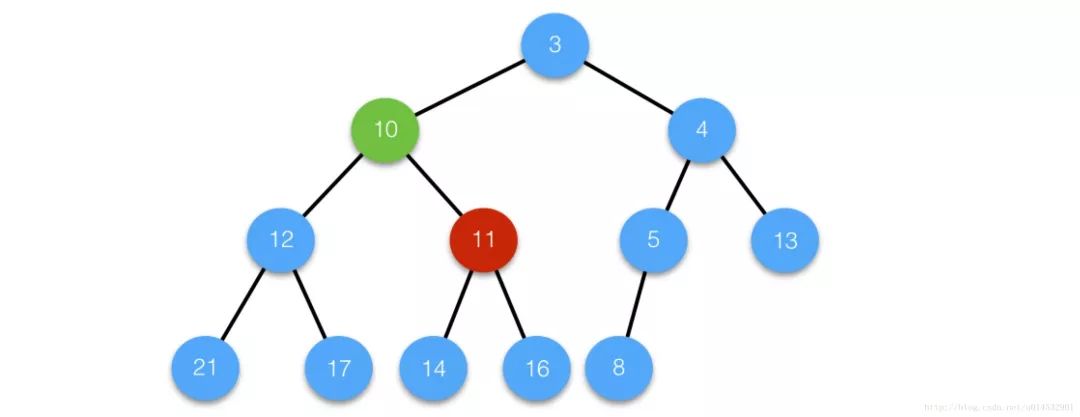
case 1 :
刪除中間節點i21,將最后一個節點復制過來;

由于沒有進行siftDown操作,節點i的值仍然為6,因此為確保堆的性質,執行siftUp操作;

case 2
刪除中間節點i,將值為11的節點復制過來,執行siftDown操作;

由于執行siftDown操作后,節點i的值不再是11,因此就不用再執行siftUp操作了,因為堆的性質在siftDown操作生效后已經得到了保持。
可以看出,堆的基本操作都依賴于兩個核心的函數siftUp和siftDown;較為完整的Heap代碼如下:
classHeap{
privatefinalstaticintN = 100;//default size
privateint[]nums;
privateintsize;
publicHeap(int[]nums){
this.nums = nums;
this.size = nums.length;
heapify(this.nums);
}
publicHeap(){
this.nums = newint[N];
}
/**
* heapify an array, O(n)
* @param nums An array to be heapified.
*/
privatevoidheapify(int[]nums){
for(intj = (size - 1) >> 1;j >= 0;j--)
siftDown(j);
}
/**
* append x to heap
* O(logn)
* @param x
* @return
*/
publicintinsert(intx){
if(size >= this.nums.length)
expandSpace();
size += 1;
nums[size-1] = x;
siftUp(size-1);
returnx;
}
/**
* delete an element located in i position.
* O(logn)
* @param i
* @return
*/
publicintdelete(inti){
rangeCheck(i);
intkey = nums[i];
//將last元素覆蓋過來,先siftDown; 再視情況考慮是否siftUp;
intlast = nums[i] = nums[size-1];
size--;
siftDown(i);
//check #i的node的鍵值是否確實發生改變,若發生改變,則ok,否則為確保堆性質,則需要siftUp;
if(i < size && nums[i] == last)
siftUp(i);
returnkey;
}
/**
* remove the root of heap, return it's value, and adjust heap to maintain the heap's property.
* O(logn)
* @return
*/
publicintextractMin(){
rangeCheck(0);
intkey = nums[0],last = nums[size-1];
nums[0] = last;
size--;
siftDown(0);
returnkey;
}
/**
* return an element's index, if not exists, return -1;
* O(n)
* @param x
* @return
*/
publicintsearch(intx){
for(inti = 0;i < size;i++)
if(nums[i] == x)
returni;
return -1;
}
/**
* return but does not remove the root of heap.
* O(1)
* @return
*/
publicintpeek(){
rangeCheck(0);
returnnums[0];
}
privatevoidsiftUp(inti){
intkey = nums[i];
for(;i > 0;){
intp = (i - 1) >>> 1;
if(nums[p] <= key)
break;
nums[i] = nums[p];
i = p;
}
nums[i] = key;
}
privatevoidsiftDown(inti){
intkey = nums[i];
for(;i < size / 2;){
intchild = (i << 1) + 1;
if(child + 1 < size && nums[child] > nums[child+1])
child++;
if(key <= nums[child])
break;
nums[i] = nums[child];
i = child;
}
nums[i] = key;
}
privatevoidrangeCheck(inti){
if(!(0 <= i && i < size))
thrownewRuntimeException("Index is out of boundary");
}
privatevoidexpandSpace(){
this.nums = Arrays.copyOf(this.nums,size *2);
}
publicStringtoString(){
// TODO Auto-generated method stub
StringBuilder sb = newStringBuilder();
sb.append("[");
for(inti = 0;i < size;i++)
sb.append(String.format((i != 0?", " : "") + "%d",nums[i]));
sb.append("] ");
returnsb.toString();
}
}
2.堆的應用:堆排序
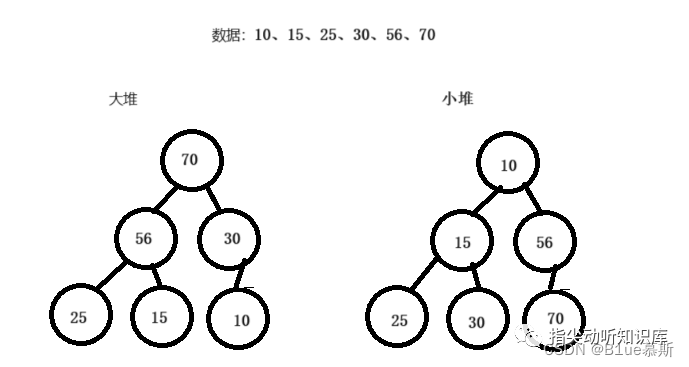
運用堆的性質,我們可以得到一種常用的、穩定的、高效的排序算法————堆排序。堆排序的時間復雜度為O(n*log(n)),空間復雜度為O(1),堆排序的思想是:對于含有n個元素的無序數組nums, 構建一個堆(這里是小頂堆)heap,然后執行extractMin得到最小的元素,這樣執行n次得到序列就是排序好的序列。如果是降序排列則是小頂堆;否則利用大頂堆。
Trick
由于extractMin執行完畢后,最后一個元素last已經被移動到了root,因此可以將extractMin返回的元素放置于最后,這樣可以得到sort in place的堆排序算法。
具體操作如下:
int[]n = newint[]{1,9,5,6,8,3,1,2,5,9,86};
Heaph = newHeap(n);
for(inti = 0;i < n.length;i++)
n[n.length-1-i] = h.extractMin();
當然,如果不使用前面定義的heap,則可以手動寫堆排序,由于堆排序設計到建堆和extractMin, 兩個操作都公共依賴于siftDown函數,因此我們只需要實現siftDown即可。(trick:由于建堆操作可以采用siftUp或者siftDown,而extractMin是需要siftDown操作,因此取公共部分,則采用siftDown建堆)。
這里便于和前面統一,采用小頂堆數組進行降序排列。
publicvoidheapSort(int[]nums){
intsize = nums.length;
buildMinHeap(nums);
while(size != 0){
// 交換堆頂和最后一個元素
inttmp = nums[0];
nums[0] = nums[size - 1];
nums[size - 1] = tmp;
size--;
siftDown(nums,0,size);
}
}
// 建立小頂堆
privatevoidbuildMinHeap(int[]nums){
intsize = nums.length;
for(intj = size / 2 - 1;j >= 0;j--)
siftDown(nums,j,size);
}
privatevoidsiftDown(int[]nums,inti,intnewSize){
intkey = nums[i];
while(i < newSize >>> 1){
intleftChild = (i << 1) + 1;
intrightChild = leftChild + 1;
// 最小的孩子,比最小的孩子還小
intmin = (rightChild >= newSize || nums[leftChild] < nums[rightChild])?leftChild : rightChild;
if(key <= nums[min])
break;
nums[i] = nums[min];
i = min;
}
nums[i] = key;
}
3.堆的應用:優先隊列
優先隊列是一種抽象的數據類型,它和堆的關系類似于,List和數組、鏈表的關系一樣;我們常常使用堆來實現優先隊列,因此很多時候堆和優先隊列都很相似,它們只是概念上的區分。優先隊列的應用場景十分的廣泛:常見的應用有:
Dijkstra’s algorithm(單源最短路問題中需要在鄰接表中找到某一點的最短鄰接邊,這可以將復雜度降低。)
Huffman coding(貪心算法的一個典型例子,采用優先隊列構建最優的前綴編碼樹(prefixEncodeTree))
Prim’s algorithm for minimum spanning tree
Best-first search algorithms
這里簡單介紹上述應用之一:Huffman coding。
Huffman編碼是一種變長的編碼方案,對于每一個字符,所對應的二進制位串的長度是不一致的,但是遵守如下原則:
出現頻率高的字符的二進制位串的長度小
不存在一個字符c的二進制位串s是除c外任意字符的二進制位串的前綴
遵守這樣原則的Huffman編碼屬于變長編碼,可以無損的壓縮數據,壓縮后通常可以節省20%-90%的空間,具體壓縮率依賴于數據的固有結構。
Huffman編碼的實現就是要找到滿足這兩種原則的字符-二進制位串對照關系,即找到最優前綴碼的編碼方案(前綴碼:沒有任何字符編碼后的二進制位串是其他字符編碼后位串的前綴)。這里我們需要用到二叉樹來表達最優前綴碼,該樹稱為最優前綴碼樹一棵最優前綴碼樹看起來像這樣:
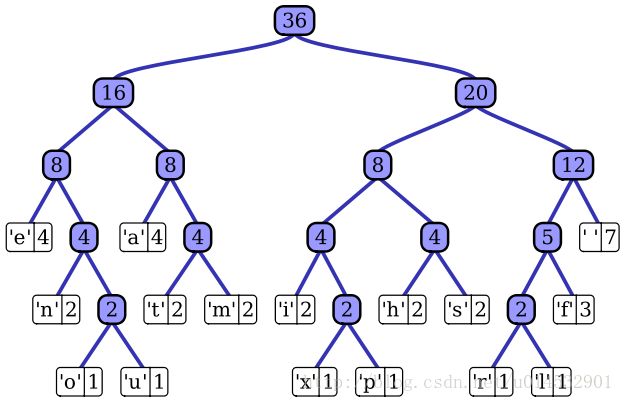
算法思想:用一個屬性為freqeunce關鍵字的最小優先隊列Q,將當前最小的兩個元素x,y合并得到一個新元素z(z.frequence = x.freqeunce + y.frequence),然后插入到優先隊列中Q中,這樣執行n-1次合并后,得到一棵最優前綴碼樹(這里不討論算法的證明)。
一個常見的構建流程如下:
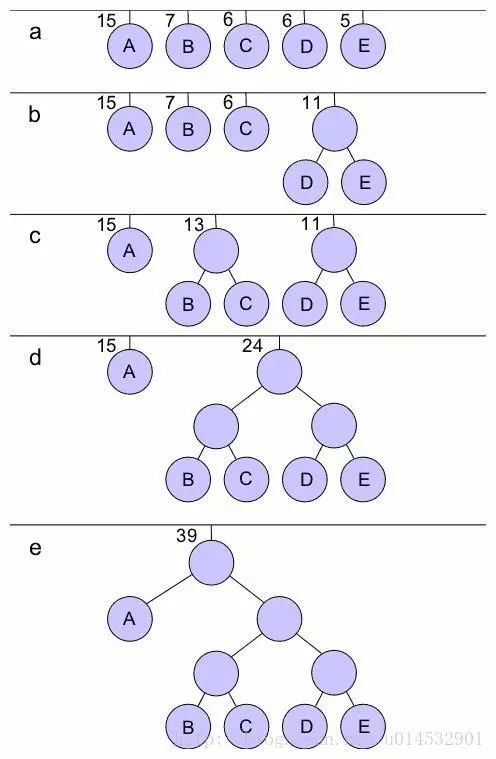
樹中指向某個節點左孩子的邊上表示位0,指向右孩子的邊上的表示位1,這樣遍歷一棵最優前綴碼樹就可以得到對照表。
import java.util.Comparator;
import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
/**
*
*root
*/
*--------- ----------
*|c:freq | | c:freq |
*--------- ----------
*
*
*/
publicclassHuffmanEncodeDemo{
publicstaticvoidmain(String[]args){
// TODO Auto-generated method stub
Node[]n = newNode[6];
float[]freq = newfloat[]{9,5,45,13,16,12};
char[]chs = newchar[]{'e','f','a','b','d','c'};
HuffmanEncodeDemo demo = newHuffmanEncodeDemo();
Node root = demo.buildPrefixEncodeTree(n,freq,chs);
Map
StringBuilder sb = newStringBuilder();
demo.tranversalPrefixEncodeTree(root,collector,sb);
System.out.println(collector);
Strings = "abcabcefefefeabcdbebfbebfbabc";
StringBuilder sb1 = newStringBuilder();
for(charc : s.toCharArray()){
sb1.append(collector.get(c));
}
System.out.println(sb1.toString());
}
publicNode buildPrefixEncodeTree(Node[]n,float[]freq,char[]chs){
PriorityQueue
publicintcompare(Node o1,Node o2){
returno1.item.freq > o2.item.freq?1 : o1.item.freq == o2.item.freq?0 : -1;
};
});
Nodee = null;
for(inti = 0;i < chs.length;i++){
n[i] = e = newNode(null,null,newItem(chs[i],freq[i]));
pQ.add(e);
}
for(inti = 0;i < n.length - 1;i++){
Nodex = pQ.poll(),y = pQ.poll();
Nodez = newNode(x,y,newItem('$',x.item.freq + y.item.freq));
pQ.add(z);
}
returnpQ.poll();
}
/**
* tranversal
* @param root
* @param collector
* @param sb
*/
publicvoidtranversalPrefixEncodeTree(Node root,Map
// leaf node
if(root.left == null && root.right == null){
collector.put(root.item.c,sb.toString());
return;
}
Node left = root.left,right = root.right;
tranversalPrefixEncodeTree(left,collector,sb.append(0));
sb.delete(sb.length() - 1,sb.length());
tranversalPrefixEncodeTree(right,collector,sb.append(1));
sb.delete(sb.length() - 1,sb.length());
}
}
classNode{
publicNode left,right;
publicItem item;
publicNode(Node left,Node right,Item item){
super();
this.left = left;
this.right = right;
this.item = item;
}
}
classItem{
publiccharc;
publicfloatfreq;
publicItem(charc,floatfreq){
super();
this.c = c;
this.freq = freq;
}
}
輸出如下:
{a=0,b=101,c=100,d=111,e=1101,f=1100}
010110001011001101110011011100110111001101010110011110111011011100101110110111001010101100
4 堆的應用:海量實數中(一億級別以上)找到TopK(一萬級別以下)的數集合。
A:通常遇到找一個集合中的TopK問題,想到的便是排序,因為常見的排序算法例如快排算是比較快了,然后再取出K個TopK數,時間復雜度為O(nlogn),當n很大的時候這個時間復雜度還是很大的;
B:另一種思路就是打擂臺的方式,每個元素與K個待選元素比較一次,時間復雜度很高:O(k*n),此方案明顯遜色于前者。
對于一億數據來說,A方案大約是26.575424*n;
C:由于我們只需要TopK,因此不需要對所有數據進行排序,可以利用堆得思想,維護一個大小為K的小頂堆,然后依次遍歷每個元素e, 若元素e大于堆頂元素root,則刪除root,將e放在堆頂,然后調整,時間復雜度為logK;若小于或等于,則考察下一個元素。這樣遍歷一遍后,最小堆里面保留的數就是我們要找的topK,整體時間復雜度為O(k+n*logk)約等于O(n*logk),大約是13.287712*n(由于k與n數量級差太多),這樣時間復雜度下降了約一半。
A、B、C三個方案中,C通常是優于B的,因為logK通常是小于k的,當K和n的數量級相差越大,這種方式越有效。
以下為具體操作:
import java.io.File;
import java.io.FileNotFoundException;
import java.io.PrintWriter;
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
import java.util.Scanner;
import java.util.Set;
import java.util.TreeSet;
publicclassTopKNumbersInMassiveNumbersDemo{
publicstaticvoidmain(String[]args){
// TODO Auto-generated method stub
int[]topK = newint[]{50001,50002,50003,50004,50005};
genData(1000 * 1000 * 1000,500,topK);
longt = System.currentTimeMillis();
findTopK(topK.length);
System.out.println(String.format("cost:%fs",(System.currentTimeMillis() - t) * 1.0 / 1000));
}
publicstaticvoidgenData(intN,intmaxRandomNumer,int[]topK){
Filef = newFile("data.txt");
intk = topK.length;
Set
for(;;){
index.add((int)(Math.random() * N));
if(index.size() == k)
break;
}
System.out.println(index);
intj = 0;
try{
PrintWriter pW = newPrintWriter(f,"UTF-8");
for(inti = 0;i < N;i++)
if(!index.contains(i))
pW.println((int)(Math.random() * maxRandomNumer));
else
pW.println(topK[j++]);
pW.flush();
}catch(FileNotFoundExceptione){
// TODO Auto-generated catch block
e.printStackTrace();
}catch(UnsupportedEncodingExceptione){
// TODO Auto-generated catch block
e.printStackTrace();
}
}
publicstaticvoidfindTopK(intk){
int[]nums = newint[k];
//read
Filef = newFile("data.txt");
try{
Scanner scanner = newScanner(f);
for(intj = 0;j < k;j++)
nums[j] = scanner.nextInt();
heapify(nums);
//core
while(scanner.hasNextInt()){
inta = scanner.nextInt();
if(a <= nums[0])
continue;
else{
nums[0] = a;
siftDown(0,k,nums);
}
}
System.out.println(Arrays.toString(nums));
}catch(FileNotFoundExceptione){
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//O(n), minimal heap
publicstaticvoidheapify(int[]nums){
intsize = nums.length;
for(intj = (size - 1) >> 1;j >= 0;j--)
siftDown(j,size,nums);
}
privatestaticvoidsiftDown(inti,intn,int[]nums){
intkey = nums[i];
for(;i < (n >>> 1);){
intchild = (i << 1) + 1;
if(child + 1 < n && nums[child] > nums[child+1])
child++;
if(key <= nums[child])
break;
nums[i] = nums[child];
i = child;
}
nums[i] = key;
}
}
ps:大致測試了一下,10億個數中找到top5需要140秒左右,應該是很快了。
5 總結
堆是基于樹的滿足一定約束的重要數據結構,存在許多變體例如二叉堆、二項式堆、斐波那契堆(很高效)等。
堆的幾個基本操作都依賴于兩個重要的函數siftUp和siftDown,堆的insert通常是在堆尾插入新元素并siftUp調整堆,而extractMin是在刪除堆頂元素,然后將最后一個元素放置堆頂并調用siftDown調整堆。
二叉堆是常用的一種堆,其是一棵二叉樹;由于二叉樹良好的性質,因此常常采用數組來存儲堆。堆得基本操作的時間復雜度如下表所示:
| heapify | insert | peek | extractMin | delete(i) |
|---|---|---|---|---|
| O(n) | O(logn) | O(1) | O(logn) | O(logn) |
二叉堆通常被用來實現堆排序算法,堆排序可以sort in place,堆排序的時間復雜度的上界是O(nlogn),是一種很優秀的排序算法。由于存在相同鍵值的兩個元素處于兩棵子樹中,而兩個元素的順序可能會在后續的堆調整中發生改變,因此堆排序不是穩定的。降序排序需要建立小頂堆,升序排序需要建立大頂堆。
堆是實現抽象數據類型優先隊列的一種方式,優先隊列有很廣泛的應用,例如Huffman編碼中使用優先隊列利用貪心算法構建最優前綴編碼樹。
堆的另一個應用就是在海量數據中找到TopK個數,思想是維護一個大小為K的二叉堆,然后不斷地比較堆頂元素,判斷是否需要執行替換對頂元素的操作,采用此方法的時間復雜度為n*logk,當k和n的數量級差距很大的時候,這種方式是很有效的方法。
6 references
[1]https://en.wikipedia.org/wiki/Heap_(data_structure))
[2]https://en.wikipedia.org/wiki/Heapsort
[3]https://en.wikipedia.org/wiki/Priority_queue
[4]https://www.cnblogs.com/swiftma/p/6006395.html
[5] Thomas H.Cormen, Charles E.Leiserson, Ronald L.Rivest, Clifford Stein.算法導論[M].北京:機械工業出版社,2015:245-249
[6] Jon Bentley.編程珠璣[M].北京:人民郵電出版社,2015:161-174
●本文編號591,以后想閱讀這篇文章直接輸入591即可
●輸入m獲取文章目錄
原文標題:堆和堆的應用:堆排序和優先隊列
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
整流堆,什么是整流堆
明確區分堆與棧,堆和棧究竟有什么區別?

JAVA的堆和棧介紹和內存機制中堆和棧的區別及變量在內存中的分配

什么是堆內存?堆內存是如何分配的?
C語言排序中堆排序的技巧

stm32 freetos堆空間和啟動文件堆空間

大功率充電堆技術

橋堆的作用是什么?橋堆整流后電壓是多少?
堆的實現思路
如何使用SystemView的堆監控功能





 工商網監
工商網監
評論