 Read系統調用在用戶空間中的處理過程
Read系統調用在用戶空間中的處理過程
Read 系統調用在用戶空間中的處理過程
Linux 系統調用(SCI,system call interface)的實現機制實際上是一個多路匯聚以及分解的過程,該匯聚點就是 0x80 中斷這個入口點(X86 系統結構)。也就是說,所有系統調用都從用戶空間中匯聚到 0x80 中斷點,同時保存具體的系統調用號。當 0x80 中斷處理程序運行時,將根據系統調用號對不同的系統調用分別處理(調用不同的內核函數處理)。系統調用的更多內容,請參見參考資料。
Read 系統調用也不例外,當調用發生時,庫函數在保存 read 系統調用號以及參數后,陷入 0x80 中斷。這時庫函數工作結束。Read 系統調用在用戶空間中的處理也就完成了。
Read 系統調用在核心空間中的處理過程
0x80 中斷處理程序接管執行后,先檢察其系統調用號,然后根據系統調用號查找系統調用表,并從系統調用表中得到處理 read 系統調用的內核函數 sys_read ,最后傳遞參數并運行 sys_read 函數。至此,內核真正開始處理 read 系統調用(sys_read 是 read 系統調用的內核入口)。
在講解 read 系統調用在核心空間中的處理部分中,首先介紹了內核處理磁盤請求的層次模型,然后再按該層次模型從上到下的順序依次介紹磁盤讀請求在各層的處理過程。
Read 系統調用在核心空間中處理的層次模型
圖1顯示了 read 系統調用在核心空間中所要經歷的層次模型。從圖中看出:對于磁盤的一次讀請求,首先經過虛擬文件系統層(vfs layer),其次是具體的文件系統層(例如 ext2),接下來是 cache 層(page cache 層)、通用塊層(generic block layer)、IO 調度層(I/O scheduler layer)、塊設備驅動層(block device driver layer),最后是物理塊設備層(block device layer)
圖1 read 系統調用在核心空間中的處理層次
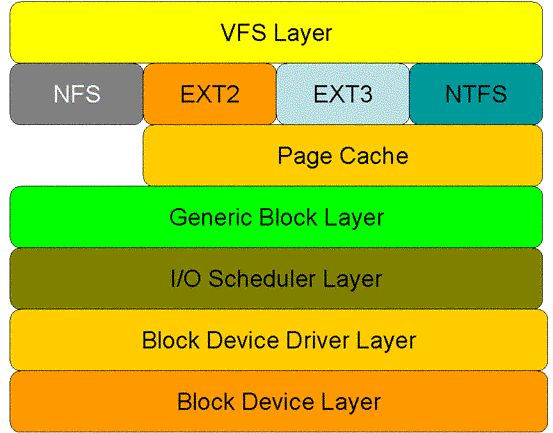
虛擬文件系統層的作用:屏蔽下層具體文件系統操作的差異,為上層的操作提供一個統一的接口。正是因為有了這個層次,所以可以把設備抽象成文件,使得操作設備就像操作文件一樣簡單。
在具體的文件系統層中,不同的文件系統(例如 ext2 和 NTFS)具體的操作過程也是不同的。每種文件系統定義了自己的操作集合。關于文件系統的更多內容,請參見參考資料。
引入 cache 層的目的是為了提高 linux 操作系統對磁盤訪問的性能。 Cache 層在內存中緩存了磁盤上的部分數據。當數據的請求到達時,如果在 cache 中存在該數據且是最新的,則直接將數據傳遞給用戶程序,免除了對底層磁盤的操作,提高了性能。
通用塊層的主要工作是:接收上層發出的磁盤請求,并最終發出 IO 請求。該層隱藏了底層硬件塊設備的特性,為塊設備提供了一個通用的抽象視圖。
IO 調度層的功能:接收通用塊層發出的 IO 請求,緩存請求并試圖合并相鄰的請求(如果這兩個請求的數據在磁盤上是相鄰的)。并根據設置好的調度算法,回調驅動層提供的請求處理函數,以處理具體的 IO 請求。
驅動層中的驅動程序對應具體的物理塊設備。它從上層中取出 IO 請求,并根據該 IO 請求中指定的信息,通過向具體塊設備的設備控制器發送命令的方式,來操縱設備傳輸數據。
設備層中都是具體的物理設備。定義了操作具體設備的規范。
相關的內核數據結構:
Dentry : 聯系了文件名和文件的 i 節點
inode : 文件 i 節點,保存文件標識、權限和內容等信息
file : 保存文件的相關信息和各種操作文件的函數指針集合
file_operations :操作文件的函數接口集合
address_space :描述文件的 page cache 結構以及相關信息,并包含有操作 page cache 的函數指針集合
address_space_operations :操作 page cache 的函數接口集合
bio : IO 請求的描述
數據結構之間的關系:
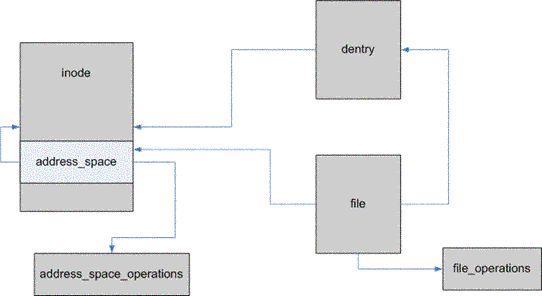
圖2示意性地展示了上述各個數據結構(除了 bio)之間的關系。可以看出:由 dentry 對象可以找到 inode 對象,從 inode 對象中可以取出 address_space 對象,再由 address_space 對象找到 address_space_operations 對象。
File 對象可以根據當前進程描述符中提供的信息取得,進而可以找到 dentry 對象、 address_space 對象和 file_operations 對象。
圖2 數據結構關系圖:
前提條件:
對于具體的一次 read 調用,內核中可能遇到的處理情況很多。這里舉例其中的一種情況:
要讀取的文件已經存在
文件經過 page cache
要讀的是普通文件
磁盤上文件系統為 ext2 文件系統,有關 ext2 文件系統的相關內容,參見參考資料
準備:
注:所有清單中代碼均來自 linux2.6.11 內核原代碼
讀數據之前,必須先打開文件。處理 open 系統調用的內核函數為 sys_open 。所以我們先來看一下該函數都作了哪些事。清單1顯示了 sys_open 的代碼(省略了部分內容,以后的程序清單同樣方式處理)
清單1 sys_open 函數代碼

代碼解釋:
get_unuesed_fd() :取回一個未被使用的文件描述符(每次都會選取最小的未被使用的文件描述符)。
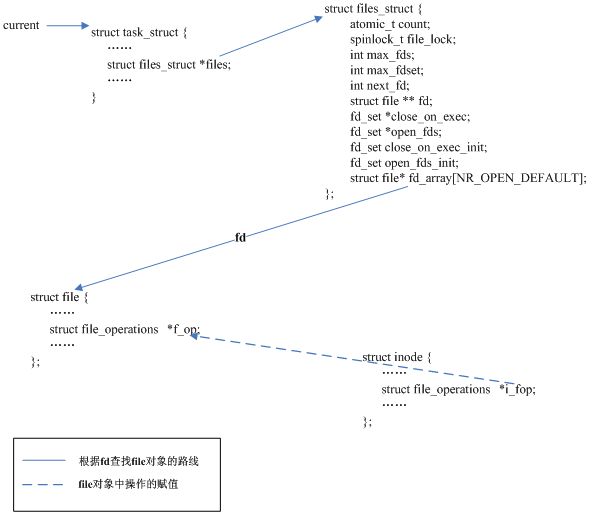
filp_open() :調用 open_namei() 函數取出和該文件相關的 dentry 和 inode (因為前提指明了文件已經存在,所以 dentry 和 inode 能夠查找到,不用創建),然后調用 dentry_open() 函數創建新的 file 對象,并用 dentry 和 inode 中的信息初始化 file 對象(文件當前的讀寫位置在 file 對象中保存)。注意到 dentry_open() 中有一條語句:
f->f_op = fops_get(inode->i_fop);
這個賦值語句把和具體文件系統相關的,操作文件的函數指針集合賦給了 file 對象的 f _op 變量(這個指針集合是保存在 inode 對象中的),在接下來的 sys_read 函數中將會調用 file->f_op 中的成員 read 。
fd_install() :以文件描述符為索引,關聯當前進程描述符和上述的 file 對象,為之后的 read 和 write 等操作作準備。
函數最后返回該文件描述符。
圖3顯示了 sys_open 函數返回后, file 對象和當前進程描述符之間的關聯關系,以及 file 對象中操作文件的函數指針集合的來源(inode 對象中的成員 i_fop)。
圖3 file 對象和當前進程描述符之間的關系
到此為止,所有的準備工作已經全部結束了,下面開始介紹 read 系統調用在圖1所示的各個層次中的處理過程。
虛擬文件系統層的處理:
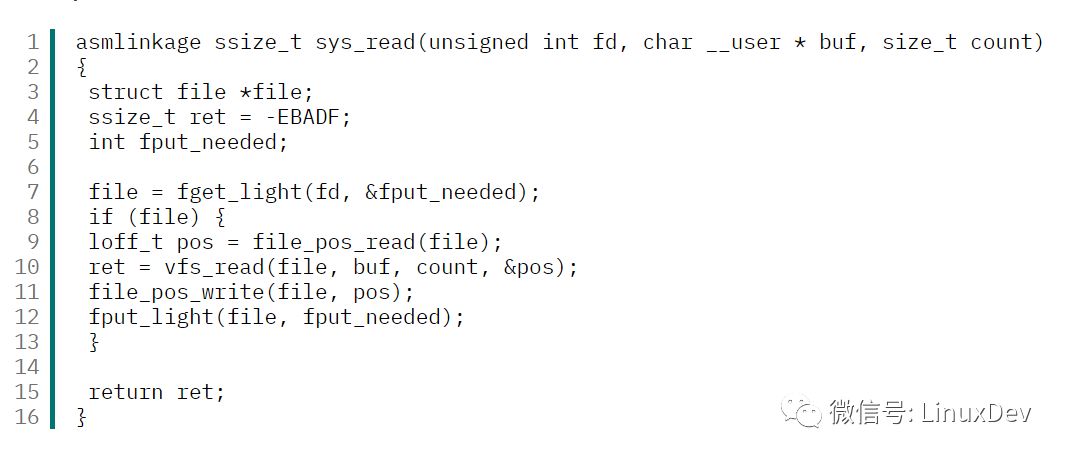
內核函數 sys_read() 是 read 系統調用在該層的入口點,清單2顯示了該函數的代碼。
清單2 sys_read 函數的代碼
代碼解析:
fget_light() :根據 fd 指定的索引,從當前進程描述符中取出相應的 file 對象(見圖3)。
如果沒找到指定的 file 對象,則返回錯誤
如果找到了指定的 file 對象:
調用 file_pos_read() 函數取出此次讀寫文件的當前位置。
調用 vfs_read() 執行文件讀取操作,而這個函數最終調用 file->f_op.read() 指向的函數,代碼如下:
if (file->f_op->read)ret = file->f_op->read(file, buf, count, pos);
調用 file_pos_write() 更新文件的當前讀寫位置。
調用 fput_light() 更新文件的引用計數。
最后返回讀取數據的字節數。
到此,虛擬文件系統層所做的處理就完成了,控制權交給了 ext2 文件系統層。
在解析 ext2 文件系統層的操作之前,先讓我們看一下 file 對象中 read 指針來源。
File 對象中 read 函數指針的來源:
從前面對 sys_open 內核函數的分析來看, file->f_op 來自于 inode->i_fop 。那么 inode->i_fop 來自于哪里呢?在初始化 inode 對象時賦予的。見清單3。
清單3 ext2_read_inode() 函數部分代碼
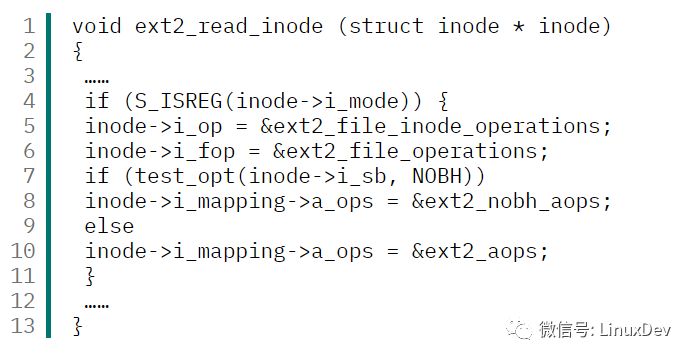
從代碼中可以看出,如果該 inode 所關聯的文件是普通文件,則將變量 ext2_file_operations 的地址賦予 inode 對象的 i_fop 成員。所以可以知道: inode->i_fop.read 函數指針所指向的函數為 ext2_file_operations 變量的成員 read 所指向的函數。下面來看一下 ext2_file_operations 變量的初始化過程,如清單4。
清單4 ext2_file_operations 的初始化

該成員 read 指向函數 generic_file_read 。所以, inode->i_fop.read 指向 generic_file_read 函數,進而 file->f_op.read 指向 generic_file_read 函數。最終得出結論: generic_file_read 函數才是 ext2 層的真實入口。
Ext2 文件系統層的處理
圖4 read 系統調用在 ext2 層中處理時函數調用關系
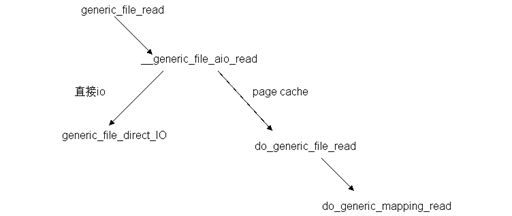
由圖 4 可知,該層入口函數 generic_file_read 調用函數 __generic_file_aio_read ,后者判斷本次讀請求的訪問方式,如果是直接 io (filp->f_flags 被設置了 O_DIRECT 標志,即不經過 cache)的方式,則調用 generic_file_direct_IO 函數;如果是 page cache 的方式,則調用 do_generic_file_read 函數。函數 do_generic_file_read 僅僅是一個包裝函數,它又調用 do_generic_mapping_read 函數。
在講解 do_generic_mapping_read 函數都作了哪些工作之前,我們再來看一下文件在內存中的緩存區域是被怎么組織起來的。
文件的 page cache 結構
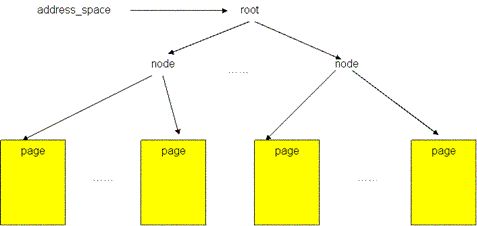
圖5顯示了一個文件的 page cache 結構。文件被分割為一個個以 page 大小為單元的數據塊,這些數據塊(頁)被組織成一個多叉樹(稱為 radix 樹)。樹中所有葉子節點為一個個頁幀結構(struct page),表示了用于緩存該文件的每一個頁。在葉子層最左端的第一個頁保存著該文件的前4096個字節(如果頁的大小為4096字節),接下來的頁保存著文件第二個4096個字節,依次類推。樹中的所有中間節點為組織節點,指示某一地址上的數據所在的頁。此樹的層次可以從0層到6層,所支持的文件大小從0字節到16 T 個字節。樹的根節點指針可以從和文件相關的 address_space 對象(該對象保存在和文件關聯的 inode 對象中)中取得(更多關于 page cache 的結構內容請參見參考資料)。
圖5 文件的 page cache 結構
現在,我們來看看函數 do_generic_mapping_read 都作了哪些工作, do_generic_mapping_read 函數代碼較長,本文簡要介紹下它的主要流程:
根據文件當前的讀寫位置,在 page cache 中找到緩存請求數據的 page
如果該頁已經最新,將請求的數據拷貝到用戶空間
否則, Lock 該頁
調用 readpage 函數向磁盤發出添頁請求(當下層完成該 IO 操作時會解鎖該頁),代碼:
| 1 |
-
Linux
+關注
關注
87文章
11345瀏覽量
210389 -
Read
+關注
關注
0文章
10瀏覽量
11129 -
數據結構
+關注
關注
3文章
573瀏覽量
40230
原文標題:read 系統調用剖析
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論