 文本數據分析:文本挖掘還是自然語言處理?
文本數據分析:文本挖掘還是自然語言處理?
數據分析師Seth Grimes曾指出“80%的商業信息來自非結構化數據,主要是文本數據”,這一表述可能夸大了文本數據在商業數據中的占比,但是文本數據的蘊含的信息價值毋庸置疑。KDnuggets的編輯、機器學習研究者和數據科學家Matthew Mayo就在網站上寫了一個有關文本數據分析的文章系列。本文是該系列的第一篇,主要講述了文本數據分析的大致步驟和框架。以下是論智對原文的編譯。
雖然NLP和文本挖掘不是一回事兒,但它們仍是緊密相關的:它們處理同樣的原始數據類型、在使用時還有很多交叉。下面我們就來描述一下這些任務的處理步驟。
如今的文本數據量非常之大,許多都是從日常生活中產生的,其中既有結構化的,也有半結構化甚至混亂的數據。我們對此能做什么?事實上,能做的有很多,這取決于你的目標是什么。
文本挖掘還是自然語言處理?
自然語言處理(NLP)關注的是人類的自然語言與計算機設備之間的相互關系。NLP是計算機語言學的重要方面之一,它同樣也屬于計算機科學和人工智能領域。而文本挖掘和NLP的存在領域類似,它關注的是識別文本數據中有趣并且重要的模式。
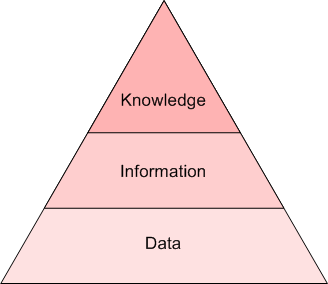
但是,這二者仍有不同。首先,這兩個概念并沒有明確的界定(就像“數據挖掘”和“數據科學”一樣),并且在不同程度上二者相互交叉,具體要看與你交談的對象是誰。我認為通過洞見級別來區分是最容易的。如果原始文本是數據,那么文本挖掘就是信息,NLP就是知識,也就是語法和語義的關系。下面的金字塔表示了這種關系:
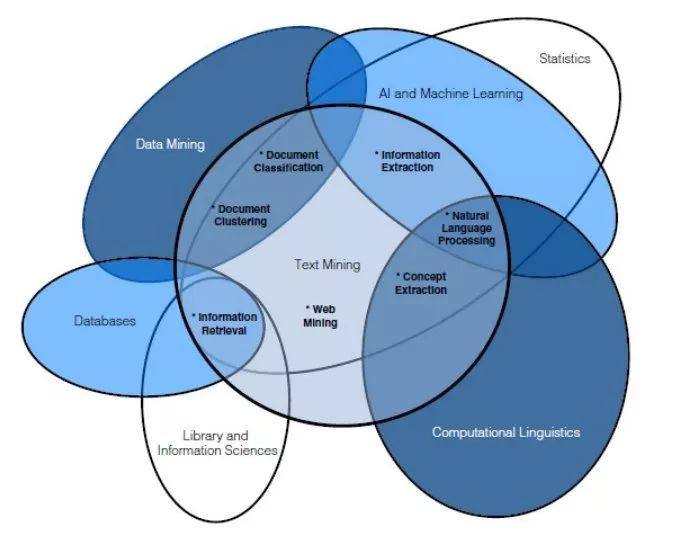
另一種區分這兩個概念的方法是用下方的韋恩圖區分,其中也涉及其他相關概念,從而能更好地表示它們之間重疊的關系。
我們的目的并不是二者絕對或相對的定義,重要的是要認識到,這兩種任務下對數據的預處理是相同的。
努力消除歧義是文本預處理很重要的一個方面,我們希望保留原本的含義,同時消除噪音。為此,我們需要了解:
關于語言的知識
關于世界的知識
結合知識來源的方法
除此之外,下圖所示的六個因素也加大了文本數據處理的難度,包括非標準的語言表述、斷句問題、習慣用語、新興詞匯、常識以及復雜的名詞等等。

文本數據科學任務框架
我們能否為文本數據的處理制作一個高效并且通用的框架呢?我們發現,處理文本和處理其他非文本的任務很相似,可以查看我之前寫的KDD Process作為參考。
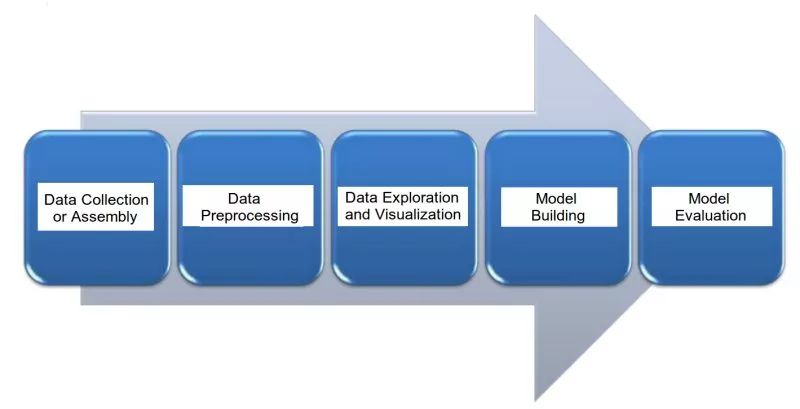
以下就是處理文本任務的幾大主要步驟:
1.數據收集
獲取或創建語料庫,來源可以是郵箱、英文維基百科文章或者公司財報,甚至是莎士比亞的作品等等任何資料。
2.數據預處理
在原始文本語料上進行預處理,為文本挖掘或NLP任務做準備
數據預處理分為好幾步,其中有些步驟可能適用于給定的任務,也可能不適用。但通常都是標記化、歸一化和替代的其中一種。
3.數據挖掘和可視化
無論我們的數據類型是什么,挖掘和可視化是探尋規律的重要步驟
常見任務可能包括可視化字數和分布,生成wordclouds并進行距離測量
4.模型搭建
這是文本挖掘和NLP任務進行的主要部分,包括訓練和測試
在適當的時候還會進行特征選擇和工程設計
語言模型:有限狀態機、馬爾可夫模型、詞義的向量空間建模
機器學習分類器:樸素貝葉斯、邏輯回歸、決策樹、支持向量機、神經網絡
序列模型:隱藏馬爾可夫模型、循環神經網絡(RNN)、長短期記憶神經網絡(LSTMs)
5.模型評估
模型是否達到預期?
度量標準將隨文本挖掘或NLP任務的類型而變化
即使不做聊天機器人或生成模型,某種形式的評估也是必要的
在下篇連載中,我將為大家帶來在文本數據任務中,對數據預處理的框架的進一步探索,敬請關注。
-
數據處理
+關注
關注
0文章
613瀏覽量
28629 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13646
原文標題:文本數據分析(一):基本框架
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
自然語言處理包括哪些內容 自然語言處理技術包括哪些
NLPIR語義分析是對自然語言處理的完美理解
自然語言處理技術可助力機器學習加快挖掘數據
自然語言處理(NLP)的學習方向
自然語言處理的圖像文本建模相關研究及分析






 工商網監
工商網監
評論