") 如何對圖像中的實(shí)體精準(zhǔn)“配對”?
如何對圖像中的實(shí)體精準(zhǔn)“配對”?
近日,李飛飛的斯坦福大學(xué)視覺實(shí)驗(yàn)室發(fā)布了一篇即將在 CVPR 2018上要介紹的論文 Referring Relationships(指稱關(guān)系),這篇論文主要研究的問題是給出一張圖像中實(shí)體的關(guān)系網(wǎng)絡(luò),從而讓 AI 迅速定位出某一主體所對應(yīng)的客體,或者某一客體所對應(yīng)的主體。

圖像不僅僅是對象集合,每個(gè)圖像都代表一個(gè)互相關(guān)聯(lián)的關(guān)系網(wǎng)絡(luò)。實(shí)體之間的關(guān)系具有語義意義,并能幫助觀察者區(qū)分實(shí)體的實(shí)例。例如,在一張足球比賽的圖像中,可能有多人在場,但每個(gè)人都參與著不同的關(guān)系:一個(gè)是踢球,另一個(gè)是守門。
在本文中,我們制定了利用這些“指稱關(guān)系”來消除同一類別實(shí)體之間的歧義的任務(wù)。我們引入了一種迭代模型,它將指稱關(guān)系中的兩個(gè)實(shí)體進(jìn)行定位,并相互制約。我們通過建模謂語來建立關(guān)系中實(shí)體之間的循環(huán)條件,這些謂語將實(shí)體連接起來,將注意力從一個(gè)實(shí)體轉(zhuǎn)移到另一個(gè)實(shí)體。
我們證明了我們的模型不僅好于在三種數(shù)據(jù)集上實(shí)現(xiàn)的現(xiàn)有方法--- CLEVR,VRD 和 Visual Genome ---而且它還可以產(chǎn)生視覺上有意義的謂語變換,可以作為可解釋神經(jīng)網(wǎng)絡(luò)的一個(gè)實(shí)例。最后,我們展示了將謂語建模為注意力轉(zhuǎn)換,我們甚至可以在沒有其類別的情況下進(jìn)行定位實(shí)體,從而使模型找到完全看不見的類別。
▌指稱關(guān)系任務(wù)
指稱表達(dá)可以幫助我們在日常交流中識(shí)別和定位實(shí)體。比如,我們能夠指出“踢球人”來區(qū)分“守門員”(圖 1)。在這些例子中,我們都可以根據(jù)他們與其它實(shí)體的關(guān)系來區(qū)分這兩人。 當(dāng)一個(gè)人射門時(shí),另一個(gè)人守門。 最終的目標(biāo)是建立計(jì)算模型,以識(shí)別其他人所指的實(shí)體。
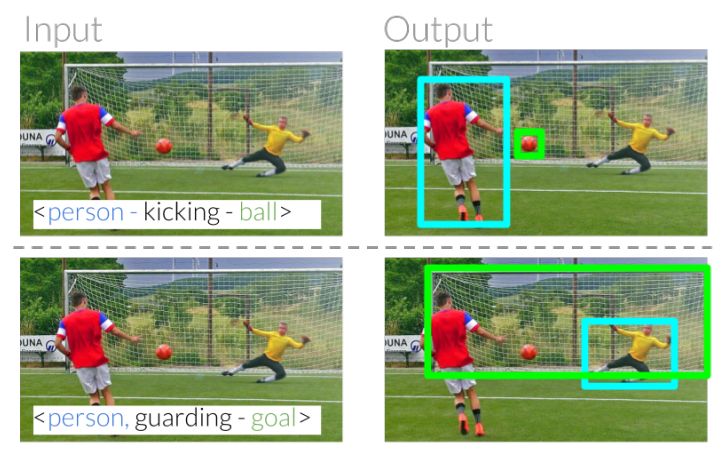
圖1:指稱關(guān)系通過使用實(shí)體間的相對關(guān)系來消除同一類別實(shí)例之間的歧義。給出這種關(guān)系之后,這項(xiàng)任務(wù)需要我們的模型通過理解謂語來正確識(shí)別圖像中的踢球人。

▌指稱關(guān)系模型
我們的目標(biāo)是通過對指稱關(guān)系的實(shí)體進(jìn)行定位,從而使用輸入的指稱關(guān)系來消除圖像中的實(shí)體歧義。 形式上而言,輸入是具有指稱關(guān)系的圖像 I,R = ,它們分別是主體,謂語和對象類別。 預(yù)計(jì)這個(gè)模型可以定位主體和客體。
▌模型設(shè)計(jì)

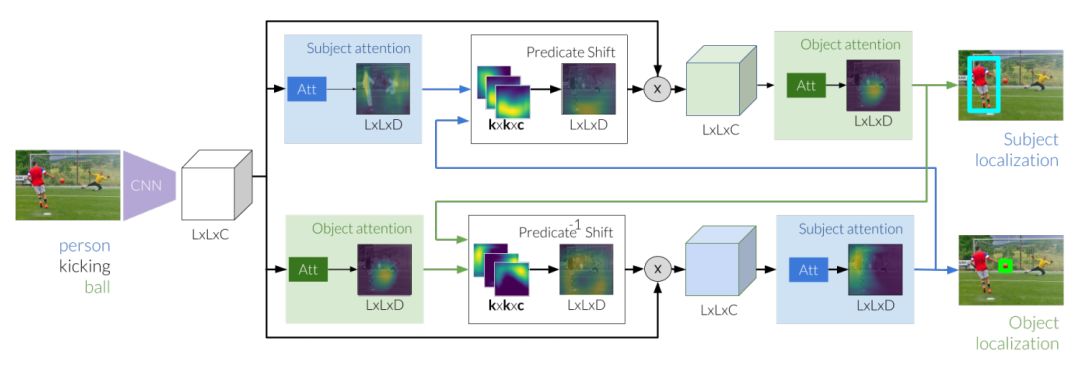
圖 2:指稱關(guān)系的推理首先要提取圖像特征,這是用于生成主體和客體的基礎(chǔ)。接下來,這些估值可以用來執(zhí)行轉(zhuǎn)換注意力,注意力使用了從主體到我們所期望客體位置的謂語。在對客體的新估值進(jìn)行細(xì)化的同時(shí),我們通過關(guān)注轉(zhuǎn)換區(qū)域來修改圖像特征。同時(shí),我們研究了從初始客體到主體的反向移位。通過兩個(gè)預(yù)測移位模塊迭代地在主體和對象之間傳遞消息,可以最終定位這兩個(gè)實(shí)體。
▌實(shí)驗(yàn)
我們在跨三個(gè)數(shù)據(jù)集的指稱關(guān)系中評估模型性能來進(jìn)行實(shí)驗(yàn)操作,其中每個(gè)數(shù)據(jù)集提供了一組獨(dú)特的特征來補(bǔ)充我們的實(shí)驗(yàn)。 接下來,我們評估在輸入指稱關(guān)系中缺少其中一個(gè)實(shí)體的情況下如何改進(jìn)模型。 最后,通過展示模型如何模塊化并用于場景圖注意力掃視來結(jié)束實(shí)驗(yàn)。
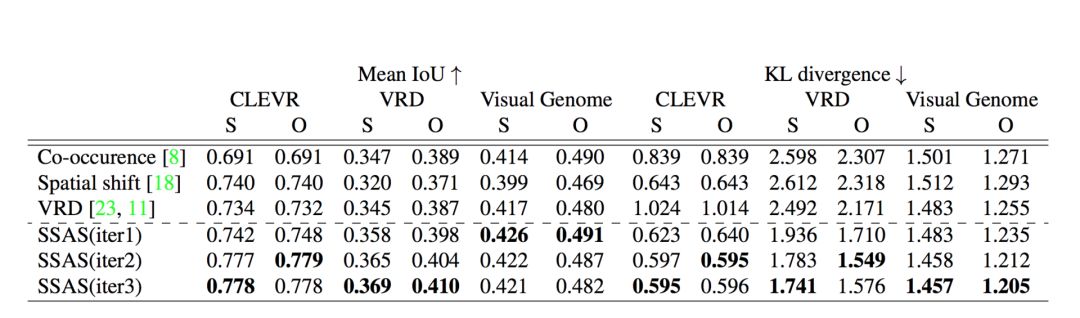
以下是我們在 CLEVR、VRD 和 Visual Genome 上的評估結(jié)果。 我們分別標(biāo)出了對主題和對象定位的 Mean IoU 和 KL 分歧:
在三種測試條件下缺少實(shí)體的指稱關(guān)系結(jié)果:
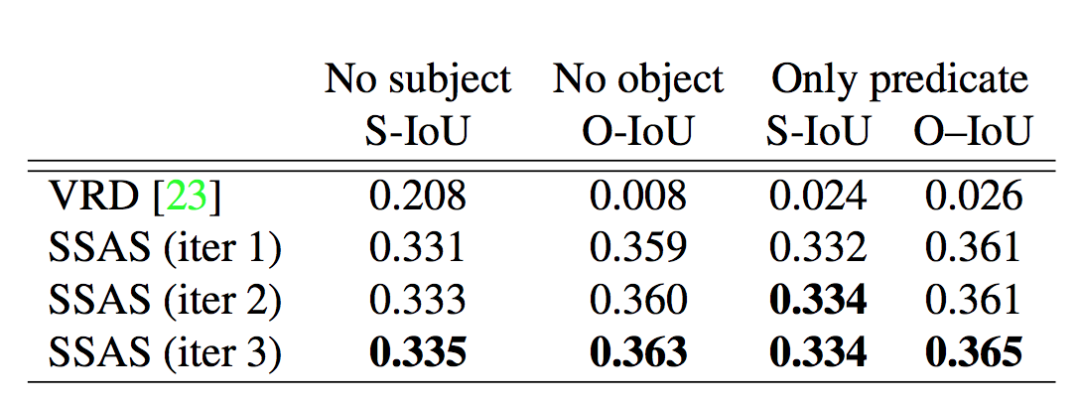
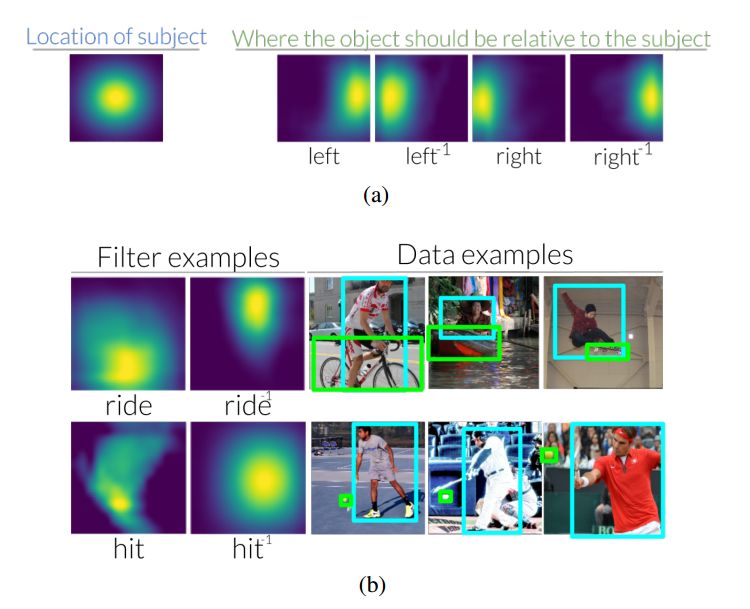
圖 3:(a)相對于圖像中的主體,當(dāng)使用關(guān)系來查找客體時(shí),左邊的謂語會(huì)把注意力轉(zhuǎn)移到右邊。相反,當(dāng)使用物體找到主體時(shí),左側(cè)的逆謂語會(huì)將注意力轉(zhuǎn)移到左側(cè)。在輔助材料中,我們可視化了 70 個(gè) VRD、6 個(gè) CLEVR 和 70 個(gè) Visual Genome 的謂語和逆謂語轉(zhuǎn)化(b)我們還看到,在查看用于了解它們的數(shù)據(jù)集時(shí),這些轉(zhuǎn)換是直觀的。

圖 4:這是 CLEVR 和 Visual Genome 數(shù)據(jù)集的注意力轉(zhuǎn)移如何跨越多次迭代的示例。在第一次迭代時(shí),模型僅接收試圖找到以及嘗試定位這些類別中所有實(shí)例的實(shí)體信息。在后面的迭代中,我們看到謂語轉(zhuǎn)換注意力,這可以讓我們的模型消除相同類別的不同實(shí)例之間的歧義。

圖 5:我們可以將我們的模型分解成其注意力和轉(zhuǎn)換模塊,并將它們堆疊起來作為場景圖的節(jié)點(diǎn)。 在這里,我們演示了如何使用模型從一個(gè)節(jié)點(diǎn)(手機(jī))開始,并使用指稱關(guān)系來通過場景圖連接節(jié)點(diǎn),并在短語<拿電話的人旁邊有人身穿夾克>中定位實(shí)體。 第二個(gè)例子是關(guān)于<在戴帽子的人的右邊有個(gè)人一張桌子前>中的實(shí)體。
▌結(jié)論

-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4781瀏覽量
101175 -
圖像
+關(guān)注
關(guān)注
2文章
1089瀏覽量
40573
原文標(biāo)題:李飛飛團(tuán)隊(duì)最新論文:如何對圖像中的實(shí)體精準(zhǔn)“配對”?
文章出處:【微信號(hào):WW_CGQJS,微信公眾號(hào):傳感器技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
藍(lán)牙配對之——密鑰生成方法
JPA實(shí)體類中的注解介紹
實(shí)體按鍵操作STemWin控件
VHDL程序實(shí)體
API修改配對請求功能?
HanLP分詞命名實(shí)體提取詳解
如何手動(dòng)進(jìn)入配對模式?
如何保證音箱中晶體管配對的準(zhǔn)確度
藍(lán)牙配對之——配對特性交換
全域圖像搜索給你更精準(zhǔn)的搜索體驗(yàn)

什么是低功耗藍(lán)牙配對?什么又是綁定?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論