 阿里苦心研發Ali-NPU,AI芯片哪種跟具優勢
阿里苦心研發Ali-NPU,AI芯片哪種跟具優勢
4月19日,有消息稱,阿里巴巴達摩院正在研發一款神經網絡芯片——Ali-NPU,主要運用于圖像視頻分析、機器學習等AI推理計算。按照設計,這款芯片性能將是目前市面上主流CPU、GPU架構AI芯片的10倍,而制造成本和功耗僅為一半,其性價比超過40倍。
事實上,隨著人工智能產業的發展,CPU、GPU、TPU、DPU、NPU、BPU……各種PU也開始爆發式出現。那么,究竟這些PU在性能和使用上有何異同,又有哪些優劣呢?
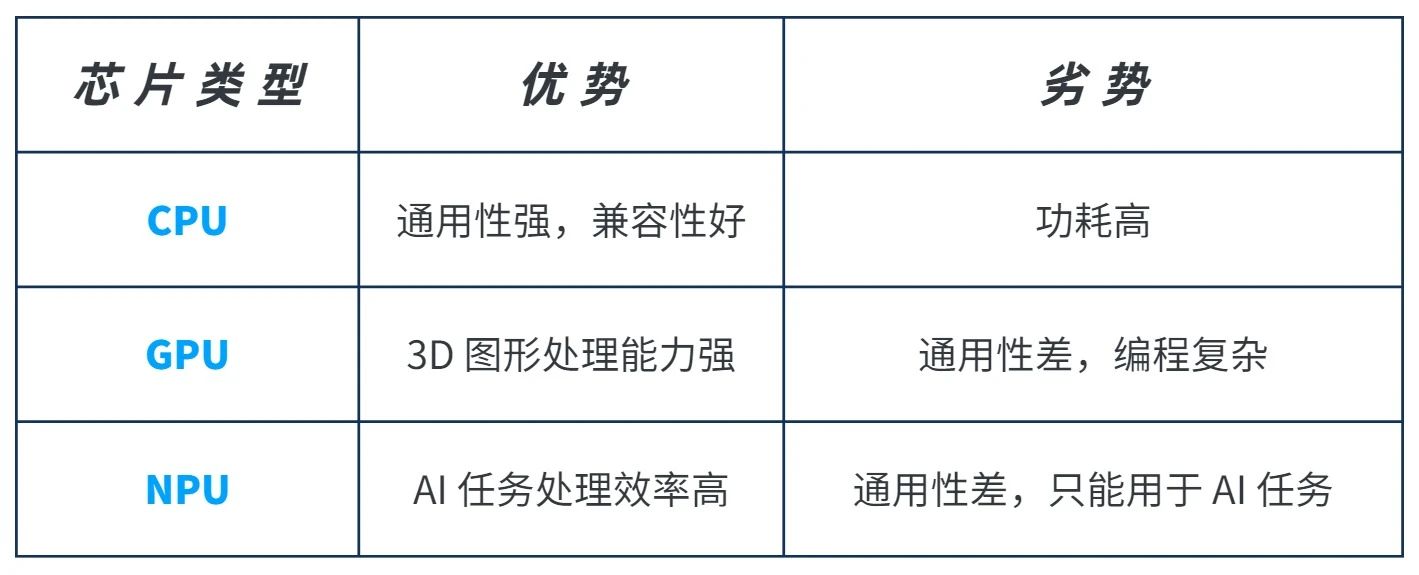
CPU:計算力占據部分很小 擅長邏輯控制
CPU是最為普遍,最為常見的中央處理器。主要包括運算器(ALU)和控制單元(CU),除此之外還包括若干寄存器、高速緩存器和它們之間通訊的數據、控制及狀態的總線。依循馮諾依曼架構,CPU需要大量空間放置存儲單元和控制邏輯,計算能力只占據很小的部分,更擅長邏輯控制。
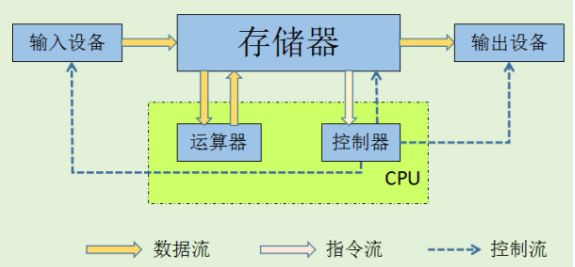
CPU結構簡化圖
GPU:計算單元數量眾多 但無法單獨使用
GPU的誕生可以解決CPU在計算能力上的天然缺陷。采用數量眾多的計算單元和超長的流水線,善于處理圖像領域的運算加速。但GPU的缺陷也很明顯,即無法單獨工作,必須由CPU進行控制調用才能工作。
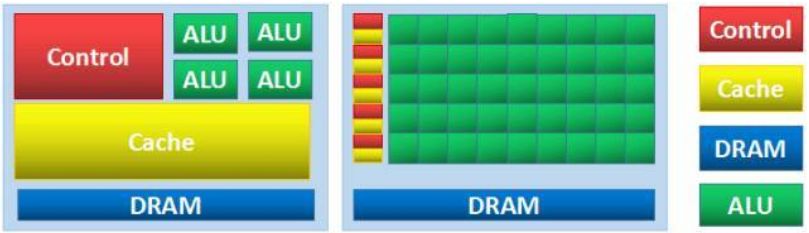
CPU、GPU微架構對比圖
TPU:高性能低功耗 然則開發周期長、轉換成本高
谷歌專門為 TensorFlow 深度學習框架定制的TPU,是一款專用于機器學習的芯片。TPU可以提供高吞吐量的低精度計算,用于模型的前向運算而不是模型訓練,且能效更高。但它的缺陷主要是開發周期長、可配置性能有限,缺乏靈活性且轉換成本高。
DPU:可實現快速開發與產品迭代
國際上,Wave Computing最早提出DPU。在國內,DPU最早是由深鑒科技提出,是基于Xilinx可重構特性的FPGA芯片,設計專用深度學習處理單元,且可以抽象出定制化的指令集和編譯器,從而實現快速的開發與產品迭代。
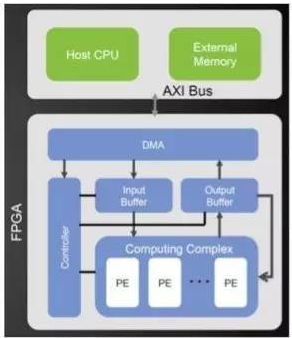
深鑒“雨燕”DPU平臺
NPU:運行效率提升 不支持大樣本訓練
NPU是神經網絡處理器,在電路層模擬人類神經元和突觸,并且用深度學習指令集直接處理大規模的神經元和突觸,一條指令完成一組神經元的處理。相比于CPU和GPU的馮諾伊曼結構,NPU通過突觸權重實現存儲和計算一體化,從而提高運行效率。但NPU也有自身的缺陷,比如不支持對大量樣本的訓練。
BPU:比在CPU上用軟件實現更為高效 不可再編程
BPU是由地平線主導的嵌入式處理器架構。第一代是高斯架構,第二代是伯努利架構,第三代是貝葉斯架構。BPU主要是用來支撐深度神經網絡,比在CPU上用軟件實現更為高效。然而,BPU一旦生產,不可再編程,且必須在CPU控制下使用。
從CPU、GPU的市場來看,已經基本被英特爾、英偉達和AMD三分天下。而在ASIC框架下的TPU,只有谷歌的體量和實力才有開發專用加速的動力。
推出DPU的深鑒科技有清華和斯坦福雙重學術背景,公司目前的兩條發展路線是:以芯片技術為主的純技術路線,以及基于技術的產品路線。其處理器做深度學習應用端,不做訓練端。目前,其深度壓縮技術可以將神經網絡壓縮數十倍而不影響精度,還可以使用芯片存儲深度學習算法模型,減少內存讀取次數,降低運行功耗。
去年底,地平線在創辦兩年后終于發布首款芯片——“征程”與“旭日”。目前,這兩款處理器都屬于嵌入式人工智能視覺芯片,分別面向智能駕駛和智能攝像頭。2018年CES上,英特爾和地平線還發布了基于伯努利架構的新一代征程處理器,其發展路徑圖為:2018年,感知;2019年,建模;2020年,決策。
而因為與英特爾的合作,地平線不禁讓市場聯想到英特爾早前重金收購的Mobileye。在嵌入式人工智能領域,Mobileye是業界領頭羊。地平線在英特爾的定位版圖是否是中國版Mobileye?但其創始人余凱的抱負是,地平線是要做中國的英特爾。
相較而言,阿里在三家中最為熱衷芯片布局,上述包括寒武紀、深鑒科技均有阿里參投。
-
阿里巴巴
+關注
關注
7文章
1619瀏覽量
47520 -
NPU
+關注
關注
2文章
292瀏覽量
18783
原文標題:“芯痛”之下阿里苦心研發NPU AI芯片究竟哪款PU更厲害?
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
恒玄科技研發AI眼鏡專用芯片
NPU在邊緣計算中的優勢
NPU技術如何提升AI性能
什么是NPU芯片及其功能
小鵬汽車2024 AI科技日:圖靈AI芯片進展公布,預計AI汽車市場將迎來巨變
什么是NPU?什么場景需要配置NPU?
NXP推出集成NPU的MCU,支持AI邊緣設備!MCU實現AI功能的多種方式
阿里Ali266解碼器助力高通AI PC首播H.266超高清
AI芯片的混合精度計算與靈活可擴展
刷新AI PC NPU算力,AMD銳龍AI 9 HX 375領銜55 TOPS





 工商網監
工商網監
評論