") IBM開發(fā)“混合精度內(nèi)存計算”,能耗降低了80倍
IBM開發(fā)“混合精度內(nèi)存計算”,能耗降低了80倍
IBM Research 稱,已經(jīng)開發(fā)出了一種內(nèi)存計算新方法,可以為微軟和谷歌尋求的高性能和機器學習應用的硬件加速器提供答案。
在近日 Nature Electronics 期刊上發(fā)表的一篇論文中,IBM 研究人員描述了這種新的 “混合精度內(nèi)存計算” 方法。
IBM 關注傳統(tǒng)計算體系結構的不同看法,在這種體系結構中,軟件需要在單獨的 CPU 和 RAM 單元之間進行數(shù)據(jù)傳輸。
據(jù) IBM 稱,這種被稱為 “馮·諾依曼” 的體系結構設計,為數(shù)據(jù)分析和機器學習應用制造了一個瓶頸,這些應用需要在處理單元和內(nèi)存單元之間進行更大的數(shù)據(jù)傳輸。傳輸數(shù)據(jù)也是一個耗能的過程。
應對這一挑戰(zhàn),IBM 給出的一種方法是模擬相變內(nèi)存(PCM)芯片,該芯片目前還處于原型階段,500 萬個納米級 PCM 器件組成 500×2000 交叉陣列。
PCM 的一個關鍵優(yōu)勢是可以處理大多數(shù)密集型數(shù)據(jù)處理,而無需將數(shù)據(jù)傳輸?shù)?CPU 或 GPU,這樣以更低的能量開銷實現(xiàn)更快速的處理。
IBM 的 PCM 單元將作為 CPU 加速器,就像微軟用于加速 Bing 和加強機器學習的 FPGA 芯片一樣。
據(jù) IBM 稱,研究表明在某些情況下,其 PCM 芯片能夠以模擬的方式進行操作,執(zhí)行計算任務,并提供與 4 位 FPGA 存儲器芯片相當?shù)臏蚀_度,但能耗降低了 80 倍。
模擬 PCM 硬件并不適合高精度計算。所幸的是,數(shù)字型 CPU 和 GPU 是適合的,IBM 認為混合架構可以實現(xiàn)更高性能、更高效率和更高精度的平衡。
這種設計將大部分處理留給內(nèi)存,然后將較輕的負載交給 CPU 進行一系列的精度修正。
根據(jù) IBM 蘇黎世實驗室的電氣工程師、也是該論文的主要作者 Manuel Le Gallo 稱,這種設計有助于云中的認知計算,有助于釋放對高性能計算機的訪問。
Le Gallo 表示:“憑借我們現(xiàn)在的精確度,我們可以將能耗降低到是使用高精度 GPU 和 CPU 的 1/6。”
“所以我們的想法是,為了應對模擬計算中的不精確性,我們將其與標準處理器結合起來。我們要做的是將大量計算任務轉移到 PCM 中,但同時得到最終的結果是精確的。”
這種技術更適合于如數(shù)字圖像識別等應用,其中誤解少數(shù)像素并不會妨礙整體識別,此外還有一些醫(yī)療應用。
“你可以用低精度完成大量計算——以模擬的方式,PCM 會非常節(jié)能——然后使用傳統(tǒng)處理器來提高精度。”
對于只有 1 兆字節(jié)大小的 IBM 原型內(nèi)存芯片,現(xiàn)在還處于初期階段。為了適用于現(xiàn)代數(shù)據(jù)中心的規(guī)模化應用,它需要達到千兆字節(jié)的內(nèi)存量級,分布在數(shù)萬億個 PCM 中。
盡管如此,IBM 認為可以通過構建更大規(guī)模的 PCM 設備或使其中 PCM 并行運行來實現(xiàn)這一目標。
-
IBM
+關注
關注
3文章
1766瀏覽量
74863 -
cpu
+關注
關注
68文章
10905瀏覽量
213030 -
gpu
+關注
關注
28文章
4777瀏覽量
129360
原文標題:IBM 取得內(nèi)存計算新突破,AI 訓練能耗降低 80 倍
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
ADS1248一旦配置Burnout Current,檢測到的值精度降低了很多,為什么?
為什么隔離ADC的采樣頻率可以如此顯著的提高?但是帶寬反而降低了?
虛擬內(nèi)存和云計算的關系
虛擬內(nèi)存對計算機性能的影響
AMD Alveo V80計算加速器網(wǎng)絡研討會
是什么原因降低了INA116的輸入阻抗?
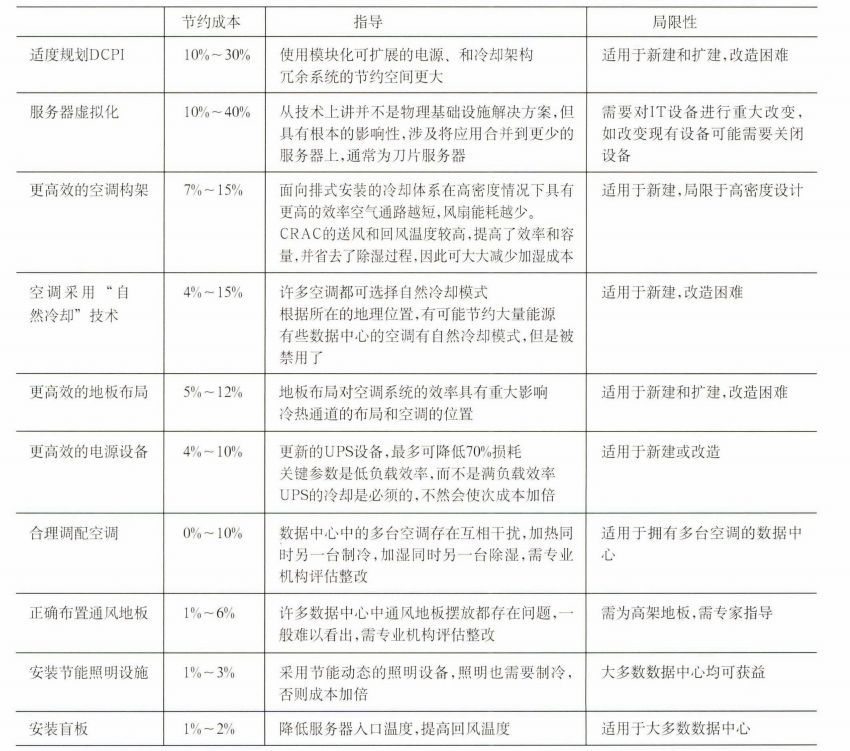
淺析如何降低數(shù)據(jù)中心電力能耗
IBM與日本AIST攜手,共創(chuàng)量子計算新紀元
淺析物聯(lián)網(wǎng)環(huán)境下小麥加工過程能耗監(jiān)測系統(tǒng)設計
高性能計算集群的能耗優(yōu)化

借助全新 AMD Alveo? V80 計算加速卡釋放計算能力







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論