") 美國重奪超算霸主,GPU提供56%的總算力
美國重奪超算霸主,GPU提供56%的總算力
在近日舉行的ISC會議上,最新Top500榜單公布了。這次,榜單頂部的排名變化較大,美國Summit超級計算機摘得桂冠,中國的神威·太湖之光排名第二。這是自2012年11月以來,美國第一次宣布全球最強大超級計算機,重奪超算霸主地位。但在進入榜單的系統數量方面,中國仍然遠超美國。
TOP500是針對全球已知最強大的計算機系統做出排名與詳細介紹的項目。此項目始于1993年,今年已經是第25年。TOP500每年公布兩次最新的超級計算機排名,一次是在6月份的國際超級計算機大會(ISC),第二次則是在11月份的全球超級計算大會(SC)。
近日舉行的ISC會議上,最新一期Top500榜單公布了。這次,榜單頂部的排名變化較大,美國Summit超級計算機摘得桂冠,兩個新系統進入前5。這是自2012年11月以來,美國第一次宣布全球最強大超級計算機,重奪超算霸主地位。
Summit超級計算機。來源:橡樹嶺國家實驗室
由IBM總包設計建設,目前在美國能源部(DOE)的橡樹嶺國家實驗室(ORNL)運行的Summit超級計算機,在作為TOP500榜單基準的高性能Linpack(HPL)基準測試中以122.3 petaflops(每秒12.23億億次)的性能問鼎榜首。Summit超算有4356個節(jié)點,每個節(jié)點配備2顆22核的Power9 CPU和6顆NVIDIA Tesla V100 GPU。節(jié)點與Mellanox雙軌EDR InfiniBand網絡連接在一起。
Summit的Linpack測試的理論峰值性能是187.7 petaflops。在Linpack測試中,Summit超算提供122.3 petaflops的性能,計算效率達到65.2% ——這對新機器來說并不差,而且顯然會隨著時間的推移而改善。
排名第二的是中國的神威·太湖之光,由國家并行計算機工程技術研究中心(NRCPC)開發(fā),安裝在國家超級計算無錫中心。該系統在過去兩年里一直名列榜首,自2016年6月上線以來,它的HPL成績一直保持不變,為93 petaflops。神威·太湖之光在Linpack性能測試中的計算效率達到74.2%,達到93 petaflops的性能的功耗為15.37百萬瓦(megawatts),而Summit系統達到122.3 petaflops性能的功耗僅8.81百萬瓦。
美國能源部勞倫斯利弗莫爾國家實驗室的新系統Sierra排名第三,它的HPL性能是71.6 petaflops。同樣由IBM打造的Sierra超算的架構與Summit非常相似,有4320個節(jié)點,每個節(jié)點均由兩顆Power9 CPU和四顆NVIDIA Tesla V100 GPU驅動,并使用相同的Mellanox EDR InfiniBand作為系統互連。
天河二號盡管經過了一次重大升級,用定制的Matrix-2000協處理器取代了5年前的Xeon Phi加速器,但它還是下降了兩名,由6個月前的第二名變成第四名。天河二號的新硬件將其HPL性能從33.9 petaflops提高到61.4 petaflops,同時將功耗略微提高了約4%。天河二號由中國國防科技大學(NUDT)開發(fā),部署在國家超級計算廣州中心。
AI Bridging Cloud Infrastructure (ABCI)是排名第五的系統,由日本富士通公司制造,它的HPL性能達到19.9 petaflops。ABCI由20核的Xeon Gold處理器和NVIDIA Tesla V100 GPU驅動,安裝在日本國家先進工業(yè)科學技術研究所(AIST)。
瑞士的Piz Daint (19.6 petaflops)、美國的Titan (17.6 petaflops)、美國的Sequoia (17.2 petaflops)、美國的Trinity (14.1 petaflops),和美國的 Cori (14.0 petaflops) 分別排第6位至第10位。
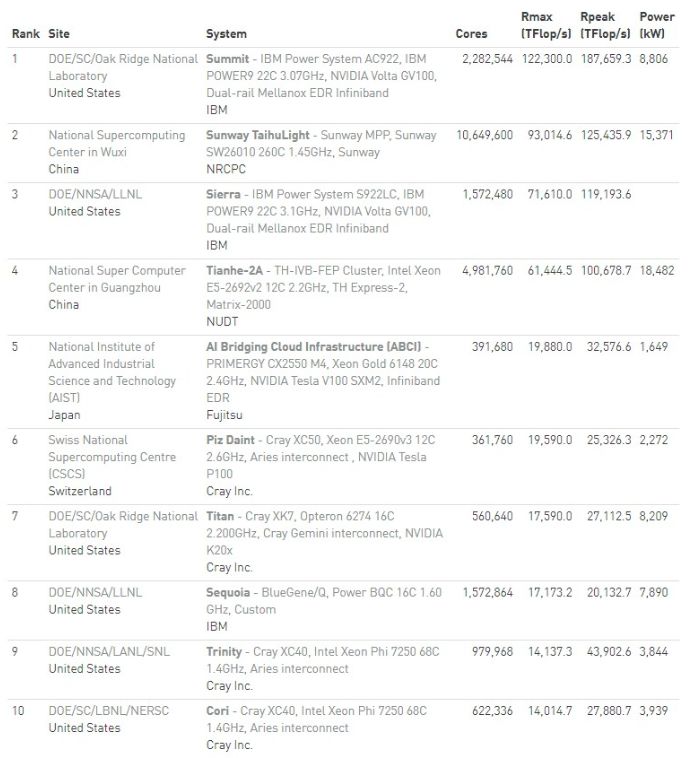
TOP500的前10名
TOP500榜單中國超算數量超過美國
接下來我們看看TOP500的一些關鍵概況。
盡管美國在榜單上的排名靠前,但目前美國在榜單上的系統只有124套,創(chuàng)歷史新低。就在6個月前,美國在榜單上的系統還有145套。與此同時,中國進入榜單的系統達到206套,占比41%,6個月前是202套。接著是日本,有36套系統,英國22套,德國21套,法國18套。這些數字與上次的榜單基本相同。
國家超算數量年度變化
不過,主要歸功于Summit和Sierra,美國在性能方面從中國手中奪回了領先地位。目前,美國的系統占TOP500系統性能總和的38.2%,中國排在第二位,占29.1%。
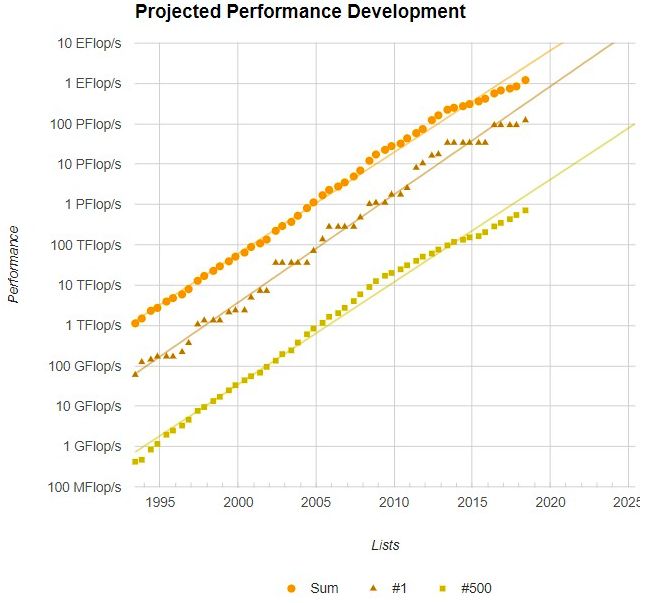
今年是第一次TOP500榜單的所有500套系統的總性能超過百億億次級別(exaflop),確切地說,已經達到1.22 exaflops。這比去年11月時的 845 petaflops 要高。其中,有273套系統的HPL性能超過1 petaflops,而上次的榜單超過只有181套系統性能超過1 petaflops。
CPU架構Intel Xeon占主導地位,56%的計算來自GPU
就處理器架構而言,Intel Xeon在CPU架構方面占據主導地位。
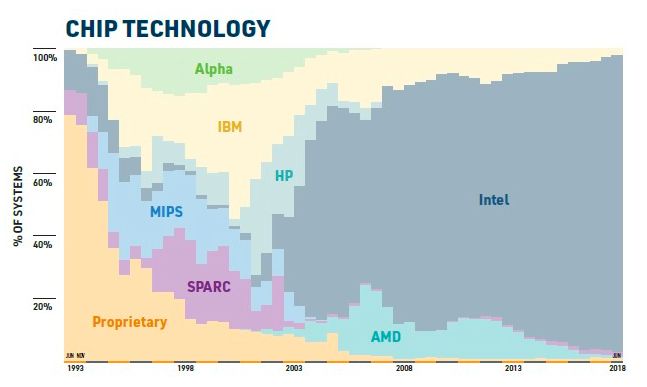
未來幾年,IBM和AMD可能會分別憑借Power和Epyc處理器迎來復興,而Arm服務器芯片也將從中分得一杯羹。但即便如此,Intel Xeon仍將繼續(xù)在CPU方面占據主導地位。
在加速器方面,TOP500系統中有110個使用加速器,相比2017年11月時的101個加速系統略有增加。TOP500超算的總體性能有一半來自某種形式的加速系統。這些使用加速器的系統中有96個使用NVIDIA GPU,其中前10名就有5個:Summit,Sierra,ABCI,Piz Daint和Titan。此外,使用加速器的系統中有7個配備了Xeon Phi協處理器,而PEZY加速器被用在4個系統中。另外20個系統使用Xeon Phi作為主處理器。
TOP500的幾乎所有超級計算機(97.8%)都由擁有8個或更多內核的主處理器驅動,超過一半(53.2%)的主處理器有超過16個內核。
10G或更快的以太網在247個系統中被使用,比6個月前榜單的228個多。此外,139個系統使用InfiniBand,比上次榜單的163個少。有38個系統使用英特爾的Omni-Path技術,上次的榜單是35個。
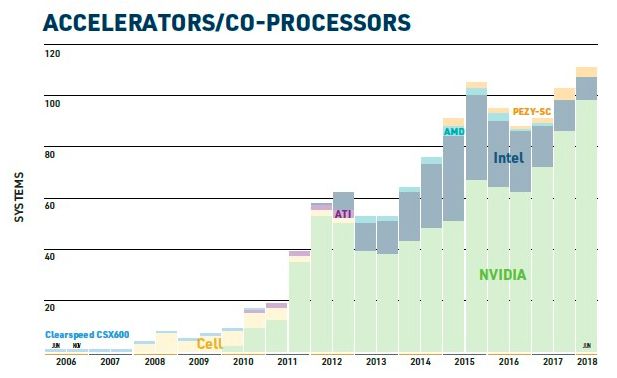
TOP500榜單中,56%的計算來自GPU。越來越多的廠商開始談論“人工智能超級計算機”(AI supercomputers),因為可以加速傳統HPC工作負載的CPU-GPU混合架構也可以用于機器學習訓練。
自1993年以來,TOP500的總性能、排名第一以及排名500的超算性能變化如下圖所示:
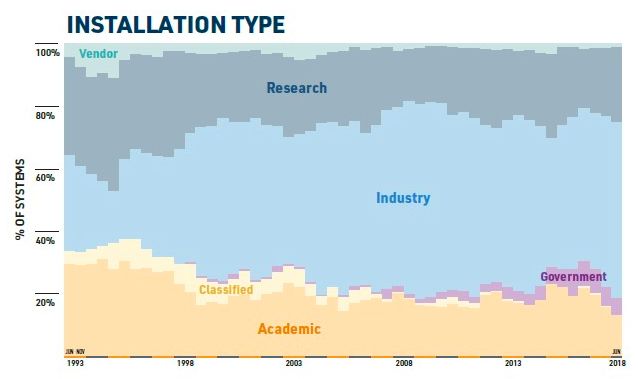
另一個變化是,榜單中學術、機密和研究類型的超算有所減少,而用于工業(yè)的超算比例增加了:
以下是按系統份額的廠商排名,聯系有122套系統上榜,占23.8%,其次是HPE,15.8%(79套系統),浪潮,13.6%(68套系統),Cray, 11.2%(56套系統),曙光, 11%(55套系統)。
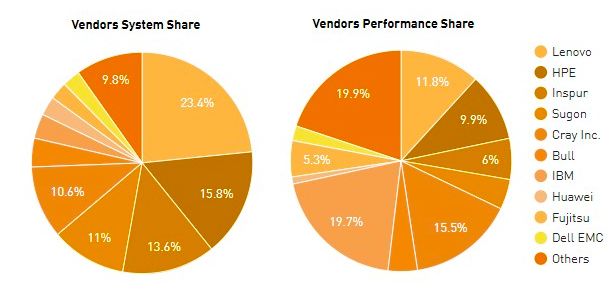
盡管IBM擁有前三名超級計算機中的兩款:Summit和Sierra,但它在整個榜單中只有19套系統。然而,由于這兩臺機器,IBM貢獻了TOP500總性能的19.9%。接著是Cray,性能份額為16.5%,聯想為12.0%,HPE為9.9%。
Green500榜單
最后,我們看一下Green500的榜單。Green500中排名前三的超算都來自日本,它們基于ZettaScaler-2.2架構,使用PEZY-SC2加速器。而前10名中的其他系統都使用NVIDIA GPU。
最高能效的超級計算機仍然日本理研的Shoubu(菖蒲) system B,能效為18.4 gigaflops/watt,在TOP500榜單中排名第362位。
能效排名第二的是位於日本高能加速器研究組織/KEK的Suiren2系統,達到16.8 gigaflops/watt,在TOP500榜單中排名第388位。
Green500的第三名是美國的DGX SaturnV Volta系統,接著是Summit(美國),TSUBAME 3.0(日本),AIST AI Cloud(日本),AI Bridging Cloud Infrastructure(日本),new IBM MareNostrum P9 cluster(西班牙),DOE’s Summit system(美國),以及Wilkes-2(英國)。
作為不依賴任何加速器的最高能效的超級計算機,神威·太湖之光在Green500榜單上排第22位。
-
gpu
+關注
關注
28文章
4774瀏覽量
129355 -
超級計算機
+關注
關注
2文章
464瀏覽量
42030
原文標題:【GPU稱霸超算TOP500最新榜單】美國重奪全球超算霸主,總算力56%來自GPU
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦

算智算中心的算力如何衡量?

超算智算融合 南京信易達發(fā)布全新“智能算力融合平臺”

未來邊緣GPU算力在車聯網中的創(chuàng)新應用(下)
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
GPU算力開發(fā)平臺是什么
【一文看懂】大白話解釋“GPU與GPU算力”
未來邊緣GPU算力在車聯網中的創(chuàng)新應用
GPU算力租用平臺怎么樣
GPU算力租用平臺是什么
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
算力服務器為什么選擇GPU
壁仞科技為中國移動呼和浩特智算中心提供強大算力
“捷智算”正式入駐國家超算互聯網平臺






 工商網監(jiān)
工商網監(jiān)
評論