 測量神經網絡的抽象推理能力
測量神經網絡的抽象推理能力
聚焦 ICML—— Deep Mind 今天在 ICML 大會上發表了他們的最新研究,從人類的 IQ 測試里用來衡量抽象推理的方法中獲得靈感,探索深層神經網絡的抽象推理和概括的能力。一開始看到文章的前半部分的 IQ 測試題數據集,我在凌晨十二點花了一些時間把幾個測試題做完了,但是并不是以預期中的飛速完成,然后回想體會了一下我“是如何理解題目,進而做出這些題目得到結果的”。我就很好奇這將會是如何開展的一個研究;隨著歲月的流逝,我們會不斷地遺忘知識,漸漸地還給老師了,但是我們學習新知識的能力,推理思維力也不如以前, 那這個研究的成果又會是如何呢?今天人工智能頭條也為大家介紹一下 Deep Mind 的這項最新研究:測量神經網絡的抽象推理能力。看到最后覺得需要練練的怕是我吧~~
神經網絡是否可以學習抽象推理,還是僅僅淺顯地學習統計數據學習,是最近學術界辯論的主題。在本文中,受到一個著名 IQ 測試的靈感啟發,我們提出一個抽象推理挑戰及其相應的數據集。為了成功應對這一挑戰,模型必須應對訓練和測試階段不同數據方法情況下的各種泛化情況,我們展示了即使是在訓練集和測試集的差別很小的情況下,像 ResNet 這樣的模型也難以取得很好的泛化表現。
為了解決這個問題,我們設計了一種用于抽象推理的新穎結構,當訓練數據和測試數據不同時,我們發現該模型能夠精通某些特定形式的泛化,但在其他方面能力較弱。進一步地,當訓練時模型能夠對答案進行解釋性的預測,那么我們模型的泛化能力將會得到明顯的改善。總的來說,我們介紹并探索兩種方法用于測量和促使神經網絡擁有更強的抽象推理能力,而我們公開的抽象推理數據集也將促進在該領域進一步的研究進展。
在機器學習問題上,基于神經網絡的模型已經取得了長足而又令人印象深刻的成果,但同時其對抽象概念的推理能力的研究也是一大難題。先前的研究主要集中于解決通用學習系統的重要特征,而我們的最新論文提出了一種在學習機器的過程中測量抽象推理的方法,并揭示了關于泛化本質問題的一些重要見解。
要理解為什么抽象推理對于通用人工智能如此得重要,首先了解阿基米德提出的 “famous Eureka” :即物體的體積等于所取代的水體積,他從概念層面理解體積,因此能夠推斷出其他不規則形狀物體的體積。
我們希望AI 也擁有這樣類似的能力。盡管當前的人工智能系統可以在復雜的戰略游戲中擊敗人類的世界冠軍,但它們經常掙扎于其他一些看似簡單的任務,特別是在新環境中需要發現并重復應用抽象概念。例如,如果專門訓練我們系統只學習計算三角形,那么即便是當前最好的AI 系統也無法計算方形或其他先前未見過的對象。
因此,要構建更好、更智能的系統,了解當前神經網絡處理抽象概念的方式并尋求改進的地方是非常重要的。為了實現這一目標,我們從人類智商測試中汲取用于測量抽象推理的靈感。
▌創建抽象推理數據庫

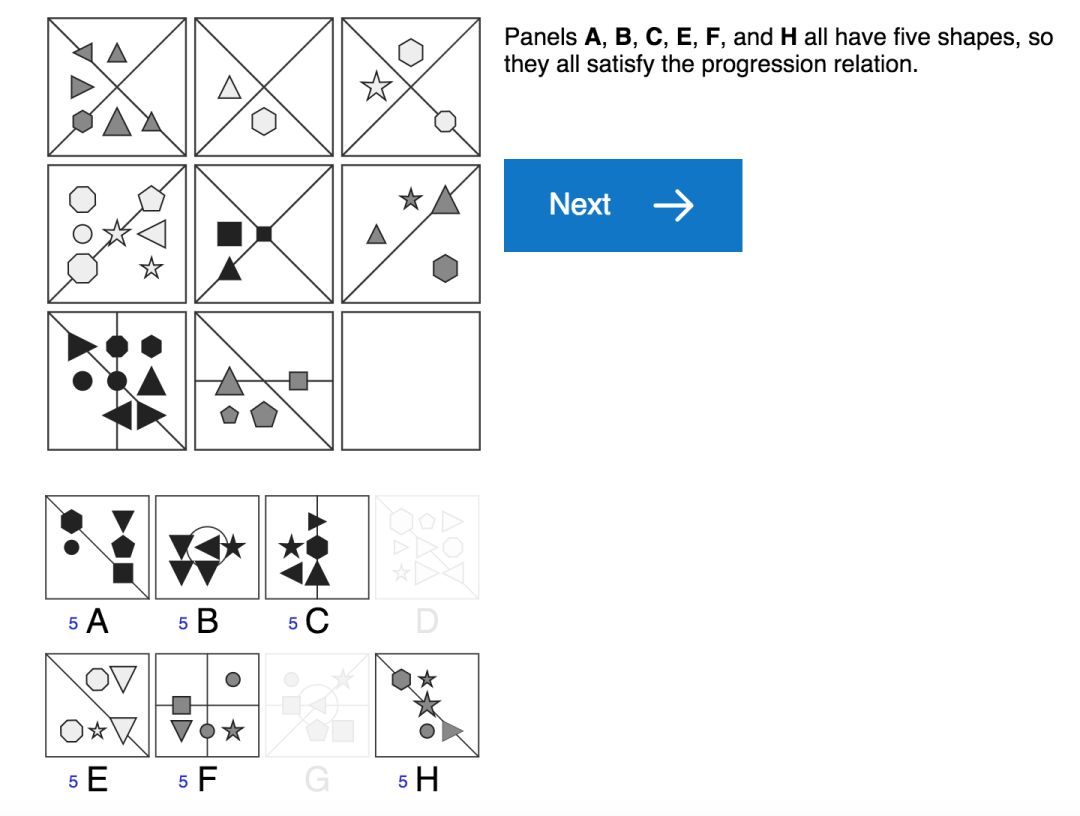
標準的人類 IQ 測試 (如上圖),通常要求測試者通過應用他們日常經驗學習到的原則來解釋一些簡單感知上的視覺場景。例如,人類測試者可以通過觀察植物或建筑物的增長,或通過數學課上學習的加法運算,或通過跟蹤銀行余額帶來的累積利息,來了解 “progressions” 這個概念 (表示屬性增加、遞增的概念)。然后,他們可以在謎題中應用這一概念,來推斷形狀的數量,大小,甚至它們的顏色強度將沿著序列增加的情況。
我們還沒有辦法能讓機器學習智能體學習到這樣的“日常體驗”,我們就無法輕易的去衡量如何它們將知識從現實世界轉化成視覺推理測試的能力。盡管如此,我們仍然可以創建一個實驗設置,以便能夠充分利用人類視覺推理測試。我們要研究的是從一組受控的視覺推理問題到另一組問題上的知識轉移,而不是研究從日常生活到視覺推理問題的知識轉移 (如人類測試中那樣)。
為了實現這個目標,我們構建了一個用于創建矩陣問題的生成器,稱之為“程序生成矩陣數據集” (Proceduralyly Generated Matrices, PGM),用于抽象推理的模型試驗。、該數據集涉及一組抽象因素并通過原始數據隨機采樣得到,這些抽象因素包括“漸進 (progressions)” 之類的關系、以及顏色大小等屬性數據。雖然該問題生成器只使用了一小部分的潛在因素,但它仍然會產生大量獨特的問題,以構成豐富的矩陣數據集。
關系類型數據集 (R,元素是 r):包括 progression,XOR,OR,AND,consistent union關系等。
目標類型數據集 (O,元素是 o):包括 shape,line 類型等。
屬性類型數據集 (A,元素是 a):包括 type,color,position,number 等屬性。
接著,我們對生成器可用的因素或組合進行了約束,使生成器能夠創建用于模型訓練和測試的不同問題數據集,以便我們進一步測量模型推廣到測試集的泛化能力。例如,我們創建了一組謎題訓練集,其中只有當應用線條顏色時才會遇到漸進 (progressions) 關系,而測試集中的情況是當應用形狀大小時才會發現該關系。如果模型在該測試集上表現良好,即使是訓練時從未見過的數據情況下也是如此,就證明了我們的模型具有推斷和應用抽象概念的能力。
▌抽象推理模型
在機器學習評估中所應用的典型的泛化方案中,訓練和測試數據是服從相同的基礎分布采樣的,所測試的所有網絡都表現出良好的泛化誤差,其中有一些絕對性能甚至超過75%,實現了令人印象深刻的結果。對于性能最佳的網絡,它不僅能夠明確地計算不同圖像面板之間的關系,還能并行地評估了每個潛在答案的適合性。我們將此網絡架構稱為—— Wild Relation Network (WReN),其模型結構示意圖如下:
WReN模型結構
其中,每個 CNN 能夠獨立處理每個上下文面板 (panel),而每個上下文面板將用于返回一個單獨的答案并生成9個嵌入矢量。隨后,將這組得到的嵌入向量傳遞給 RN,其輸出的是單個 sigmoid 單元,用于對問題答案的關聯得分進行編碼。 通過這樣的網絡傳遞過程,得到8個問題的答案及其相應的得分,最終通過一個 softmax 函數得分來確定模型的預測答案。
▌實驗分析
為了驗證抽象推理模型,我們在 PGM 數據集上進行了大量的實驗測試,并對比分析了不同模型的表現,不同類型問題模型的表現,模型的泛化表現,輔助訓練對模型表現的影響。
總的說來,當需要在先前見過的屬性值之間進行屬性值“內插值(interpolated)”時,以及在不熟悉的因素組合中應用已知抽象關系進行推理時,模型表現出非常好的泛化能力。然而,同樣的網絡在“外推 (extrapolation)”方案中卻表現的更差。在這種情況下,測試集中的屬性值與訓練集中的屬性值不在同一范圍內。例如,對于訓練期間包含深色物體而在測試期間包含淺色物體的謎題,就會出現這種情況。此外,當模型訓練時將先前學習到的關系 (如形狀數量的遞增關系) 應用于新的屬性 (如大小) 時,其泛化性能也會表現的更糟糕。
最后,我們觀察到當訓練的模型不僅能夠預測正確的答案,還能推理出正確答案 (即能夠考慮解決這個難題的特定關系和屬性) 時,我們模型的泛化性能得到了改進。更有趣的是,模型的準確性與其矩陣潛在的正確推理能力密切相關:當推理解釋正確時,模型的準確性將達到87%;而當其推理解釋錯誤時,這種準確性表現將下降到只有32%。這表明當模型能夠正確推斷出任務背后的抽象概念時,它們可以獲得更好的性能。
▌總結
最近的研究主要集中探索用于解決機器學習問題的神經網絡模型方法的優點和缺點,通常是基于模型的能力或泛化能力的研究。我們的研究結果表明,關于泛化能力的一般結論可能是無益的:我們的神經網絡在某些泛化方案測試中表現良好,而在其他測試中表現很差。其中的成功取決于一系列因素,包括所用模型的架構以及模型是否經過訓練來為其答案選擇提供可解釋的推理等。在幾乎所有的情況下,在超出模型經驗范圍的外推輸入或用于解決完全不熟悉的屬性問題時,模型都會表現不佳。因此,這也為這個關鍵而又重要的研究領域未來的工作提供了一個明確的焦點。
-
神經網絡
+關注
關注
42文章
4781瀏覽量
101176 -
人工智能
+關注
關注
1796文章
47683瀏覽量
240302
原文標題:天啊,你要的智商已下線——用我們的IQ測試題研究測量神經網絡的抽象推理能力
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論