 如何為文本分類任務選擇正確的模型,這里有一個完整流程圖!
如何為文本分類任務選擇正確的模型,這里有一個完整流程圖!
谷歌官方推出“文本分類”指南教程。為了最大限度地簡化選擇文本分類模型的過程,谷歌在進行大約450K的文本分類實驗后,總結出一個通用的“模型選擇算法”,并附上一個完整的流程圖,非常實用。
文本分類(Text classification)算法是大規模處理文本數據的各種軟件系統的核心。比如,電子郵件軟件使用文本分類來確定受到的郵件是發送到收件箱還是過濾到垃圾郵件文件夾;討論論壇使用文本分類來確定用戶評論是否應該標記為不當。
下面是兩個主題分類( topic classification)的例子,任務是將文本文檔歸類為預定義的一組主題。多數主題分類問題要基于文本中的關鍵字。
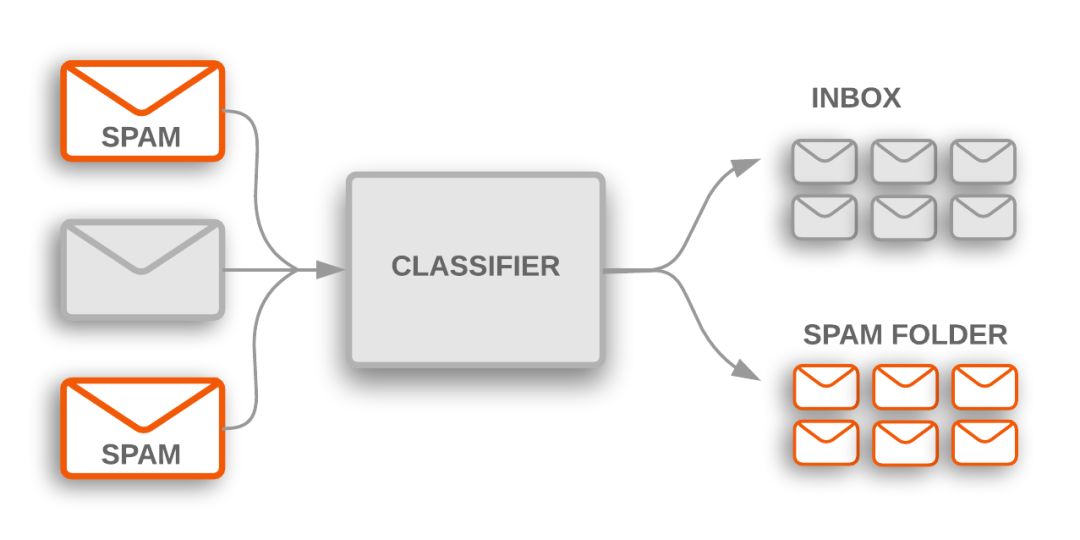
主題分類被用于標記收到的垃圾郵件,這些郵件被過濾到垃圾郵件文件夾中
另一種常見的文本分類是情感分析(sentiment analysis),其目的是識別文本內容的極性(polarity):它所表達的觀點的類型。這可以采用二進制的“喜歡/不喜歡”來評級,或者使用更精細的一組選項,比如從1顆星星到5顆星星的評級。情感分析的例子包括分析Twitter上的帖子,以確定人們是否喜歡黑豹電影,或者從沃爾瑪的評論中推斷普通大眾對耐克新品牌的看法。
這個指南將教你一些解決文本分類問題的關鍵的機器學習最佳實踐。你將學習:
使用機器學習解決文本分類問題的高級、端到端工作流(workflow)
如何為文本分類問題選擇合適的模型
如何使用TensorFlow實現你選擇的模型
文本分類的workflow
以下是解決機器學習問題的workflow
步驟1:收集數據
步驟2:探索你的數據
步驟2.5:選擇一個模型*
步驟3:準備數據
步驟4:構建、訓練和評估你的模型
步驟5:調優超參數
步驟6:部署模型

解決機器學習問題的workflow
【注】 “選擇模型”并不是傳統機器學習workflow的正式步驟;但是,為你的問題選擇合適的模型是一項關鍵的任務,它可以在接下來的步驟中明確并簡化工作。
谷歌機器學習速成課程的《文本分類》指南詳細解釋了每個步驟,以及如何用文本數據實現這些步驟。由于篇幅限制,本文在涵蓋重要的最佳實踐和經驗法則的基礎上,重點介紹步驟2.5:如何根據數據集的統計結構選擇正確的模型,并提供一個完整的流程圖。
步驟1:收集數據
收集數據是解決任何有監督的機器學習問題的最重要步驟。構成它的數據集有多好,你的文本分類器就有多好。
如果你沒有想要解決的特定問題,只是對探索文本分類感興趣,那么有大量可用的開源數據集。下面的GitHub repo就足以滿足你的需求:
https://github.com/google/eng-edu/blob/master/ml/guides/text_classification/load_data.py
另一方面,如果你正在處理一個特定的問題,則需要收集必要的數據。許多組織提供用于訪問其數據的公共API——例如,Twitter API或NY Times API,你可以利用這些來找到想要的數據。
以下是收集數據時需要記住的一些重要事項:
如果你使用的是公共API,請在使用之前了解API的局限性。例如,一些API對查詢速度設置了限制。
訓練示例(在本指南的其余部分稱為示例)越多越好。這將有助于模型更好地泛化。
確保每個類或主題的樣本數量不會過度失衡。也就是說,每個類都應該有相當數量的樣本。
確保示例充分覆蓋了可能的輸入空間,而不僅僅覆蓋常見的情況。
在本指南中,我們將使用IMDb的電影評論數據集來說明這個workflow。這個數據集收集了人們在IMDb網站上發布的電影評論,以及相應的標簽(“positive”或“negative”),表示評論者是否喜歡這部電影。這是情緒分析問題的一個典型例子。
步驟2:探索你的數據
加載數據集
檢查數據
收集關鍵指標
構建和訓練模型只是工作流程的一部分。事先了解數據的特征能夠幫助你構建更好的模型。這不僅僅意味著獲得更高的準確度,也意味著需要較少的訓練數據,或者更少的計算資源。
步驟2.5:選擇一個模型
到這一步,我們已經收集了數據集,并深入了解了數據的關鍵特性。接下來,根據我們在步驟2中收集的指標,我們應該考慮應該使用哪種分類模型。這意味著提出問題,例如“如何將文本數據呈現給期望輸入數字的算法?”(這叫做數據預處理和矢量化),“我們應該使用什么類型的模型?”,“我們的模型應該使用什么配置參數?”,等等。
經過數十年的研究,我們已經能夠訪問大量的數據預處理和模型配置選項。然而,大量可供選擇的可行方案大大增加了手頭的特定問題的復雜性和范圍。考慮到最好的選擇可能并不明顯,一個想當然的解決方案是嘗試盡每一種可能的選擇,通過直覺排除一些選擇。但是,這樣做成本是非常昂貴的。
在本指南中,我們試圖最大限度地簡化選擇文本分類模型的過程。對于給定的數據集,我們的目標是找到在最小化訓練所需的計算時間的同時,實現接近最大精度的算法。我們使用12個數據集針對不同類型的問題(尤其是情感分析和主題分類問題)進行了大量(~450K)實驗,將不同的數據預處理技術和不同的模型架構交替用于每個數據集。這有助于我們找到影響最佳選擇的數據集參數。
下面的模型選擇算法(model selection algorithm)和流程圖是我們的大量實驗的總結。
數據準備和模型構建算法
1. 計算樣本的數量/每個樣本中單詞的數量這個比率。
2. 如果這個比率小于1500,那么將文本標記為n-grams并使用簡單的MLP模型進行分類(下面的流程圖的左邊分支):
a. 將樣本分解成word n-grams;把n-grams轉換成向量。
b. 給向量的重要性打分,然后根據分支選擇前20K。
c. 構建一個MLP模型。
3. 如果比率大于1500,則將文本標記為序列,并使用sepCNN模型進行分類(流程圖右邊分支):
a. 將樣本分解成單詞;根據頻率選擇前20K的單詞。
b. 將樣本轉換為單詞序列向量。
c. 如果原始樣本數/每個樣本的單詞數這個比率小于15K,則使用微調的預訓練sepCNN模型,可能得到最優的結果。
4. 用不同的超參數值來測量模型的性能,以找到數據集的最佳模型配置。
在下面的流程圖中,黃色框表示數據和模型準備過程。灰色框和綠色框表示我們為每個流程考慮的選項。綠色框表示我們對每個流程的推薦選項。
你可以用這個流程圖作為你的第一個實驗的起點,因為它可以讓你在低計算成本下獲得良好的準確度。你可以在后面的迭代中繼續改進初始模型。
文本分類流程圖(點擊可放大查看)
此流程圖回答了兩個關鍵問題:
我們應該使用哪種學習算法或模型?
我們應該如何準備數據,才能有效地學習文本和標簽之間的關系?
第二個問題的答案取決于第一個問題的答案;我們預處理數據的方式將取決于我們選擇的模型。模型可以大致分為兩類:使用單詞排序信息的模型(序列模型),以及僅將文本視為單詞的“bags”(sets)的模型(n-gram模型)。
序列模型包括卷積神經網絡(CNN),遞歸神經網絡(RNN)及其變體。 n-gram模型包括邏輯回歸,簡單多層感知機(MLP或全連接神經網絡),梯度提升樹(gradient boosted trees)和支持向量機(SVM)。
在實驗中,我們觀察到“樣本數”(S)與“每個樣本的單詞數”(W)的比率與模型的性能具有相關性。
當該比率的值很小(<1500)時,以n-gram作為輸入的小型多層感知機(選項A)表現得更好,或者說至少與序列模型一樣好。 MLP易于定義和理解,而且比序列模型花費的計算時間更少。
當此比率的值很大(> = 1500)時,我們就使用序列模型(選項B)。在接下來的步驟中,你可以根據這個比率值的大小,直接閱讀所選模型的相關章節。
對于我們的IMDb評論數據集,樣本數/每個樣本的單詞數的比值在144以下。這意味著我們將創建一個MLP模型。
步驟3:準備數據
N-gram向量[選項A]
序列向量[選項B]
標簽的向量化
步驟4:構建,訓練和評估模型
構建最后一層
構建n-gram模型[選項A]
構建序列模型[選項B]
訓練模型
步驟5:調優超參數
步驟6:部署模型
結論
文本分類是機器學習中的基本問題,在各種產品應用中均有涉及。在本指南中,我們將文本分類的workflow分解為幾個步驟。對于每個步驟,我們都根據特定數據集的特征,建議自定義的實現方法。尤其是,我們根據樣本數量與每個樣本中的單詞數量的比值,來建議你使用哪一種模型,從而能夠更快地讓模型接近最佳性能。其他的步驟都是基于模型選擇這個步驟的。遵循這個指南中的建議,參考附錄中的代碼和流程圖將有助于你的學習和理解,并快速獲取文本分類問題的解決方案。
-
二進制
+關注
關注
2文章
796瀏覽量
41757 -
文本分類
+關注
關注
0文章
18瀏覽量
7340 -
機器學習
+關注
關注
66文章
8438瀏覽量
133082
原文標題:谷歌做了45萬次不同類型的文本分類后,總結出一個通用的“模型選擇算法”
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
pyhanlp文本分類與情感分析
基于GA和信息熵的文本分類規則抽取方法
融合詞語類別特征和語義的短文本分類方法
文本分類的一個大型“真香現場”來了
結合BERT模型的中文文本分類算法
一種基于BERT模型的社交電商文本分類算法

融合文本分類和摘要的多任務學習摘要模型






 工商網監
工商網監
評論