 自然語言處理中的卷積神經網絡的詳細資料介紹和應用
自然語言處理中的卷積神經網絡的詳細資料介紹和應用
1、傳統的自然語言處理模型
1)傳統的詞袋模型或者連續詞袋模型(CBOW)都可以通過構建一個全連接的神經網絡對句子進行情感標簽的分類,但是這樣存在一個問題,我們通過激活函數可以讓某些結點激活(例如一個句子里”not”,”hate”這樣的較強的特征詞),但是由于在這樣網絡構建里,句子中詞語的順序被忽略,也許同樣兩個句子都出現了not和hate但是一個句子(I do not hate this movie)表示的是good的情感,另一個句子(I hate this movie and will not choose it)表示的是bad的情感。其實很重要的一點是在剛才上述模型中我們無法捕獲像not hate這樣由連續兩個詞所構成的關鍵特征的詞的含義。
2)在語言模型里n-gram模型是可以用來解決上面的問題的,想法其實就是將連續的兩個詞作為一個整體納入到模型中,這樣確實能夠解決我們剛才提出的問題,加入bi-gram,tri-gram可以讓我們捕捉到例如“don’t love”,“not the best”。但是新的問題又來了,如果我們使用多元模型,實際訓練時的參數是一個非常大的問題,因為假設你有20000個詞,加入bi-gram實際上你就要有400000000個詞,這樣參數訓練顯然是爆炸的。另外一點,相似的詞語在這樣的模型中不能共享例如參數權重等,這樣就會導致相似詞無法獲得交互信息。
2、自然語言處理中的卷積神經網絡
在圖像中卷積核通常是對圖像的一小塊區域進行計算,而在文本中,一句話所構成的詞向量作為輸入。每一行代表一個詞的詞向量,所以在處理文本時,卷積核通常覆蓋上下幾行的詞,所以此時卷積核的寬度與輸入的寬度相同,通過這樣的方式,我們就能夠捕捉到多個連續詞之間的特征(只要通過設置卷積核的尺寸,卷積核的寬度一般和詞向量的長度一致,長度可以去1,2,3這類的值,當取3時就會將3個連續詞的特征表示出來),并且能夠在同一類特征計算時中共享權重。如下圖所示
如上圖所示,不同長度的卷積核,會獲得不同長度的輸出值,但在之后的池化中又會得到相同的長度(比如上面的深紅色的卷積核是4 × 5,對于輸入值為7 × 5的輸入值,卷積之后的輸出值就是4 × 1,最大池化之后就是1 × 1;深綠色的卷積核是3 × 5,卷積之后的輸出值是5 × 1,最大池化之后就是1 × 1),最后將所有池化后的值組合在一起,這樣有一點好處,無論輸入值的大小是否相同(輸入值行一般不相等,對于輸入值列是詞向量的長度,一般都是相等,但是行是和文本中詞的數量相關的),要用相同數量的卷積核進行卷積,之后再池化就會獲得相同長度的向量(向量的長度和卷積核的數量相等),這樣再之后就可以用全連接層了(全連接層的輸入值的向量大小必須是一致的)。
3、卷積層的最大池化問題
MaxPooling Over Time是NLP中CNN模型中最常見的一種下采樣操作。意思是對于某個Filter抽取到若干特征值,只取其中得分最大的那個值作為Pooling層保留值,其它特征值全部拋棄,值最大代表只保留這些特征中最強的,而拋棄其它弱的此類特征(正如上圖所示的那樣)。
CNN中采用Max Pooling操作有幾個好處:
1)這個操作可以保證特征的位置與旋轉不變性,因為不論這個強特征在哪個位置出現,都會不考慮其出現位置而能把它提出來。對于圖像處理來說這種位置與旋轉不變性是很好的特性,但是對于NLP來說,這個特性其實并不一定是好事,因為在很多NLP的應用場合,特征的出現位置信息是很重要的,比如主語出現位置一般在句子頭,賓語一般出現在句子尾等等,這些位置信息其實有時候對于分類任務來說還是很重要的,但是Max Pooling 基本把這些信息拋掉了。
2)MaxPooling能減少模型參數數量,有利于減少模型過擬合問題。因為經過Pooling操作后,往往把2D(圖像中)或者1D(自然語言中)的數組轉換為單一數值,這樣對于后續的Convolution層或者全聯接隱層來說無疑單個Filter的參數或者隱層神經元個數就減少了。
3)對于NLP任務來說,Max Pooling有個額外的好處;在此處,可以把變長的輸入X整理成固定長度的輸入。因為CNN最后往往會接全聯接層,而其神經元個數是需要事先定好的,如果輸入是不定長的那么很難設計網絡結構。
但是,CNN模型采取MaxPooling Over Time也有一些值得注意的缺點:首先就如上所述,特征的位置信息在這一步驟完全丟失。在卷積層其實是保留了特征的位置信息的,但是通過取唯一的最大值,現在在Pooling層只知道這個最大值是多少,但是其出現位置信息并沒有保留;另外一個明顯的缺點是:有時候有些強特征會出現多次,比如我們常見的TF.IDF公式,TF就是指某個特征出現的次數,出現次數越多說明這個特征越強,但是因為Max Pooling只保留一個最大值,所以即使某個特征出現多次,現在也只能看到一次,就是說同一特征的強度信息丟失了。這是Max Pooling Over Time典型的兩個缺點。
針對上面提出的兩個缺點,通常的解決辦法是下面兩種池化方法
K-Max Pooling
K-MaxPooling的核心思想是:原先的Max Pooling Over Time從Convolution層一系列特征值中只取最強的那個值,K-Max Pooling可以取所有特征值中得分在Top –K的值,并保留這些特征值原始的先后順序,就是說通過多保留一些特征信息供后續階段使用。如下圖所示
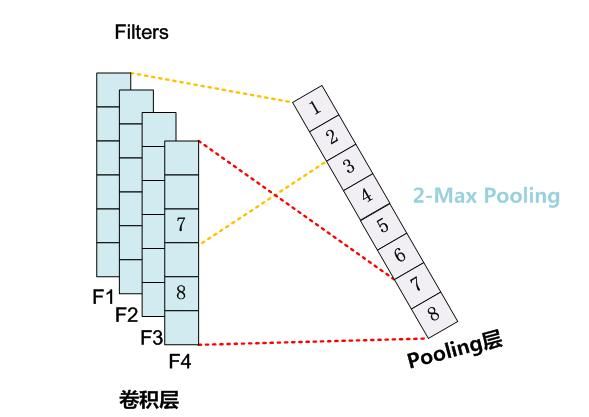
很明顯,K-Max Pooling可以表達同一類特征出現多次的情形,即可以表達某類特征的強度;另外,因為這些Top K特征值的相對順序得以保留,所以應該說其保留了部分位置信息,但是這種位置信息只是特征間的相對順序,而非絕對位置信息。
Chunk-Max Pooling
Chunk-MaxPooling的核心思想是:把某個Filter對應的Convolution層的所有特征向量進行分段,切割成若干段后,在每個分段里面各自取得一個最大特征值,比如將某個Filter的特征向量切成3個Chunk,那么就在每個Chunk里面取一個最大值,于是獲得3個特征值。如下圖所示,不同顏色代表不同段
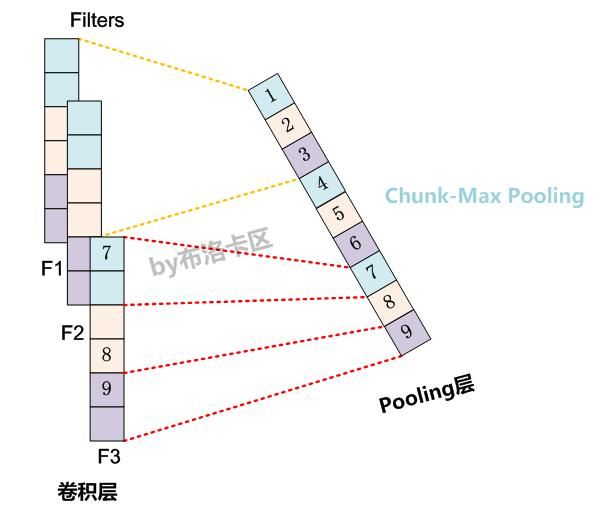
Chunk-Max Pooling思路類似于K-Max Pooling,因為它也是從Convolution層取出了K個特征值,但是兩者的主要區別是:K-Max Pooling是一種全局取Top K特征的操作方式,而Chunk-Max Pooling則是先分段,在分段內包含特征數據里面取最大值,所以其實是一種局部Top K的特征抽取方式。
至于這個Chunk怎么劃分,可以有不同的做法,比如可以事先設定好段落個數,這是一種靜態劃分Chunk的思路;也可以根據輸入的不同動態地劃分Chunk間的邊界位置,可以稱之為動態Chunk-Max方法。事實上對于K-Max Pooling也有動態的去獲取K的值的方法,表達式如下
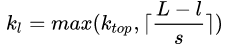
s代表的是句子長度,L代表總的卷積層的個數,l代表的是當前是在幾個卷積層,所以可以看出這里的k是隨著句子的長度和網絡深度而改變。
Chunk-Max Pooling很明顯也是保留了多個局部Max特征值的相對順序信息,盡管并沒有保留絕對位置信息,但是因為是先劃分Chunk再分別取Max值的,所以保留了比較粗粒度的模糊的位置信息;當然,如果多次出現強特征,則也可以捕獲特征強度。
如果分類所需要的關鍵特征的位置信息很重要,那么類似Chunk-Max Pooling這種能夠粗粒度保留位置信息的機制應該能夠對分類性能有一定程度的提升作用;但是對于很多分類問題,估計Max-Pooling over time就足夠了。
4、卷積神經網絡在自然語言處理中的應用
最適合CNNs的莫過于分類任務,如語義分析、垃圾郵件檢測和話題分類。卷積運算和池化會丟失局部區域某些單詞的順序信息,因此純CNN的結構框架不太適用于PoS Tagging和Entity Extraction等順序標簽任務。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101168 -
cnn
+關注
關注
3文章
353瀏覽量
22334 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13646
原文標題:自然語言處理之卷積神經網絡應用
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
卷積神經網絡模型發展及應用
淺談圖神經網絡在自然語言處理中的應用簡述






 工商網監
工商網監
評論