 流行基線基礎問題遲遲沒能解決,讓模型學會閱讀理解究竟需要多少文本
流行基線基礎問題遲遲沒能解決,讓模型學會閱讀理解究竟需要多少文本
編者按:今天,卡內基梅隆大學助理教授Zachary C. Lipton推薦了自己的一個有趣研究:讓模型學會閱讀理解究竟需要多少文本。在之前的ICML 2018研討會上,他和斯坦福大學研究生Jacob Steinhardt曾撰文痛批學界“歪風”,在學界引起巨大反響。其中提到的一個弊端就是有些學者會對“進步”錯誤歸因,把調參獲得的性能改善強加到架構調整上。結合這篇論文,也許他的研究能讓我們獲得一些見解。
摘要
近期,學界發表了不少有關閱讀理解的論文,它們使用的樣本都是(問題、段落、答案)這樣的三元組。對此,一種常規的想法是,如果模型的目標是預測相應答案,它們就必須結合來自問題和段落的信息。這是個很有趣的點,但考慮到現在有數百篇已發表的論文正在爭奪排行榜第一的寶座,圍繞這些流行基線的基礎問題還是遲遲沒能得到解決。
在本文中,我們為bAbI、SQuAD、CBT、CNN和Whodid-What數據集構建了合理的基線,發現如果樣本中只包含純問題或純段落,模型的表現通常會很好。用純段落樣本進行訓練后,模型在14個bAbI問題上取得了高于50%的準確率(一共20個),其中部分結果甚至可以媲美正常模型。
另外,我們也發現了一個奇怪的點:在CBT任務中,研究人員通常會用一個問題和一個包含前20個句子的段落預測第21個句子中的缺失詞,但實驗證實,模型可能只需第21句話就能完成預測。相比之下,CNN和SQuAD這兩個數據集似乎構造得很好。
數據集&基線

實驗結果
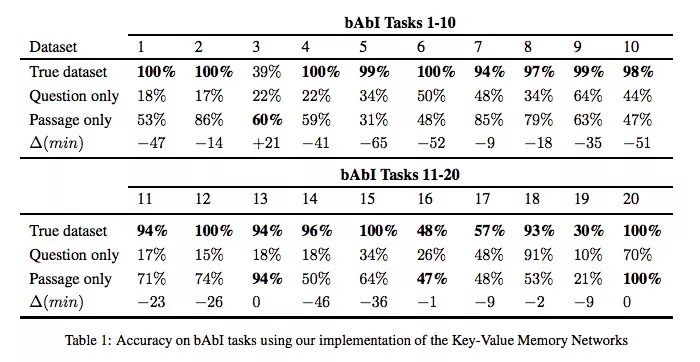
bAbI任務
下表是基線KV-MemNet在bAbI數據集上的具體表現,第一行使用的是常規樣本,包含問題和段落;第二行只使用問題;第三行只使用段落。可以發現,在第2,7,13,20個問題中,用段落訓練的模型性能驚人,準確率在80%以上。在第3,13,16和20個問題中,它的準確率甚至超過了使用常規樣本的模型。而在第18個問題中,用問題訓練的模型的準確率也達到了91%,和正常的93%非常接近。
這個發現給我們的啟示是,bAbI的某些問題可能并沒有我們想象中那么復雜。
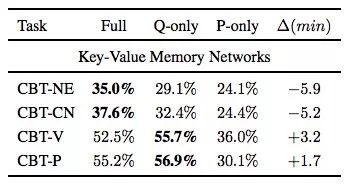
CBT任務
CBT任務的“答案”根據詞性可分為命名實體(NE)、公共名詞(CN)、動詞(V)、介詞(P)四類,由于后兩種根據上下文就能預測,通常我們在閱讀理解問題里會更重視前兩種詞性。
同樣是基線KV-MemNet,如下表所示,這次使用的三類樣本成了三列:如果是預測NE和CN,使用完整樣本訓練的模型準確率更高,但用了問題的模型和它也很接近;如果是預測V和P,只用問題訓練效果更佳。
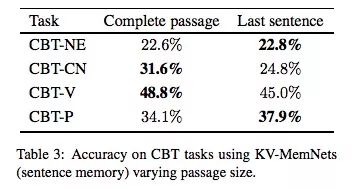
那么如果把“段落”從前20個句子改成第21句呢?下表是只用“段落”的實驗結果,可以發現,用最后一句效果更好,也就是說,它和正常模型的性能更接近。
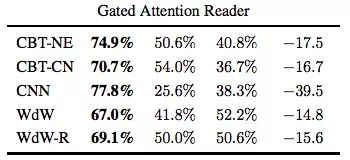
CNN任務
在這里,Gated Attention Reader在CNN任務上的準確率就差距較大了。這種下降可能是因為實體匿名化導致模型無法構建特定于實體的信息。
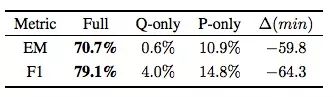
SQuAD任務
這個結果表明,SQuAD這個數據集針對閱讀理解任務做了精心設計,它最具挑戰性。
討論
從實驗數據可知,雖然同屬閱讀理解任務,但這些數據集存在不同的缺陷,也有各種漏洞可以鉆。下面是我們為評估新的基線和算法設想的一些指導原則。這不是在指責以前的數據集制作者,相反地,這些紕漏能為未來的研究提供不小的價值。
提供嚴格的RC基線:已發布的RC數據集應包含表明任務難度的合理基線,尤其是它們所需的“問題”“段落”信息量,如果沒有這些標準,我們就無法知道模型進步究竟取決于什么。
測試完整信息的必要性:在需要“問題”信息和“段落”信息的問題中,有時候真正起作用的只是部分信息。就像CBT任務,雖然只有二十幾句話,但是我們用最后一句話就能訓練媲美正常性能的模型。每個模型究竟需要多少信息量,這是研究人員應該標明的。
使用完型填空式的RC數據集時,保持謹慎:這類數據集通常是由程序批量制造的,很少有人參與。如果用它們訓練模型,我們會找不到目前技術的局限,也排查不了。
此外,各類會議在推薦收錄論文的數據集時,也應更注重嚴謹性,而不是只看創新性。
-
模型
+關注
關注
1文章
3313瀏覽量
49227 -
基線
+關注
關注
0文章
12瀏覽量
7990
原文標題:基線調研:讓模型學會閱讀理解需要多少信息?
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
【「大模型啟示錄」閱讀體驗】對本書的初印象
基于LabVIEW的文本(txt)閱讀器
基于文本摘要和引用關系的可視輔助文獻閱讀系統
機器閱讀理解的含義以及如何工作

剝開機器閱讀理解的神秘外衣
如果把中學生的英語閱讀理解選擇題讓AI來做,會做出什么水平?
一種基于多任務聯合訓練的閱讀理解模型

基于LSTM的表示學習-文本分類模型
深度揭秘工字電感究竟需要測量哪些參數的好壞






 工商網監
工商網監
評論