 深度神經決策樹:深度神經網絡和樹模型結合的新模型
深度神經決策樹:深度神經網絡和樹模型結合的新模型
近日,來自愛丁堡大學的研究人員提出了一種結合深度神經網絡和樹模型的新型模型——深度神經決策樹(Deep Neural Decision Trees, DNDT)。
這種模型不僅具有了基于樹模型的可解釋性的優點,同時還可以利用神經網絡中的梯度下降法來進行訓練,并可方便地利用現有的神經網絡框架實現,將使得神經網絡的過程得以用樹的方式得到有效的解釋。論文的作者均來自于愛丁堡大學信息學院感知、運動和行為研究所ipab。
對于感知模型來說可解釋性是十分重要的,特別是在一些涉及倫理、法律、醫學和金融等場景下尤其如此,同樣在關鍵領域的控制中,我們希望能夠回溯所有的步驟來保證模型因果邏輯和結果的正確性。深度神經網絡在計算機視覺、語音識別和語言模型等很多領域取得了成功,但作為缺乏可解釋性的黑箱模型,限制了它在模型必須求證因果領域的應用,在這些領域中我們需要明確決策是如何產生的以便評測驗證整個決策過程。除此之外,在類似于商業智能等領域,知曉每一個因素是如何影響最終決策比決策本身有時候更為重要。與此不同的是,基于決策樹模型(包括C4.5和CART等)擁有清晰的可解釋性,可以追隨樹的結構回溯出決策產生的因由。
愛丁堡大學的研究人員們基于樹和神經網絡的結構提出了一種新型的模型——深度神經決策樹(DNDT),并探索了樹和網絡之間的相互作用。DNDT是一種具有特殊結構的神經網絡,任意一種配置下的DNDT都對應著決策樹,這使其具有了可解釋性。同時由于DNDT實現自神經網絡,使得它擁有了很多傳統決策樹不曾具有的特性:
1.DNDT可以通過已有的神經網絡工具便捷的實現,可能只需要幾行即可;
一個實現的例子
2.所有的參數可以通過隨機梯度下降法(SGD)同時優化,代替了復雜的貪婪優化過程;
3.具有大規模處理數據的能力,可以利用mini-batch和GPU加速;
4.可以作為一個模塊插入到現有的神經網絡模型中,并整體訓練。
在這種網絡中研究人員們使用了一種稱為soft binning function的函數,并將它用于DNDT中的分支操作。一個典型的soft binning函數可以得到輸入標量的二進制值,與Hard binning不同的是,這是一種可微的近似。這使得決策樹中的的參數是可導的,也就可以利用梯度下降法來進行訓練了。下式是MDMT中的一層神經元表示:
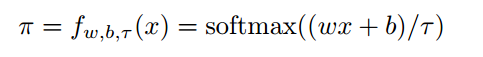
其中w為權重參數[1,2,。。。,n+1],b表示為[0,-β1,-β2...-βn],代表了n個分支點。式中的τ代表了溫度因子,其趨向于0時將為生成one-hot編碼。下圖是不同τ作用下的softbinning函數:
其中x在[0,1]區間內,此時的分割點為0.33和0.66,三個圖分別代表了τ為1,0,1和0.01的情況,越小意味著分支越陡峭。其中,
o1 = x
o2 = 2x-0.33
o3 = 3x-0.99
在決策過程中,通過上式給出的二進制函數利用克羅內克內積來實現,下圖中顯示了DNDT在Iris數據集上的學習過程,上半部分描述了深度神經決策樹的運行過程,其中紅色表示為可訓練的變量,黑色數字為常量。下半部分作為對比顯示了先前決策樹的分類過程。
通過本文提出的方法,研究人員將決策樹的訓練過程轉換為了訓練二進制分支點和葉子分類器。同時由于前傳過程是可微的,所以所有的點都可以同時利用SGD的方法來訓練。由于可以利用與神經網絡類似的mini-batch,DNDT可以便捷的實例規模化。但目前存在的問題是克羅內克積的存在使得特征的規模化不易實現。目前的解決方案是引入多棵樹來來訓練特征集中的子特征組合,避免了較“寬”的數據。
研究人員通過實驗驗證了中模型的有效性,在常見的14個數據集上(特別是Tabular類型的數據)取得了較好的結果。其中決策樹使用了超參數,“基尼”尺度和“best”分支;神經網絡使用了兩個隱藏層共50個神經元作為基準。而DNDT則使用了1最為分支點數目的超參數。
研究顯示DNDT模型隨著分割點的增加,整體激活的比重卻在下降,顯示了這種模型具有正則化的作用。
同時研究還顯示了分割點數量對于每一個特征的影響;
并利用了GPU來對計算過程進行了加速。
在未來還會探索DNDT與CNN的結合與應用,并將SGD應用到整個模型的全局優化中去,并嘗試基于決策樹的遷移學習過程。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101166 -
gpu
+關注
關注
28文章
4774瀏覽量
129351 -
決策樹
+關注
關注
3文章
96瀏覽量
13587
原文標題:愛丁堡大學研究人員提出「深度神經決策樹」,可結合深度神經網絡和樹模型
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論