 一種全新的無監督機器翻譯方法,在BLUE基準測試上取得了10分以上提升
一種全新的無監督機器翻譯方法,在BLUE基準測試上取得了10分以上提升
Facebook研究人員提出了一種全新的無監督機器翻譯方法,在BLUE基準測試上取得了10分以上提升。研究人員表示,這種無監督方法不僅適用于機器翻譯,也可以擴展到其他領域,讓智能體在使用無標記數據的情況下,完成只有極少甚至沒有訓練數據的任務。這是機器翻譯以及無監督學習的一項重大突破。而其實現方法本身也十分巧妙,相關論文已被EMNLP 2018接收。
自動語言翻譯對于Facebook來說非常重要,因為Facebook用戶高達數十億,可以想見其平臺每天承載和需要轉換的語種數量。當然,有了神經機器翻譯(NMT)技術以后,機器翻譯的速度和水平都得到了大幅提升。
不過,傳統的統計機器翻譯也好,NMT也罷,都需要大量的訓練數據,比如中英、英德、英法等大量語言對。而對于訓練數據較少的語種,比如尼泊爾語,就很難應對了。這也是之前谷歌翻譯出現奇怪宗教預言的原因之一,因為《圣經》是被翻譯成最多語種的文本之一,專家推測谷歌應該使用《圣經》文本來訓練谷歌機器翻譯系統,而當出現雜亂無章的輸入以后,機器拼命想要從中“找出”意義,才會出現一些來自《圣經》中的語句。
話題扯遠了。回來Facebook面對的問題上來。
正如前文所說,如何解決小語種,也即沒有大量可供訓練的數據時,機器翻譯的問題呢?
Facebook的研究人員提出了一種“不需要任何翻譯資源的MT模型”,也即“無監督翻譯”,他們認為這是機器翻譯未來的發展方向。在即將舉行的EMNLP 2018上,Facebook研究人員將展示的他們的結果。
新方法比以前最先進的無監督方法有了顯著的改進,其效果相當于使用近10萬個參考譯文訓練過的監督方法。用機器翻譯常用的基準BLEU衡量,Facebook的新方法實現了超過10分的改善(BLEU上提高1分就已經是相當了不起的成果了)。
對于機器翻譯而言,這是一個非常重要的發現,特別是小語種而言,有些訓練數據很少,有些甚至連訓練數據都沒有。而Facebook提出的無監督機器翻譯,能夠初步解決這一問題,比如在烏爾都語(注釋:巴基斯坦的國語,屬于印歐語系印度-伊朗語族的印度-雅利安語支;是全球使用人數排名第20的語言)和英語之間進行自動翻譯——不需要任何翻譯好的語言對。
這種新方法為更快、更準確地翻譯更多的語言打開了一扇門。同時,相關的技術原理或許也能用于其他機器學習和人工智能的應用。
通過旋轉對齊詞嵌入結構,進行詞到詞的翻譯
Facebook無監督機器翻譯的方法,首先是讓系統學習雙語詞典,將一個詞與其他語言對應的多種翻譯聯系起來。舉個例子,就好比讓系統學會“Bug”在作為名詞時,既有“蟲子”、“計算機漏洞”,也有“竊聽器”的意思。
Facebook使用了他們在之前發表于ICLR 2018的論文《Word Translation Without Parallel Data》中介紹的方法,讓系統首先為每種語言中的每個單詞學習詞嵌入,也即單詞的向量表示。
然后,系統會訓練詞嵌入,根據其上下文(例如,給定單詞前后的各5個單詞)來預測給定單詞周圍的單詞。盡管詞嵌入是一種非常簡單的表示方法,但從中可以獲得很有趣的語義結構。例如,與“kitty”(小貓)這個詞距離最近的是“cat”(貓),并且“kitty”這個詞與“animal”(動物)之間的距離要遠遠小于它與“rocket”(火箭)這個詞的距離。換句話說,“kitty”很少出現在有“rocket”的上下文里。
可以通過簡單的旋轉并對齊兩種語言(X和Y)的二維詞嵌入,然后通過最近鄰搜索實現單詞翻譯。
此外,不同語言中意思相近的詞匯具有相似的鄰域結構,因為世界各地的人們生活在相同的物理環境中。例如,英語中“cat”和“furry”(毛茸茸)之間的關系,類似于它們在西班牙語中對應的翻譯“gato”和“peludo”,因為這些單詞的出現頻率及其上下文是非常相似的。
鑒于這些相似之處,Facebook的研究人員提出了一種方法,讓系統通過對抗訓練等方法,學習將一種語言的詞嵌入結構進行旋轉,從而匹配另一種語言的詞嵌入結構。有了這些信息以后,他們就可以推斷出一個相當準確的雙語詞典,無需任何已經翻譯好的語句,并且基本上可以做到逐字翻譯。
通過旋轉并對齊不同語言的詞嵌入結構,得到詞到詞的翻譯
用無監督反向翻譯技術,訓練句到句的機器翻譯系統
當逐字翻譯實現以后,接下來就是詞組乃至句子的翻譯了。
當然,逐字翻譯的結果是無法直接用在句子翻譯上的。于是,Facebook的研究人員又使用了一種方法,他們訓練了一個單語種語言模型,對逐字翻譯系統給出的結果打分,從而盡可能排除不符合語法規則或有語病的句子。
這個單語模型比較好獲得,只要有小語種(比如烏爾都語)的大量單語數據集就可以。英語的單語模型則更好構建了。
通過使用單語模型對逐字翻譯模型進行優化,就得到了一個比較原始的機器翻譯系統。
雖然翻譯結果不是很理想,但這個系統已經比逐字翻譯的結果更好了,并且它可以將大量句子從源語言(比如烏爾都語)翻譯成目標語言(比如英語)。
接下來,Facebook研究人員再將這些機器翻譯所得到的句子(從烏爾都語到英語的翻譯)作為ground truth,用于訓練從英語到烏爾都語的機器翻譯。這種技術最先由R. Sennrich等人在ACL 2015時提出,叫做“反向翻譯”,當時使用的是半監督學習方法(有大量的語言對)。這還是反向翻譯技術首次應用于完全無監督的系統。
不可否認,由于第一個系統(從烏爾都語到英語的原始機器翻譯系統)的翻譯錯誤,作為訓練數據輸入的英語句子質量并不高,因此第二個反向翻譯系統輸出的烏爾都語翻譯效果可想而知。
不過,有了剛才訓練好的那個烏爾都語單語模型,就可以用它來對第二個反向翻譯系統輸出的烏爾都語譯文進行校正,從而不斷優化、迭代,逐漸完善第二個反向翻譯系統。
無監督機器翻譯三原則:詞到詞的翻譯、語言建模和反向翻譯
在Facebook的這項工作中,他們確定了三個步驟——詞到詞的翻譯(word-by-word initialization)、語言建模和反向翻譯——作為無監督機器翻譯的重要原則。有了這些原則后,就可以推導出各種模型。
紅點代表源語言,紅圈代表未觀測到的目標語言翻譯,紅叉代表系統對目標語言的翻譯;藍點代表目標語言,藍圈代表未觀測到的源語言翻譯,藍叉代表系統對源語言的翻譯。A) 構建兩種語言的詞嵌入模型;B) 通過旋轉對齊詞嵌入進行詞到詞的翻譯;C) 通過單語種模型訓練改善;D) 反向翻譯。
Facebook研究人員用其構建了兩種不同的模型,以解決無監督機器翻譯的目標。
第一個是無監督神經模型,其結果比逐字翻譯更流暢,但卻沒有產生研究人員想要的質量翻譯。但是,這個無監督神經模型的翻譯結果可以用作反向翻譯的訓練數據。使用這種方法得到的翻譯結果,與使用100,000個語言對進行訓練的監督模型效果相當。
接下來,Facebook的研究人員上述原則應用于基于經典計數統計方法的另一個機器翻譯模型,叫做“基于短語的機器翻譯”(phrase-based MT)。通常而言,這些模型在訓練數據(也即翻譯好的語言對)較少時表現更好,這也是首次將其應用于無監督的機器翻譯。基于短語的機器翻譯系統,能夠得出正確的單詞,但仍然不能形成流暢的句子。但是,這種方法取得的結果也優于以前最先進的無監督模型。
最后,他們將兩種模型結合起來,得到一個既流暢又準確翻譯的模型。其方法是,從一個訓練好的神經模型開始,用基于短語的模型生成的反向翻譯句子,對這個神經模型進行訓練。
根據實證結果,研究人員發現最后一種組合方法顯著提高了先前無監督機器翻譯的準確性,在BLEU基準測試上,英法和英德兩個語種的翻譯提高了超過10分(英法和英德翻譯也是使用無監督學習訓練的,僅在測試時使用了翻譯好的語言對進行評估)。
研究人員還測試了在語種上相隔較遠的語種(英俄),訓練資源較少的語種(英語—羅馬尼亞語),以及語種相隔極遠且訓練資源極少的語種(英語—烏爾都語)的翻譯。在所有情況下,新的方法比其他無監督方法都有很大的改進,有時甚至超過了使用監督學習方法進行訓練的翻譯系統得出的結果。
適用于任何領域的無監督學習,讓智能體利用無標記數據執行罕見任務
Facebook的研究人員表示,在BLEU測試基準上提高超過10分是一個令人興奮的開始,但對他們來說更令人興奮的是這種方法為未來改進開啟的可能性。
從短期來看,這肯定有助于我們翻譯更多的語言并提高訓練數據少的語言的翻譯質量。但是,從這種新方法和基本原則中獲得的知識,可以遠遠超出機器翻譯的范疇。
Facebook的研究人員認為,這項研究有可能應用于任何領域的無監督學習,并可以讓智能體利用沒有標記的數據執行當前只有少量甚至沒有專家演示的任務。這項工作表明,系統至少可以在沒有監督的情況下學習,并建立一個耦合系統,其中每個組件都在一個良性循環中,隨著時間的推移而不斷改進。
現在,這個項目已經在Github開源,代碼可以訪問下面的鏈接獲得:
https://github.com/facebookresearch/UnsupervisedMT
相關論文:https://arxiv.org/pdf/1804.07755.pdf
-
Facebook
+關注
關注
3文章
1429瀏覽量
54992 -
機器學習
+關注
關注
66文章
8438瀏覽量
133080 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14945
原文標題:Facebook全新無監督機器翻譯法,BLUE測試提升超過10分!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機器翻譯三大核心技術原理 | AI知識科普
機器翻譯三大核心技術原理 | AI知識科普 2
機器翻譯不可不知的Seq2Seq模型
英漢機器翻譯中基于模式的譯文生成
機器翻譯系統實現了自然語言處理的又一里程碑突破

從冷戰到深度學習_機器翻譯歷史不簡單

阿里巴巴機器翻譯在跨境電商場景下的應用和實踐
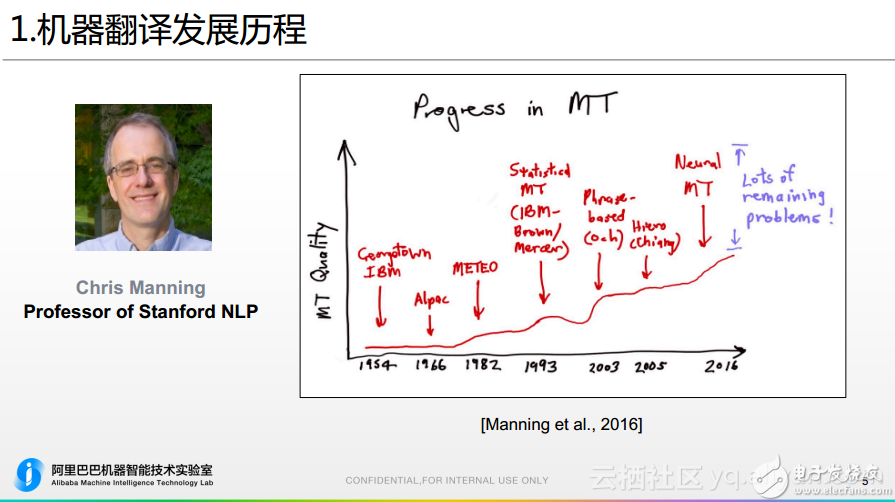
從冷戰到深度學習,機器翻譯歷史不簡單!
換個角度來聊機器翻譯

人工智能翻譯mRASP:可翻譯32種語言
未來機器翻譯會取代人工翻譯嗎
多語言翻譯新范式的工作:機器翻譯界的BERT





 工商網監
工商網監
評論