") 基于目標圖像的視覺強化學(xué)習(xí)算法,讓機器人可以同時學(xué)習(xí)多個任務(wù)
基于目標圖像的視覺強化學(xué)習(xí)算法,讓機器人可以同時學(xué)習(xí)多個任務(wù)
目前的深度強化學(xué)習(xí)需要人為地為每一個任務(wù)設(shè)計獎勵函數(shù),當涉及復(fù)雜系統(tǒng)時需要很多的人力成本和復(fù)雜的工作。如果需要完成更大范圍內(nèi)的更多工作,就需要對每一個新任務(wù)進行重復(fù)的訓(xùn)練。為了提高學(xué)習(xí)的效率,伯克利的研究者們提出了一種可以同時對多個不同任務(wù)進行學(xué)習(xí)的算法,無需人工干預(yù)。
這一算法可以自動從圖像中抽取目標并學(xué)習(xí)如何達到目標,并實現(xiàn)推物體、抓握和開門等一系列特殊的任務(wù)。機器人可以學(xué)會自己表示目標、學(xué)習(xí)如何達到目標,而一切的輸入僅僅是來自相機的RGB圖像。
· 目標條件下的強化學(xué)習(xí)
如何描述真實世界的狀態(tài)和期望的目標是我們需要考慮的首要問題,但對于機器人來說枚舉出所有需要注意的物體是不現(xiàn)實的,現(xiàn)實世界中的物體及其數(shù)量變化多端、如果要檢測他們就需要額外的視覺檢測工作。
那么該如何解決這一問題呢?研究人員提出了一種直接利用傳感器信息來操作的方法,利用機器人相機的輸出來表達世界的狀態(tài),同時利用期望狀態(tài)的圖像作為目標輸入到機器人中。對于新的任務(wù),只需要為模型提供新的目標圖像即可。這種方法同時能拓展到多種復(fù)雜的任務(wù),例如可以通過語言和描述來表達狀態(tài)/目標。(或者可以利用先前提出的方法來優(yōu)化目標:傳送門>>UC Berkeley提出新的時域差分模型策略:從無模型到基于模型的深度強化學(xué)習(xí))
強化學(xué)習(xí)是一種訓(xùn)練主體最大化獎勵的學(xué)習(xí)機制,對于目標條件下的強化學(xué)習(xí)來說可以將獎勵函數(shù)設(shè)為當前狀態(tài)與目標狀態(tài)之間距離的反比函數(shù),那么最大化獎勵就對應(yīng)著最小化與目標函數(shù)的距離。
我們可以通過一個基于目標條件下的Q函數(shù)來訓(xùn)練策略實現(xiàn)最大化獎勵。基于目標條件的Q函數(shù)Q(s,a,g)描述的是在當前狀態(tài)和目標下,當前的行為將產(chǎn)生對主體怎樣的結(jié)果(獎勵)?也就是說在給定狀態(tài)s、目標g的前提下,我們可以通過優(yōu)化行為a來實現(xiàn)獎勵最大化:
π(s,g) = maxaQ(s,a,g)
基于Q函數(shù)來選擇最優(yōu)的行為,可以得到最大化獎勵和的策略(在這個例子中便是達到各種不同的目標)。
Q學(xué)習(xí)得以廣泛應(yīng)用的原因在于它可以不基于策略而僅僅只依賴與s,a,g。那么意味著訓(xùn)練任意策略所收集的數(shù)據(jù)都可以用來在多個任務(wù)上進行訓(xùn)練。基于目標條件的Q學(xué)習(xí)算法如簡圖所示:
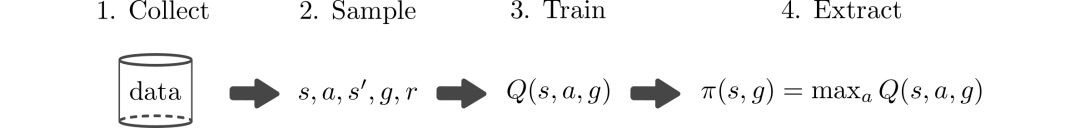
但上述方法的主要局限在于數(shù)據(jù)收集。如果能人工生成數(shù)據(jù),理論上就可以學(xué)習(xí)解決不同的任務(wù)而無需與真實世界進行交互。但遺憾的是在真實世界中學(xué)習(xí)精確的模型十分困難,所以通常依賴于采樣來獲取狀態(tài)s--行為a--下一個狀態(tài)s'的訓(xùn)練數(shù)據(jù)。
但我們換個角度來看,如果可以表達出獎勵函數(shù)r(s,g), 有一種可以生成目標并計算獎勵的機制,我們就可以可回溯的重新標記目標,重新計算獎勵。這樣的話就可以利用(s,a,s') 數(shù)據(jù)生成大量的人工數(shù)據(jù),這一個過程如下圖所示:

最美妙的事情在于可以同時生成多個目標和獎勵函數(shù),這就意味著可以學(xué)習(xí)達到多個目標而無需采集額外的數(shù)據(jù),這一簡單的改進極大的加速了學(xué)習(xí)過程。
上面的方法主要基于兩個假設(shè):1).知道獎勵函數(shù)的表達并可以進行操作;2).可以得到目標的采樣分布p(g).基于前人的工作,可以方便的設(shè)計出目標分布p(g)和獎勵函數(shù)。
但對于基于視覺的任務(wù)來說會出現(xiàn)兩個問題:1).由于基于像素的距離可能沒有實際意義,模型不知道該使用哪一個獎勵函數(shù);2).由于任務(wù)的目標是圖像的形式,需要知道目標圖像的分布p(g),但人工設(shè)計目標圖像的分布是一個很復(fù)雜的任務(wù)。那么研究人員們期望最好的情況就是,主體可以自動地想象出它的目標,并學(xué)習(xí)出如何達到這一目標。
·基于假想目標的強化學(xué)習(xí)
為了解決這一問題,研究人員通過學(xué)習(xí)出圖像的表示并利用這些表示來實現(xiàn)條件Q學(xué)習(xí),而不是直接利用圖像本身來進行強化學(xué)習(xí)。那么這時候關(guān)鍵的問題就被轉(zhuǎn)換為:這一從圖像中學(xué)習(xí)的表達應(yīng)該滿足什么樣的特點?為了計算出語義的獎勵,需要一種可以捕捉圖像中變量潛在因素的表達,同時這種表達需要很便捷地生成新的目標。
試驗中研究人員通過變分自編碼器(VAE)來從圖像中獲取滿足這些條件地表示。這種生成模型可以將高維空間中圖像轉(zhuǎn)換到低維度地隱空間中去(或者進行相反地變換)。得到的模型可以將圖像轉(zhuǎn)換到隱空間中并抽取其中的變量特征,這與人類在真實世界中描述目標的抽象過程很類似。在給定當前圖像x和目標圖像xg后,模型可將他們轉(zhuǎn)換為隱空間中對應(yīng)的隱變量z和zg,此時就可以利用隱變量來為強化學(xué)習(xí)算法描述系統(tǒng)狀態(tài)和期望目標了。在低維的隱空間中學(xué)習(xí)Q函數(shù)和策略比直接使用圖像進行訓(xùn)練要快很多。
將當前圖像和目標圖像編碼到隱空間中,并利用其中的距離來計算獎勵。
這同時解決了如何計算強化學(xué)習(xí)中計算獎勵的問題。相較于利用像素誤差,可以使用隱空間中與目標的距離來訓(xùn)練主體。在最大化抵達目標概率的同時這一方法可以給出更有效的學(xué)習(xí)信號。
這一模型的重要性在于主體可以容易的在隱空間中生成目標。(這一生成模型使得隱空間中的采樣是可以回溯的:僅僅從VAE的先驗中采樣)其原因在于:為主體提供了可以設(shè)置自身目標的機制,主體從生成模型的隱變量中采樣并嘗試抵達隱空間中的目標;同時為重采樣機制也可用于前述的重標記過程。由于訓(xùn)練的生成模型可以將真實圖像編碼為先驗,從先驗的隱變量采樣也對應(yīng)著有意義的隱目標。
主體可以通過模型生成自己的目標,用于探索和目標重標記。
綜上所述,對于輸入圖像的隱空間表示1).捕捉了場景中的隱含因素;2).為優(yōu)化提供了有效的距離度量;3).提供了有效的目標采樣機制,使得這一方法可以直接利用像素輸入來實現(xiàn)基于假想的強化學(xué)習(xí)算法( Reinforcement Learning with imagined Goals ,RIG)
· 實驗
下面研究人員將通過實驗來證明這一方法是能簡單高效地在合理的時間內(nèi)在真實世界中訓(xùn)練出機器人策略。實驗分為兩個任務(wù),分別是基于目標圖像直到機械臂運動到人為指定地位置和將目標推到期望的位置。實驗中僅僅通過84*84的RGB圖像來訓(xùn)練,而沒有關(guān)節(jié)角度和位置信息。
機器人首先學(xué)習(xí)到如何在隱含空間內(nèi)學(xué)習(xí)出自己的目標,這一階段可以利用解碼器來可視化機器人為自己假想出來的目標。下圖上半部分顯示了機器人“想象”出的目標位置,而下面圖則是實際運行狀況。
通過設(shè)置自身的目標,機器人就可以在沒有人類的干預(yù)下自動的訓(xùn)練嘗試以抵達目標。需要執(zhí)行特定的任務(wù)時,才需要人為的給定目標圖像。由于機器人以及多次練習(xí)過如何抵達目標,在下面的圖中我們可以看到它已經(jīng)不需要額外的訓(xùn)練便可以抵達新的目標。
下圖是第二個任務(wù),利用RIG來訓(xùn)練機械臂將物體推到指定位置。其中左邊是實驗裝置、右上是目標圖像、右下是機器人推動的過程。
通過圖像訓(xùn)練策略使得機器人推物體的任務(wù)變得容易多了。只需要在上一個任務(wù)的基礎(chǔ)上加上一張桌子、一個物體、稍微調(diào)整相機就可以開始訓(xùn)練了。雖然模型的輸入是圖像,但這一算法只需要一個小時的時間就可以訓(xùn)練完成抵達特定位置的任務(wù)、4.5小時就可以實現(xiàn)將物體推到特定位置的任務(wù)(需要與環(huán)境交互),同時達到了比較好的精度。
很多實際使用的強化學(xué)習(xí)算法需要目標位置的基準狀態(tài),然而這卻需要引入額外的傳感器或訓(xùn)練目標檢測算法來實現(xiàn) 。與之相比,這里提出的算法僅僅依賴于RGB相機,并可以直接輸入圖像完成訓(xùn)練過程。
· 未來研究方向
通過前文描述的方法,可以利用直接輸入的圖片訓(xùn)練出真實世界的機器人策略,簡單高效地實現(xiàn)不同的任務(wù)。基于這一結(jié)果,可以開啟很多令人激動地研究領(lǐng)域。這一研究不僅限于利用圖像作為強化學(xué)習(xí)的目標,同時還可以廣泛應(yīng)用于語言和描述等不同的目標表達中。同時,可以探索如何利用更本質(zhì)的方式來選擇目標以實現(xiàn)更好的自動學(xué)習(xí)。如果使用內(nèi)在動機的概念與上文提出的策略結(jié)合,可以引導(dǎo)策略進行更快的學(xué)習(xí)。
另一個可能方向是訓(xùn)練模型能夠處理動力學(xué)的情況。對環(huán)境動力學(xué)進行編碼可以使得隱含空間更加適合強化學(xué)習(xí),加速學(xué)習(xí)的過程。最后,有很多機器人任務(wù)的狀態(tài)很難被傳感器所捕捉,但利用基于假想目標的學(xué)習(xí)就可以處理諸如形變物體的抓取、目標數(shù)量變化這樣復(fù)雜的問題。
-
機器人
+關(guān)注
關(guān)注
211文章
28641瀏覽量
208396 -
算法
+關(guān)注
關(guān)注
23文章
4630瀏覽量
93348 -
強化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
268瀏覽量
11298
原文標題:伯克利研究人員提出基于目標圖像的視覺強化學(xué)習(xí)算法,讓機器人可以同時學(xué)習(xí)多個任務(wù)
文章出處:【微信號:thejiangmen,微信公眾號:將門創(chuàng)投】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
【「具身智能機器人系統(tǒng)」閱讀體驗】2.具身智能機器人的基礎(chǔ)模塊
基于深度學(xué)習(xí)技術(shù)的智能機器人
機器人視覺系統(tǒng)組成及定位算法分析
深度強化學(xué)習(xí)實戰(zhàn)
四足機器人的機構(gòu)設(shè)計
基于LCS和LS-SVM的多機器人強化學(xué)習(xí)
【重磅】DeepMind發(fā)布通用強化學(xué)習(xí)新范式,自主機器人可學(xué)會任何任務(wù)
基于強化學(xué)習(xí)的MADDPG算法原理及實現(xiàn)
一文詳談機器學(xué)習(xí)的強化學(xué)習(xí)
一種基于多智能體協(xié)同強化學(xué)習(xí)的多目標追蹤方法
機器學(xué)習(xí)中的無模型強化學(xué)習(xí)算法及研究綜述

當機器人遇見強化學(xué)習(xí),會碰出怎樣的火花?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論